基于改进孤立森林算法的异常用电行为识别方法
2023-12-08钱旭盛翟千惠张轩城
钱旭盛, 朱 萌, 翟千惠, 张轩城, 陈 可
(1. 哈尔滨工业大学 电气工程及自动化学院, 黑龙江 哈尔滨 150006; 2. 国网江苏省电力有限公司 营销服务中心, 江苏 南京 210018)
异常用电行为会造成电网的电能损失,该损失通常分为技术性和非技术性两种[1-2],后者通常是由于电力用户的窃电行为所造成的.而窃电则普遍通过私下篡改计量装置与电力线路等方式实现,该行为不仅会给电网造成经济损失,还存在严重的安全隐患。当前,异常用电行为主要依靠人工定期现场巡检来进行识别,虽然消耗了大量的人、物及财力,但其覆盖面窄且识别效率仍较低[3]。因此,利用现代数据挖掘技术实现异常用电行为的高效识别,对于电网的稳定运行及智能建设具有重要意义[4-5]。
现阶段国内外应用于异常用电行为识别的数据挖掘方法分为有监督和无监督学习两类。有监督学习需要人工对样本数据进行类别标签的标记,其主观性较强且工作量较大。而无监督学习则不需要标签标记即可识别更多数据之间的映射关系。NIZAR等[6]采用基于距离的聚类算法K-means对电力用户的负荷数据进行聚合,以得到特征曲线,再根据两者的偏离程度实现对异常用户的识别;田力等[7]采用基于密度的聚类方法分析电力用户的异常行为,并通过簇的异常程度得分来进行排序。庄池杰等[8]基于主成分分析(principal component analysis,PCA)法进行特征降维,并采用优化离群算法结合阈值设定识别出异常用电用户。上述文献所提方法均需要计算有关距离和密度的指标,因此对用电行为高维度数据的计算效率偏低,且精准度也会受到影响。本文提出一种基于孤立森林算法(isolation forest,iForest)的异常用电行为识别方法,该方法无须对距离与密度进行计算便可大幅提升速度并减少系统的开销,同时文中还引入粒子群优化算法(particle swarm optimization,PSO)进一步增强了异常识别的检测精度。
1 异常用电行为特征
电力负荷曲线虽然能在一定程度上反映异常用户的某些规律,但其作为识别模型的特征并不明显,因此需要进行数据探索,总结异常用户的行为规律,再从相关数据中提取出描述异常用户的特征指标,如图1所示。提取的特征指标包括:电量下降趋势、线损率以及告警类指标。

图1 异常用电行为特征分类及其指标Fig.1 Classification and indexes of abnormal electricity user behavior
正常用户的用电量在一个周期内较为平稳,而异常用户的用电量则存在持续下降的情况。首先统计一个时间窗口内的电量下降趋势,将时间窗口设定为当日的前后5日,并用斜率ki表示这11日中第i日的电量趋势,即
(1)

线损率用于衡量供电线路的损失比例,若用户用电异常、存在窃漏电行为,则当日的线损率便会增加,第i日线损率r可表示为
(2)

2 孤立森林算法理论
目前,异常用电行为识别方法主要使用正常样本进行学习与训练,并在特征空间中划分出一个正常样本区域,对于不属于该区域的样本,则判断其为异常样本。该方法的主要问题在于训练过程中仅会对正常样本的学习加以优化,由此可能出现大量误报和漏报的情况。而孤立森林算法[9-10]并未学习正常的样本,其利用二叉搜索树结构以递归的形式随机分割数据集,从而对异常样本进行孤立。由于异常样本具有数量较少且与大部分样本疏离的特点,因此该样本会被更早地孤立出来,其相比传统聚类算法有更良好的鲁棒性。孤立森林的分割示意图如图2所示。从图2中可以较为直观看到,正常样本点x1经过12次分割才从整体中分离出来,而异常样本x2仅需3次即可完成分割。
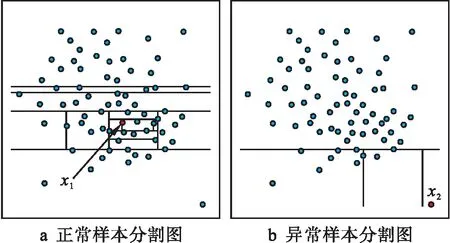
图2 孤立森林示意图Fig.2 Schematic Diagram of Isolated Forest
单棵孤立树的构建流程如图3所示。重复t次即可得到t棵孤立树并生成孤立森林,随后将每个样本点x带入孤立森林,计算异常得分,即

图3 单棵孤立树的构建流程Fig.3 Flow chart of single isolated tree construction
(3)
式中:h(x)为样本x在孤立树中的高度;c(β)为路径长度的平均值,需要进行标准化处理。若
c(β)异常得分接近1,则为异常样本;若c(β)异常得分远小于0.5,则为正常样本;若c(β)异常得分约为0.5,则表示不存在异常样本。
3 基于粒子群的改进孤立森林算法
孤立森林的本质是一种基于套袋思想的集成算法,因此选择精准度较高、差异度偏大的孤立树子集有利于对异常用电行为的识别。通过粒子群算法寻找最优孤立树子集,在降低孤立树数量并提升运行效率的同时,还提高了异常用电行为的识别精度。
3.1 粒子群算法
粒子群算法[11-13]通过模拟鸟群飞行觅食的行为,将每只鸟均作为寻优的问题解,并利用群集智慧的思想,共同协作实现群体最优。每只鸟即一个粒子,在一个D维空间内进行个体和群体的寻优搜索,假设有N个粒子,粒子i的位置为
li=(li1,li2,…,liD)
(4)
每个粒子是否处于最佳位置,需要通过适应度函数f(x)进行判断。对粒子赋予记忆功能,并记录历史搜索的最佳位置为
zbesti=(zi1,zi2,…,ziD)
(5)
其中,种群所经历的最优位置为
gbesti=(g1,g2,…,gD)
(6)
在飞行搜索中每个粒子均具有一个速度vi=(vi1,vi2,…,viD),该速度决定了飞行搜索的距离和方向。根据自身及群体的飞行搜索情况对其速度进行动态调整,则粒子i的第d维速度与位置更新表达式为
(7)
(8)
式中:c1和c2分别为个体及群体的调节学习最大步长;r1和r2为随机数,通常取值范围为[0,1];ω为惯性权重。
3.2 改进孤立森林算法
根据选择性集成思想,通过粒子群算法在孤立森林中选择出精准度高、差异度大的孤立树子集。做出上述选择的原因在于:识别异常用电行为是一种基于投票的分类集成思想,低精度的孤立树可能会对结果产生误导;而差异度较大的孤立树能够互补不同个体间的学习信息,进一步增加孤立森林的泛化能力。为了平衡精准度和差异度的需求,建立适应度函数为
(9)
图4 ROC曲线Fig.4 ROC curve
差异度采用汉明距离[14-16]进行评价,即比较两个孤立树集合之间对于相同样本不同标记的个数,不同标记的个数越多,两棵孤立树之间的差异度就越大。为了消除量纲的影响,将评价指标映射到[0,1]范围内,则有
(10)
式中:n为样本数量,且T={s1,s2,…,sn};s=0或1,1和0分别表示识别正确及错误的样本;D(Ti,Tj)为孤立树Ti与Tj的汉明距离。Q越接近1表示差异度越大。
通过适应度函数计算粒子的适应度值,并更新粒子群的位置。将每个粒子维度对应到孤立森林的孤立树中,并将孤立树进行二进制编码,‘1’表示选择该孤立树,‘0’表示未选择。基于粒子群的改进孤立森林算法流程如图5所示。最终输出最优的孤立树子集,其能够同时满足较高的精准度及差异度,可以直接用于用电行为数据的异常分析计算。
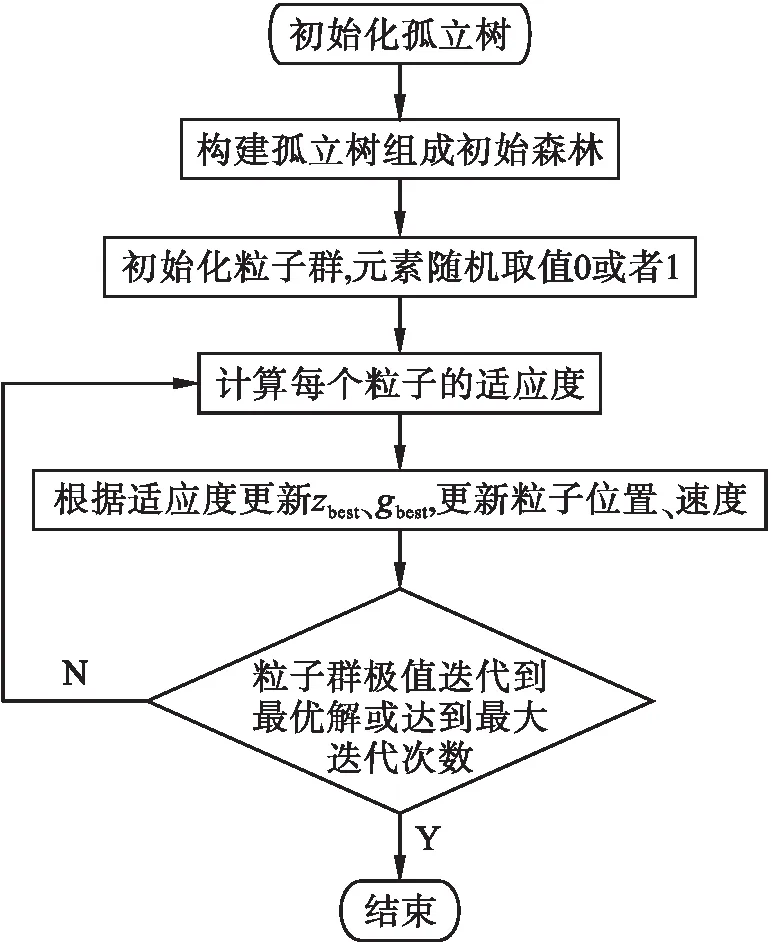
图5 改进孤立森林算法流程Fig.5 Flow chart of improved isolated forest algorithm
4 实验验证分析
本实验抽取某市近一个月的窃漏电用户数据和部分正常用户数据,两类用户共计3 910户,其中异常的有148户,占比3.79%。数据中包含用户电力负荷、线损率及终端报警等信息。同时,实验集成开发环境则采用Pycharm的Python 3.8.3。
由于在用户负荷抽取中存在缺失值,因此本实验采用拉格朗日插值法对该值填充,填充表达式为
(11)
填充完数据后便可进行特征提取,样本示例如表1所示。

表1 特征提取后的样本示例Tab.1 Sample demonstration after feature extraction
构建孤立森林模型有两个重要参数:孤立树棵数和采样数。采用学习曲线的方法进行参数确认,结果如图6、7所示。由图6可知,孤立树的棵数大于140之后,AUC值均较为接近,且在0.925上下波动;而采样数在大于200时,AUC值约为0.93,之后则随着采样数的增加略有下降。因此,本文两参数取值分别为140和200。接着再确定适应度函数α和γ的值,由于精准度与差异度同等重要,故α和γ均取值0.5。采用网格搜索的方法对粒子群进行调参,参数结果如表2所示。

表2 粒子群参数Tab.2 Particle swarm parameters

图6 不同孤立树棵数的AUC值Fig.6 AUC value of different isolated tree number

图7 不同采样数的AUC值Fig.7 AUC value of different samples
对改进孤立森林、传统孤立森林和K-means聚类算法的精准度进行对比,结果如图8所示。从图8中可以看出,在148户异常用户中,3种算法分别识别出了133户、126户和99户异常用户,且改进孤立森林算法的真正率高达89.86%,从而大幅降低漏检的风险性。而在3 762户正常用户中,3种算法识别出的异常用户分别为194户、243户及350户,且改进孤立森立算法假正率仅为5.16%,有效地降低了误检的可能性。由此说明,改进孤立森林算法的AUC值高于孤立森林及K-means聚类算法,能够更为精准地识别出异常用户。

图8 不同算法的AUC值对比Fig.8 Comparison of AUC values of different algorithms
3种算法的执行效率对比情况如表3所示。其中孤立森林类算法由于省去了计算距离、密度指标所带来的时间消耗,故其执行效率远高于K-means聚类算法。而改进孤立森林则在原始孤立森林的基础上,进一步采用粒子群算法选出了精准度高且差异度较大的最优孤立树子集,从而减少了孤立森林的规模,且其执行效率约为传统孤立森林的3倍。由此证实了改进孤立森林在异常用电行为识别上的优越性。

表3 3种算法的计算时间Tab.3 Computation time of three algorithms
5 结 论
本文提出了一种基于粒子群算法的改进孤立森林识别模型。通过提取样本特征反映异常用户的用电行为,并平衡精准度和差异度建立适应度函数,再结合学习曲线与网格搜索方法优化了模型参数。实验结果表明,改进孤立森林算法在异常用电行为识别上的真正率及假正率均优于对比算法,故其漏检和误检率更低,而且执行效率更高,因此具有更为理想的识别效果。未来将考虑通过其他的优化算法对孤立森林进行改进,以期进一步提升对异常用电行为的识别精度。
