基于特征识别的变电站消防监控图像处理方法
2023-12-08节连彬赵嘉兴刘毅敏
节连彬, 赵嘉兴, 刘毅敏
(国网山西省电力公司 a. 阳泉供电公司, b. 营销部, 山西 阳泉 045000)
目前变电站正向自动化、无人化方向发展,消防监控是变电站消防安全管理的有效途径[1]。大多变电站消防设备除了具备感温、感光、感烟功能外,还增加了“遥视”功能。通过对远程传输图像进行处理可以及时检测是否存在火灾,具有远程非接触特点。“遥视”图像处理技术可使火灾能够在较短时间内得以有效识别且不受空间位置影响,避免造成经济损失和社会影响,确保实现变电站的全年消防安全目标[2-3]。
图像处理技术是通过计算机对图像进行分析、归纳、总结来辨别图像中目标所属类的一种技术。图像处理技术通常包括图像预处理、目标检测、图像分割、特征提取、特征选择、目标分类等[4]。YAMAMOTO等[5]提出了一种融合思想,将监控的红外图像和彩色图像融合为一幅图像,通过增强视觉效果来识别电力传输线,该方法识别精度较低,容易出现漏诊和误诊情况。赵梦琦[6]提出了一种基于拓扑理论数学形态学的图像分割方法—分水岭算法,能够针对图像边缘进行精准定位,但对梯度图像中的纹理和噪声较敏感,容易引起过分割现象。TÖREYIN等[7]利用火焰颜色会随着时间推移而发生变化的特性,提出了一种结合火焰颜色特征识别的火灾图像处理算法,采用小波分析和频率统计算法,通过比较火灾图像序列差异实现火灾识别,该方法识别精度较高,但仍存在漏诊情况,此外该算法需要处理数据量较大,需要多帧复杂视频比较,不适宜远程传输且增加了火灾识别时间。
针对上述方法的不足,本文提出了一种采用K-means聚类算法的图像处理方法。通过提取变电站监控图像的HSI特征,针对该特征进行图像子集聚类,分割火灾子集、类火灾子集和非火灾子集,并结合火灾纹理、边缘特征采用样本熵信号处理算法进一步识别火灾区域。由于该处理方法适用于静态图像,因而降低了运算时间,能够进行实时火灾识别。本文搜集整理200幅变电站消防监控图像,运用Python3.7开发工具进行建模仿真,实验验证了所提方法的准确性。
1 HSI特征识别
1.1 颜色模型
图1为RGB和HSI颜色模型。变电站消防监控图像通常属于RGB颜色模型,由红(R)、绿(G)、蓝(B)三原色组成。RGB颜色模型只反映了颜色特征并未体现亮度特征。当火焰亮度发生变化时,设定的分割图像子集阈值发生变化,进而降低火灾识别准确率[8]。HSI颜色模型是一种更加符合人眼视觉系统描述和颜色方式解释的颜色模型,由色调(H)、饱和度(S)、亮度(I)三个特征构成。色调表示颜色频率;饱和度表示颜色深浅;亮度表示颜色强度,有利于对火灾颜色特征进行识别。HSI颜色模型可以从彩色图像携带的色调和饱和度特征中消去强度分量的影响,进而使得该模型能够应用在类火灾子集图像处理算法中[9]。

图1 RGB和HSI颜色模型Fig.1 RGB and HSI colour models
1.2 特征提取
变电站火灾原始图像如图2所示。该图像属于RGB颜色模型,模型三个维度R、G、B范围为[0,255],可与HSI颜色模型相互转换。对RGB模型进行归一化处理,则

图2 变电站火灾原始图像Fig.2 Original image of substation fire
(1)
式中,R′、G′和B′分别为R、G、B的归一化处理值。
将RGB颜色模型转换为HSI模型,即
(2)
(3)
(4)
式中,θ为色调角度,θ∈[0,2π]。转化后变电站火灾图像如图3所示。

图3 变电站火灾特征提取图像Fig.3 Feature extraction image of substation fire
2 K-means图像子集分割
2.1 K-means聚类算法
K-means聚类算法[10]是一种典型无监督学习分类方法,其目的是将数据样本划分成有意义或有用的簇并应用于变电站消防监控图像中。K-means聚类算法将由一定数据样本构成的特征(HSI颜色特征)矩阵划分为无交集的簇(火灾子集、类火灾子集、非火灾子集)用以表征聚类表现结果。通常情况下定义每个簇内所有数据样本的均值为该簇的“质心”。在K-means聚类算法中簇的个数是一个超参数,需要根据具体情况确定。随机选取一定像素点作为初始质心,计算每个像素点到每个质心的距离,将离质心最近的像素点分配到该质心所属的簇中。采用欧式距离法进行计算,即
(5)
式中:x为簇中像素点位置;α为簇中质心位置;n为像素点特征数量;i为像素点特征值。
重新计算每个簇中所有数据样本的均值并将其作为新的质心,直到簇不再发生变化或达到最大迭代次数。实际上,在质心不断变化的迭代过程中,簇内每个样本点到质心的距离平方和(簇内平方和)越来越小。因此,K-means求解过程变成了一个簇内平方和最优化的问题,具体算法流程如图4所示。
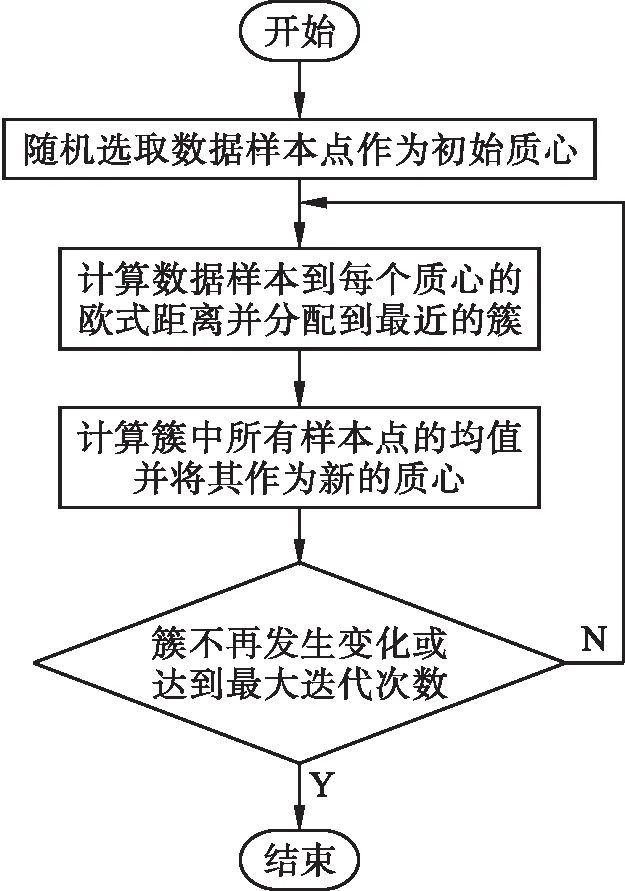
图4 K-means聚类算法流程Fig.4 Flow chart of K-means clustering algorithm
2.2 变电站消防监控图像分割
变电站监控图像中可能存在与火焰相近颜色或特征的物体。因此,采用K-means聚类算法先将图像中特征相似的物体聚类于同一簇中,可以有效降低火灾识别复杂度[11]。
图5为原始图像与K-means聚类结果。图5a变电站火灾原始图像具有307×410个像素点,每个像素点有H、S、I三个特征,共计125 870个颜色点。通常变电站消防监控图像包括变电站设施、天空、场地等区域,而火灾区域又分为火焰和被火焰照射区域。设置超参数为5,按照图4所示流程进行K-means聚类得到5个簇。图5b为聚类后形成的天空区域图像子集;图5c为聚类后变电站设施和烟雾区域图像子集;图5d聚类后为场地和其他区域图像子集;图5e为聚类后火焰照射区域图像子集;图5f为聚类后火焰区域图像子集。

图5 原始图像与K-means聚类结果Fig.5 Original image and K-means clustering results
对100幅变电站火灾图像进行K-means算法分割后的分析结果表明,火灾区域图像子集H特征范围集中在[0,0.17],S特征范围集中在[0,0.47],I特征范围集中在[0.56,1]。因此,可以通过提取原始监控图像的HSI特征判断该图像的所有像素点是否在火焰区域特征范围内,若是,则进行相应标记。相对分水岭分割方法,K-means聚类算法考虑了像素点的更多特征且可以避免图像中的像素点陷入局部分割,具有较强鲁棒性。
3 样本熵火灾识别
仅通过K-means算法分割图像子集,再利用HSI颜色特征阈值判定法来识别火灾的准确率较低。因为变电站消防监控图像中可能包含与火焰色调、饱和度、亮度近似的物体,消防柜、消防管、红色标志等均有可能作为火灾区域被标记出来。图6为变电站监控原始图像和类火灾子集。由图6可见,图像中的消防柜在图像子集分割时被误认为是火灾区域而标记出来。因此,需要对基于HSI颜色特征的K-means聚类算法进行优化。

图6 变电站监控原始图像和类火灾子集Fig.6 Original image and fire-like subset of substation monitoring
样本熵[12-15]是一种新的衡量时间序列复杂度算法,信号中产生新模式的概率越大,序列复杂度越大,样本熵值越大。通过对火灾图像子集和类火灾图像子集的边缘、纹理、灰度等特征进行比对与分析后发现,火焰信号分布较为杂乱且无规律,相对于消防柜、消防管等复杂度高得多。因此,可以通过计算标记火灾区域的样本熵值进行火灾判定。样本熵具体计算流程为:
1) 将标记为火灾区域的图像子集降维成长度为N的时间序列β(n),1≤n≤N。
2) 根据比较维度构造一组m维空间向量Y(i),Y(i)={β(i),β(i+1),…,β(i+m)},1≤i≤N-m+1。
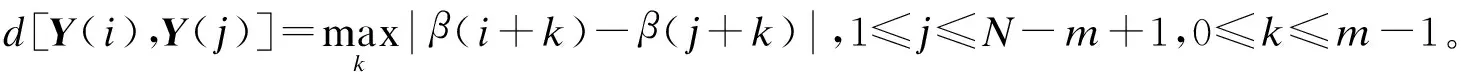

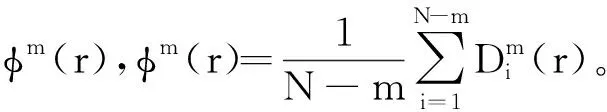

选取50幅既包含火灾区域又包含类火灾区域的变电站监控图像,设置N=1 200,m=3,r=0.15。计算标记为火灾图像子集的样本熵,结果如图7所示。火灾区域的样本熵值范围为[0.8,2.0],类火灾区域的样本熵值范围为[0.2,0.75]。设置样本熵阈值为0.8,当标记为火灾图像子集的样本熵值大于0.8时,判定为存在火灾并进行报警;当样本熵值小于0.8,则判定为非(类)火灾区域。

图7 火灾区域和类火灾区域样本熵对比Fig.7 Comparison of sample entropy between fire and fire-like areas
4 实验结果与分析
4.1 评价指标
在实际变电站消防监控中发生火灾是小概率事件[16-17]。因此,火灾识别数据集是不平衡数据集,采用正确率作为实验评价指标意义不大。本文选取TPR(真正类率)和FPR(假正类率)作为验证所提方法性能的评价指标。存在火灾记为正,无火灾记为负,即
(6)
(7)
式中:TP为识别为正实际为正的样本数;FN为识别为负实际为正的样本数;FP为识别为正实际为负的样本数;TN为识别为负实际为负的样本数。TPR为识别存在火灾实际也存在火灾的样本数占实际发生火灾总数的比例,TPR越大表征性能越优,若TPR为100%则表示未出现漏诊;FPR为识别存在火灾实际非火灾的样本数占实际非火灾总数的比例,FPR越小表征性能越优,FPR为零表示未有误诊。在变电站消防监控应用中,漏诊危害远高于误诊,因而需要更加关注TPR指标。
4.2 结果分析
选取某110 kV变电站安全区域作为试点区域,整个实验过程时长100 min。由变电站专业人员在30 min时进行点火,火焰持续10 min后灭火。通过摄像头拍摄并将视频导入消防监控平台。平台每隔30s生成一幅图像(共计200幅图像,其中火灾图像20幅)并调用火灾识别模型脚本。利用开发工具Python3.7 OpenCV库编写模型脚本,建模流程如图8所示。

图8 图像处理建模流程Fig.8 Flow chart of modelling for image processing
传统分水岭算法因过分割问题导致火灾区域无法被识别,因而采用改进分水岭算法(在图像处理前后进行预处理)作为算法1与本文所提方法(算法2)对200幅变电站消防监控图像进行分割与火灾识别对比,识别结果如表1所示。实际存在火灾的20幅图像中算法1识别出14幅,漏诊率为30%,算法2识别出20幅,未有漏诊情况;实际为非火灾的180幅图像中,算法1有37幅识别为火灾图像,误诊率为20.56%;算法2有8幅图像识别为火灾图像,误诊率为4.44%;算法1与算法2火灾识别并报警平均时间t分别为21.68 s和15.21 s。

表1 火灾识别结果Tab.1 Fire identification results
算法1仅使用每个像素点的灰度值单一特征,会受到类火灾图像子集的影响导致火灾漏诊率和误诊率较高。另外,在分水岭算法分割前,需要采用像素标记和滤波方式进行图像预处理,从而降低噪声和纹理的影响。分水岭算法分割后通过自定义合并规则进行受噪声或纹理影响的极小邻接区域合并,虽然有效抑制过分割现象,但模型算法复杂度增加同时也延长了图像火灾识别时间。算法2提取了HSI表征火焰的3项特征且采用欧氏距离进行聚类,可以避免局部噪声的影响,降低漏诊率和误诊率的同时缩短了识别时间。此外,算法2的8幅误诊非火灾图像中均包含类火灾图像子集,类火灾区域样本熵值介于0.80~0.81之间,因此考虑可以通过提高样本熵值的阈值精度来降低误诊率。
5 结束语
针对变电站消防监控图像火灾识别存在误诊甚至漏诊的情况,在基于HSI特征的K-means聚类图像分割基础上进行火灾区域(类火灾区域)标记,克服了仅用单一特征识别火灾区域的缺陷且具有较强鲁棒性。利用火灾区域序列复杂度大于类火灾区域序列复杂度的特性,采用样本熵阈值法判别是否为火灾区域并进行报警,提高了火灾识别方法的准确性。200幅变电站消防图像实验结果表明,所提图像处理方法规避了火灾漏诊风险,误诊率仅为4.44%,每幅图像平均识别时间为15.21 s,能够实现火灾的迅速精准识别。未来可通过分析更多火灾(类火灾)图像样本,考虑更全面的特征优化样本熵阈值,进一步降低误诊率。
