基于平滑采样和改进损失的不平衡文本分类
2023-12-10梁健力商豪
梁健力 商豪


[收稿日期]20210923
[第一作者]梁健力(1996-),男,广东佛山人,湖北工业大学硕士研究生,研究方向为数据挖掘
[通信作者]商豪(1982-),女,湖北罗田人,湖北工业大学副教授,研究方向为随机分析与算法
[文章编号]1003-4684(2023)02-0033-07
[摘要]在不平衡数据下,文本分类模型容易把样本数量较少的类别错分成数量较多的类别。在采样层面上提出一种平滑采样方法,在损失函数层面上根据不平衡分布改进交叉熵损失和标签平滑。复旦文本数据集上的实验表明,每种层面的改进都较基准模型有一定提高。当结合使用采样和损失函数的改进时,TextCNN、BiLSTM+Attention、TextRCNN和HAN模型在宏平均F1值上分别提高4.17%、5.13%、5.06%和6.21%,在G-mean上分别提高6.56%、3.03%、3.92%和5.32%,较好解决了不平衡数据下文本分类任务。
[关键词]文本分类; 不平衡比例; 平滑采样; 损失函数
[中图分类号]TP391 [文献标识码]A
文本分类是自然语言处理领域中一项基础又重要的任务,可用于情感分析、新闻分类和意图识别等应用场景,也可以为搜索、排序等大型的复杂系统提供技术支持。从传统的手工特征结合分类器[1-2]的机器学习时代,再到使用循环神经网络(Recurrent Neural Network)[3-5]、卷积神经网络(Convolutional Neural Network)[6]和大规模预训练语言模型(Pretrained Language Model)[7-8]对数据进行自动学习的深度学习时代,模型不断被创新和优化,文本分类效果得到了飞跃性的突破。例如,TextCNN[6]汲取N元语法(n-gram)[9]的思想,使用不同大小的卷积核来捕捉句子中的局部信息,取得了当时文本分类最好的结果。TextRCNN[10]在双向长短时记忆网络(BiLSTM)的基础上,使用1×1卷积核在通道维度上进行卷积运算,并通过时序全局最大池化获取重要特征。带注意力机制的双向长短时记忆网络(BiLSTM-Attention)[11]在充分利用RNNs的时序建模优良性的同时,使用长短时记忆网络(LSTM)和注意力机制来缓解梯度消失的问题,进一步提升模型的效果。HAN[12]模型利用注意力机制,从单词层面和句子层面对文档进行分类,从而捕捉句子中的重要词汇以及文档中的重要句子,获取较好的分类效果。
然而,文本分类性能的提升与训练数据的质量、规模以及类别平衡性有着一定的关系。当出现数据标签不平衡时,由于每个训练样本对目标函数的贡献均等,模型在学习过程中会主动偏向样本数量较多的类别标签。一方面相当于模型对多数类别有着更大的权重,另一方面也意味着模型对多数类别过拟合。但测试阶段所采用的评价指标对多数类别与少数类别都同等看待,最终导致在类别不平衡的场景下,训练结果与实际的测试结果相差甚远。
由于现实收集的数据基本都存在类别不平衡的现象,需要进一步研究在类别不平衡场景下的文本分类。过去机器学习和深度学习时代,主要通过3种方式来处理类别不平衡的问题,即对原始数据进行重抽样[13-16]、修改损失函数[17-18]以及采用集成学习算法[19]。在采样方法上,本文利用数据的不平衡比例,基于指数平滑的思想,提出了一种降低数据不平衡度的平滑重抽样方法;在损失函数上,以不平衡分布来改进标签平滑以及交叉熵损失,提出了一种结合不平衡分布和标签平滑的交叉熵损失函数以提升文本分类的效果。同时结合采样方法和在损失函数上的改进,深度学习模型对不平衡数据的分类能力得到进一步提升。
1 方法设计
1.1 采样方法
在过去,无论是机器学习中的经典采样方法,还是深度学习中的数据增强方法,对不平衡数据采样后是否配平并没有统一的定论。有的学者采用完全配平的方式来完成样本的重抽样,有的则认为这种配平方式可能会损害最终的分类效果。所以,在采样后保持多大的不平衡比例仍然是一个需要深入研究的问题。但总体来看,增加数据量、降低数据的不平衡度对文本分类效果有一定增益。
指数平滑多用于时间序列,其是对历史观测值按时间进行加权平均作为当前时间的预测值。虽然训练数据的不平衡比例序列和时间并没有关联,但由于指数平滑具有一定的平滑数据功能,能够在降低不平衡比例的同时,保证平滑后的类别不平衡度与平滑前有相似的分布。本文提出的平滑采样方法的定义如下:
假设原始数据有k个类别,记为c1,c2,…,ck。记#ci为第i个类别的样本数量,其中i取1,2,…,k,可定义各类别的不平衡比例如下:
θi=#cimin(#c1,#c2,…,#ck)
对于k个类别可得到长度为k的不平衡序列{θt}kt=1,将该序列从小到大排序得到有序的不平衡序列{θ′t}kt=1,根据指数平滑思想计算不平衡序列的平滑值,其中t取1,2,…,k:
vt=0,t=0βvt-1+(1-β)θ′t,t≥1
修正平滑值,其中t取1,2,…,k:
v′t=vt1-βt
根據修正后的平滑值与原始的不平衡比例,可计算各类别中欠采样(式(1))与过采样(式(2))的比例,其中minv′tθ′tkt=1是指k个欠采样比例的最小值,且t取1,2,…,k:
dt=v′tθ′t(1)
ot=v′tθ′t/minv′tθ′tkt=1(2)
由于式(2)并不能保证过采样比例大于1,因此对过采样比例ot进行修正,使得修正后的过采样比例恒大于1。
o′t=ot+log1ot
1.2 损失函数
在深度学习模型训练中,由于需要使用损失函数根据正向传播的结果计算出误差,再进行反向传播实现梯度更新,因此模型的效果往往跟选用何种损失函数有一定关系,好的损失函数可能会带来性能上的提升。在文本分类问题上,一般采用交叉熵损失,其具体定义如下:
loss=-1N∑Nn=1∑kc=1y(n)clog(n)c(3)
假定训练数据中有k个类别,一个批的样本数量为N,记类别c的独热编码向量为yhot,其具体形式为[I(1=c),I(2=c),…,I(k=c)]T。使用y(n)c来代表批中第n个样本是否属于第c个类别,其中y(n)c∈{0,1}。而(n)c表示该样本属于第c个类别的预测概率。
由于交叉熵损失对多数类样本和少数类样本的错误同等看待,为了使模型在训练过程中更加关注少数类别,本文根据训练数据的不平衡分布对交叉熵损失进行改进,记原始数据或采样数据的类别不平衡比例为{θc}kc=1,对于改进后的带不平衡分布的交叉熵损失
weight_loss=-1N∑Nn=1∑kc=11θcy(n)clog(n)c
此外,为了防止模型在训练过程中对标签的预测过于自信,本文还对损失函数引入标签平滑[20]的正则化方式。其结合均匀分布的思想来修改传统的独热编码向量,可以减少类内距离,增加类间距离,从而提升模型的泛化能力[21]。记α为平滑值,标签平滑的具体形式为:
y(i)smooth=1-α,i=targetα/(k-1),i≠target(4)
但在不平衡数据中,各类别标签的分布并不均匀,因此本文使用数据不平衡比例对标签平滑进行改进。首先利用原始的不平衡比例序列{θi}ki=1求出用于标签平滑的不平衡比例序列θ(i)smoothki=1,其具体形式如下:
θ(i)smooth=0,i=target1θi,i≠target
对不平衡序列θ(i)smoothki=1进行归一化处理,可得到改进后的标签平滑向量y′smooth,其元素值
y′(i)smooth=1-α,i=targetα·softmax(θsmooth)(i),i≠target(4)
结合式(3)和式(4),可得到用带不平衡分布的标签平滑来改进交叉熵损失的形式:
smooth_loss=1N∑Nn=1∑kc=1y(n)smooth,clogc(n)
最后将带不平衡分布的交叉熵损失和带改进标签平滑的交叉熵损失加权平均,得到本文最终提出的损失函数,其具体形式如下:
our_loss=βweight_loss+(1-β)smooth_loss
其中β是需要调节的超参数。当β等于1时,该损失函数退化为带不平衡分布的交叉熵损失;当β等于0时,该损失函数退化为带改进标签平滑的交叉熵损失。
2 实验设置
2.1 實验数据集
实验数据集主要采用复旦大学的文本分类语料库,其包含9804个训练文档与9833个测试文档,并涵盖了20个主题类别。其中,原始数据中各类别的样本数量和文档长度差异较大,数量不平衡比例高达64∶1。此外,数据集中有大量的重复数据,且部分文档并没有包含实质性的内容。因此,本文先对原始数据集进行数据清洗,并提取文档中的正文部分进行分析。清洗后的训练集和测试集包含8184和8197个文档,训练数据的不平衡比例降为54.84∶1。训练集清洗前后的数量和文档字符长度分布如图1所示。
(a)原始训练数据集的类别分布/比例
(b)清洗训练数据集的类别分布/比例
(c)原始训练数据集的字符长度分布
(d)清洗训练数据集的字符长度分布图 1 训练集清洗前后数量和字符长度分布
此外,在模型训练和测试前,还需要对文本进行分词和去除停用词。本文使用jieba分词工具对清洗后的训练集和测试集进行分词,并引入停词表对其进行去停词处理。
2.2 评价指标
准确率(accuracy)是衡量模型好坏的标准之一。但当数据是类别不平衡或者不同类别的错误所造成的后果不同的时候,准确率这一指标实际并不适用。通常来说,模型的分类性能应综合使用查全率和查准率进行度量。此外,也有学者建议使用G-mean来度量模型在不平衡数据中的表现。因此,本文将把宏F1和G-mean作为主要的性能评价指标,多分类情况下的性能指标定义如下:
假设数据集中有k个类别,Ck×k为分类的混淆矩阵,Cij为该矩阵中的第i行第j列的元素,其中i,j∈{1,2,…,k}。记Ci.=[Ci1,Ci2,…,Cik]T,C.j=[C1j,C2j,…,Ckj]T,可计算各类别中真正例(TPv)、假正例(FPv)、真反例(TNv)、假反例(FNv)向量:
TPv=diag(Ck×k)=[C11,C22,…,Ckk]T
FPv=∑ki=1Ci.-diag(Ck×k)
FNv=∑kj=1C.j-diag(Ck×k)
TNv=[∑i∑jCk×k,…,∑i∑jCk×k]k×1-(TPv+FPv+FNv)
根据TPv、FPv、TNv和FNv可计算宏查准率(macro-Pv)、宏查全率(macro-Rv)和宏特异度(macro-Sv)向量为:
macro-Pv=TPvTPv+FPv
macro-Rv=TPvTPv+FNv
macro-Sv=TNvTNv+FPv
根据向量macro-Pv、macro-Rv和macro-Sv可计算得到本文使用的宏F1和G-mean:
macro-F1=1k∑2×macro-Pv⊙macro-Rvmacro-Pv+macro-Rv
G-mean=1k∑macro-Rv⊙macro-Sv
2.3 文本分类模型
为了呈现改进方法的效果,本文将使用BiLSTM-Attention、TextCNN、TextRCNN和HAN等几个较先进的深度学习模型来进行实验。
1)设置BiLSTM-Attention模型的输入序列长度、词向量维度、隐藏层单元数和隐藏层数量分别为2000、200、200和2。
2)对于TextCNN模型,本文使用窗宽为3、4、5的卷积核来提取特征,每组不同卷积核的输出维度都为200。此外,设置模型输入的序列长度为3000,词向量维度为200,模型的输入维度为400。其中,模型的输入由两组序列词向量合并而成,一組为固定的词向量,一组随着模型的训练而更新。
3)本文设置TextRCNN模型的输入序列长度为3000,词向量维度为200,BiLSTM模块的隐藏层单元数和隐藏层数量分别为100和1,卷积模块的输出维度为300。其中将BiLSTM模块的输出和原始序列的词向量在通道维度上进行连接,作为卷积模块的输入。
4)本文设置HAN模型的单个文档中的最大句子数和句子中的最大单词数分别为20、80,双向门控循环神经网络(BiGRU)模块的隐藏层单元数和隐藏层数量分别为200和1。
由于复旦文本数据集中的文档字符长度不一,因此,本文对较短的文档进行补0,对较长的文档从中间进行截取。在将文本转化成词向量的过程中,采用预训练的腾讯词向量,其词向量维度为200。在训练过程中,采用学习率衰减的方法,每更新1000步时进行一次衰减。此外,各种模型的输出节点数都为20,Dropout的概率采用0.5,激活函数皆采用ReLU。
3 实验结果和分析
为了单独呈现采样方法的效果,本文还将利用BOW、TFIDF、LDA和Fasttext来进行特征提取,并在经过不同采样处理的数据集上建模。在采样方式上,本文分别进行随机欠采样、随机过采样和回译过采样三种实验;在采样比例上,本文采用0.44、0.74、0.86、0.9、0.96和0.98等6种采样平滑值,并与原始比例以及完全配平的数据集实验结果进行对照。为了避免其他数据增强方法对实验结果的干扰,表1仅展示9种模型在不同随机过采样比例上的具体表现,其余采样方式的实验结果如图2所示。其中,9种模型对比系统如下。
1)BOW:使用词袋模型表示文本,特征维度为20 000,并用逻辑回归(LR)和随机森林(RF)对文本进行分类。
2)TFIDF:使用词频逆词频表示文本,特征维度为20 000,并用支持向量机(SVM)和极端梯度提升树(Xgboost)对进行文本分类。
3)LDA:使用概率主题模型将文本映射到低维空间向量,再用RF和SVM进行分类,其中主题个数为130。
4)Fasttext:先采用有监督方式直接进行文本分类,再使用无监督的方法生成文本词向量,并用LR和SVM进行分类。
由表1可以看出,9种模型系统的最佳结果皆在非原始比例数据集上取得。其中,完全配平的采样方式更倾向于在BOW、TFIDF等稀疏的向量表示空间上取得更好的效果,但在LDA、Fasttext等稠密的低维空间上的表现甚至比原始比例数据集的效果差。这表明虽然不平衡比例的降低和样本数量的增加会对模型效果有一定增益,但完全配平的方式会极大改变原始数据分布,可能会导致模型性能下降。此外,随着采样比例的调整,本文提出的采样方法在9种模型系统上均取得比原始比例更好的效果。在BOW、LDA和Fasttext三种模型系统中,对比采样平滑值0.74和0.98的结果,可发现后者都有一定的提升,但其不平衡比例从41.66下降到17.71,数据量却基本保持不变,表明适当降低不平衡比例可能会给模型带来提升,尤其是在低维稠密的向量空间中。
图2a显示不同采样平滑值下各类别不平衡比例的变化情况。相比于完全配平,该采样方式在降低不平衡比例的同时,仍保持与原始数据相似的分布。从图2b可以看出,在绝大部分实验模型中,欠采样会极大地损害模型的性能,这是由于样本数量的锐减使得文本中的重要信息缺失,从而导致分类效果的下降。而图2c和d则表明,在过采样时,采用回译等其他增强方式可能会降低直接随机复制样本带来的过拟合风险,从而进一步提升分类的效果。
图 2 不同改进采样方法在复旦数据集上的实验结果
为了进一步说明平滑采样方法和带不平衡分布与标签平滑的损失函数的有效性,本文以TextCNN为基准,开展一系列的对比工作。表2和表3分别呈现使用预训练的腾讯词向量前后,改进的采样方法和损失函数较基准方法的提升。其中,CE和Smooth分别表示仅使用交叉熵损失和带标签平滑的交叉熵损失的情况;Weight_CE和Weight_Smooth分别代表利用不平衡分布改进的交叉熵损失和标签平滑的情况;Weight_CE_Smooth是指结合使用带不平衡分布的交叉熵损失和带改进标签平滑的交叉熵损失的结果,其中超参数选取0.9;+0.98是指TextCNN模型在利用0.98采样平滑率得到的数据集下的建模效果,其中采样方式默认为随机过采样,而trans表示使用回译的方式来进行过采样。表3呈现了本文实验的最佳效果。
从表2和表3可以看出,无论是单独使用本文提出的采样方法,还是单独使用损失函数上的改进,其在宏F1和G-mean上都较基准模型上有一定的提升。而当结合使用带不平衡分布的交叉熵损失和带改进标签平滑的交叉熵损失时,文本分类效果能够得到进一步改善。此外,当融合采样方法以及损失函数的改进时,模型在宏F1上会有进一步的提升,但相比只使用损失函数改进时,G-mean会有轻微下降。
当未使用预训练的腾讯词向量时,本文提出的方法较基准模型分别在准确率、宏查全率、宏F1和G-mean上提升1.18%、10.12%、8.73%和7.49%,但在宏查准率上轻微损失了0.53%;当使用预训练的腾讯词向量时,本文提出的方法较基准模型在宏查全率上提升了10.21%,在宏F1上提升了4.17%,在G-mean上提升了6.56%,但在准确率和宏查准率上分别损失了0.23%和3.95%。
图3a展示了在使用预训练词向量的情况下,本文使用的改进方法与基准模型在20个主题类别中的宏F1值对比。可以看出,改进方法在多数类别中保持与基准模型一致的分类效果,而其区分少数类别的性能有了较大的改善,从而提升了整体的分类效果。
(a)改进方法和基准模型在各个主题上的实验结果
图3b呈现了在不同采样平滑率下联合采样方法和损失函数改进的模型效果。可以看出,使用回译代替简单随机复制的过采样方法,可以进一步提升模型的效果。
(b)不同采样比例下的方法结果对比图 3 聯合改进方法在复旦数据集上的实验结果
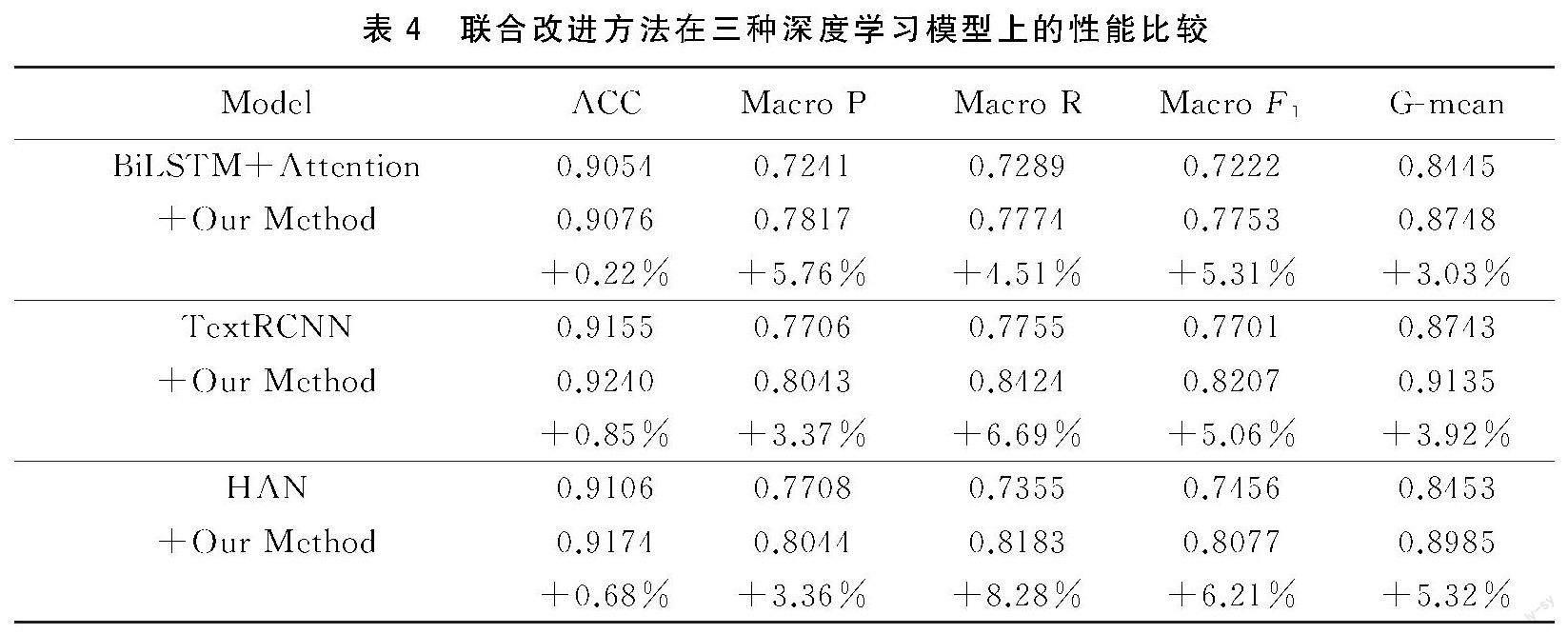
为了表明改进方法的适用性,表4还显示了BiLSTM+Attention、TextRCNN和HAN等3种模型在改进前后的效果对比。改进后的这3种深度学习模型都在宏F1和G-mean上有着较大的提升,且在准确率、宏查准率和宏查全率都没有性能的损失。其中BiLSTM+Attention模型在宏F1上提升了5.31%、在G-mean上提升了3.03%;TextRCNN模型在宏F1和G-mean分别提升了5.06%和3.92%;HAN模型获得了6.21%的宏F1和5.32%的G-mean性能提升。
通过上述实验结果可以看出,适当降低不平衡比例,以及利用不平衡分布改进交叉熵损失和标签平滑,可以提高少数类别的分类性能。此外,融合采样方法和损失函数的改进能够为整体的分类效果带来进一步的提升。虽然本文的改进方法可能会牺牲部分宏查准率的性能,但其能大幅提升宏查全率,且保持准确率基本不变,从而获得模型在宏F1和G-mean等综合指标的改善。
4 结论
本文从采样方法和损失函数上进行改进,并在复旦文本数据上进行验证。实验表明,单独使用本文提出的平滑采样方法、带不平衡分布的改进交叉熵损失和改进标签平滑时,都较基准模型有一定提升。而当联合使用采样方法和损失函数的改进时,以宏F1和G-mean作为性能评判标准,其在4种深度学习模型中都取得较大的性能提高。因此,本文提出的算法可以较好地解决不平衡数据的分类问题,在大量数据中能够更好地检测出少数类别的数据。
[参考文献]
[1]CAVNAR W B, TRENKLE J M. N-gram-based text categorization[C].∥Proceedings of SDAIR-94, 3rd annual symposium on document analysis and information retrieval,1994,161175.
[2]SALTON G, BUCKLEY C. Term-weighting approaches in automatic text retrieval[J]. Information processing & management, 1988, 24(05):513-523.
[3]HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(08):1735-1780.
[4]Chung J,Gulcehre C,Cho K H,et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[C].∥NIPS 2014 Workshop on Deep Learning,2014.
[5]LAI S, XU L, LIU K, et al. Recurrent convolutional neural networks for text classification[C].∥Proceedings of the AAAI Conference on Artificial Intelligence,2015.
[6]KIM Y. Convolutional neural networks for sentence classification[J]. EMNLP, 2014.
[7]VASWANI A, Shazeer N, Parmar N, et al. Attention is all you need[C].∥Advances in neural information processing systems,2017:5998-6008.
[8]DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C].∥Proceedings of NAACL-HLT,2018.
[9]CAVNAR W B, TRENKLE J M. N-gram-based text categorization[C].∥Proceedings of SDAIR-94, 3rd annual symposium on document analysis and information retrieval,1994:161 175.
[10] LAI S, XU L, LIU K, et al. Recurrent convolutional neural networks for text classification[C].∥Proceedings of the AAAI Conference on Artificial Intelligence,2015.
[11] ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C].∥Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers),2016:207-212.
[12] YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification[C].∥Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies,2016:1480-1489.
[13] KUBAT M, MATWIN S. Addressing the curse of imbalanced training sets: one-sided selection[J].Icml, 1997, 97:179-186.
[14] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002, 16:321-357.
[15] WEI J, ZOU K. EDA: Easy data augmentation techniques for boosting performance on text classification tasks[C].∥Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019:6382-6388.
[16] YU A W, DOHAN D, LUONG M T, et al. QANet: Combining local convolution with global self-attention for reading comprehension[C].∥International Conference on Learning Representations,2018.
[17] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C].∥Proceedings of the IEEE international conference on computer vision, 2017:2980-2988.
[18] LI X, SUN X, MENG Y, et al. Dice loss for data-imbalanced NLP tasks[C].∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020:465-476.
[19] SUN Y, KAMEL M S, Wong A K C, et al. Cost-sensitive boosting for classification of imbalanced data[J]. Pattern Recognition, 2007, 40(12):3358-3378.
[20] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C].∥Proceedings of the IEEE conference on computer vision and pattern recognition, 2016:2818-2826.
[21] MLLER R, KORNBLITH S, HINTON G.When doeslabelsmoothinghelp? [C].∥NeurIPS,2019.
Unbalanced Text Classification Based on SmoothSampling and Improved Loss
LIANG Jianli, SHANG Hao
(School of Science, Hubei Univ. of Tech., Wuhan 430068, China)
Abstract:When data are imbalanced, text classification models are easy to misclassify minority class to majority class. This paper proposes a smooth sampling method at the sampling level, and improves the cross entropy loss and label smoothing based on the imbalanced distribution at the loss function level. Experiments on the Fudan text corpus show that the improved method in each level outperforms the benchmark method. With the combination of the improved method in sampling level and loss function level, the TextCNN, BiLSTM+Attention, TextRCNN and HAN models can obtain 4.17%, 5.31%, 5.06%, and 6.21% macro F1 improvement and increase 6.56%, 3.03%, 3.92%, and 5.32% on G mean respectively. The methods proposed in this paper have been verified the effectiveness on imbalanced corpora.
Keywords: text classification; unbalanced percent; sampling; loss function
[責任编校: 张众]
