基于节点相似性的并行启发式网络拓扑结构发现算法
2023-12-08董振亮陈志宾何文海孙丽丽
董振亮, 陈志宾, 张 华, 何文海, 孙丽丽
(1. 华北电力大学 计算机系, 河北 保定 071003; 2. 河北省教育考试院 信息管理部, 河北 石家庄 050091; 3. 河北省科学院 应用数学研究所, 河北 石家庄 050081; 4. 石家庄医学高等专科学校 公共课部, 河北 石家庄 050000)
随着计算机和通信技术的快速普及,普通网络的拓扑结构也呈现出大型化与模块化的特点,从而逐渐转化为具有生物、社交及通信等多种功能的复杂网络。按照图论原理,在复杂网络中具有相似抽象属性或功能的所有节点均可被归纳为连通子图,这样的划分方式也被称为社区结构。通常而言,复杂网络中社区内部节点连接密度较高,而社区之间节点连接密度较低,这样的组织结构大幅提高了复杂网络的管理效率。然而,随着网络规模的不断扩大,如何完成全局性的社区发现逐渐成为复杂网络研究领域的主要问题。
针对大规模复杂网络的全局性社区发现问题,国内外学者已做出了诸多具有较高借鉴价值的工作。刘旭[1]在开源平台上给出了能够评估社区划分分数的目标函数,进而充分衡量了社区划分的质量和水平。周旭[2]通过引入启发式蚁群算法(ant clony optimization,ACO),首次提出高精确度的社区发现算法,该算法具有一定的启发性和代表性。然而,上述工作依旧未能完全解决复杂网络中的社区发现问题,且相应算法的执行效率及准确率仍有待提高。为了进一步优化该算法,文中在邻接矩阵的基础上,结合经典的评判准则,制定了更加精确的节点相似性评价规则,进而提出了具有并行化特点的社区发现算法。由社区发现算法实验仿真可知,与基于Jaccard准则的社区发现算法相比,本文所提出的算法具有较高的精确度及更少的执行时间。
1 节点相似性
在复杂网络中,由于网络拓扑具有较高的不确定性且难以进行预测,因此复杂社区网络的发现问题已成为横跨多个研究领域的难题之一[3-5]。为描述该问题,多位学者引入图论的邻接矩阵对社区网络发现问题进行了详细阐述[6-7]。
不妨令G代表由n个节点与m条边组成的复杂社区网络,根据节点间的连接关系,可得到与G逐一对应的邻接矩阵M。令i,j∈[1,n],则矩阵M中元素mij表示第i个节点与第j个节点间的连接关系。若节点i与节点j之间有边连接,则mij=1;否则,mij=0。利用邻接矩阵M的数据可以顺利统计复杂网络G中所有节点的连通状态。对于节点i,与其连接的所有节点数量即为矩阵M的第i行或第i列的边数之和,该数值又被称为节点i的度数。在复杂网络G中,令Ci表示与节点i具有连接关系的所有节点组成的邻居集合。通常而言,邻居集合Ci也是网络G的非空子集。在邻居集合Ci中,节点i的度数越大,则其与集合中其他节点的联系就更为紧密。换言之,与其他节点的联系越紧密,则当前节点的重要程度越高。
为了精确衡量社区网络中节点间的相似性关系,文中对具有不同属性的相邻节点设置了不同的权重,从而实现节点相似性的计算与区分,具体设置方法如下:
1) 若邻接矩阵元素mij=1,即节点i与节点j之间具有连接的边,则这些边的权重设置为w1;
2) 若节点i和节点j的邻居集合Ci及Cj之间存在非空交集,且该交集的节点存在连接的边,则这些边的权重设置为w2;
3) 若节点i及节点j的邻居集合Ci与Cj之间存在非空交集,且该交集中存在没有连接的边,则这些边的权重设置为w3;
4) 若节点i和节点j的邻居集合Ci及Cj之间存在非空交集,而其他节点与该交集以及节点i、j存在连接的边,则这些边的权重设置为w4;
5) 对于其他连接情况的边,则设置其权重为w5。
需要说明的是,不同的边对节点相似性产生的影响不同,所以权重遵循递减的顺序,即w1>w2>w3>w4>w5。
定义1根据边权重的设置方法,节点i和节点j之间相似性的计算表达式为
(1)
式中,N1、N2、N3、N4和N5分别为节点相似性权重设置时5种不同类型边的数目。

2 并行化策略
在复杂网络中,数据信息的快速增长及不合理分配会造成计算资源的浪费[8-9],从而大幅降低整体的运行效率,而其根源在于社区发现中的串行算法结构。为了改变这一现状,文中通过改变社区数据的组织结构,提出具有并行化特点的存储与检索策略[10]。
通常而言,传统的复杂网络采用数组及链表的结构来实现数据的存储和检索。其优点在于数据的插入及删除较为便捷,但其寻址仍存在较大困难。为克服这一缺点,文中引入哈希表完成对数据的存储,从而实现数据的快速查询、插入、删除与寻址等多种操作[11]。令a~f表示拓扑图中的6个节点,F表示节点之间的边存储信息,H表示对应的哈希函数,wi表示第i个边权重数值,则并行化存储策略的框架如图1所示。
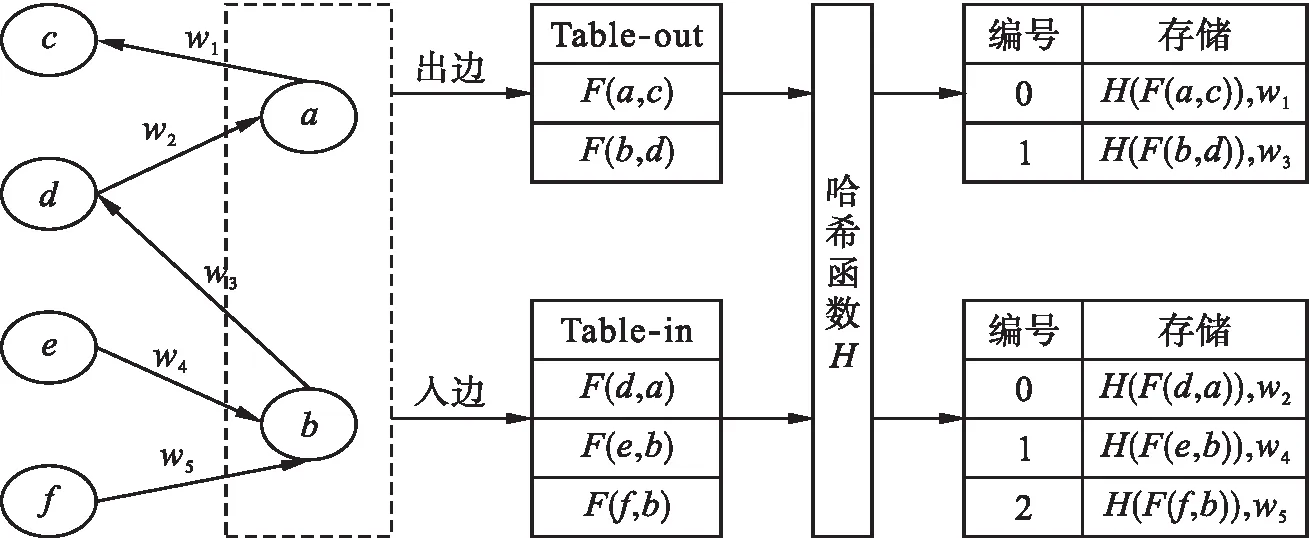
图1 并行化存储策略框架示意图Fig.1 Schematic diagram of parallelized storage strategy framework
由图1可知,在策略框架中,网络G利用哈希表计算存储发射方向与入射方向的节点信息,其实现步骤如下:
1) 按照边的方向对G中所有边进行分类,即分别使用Table-in和Table-out表格存储入边与出边;
2) 利用边的节点信息及函数F,计算入边和出边的实际存储信息,令“|”表示位或运算,“≪”表示位左移运算,则节点i和j之间边的存储信息计算表达式为
F(i,j)=j|(i≪16)
(2)
3) 利用哈希函数[12]对边的存储信息进行计算,获取对应的哈希值,再结合边的权值信息,形成具有固定格式的三元组信息,并分别存储于对应的哈希表中。令H0表示斐波那契哈希函数,S表示哈希表的最大容量,φ表示黄金分割率,常数m=264-1,则自变量x的哈希值计算方式为
(3)
综上所述,文中通过综合节点相似性及哈希函数,将复杂网络的节点数据存储转化为哈希表格式,进而实现节点关系数据的高效存储与检索。同时利用并行化策略,计算节点相似性时无须扫描所有网络节点,便可顺利地将串行计算模式转换为并行计算模式,并降低发现算法的计算成本。
3 社区发现算法
复杂网络社区结构的发现和划分与其拓扑结构之间具有较为紧密的关系[13-15],这意味着社区发现算法需根据网络节点的相似性计算结果来考虑图中边权值的影响,并对复杂网络的所有节点属性进行识别及划分,再以较高的精确度判定复杂网络的社区结构。实际算法步骤如下:
1) 针对复杂网络抽象化之后的网络G建立存储入边和出边的Table-in与Table-out表格,并加入边的哈希存储表;
2) 按照节点相似性的设置方式,利用降序法设置边的权重影响因子(w1>w2>w3>w4>w5);
3) 从G中任选两个网络节点i和j,并利用并行化存储策略构建哈希表,同时获取这两个节点的所有邻居三元组信息,再计算节点i和j之间的相似性;
4) 重复执行步骤3,直至G中所有n个网络节点之间的相似性计算完成,并形成节点相似性矩阵;
5) 根据节点相似性矩阵结果,对G中所有n个节点执行聚类操作,即按照相似性计算结果实现复杂网络所有节点的层次划分;
6) 依据节点的层次划分结果,完成对复杂网络的社区划分。
4 实验仿真
在大规模网络数据集基础上,针对节点相似性社区发现算法,本文设计了算法的综合性测试仿真,从而充分地衡量复杂网络中社区发现算法的计算效率与准确度。
4.1 仿真数据集
基于Jaccard准则及节点相似性的社区发现算法,文中引入了反映客观网络状态的大型数据集,即Email Euall数据集。该数据集由某研究机构所有发送和接收的电子邮件组成,共包含42个研究部门的通信信息。经过抽象化之后,与Email Euall数据集对应的图包含1 005个节点与25 571条边,且其平均聚类系数为0.339 4。此外,在复杂网络中节点重要程度与节点的度成正比关系。按照此原则,文中引入节点相似性因子δ对原始数据集进行了必要处理,从而充分评估中心节点的重要程度。其中,令Mi和Mj分别表示邻接矩阵的第i行和第j行,即节点i和j的邻域集合,则节点i和j之间的相似性因子δ表达式为
(4)
4.2 评估指标
为了衡量算法发现结构与客观网络结构间的匹配度,文中引入标准化信息交互评估机制,即利用社区层次划分的一致程度评估发现算法的准确性。

(5)
对于同样复杂网络结构,通过计算算法划分结果及复杂网络之间的标准化互信息指标可获取不同算法划分结果的相似程度,从而衡量社区发现算法的划分质量。一般而言,标准化互信息量I(rp,rq)的计算结果位于[0,1]之间,其数值越接近于0,则表明准确划分结果与发现算法运行结果的相关性越低;而数值越接近于1,则发现算法运行结果越接近准确的划分结果。
4.3 仿真过程
对于具有不同节点相似性因子的Email Euall数据集,本文分别对基于Jaccard准则及基于节点相似性的社区发现算法进行必要的测试对比。需要说明的是,针对两种社区发现算法,文中主要从准确度和计算效率进行衡量。在不同相似性因子的实验数据集条件下,文中对两种算法的运行结果与实验数据集之间的标准化互信息量进行了精确统计,结果如图2所示;在不同相似性因子的实验数据集条件下,两种社区发现算法达到相同的标准化互信息量(0.7)所需的运行时间不同,文中对算法的运行时间进行了统计与对比,结果如图3所示。

图2 不同相似性因子时两种算法的标准化互信息量Fig.2 Normalized mutual information of two algorithms under different similarity factors
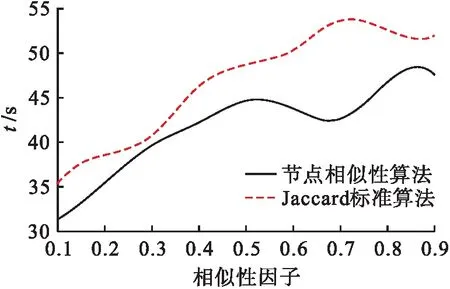
图3 在不同相似性因子时两种算法的运行时间Fig.3 Running time of two algorithms under different similarity factors
由图2的统计结果可知,当节点相似性因子数值增加时,基于Jaccard准则与基于节点相似性的社区发现算法的标准化互信息量均呈现了先小幅下降再大幅提升的趋势;且当相似性因子相等时,基于节点相似性的社区发现算法的标准化互信息量优于经典的Jaccard准则社区发现算法。换言之,与基于Jaccard准则的社区发现算法相比,本文算法具有更优的准确度。从图3可以看出,随着相似性因子数值的增加,两种算法的运行时间逐步增加,部分情况下会出现小幅下降;但当相似性因子相等时,为达到相同的拓扑发现精确度,基于节点相似性的社区发现算法所需运行时间均小于经典的Jaccard准则社区发现算法,表明文中算法的计算效率更高。综上所述,与经典Jaccard准则的社区发现算法相比,基于节点相似性的社区发现算法具备更高的发现准确度及计算效率。
5 结束语
基于节点相似性和并行化策略,文中提出具有较高准确度和计算效率的复杂网络社区发现算法,并对该算法进行了必要的仿真对比及分析。与经典Jaccard准则的社区发现算法相比,基于节点相似性的社区发现算法并未进行实际应用环境下的反复实验与仿真,这意味着该算法仍停留在实验阶段,在大面积应用时仍然可能存在潜在的缺陷和问题,尤其是社区发现算法在更大应用范围内的安全性和稳定性未能得到充分的实验和分析,将在未来的工作中致力于这一问题的研究,从而实现基于节点相似性的并行拓扑结构发现算法的推广和应用。
