ECA-SKNet:玉米单倍体种子的卷积神经网络识别模型
2023-12-06刘勇国朱嘉静
刘勇国,高 攀,兰 荻,朱嘉静
(电子科技大学信息与软件工程学院 成都 610054)
单倍体育种是一种植物育种方法,其原理是利用人工培育或自然发生的单倍体植株,通过加倍该植株染色体获得纯合的二倍体植株[1]。玉米单倍体育种[2]主要包括单倍体生产、单倍体鉴定、单倍体加倍产生单二倍体(diploid haploid, DH)系、DH 系育种几个步骤[3],具有如下优点:1)获得纯系快,育种周期短;2)无基因互作效应,选择准确性高;3)所获DH 系高度纯合和稳定[4];4)所得DH 群体遗传类型丰富。单倍体自然发生的概率仅为0.1%[5],故实际单倍体育种均采用人工诱导单倍体技术。通过诱导剂进行人工诱导的DH 率为8%以上[6],虽然人工诱导有如此高的DH 率,但诱导后仍有问题待解决,即如何从众多单二倍体玉米种子中鉴别出单倍体种子。
文献[7]使用核磁共振测定玉米种子含油量,提出一种基于最小二乘误差的单倍体和二倍体的分离方法。根据模型结果,最小二乘误差法可在样本较少的情况下快速确定单倍体和二倍体含油量的阈值,识别率达90%以上。文献[8]设计了一套玉米单倍体种子的分选系统,该系统包括种子输送、图像采集与处理、分选和系统控制单元,系统根据玉米胚和玉米胚乳顶部的颜色特征分选单倍体,能够实现500 粒/min 的分选速度,对杂合种子的正确识别率为90%,分选成功率为80%。文献[9-10]使用从灰度共生矩阵中获得的文体特征识别单倍体和二倍体玉米种子。这些特征被用于决策树(decision tree, DT)、k-最近邻和人工神经网络分类器的输入,结果显示,最佳结果由DT 获得,其分类成功率达84.48%。文献[11]使用红外光谱仪对玉米种子的红外光谱进行采集,然后将数据预处理后使用核变换提取特征,最后使用不同的特征提取算法建立鉴别模型。结果显示,采用核局部投影的特征提取算法在两组测试集的识别率分别达95.71%和96.43%。
现有研究中,使用传统图像处理[8]或机器学习进行图像分类[9-10]对玉米单倍体种子进行识别的成功率不高,未超过90%。使用核磁共振[7]或红外光谱[11]对玉米单倍体种子的识别率可达90%以上,但核磁共振仪和红外光谱仪设备昂贵,不具备普适性。当前深度学习技术发展迅速,卷积神经网络作为深度学习的一种网络结构,在图像、声音、语音等领域的研究均有很大进展。玉米种子R1-nj 基因的表达会导致花青素沉积使籽粒显深紫色[12],单倍体只在胚乳顶端显示深紫色而二倍体会在胚乳顶端和胚胎都显示深紫色。使用卷积神经网络能够提取单倍体和二倍体玉米种子的不同颜色特征,本文以玉米单倍体和二倍体种子图像为数据集,建立卷积神经网络,进行玉米单倍体种子识别。本文的卷积神经网络将在内核选择性网络(selective kernel networks, SKNet)[13]的基础上加以改进,与DenseNet[14]、ResNet[15]和VGGNet[16]进行性能比较。
1 材料与方法
1.1 数据集描述
本研究所使用数据集为网络公开数据集,该数据集共有3 000 粒玉米种子,包括1 230 个单倍体和1 770 个二倍体。图像中玉米种子放置为4 行5 列共20 粒,胚胎处于向上位置且彼此不接触。所有图像均使用Sony SLT-A58 相机和Sony SAL 100 mm f/2.8 微距镜头拍摄,图像均在“M”模式下拍摄,图像参数为100 ISO、1/125 s 的快门速度、f/9 的光圈、150 mm 焦距和55 cm 的相机距离,图像的最终分辨率为5 459×3 632。
由于每张图像包括20 粒玉米种子,所以最终数据集对原始图像进行图像分割后获得。根据经验选定150 作为阈值将原始图像进行二值化,通过使用玉米种子的轮廓线计算玉米种子的边界框。通过二值图和边界框裁剪每粒玉米种子的图像单独存储,如图1 所示。
图1 裁剪后的玉米种子图像
1.2 数据增强
数据增强是一种正则化技术,用以增加数据量和数据的多样性[17]。常用数据增强方法包括旋转、翻转、缩放、裁剪、位移、高斯噪声等。原数据集包含3 000 粒玉米种子的图像,每粒种子单独保存为一幅图像,即一共3 000 幅图像。对原始数据集中的3 000 幅图像进行数据增强,数据增强方式选择旋转和翻转,其中旋转包括旋转90°、180°和270°。通过数据增强把数据集数量扩充至15 000 张。
1.3 卷积神经网络
卷积神经网络是一种深度学习网络架构,该网络由一些连续的层组成,不同的层具有不同的功能,如卷积层、池化层、Dropout 和全连接层等。卷积层是卷积神经网络的最基本层,通过卷积核与输入特征图进行卷积运算,抽取特征图蕴藏的抽象特征。为降低运算复杂度和防止过拟合,卷积层后紧跟池化层,简化特征图的信息维度,常用池化方式包括平均池化、L2 范数池化和最大池化,其中最大池化因其速度快和收敛性好而被广泛使用[18]。卷积神经网络通常设置全连接层,将图像空间分布的特征映射到样本标签空间,通过softmax 输出类别概率并实现分类。
VGG 是一个被广泛使用的卷积神经网络,主要研究卷积神经网络的深度对大规模图像识别的精度影响[16],该模型将卷积神经网络的深度加到16~19 层,获得了显著的性能提升。
ResNet 模型采用残差学习简化网络训练[15],模型的核心问题是网络的退化问题[19]。网络退化是指网络的训练精度随着网络深度的增加而趋于饱和,如果继续增加深度,训练精度反而会下降。网络退化的原因是随着网络深度的增加,梯度在传递的过程中逐渐消失。由于卷积神经网络中采用非线性激活函数,从输入到输出的过程几乎不可逆,造成许多信息损失。ResNet 通过恒等映射,把输入的结果传递到输出让深层网络至少保持浅层网络的水平,使得网络的深度获得大幅提升。
DenseNet 借鉴ResNet 的思想将网络分为多块,每块中的网络均与后续每层连接,则拥有L层的块包括L(L+1)/2 个连接。DenseNet 网络减轻梯度消失问题,加强特征传播,鼓励特征重用,显著减少了参数数量[14]。
2 ECA-SKNet 模型
2.1 搭建SKNet 模型
SKNet 是一个轻量级的嵌入式模块,其关键是选择性内核单元(selective kernel, SK)的构建块,使用基于softmax 的注意力机制融合具有不同卷积核大小的多个分支[13],对这些分支的不同注意力会产生不同大小的融合层神经元有效感受野。在SK 卷积的前后分别加上一个1×1 卷积,即可构成选择性内核单元,将多个SK 构建块堆叠而构建的网络称为SKNet。在SK 构建块中,需对3 个重要超参数进行设置:SK 构建块需融合的分支数M,每个分支的分组卷积的分组数G,融合操作中全连接的压缩系数r。图2 为SKNet 的核心模块,该模块分为3 个部分:分离、融合和选择。

图2 SKNet 的核心模块
1)分离:输入特征X经过两个具有不同大小的卷积核分支,卷积获得特征图U˜ 和特征图Uˆ。
2)融合:不同分支的特征图对应元素相加,融合成特征图U,然后对特征图U使用全局平均池化[19],全局平均池化后特征图大小从h×w变为1×1,可理解为特征图从三维转换为一维。紧接着对一维向量进行全连接操作再进行降维,使一维向量的通道数量从C降低到d,d=max(C/r,dmin),其中dmin表示d的最小值,改变r即可改变d的大小。
3)选择:对降维的向量再进行升维,把通道数增加到特征图U˜ 和特征图Uˆ 的通道数量,然后对向量使用softmax 获得a、b两个权重矩阵,使用权重矩阵对特征图U˜ 和特征图Uˆ进行加权操作可自适应地选取合适的特征图。
2.2 SKNet 模型结构改进
SKNet 使用注意力机制改善网络性能,不可避免地会增加网络的计算复杂度。虽然在SKNet 中使用先降维再升维的操作会降低复杂度,但由于该操作中使用全连接,网络的参数量依然庞大。此外,避免降维操作对学习通道注意力非常重要,适当的跨通道交互可显著降低模型复杂性的同时保持模型性能,ECA-Net 采用一维卷积生成通道权重以避免捕获所有通道依赖关系导致的低效性[20]。
本文提出一个高效通道注意力(efficient channel attention, ECA)模块替换SKNet 中的全连接层。在SKNet 的基础上进行变更,对SKNet 中先降维再升维的操作进行替换,实现一种不降维的局部跨通道交互策略。一维卷积能以极轻量级的方式捕获每个通道及其k个邻居的局部跨通道交互,故采用一维卷积替换SKNet 的全连接层,如图3 所示。ECA模块用于减少全连接层的计算参数量,通过ECA模块获得网络分支数对应个数的权重矩阵用于选择合适的特征图,可进一步降低网络参数数量,同时提升性能,将改进后的SKNet 称为ECA-SKNet。
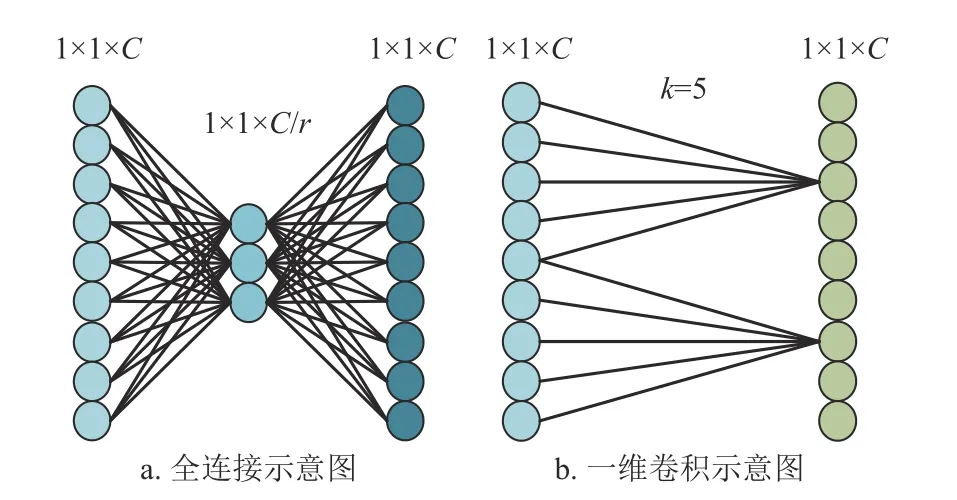
图3 全连接替换为一维卷积
3 实验与结果分析
3.1 实验设置
本实验的硬件环境为:Intel(R) Core(TM) i5-9300H 2.4 GHz 处理器、16 GB 内存、NVIDIA GeForce GTX 1660Ti 6 GB 显存显卡。使用的系统为Windows 10,使用PyTorch 深度学习框架进行卷积神经网络的构建和训练。实验采用VGG、ResNet、DenseNet、SKNet 和ECA-SKNet进行训练,实验的超参数设置见表1。训练批量大小为16,训练周期为100,训练初始学习率为0.001,学习率每经过30 个周期缩小到原来的0.1 倍,优化器使用adam 优化器,损失函数使用交叉熵损失函数。实验所使用的评价指标为准确率(accuracy)、精确率(precision)、召回率(recall)和F1 分数(F1 Score),计算公式分别为:

表1 实验超参数设置
式中,TP 表示正确识别单倍体的数量;TN 表示正确识别二倍体的数量;FP 表示不正确识别单倍体的数量;FN 表示不正确识别二倍体的数量。
3.2 实验结果与分析
1)最优模型的确定
将玉米种子数据集按7:3 的比例随机划分为训练集和验证集对VGG、ResNet、DenseNet、SKNet和ECA-SKNet 进行训练,训练超参数使用表1 中的设置,对于SKNet 和ECA-SKNet 的其他超参数,使用默认设置。各模型的训练准确率、训练损失、验证准确率、验证损失如图4 所示,实验结果如表2 所示。

表2 不同模型的训练结果 %

图4 不同模型的训练准确率、验证准确率、训练损失和验证损失
由表2 可知,实验模型对单倍体和二倍体玉米种子的分类精度达88%以上,其中VGG、SKNet和ECA_SKNet 的分类精度达90%以上。表2 的4 个验证指标中,准确率为最重要指标,因为其表示该模型对单倍体玉米种子的筛选精度。可见,SKNet的实验结果为第二优结果,ECA-SKNet 在准确率、精确率、和F1 分数3 项评价指标上均取得最好结果。
实验结果表明,ECA-SKNet 在对单倍体和二倍体玉米种子图像分类上具有较好效果,验证了ECA 模块在避免降维和局部跨通道交互对学习通道注意的影响,即SKNet 的改进能够进一步提升分类效果,故选定ECA-SKNet 作为后续实验的模型。
图5 是ECA_SKNet 模型在中间层提取出的特征图及其对应的原图。可见,ECA_SKNet 关注玉米种子胚乳和胚胎的颜色特征。
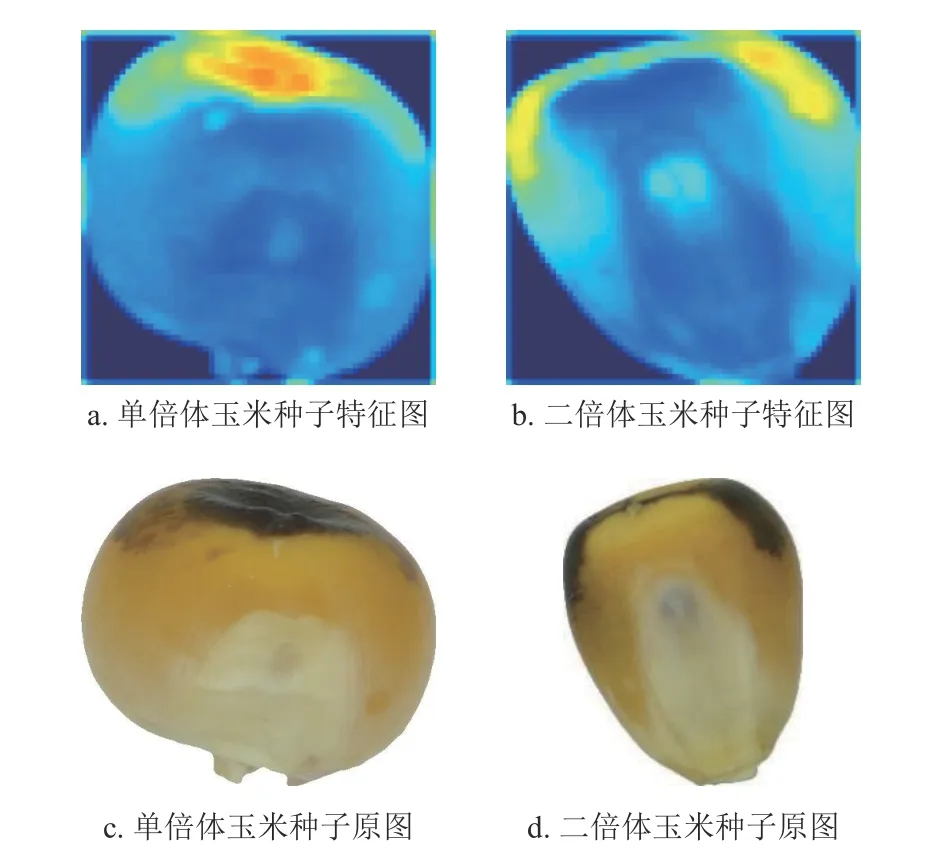
图5 ECA-SKNet 模型输出的玉米种子和原图像比较
2) ECA-SKNet 的超参数调优
SKNet 中使用分组卷积降低网络参数数量,ECA-SKNet 也使用分组卷积。ECA-SKNet 默认的分组卷积的组数为32,分别对组数为32、64 和128 的网络进行对比实验,实验结果如表3 所示。
由表3 可知,当分组数为64 时,准确率为93.04%,精确率为92.70%,召回率为90.10%,F1 分数为91.40%。分组卷积在相同的FLOPs 下,分组数越大,通道上的密集卷积越稀疏,ECA 模块可实现通道间信息的交互,促进模型精度增加。其中,分组数为64 时在准确率、精确率和F1 分数都获得最优结果,表明此模型对玉米种子的特征能进行更有效的提取和区分。
SKNet 使用多分支进行自适应的特征选取,如图2 所示为2 分支的结构,在分组数为64 的基础上,对分支数为2、3、4 的ECA-SKNet 进行对比试验,实验结果见表4。
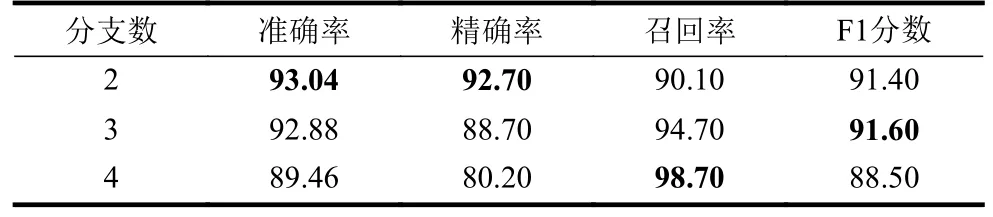
表4 ECA-SKNet 不同分支数的训练结果 %
由表4 可知,当分支数为2 时,准确率和精确率为最优结果。当分支数为3 时准确率和精确率相较于分支数为2 的模型略微下降,但F1 分数为最优。当分支数为4 时,准确率下降明显,模型效果与ResNet 相当。
4 结 束 语
本文使用卷积神经网络对单倍体和二倍体玉米种子进行分类识别,对比了不同卷积神经网络对单倍体和二倍体玉米种子进行分类的效果,从中选出最优模型并进行超参数的调优,获得以下结论。
1)在VGG、ResNet、DenseNet、SKNet 和本文改进的ECA-SKNet 中,ECA-SKNet 获得了最优结果。在未调优前ECA-SKNet 获得91.38%的验证准确率。
2) ECA-SKNet 使用分组数为64 的模型能获得较大的性能提升,相比于默认32 分组数量的模型准确率提高1.66%。分支数为2 和3 的模型性能相差不大,分支数为2 的模型准确率和精确率较高,分支数为3 的模型F1 分数较高。
3)本文使用ECA-SKNet 对单倍体和二倍体玉米种子进行分类的准确率达93.04%,为本研究中的最优结果。
