基于多阶段空间视觉线索和主动定位偏移的胰腺分割框架
2023-12-06李嘉铭任书敏姬明昊句建国王和旭
李嘉铭, 折 娇, 任书敏, 姬明昊, 句建国*, 王和旭
(1.西北大学 信息科学与技术学院, 陕西 西安 710127; 2.西京学院 西安市智能康复人机共融与控制技术重点实验室, 陕西 西安 710123)
0 引言
2020年国际癌症研究机构[1]提供的数据显示,胰腺癌造成的死亡数约为466 000而当年的病例数约为496 000,两者几乎一致,在因癌症死亡人数中排名第7.更糟糕的是,一项对28个欧洲国家的调查显示,到2025年,胰腺癌将超过乳腺癌,成为癌症死亡人数排名第3.胰腺癌早期及时进行干预并开始治疗,可以防止疾病进一步发展,提高生存率.从计算机断层扫描(Computed Tomography,CT)中分割胰腺或胰腺肿瘤在临床医生的准确诊断和制定手术方案过程中起着至关重要的作用.在目前的临床实践中,器官或肿瘤是由专业的临床医生从CT扫描中人工分割出来的,这不仅需要丰富的专业经验,而且耗时耗力且易受主观因素影响,有时甚至不同临床专家之间的观察也存在较大的差异.因此,亟需智能器官或肿瘤分割方法来减轻医生大量的繁琐临床工作,并消除医生的主观因素干扰.
目前,已经有许多工作致力于智能器官或肿瘤分割,以优化计算机辅助诊断(Computer-Aided Diagnosis,CAD)的应用环境[2].具体来说,深度卷积神经网络(Deep Convolutional Neural Networks,DCNNs)在脑[3]、心脏、肝脏[4]、肺[5]等智能医学图像分割方面取得了很大的进展,但这些方法大多是为形状较为规则且面积较大的器官或病变而设计的特定算法.一些器官,如胰腺及其病变(如图1 (c)、(f)所示)体积较小,具有高度解剖变异性.这些小目标(例如,胰腺和胰腺肿瘤)的分割仍然是最具挑战性的任务之一.为了在实践中解决这一挑战,一些研究人员采用3D神经网络来处理胰腺分割问题[6,7].虽然3D卷积可以更好地挖掘高维空间中的语义信息,并学习更有效的特征表示,但它需要花费大量的计算和内存,限制了网络训练和测试策略并阻碍了他们进一步的临床应用和精度的提升.
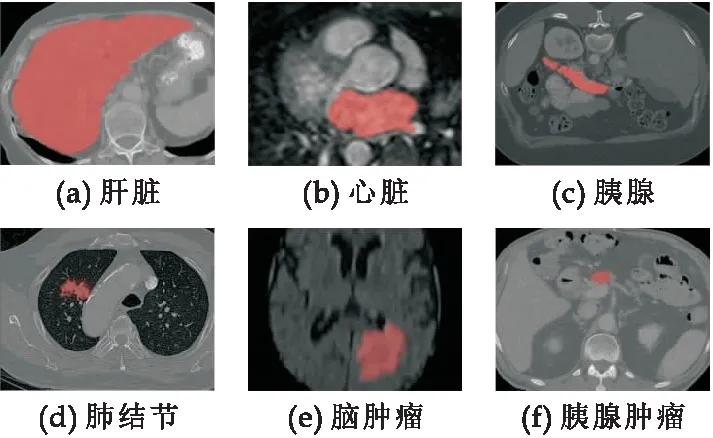
图1 器官和病灶的示意图
2D神经网络[8]无法学习胰腺(或胰腺肿瘤)CT切片序列之间的上下文信息,在一些实践中表现出相较于3D网络略差的结果.为了在不增加额外计算负担的情况下捕获空间上下文信息,有研究者提出了一种新的替代模型,即伪3D方法[9,10],该方法将堆叠的相邻切片作为模型输入,输出中心切片的预测结果.虽然伪三维可以捕获某些高维信息,但文献[11]通过在多个数据集上进行测试表明这种方法带来的提升非常有限而且不稳定.胰腺(或胰腺肿瘤)的智能分割仍有一些局限性有待进一步改进.如图1(c)所示,胰腺的区域较小,与周围背景的强度和纹理相似,因此容易混淆模型学习,使其无法准确的预测出边界.此外,胰腺的大小以及在患者腹腔内的位置在解剖学中表现出高度的可变性,且胰腺的形状和外观在不同个体之间具有很大的差异.这促使研究人员提出一类从粗到细的分割框架[12-14],这类框架包括两个阶段,其中粗分割阶段提供一个粗糙的定位或部分目标像素,而细分割阶段执行目标分割.尽管该框架展现出了比单阶段网络更高的精度,但是细分割阶段的输入往往会对最后的精度产生较大影响.这是因为:(1)大多数方法最终的分割结果高度依赖粗分割的定位结果;(2)细分割阶段无法学习到全局的上下文信息,因为细分割阶段的输入是依据粗分割网络预测结果裁剪后的一个较小的区域;(3)细分割网络由于从更小的输入区域进行分割,在减小了问题复杂度的同时也带来了过拟合的风险.
因此,本文提出了一种新的神经网络框架来解决以上问题,本文设计了转换函数和一个主动定位偏移(Active Localization Offset,ALOT)模块.与之前的工作[15]不同的是,转换函数融合视觉线索并将其转化为空间权重图.该函数通过全监督的方式参与网络训练,生成较为平滑的空间权重图来初始化细分割网络的输入,以防止细分割网络的关注区域受限.并且,受主动学习的启发,ALOT在粗阶段迭代中自适应学习定位偏移策略,从而使细分割阶段具有信息性更强的输入和更精细的分割结果.本文的主要贡献可以总结如下:
(1)本文提出了一个转换函数,在保证整体网络语义连通性的同时指导网络融合视觉特征线索,生成更平滑的空间权重图,为细分割阶段的输入提供良好的初始化.
(2)本文提出一个定位偏移模块,该模块在粗分割网络迭代过程中学习偏移策略来动态调整定位结果.自适应地增加了细分割阶段目标周围的语义信息,同时降低了细分割阶段过拟合情况.
1 本文提出的方法
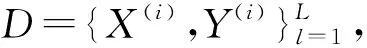
1.1 网络框架
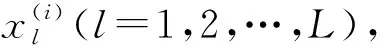
(1)
式(1)中:Fcoar和Ffine分别代表粗分割网络和细分割网络,Crop是自定义的裁剪函数用于生成细分割的输入.本文的主要创新是转换函数和主动定位偏移模块(整体记为Ω),通过转换函数融合视觉信息并且转换为空间权重图来为细分割网络提供良好的初始化,同时可以使两个网络进行联合优化.主动定位偏移模块从粗分割迭代过程中学习到偏移向量来指导生成裁剪区域,可以在增加目标周围语义信息的同时减轻细分割网络过拟合的问题.本文设计的这两个模块可以被应用到大部分由粗到细的神经网络结构以提供更高的识别性能,网络框架如图2所示.具体细节将在下面的章节详细描述.
1.2 转换函数设计
基于之前的工作[12,15],细分割阶段的分割结果直接依赖于粗分割阶段的输出.虽然直接根据粗分割结果进行裁剪,一定程度上减少了冗余背景的干扰,提供了定位信息.但是粗分割网络只提供了定位功能,忽略了像素级的上下文语义信息.这有时会导致网络的收敛不令人满意,甚至有时细分割网络的精度会低于粗分割网络.因此,本文提出一个转换函数来融合视觉线索并转换为空间权重图来更新输入数据.整体过程可以表示为:
(2)
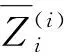
1.3 主动定位偏移模块
根据1.2小节,细分割网络可以在排除了大部分背景干扰后的小区域进行分割,但同时也有过拟合的风险.之前的方法[12,15]为了防止网络过拟合,在裁剪时随机添加1~60和20个像素来解决这个问题.然而,这在训练时可能会导致裁剪后目标区域保留不完整,为了可以使细分割阶段得到一个有效的输入,有必要设置一个策略以获得更为合理的输入区域.因此,本文的另一个主要创新是提出一个主动定位偏移模块(ALOT)来学习偏移向量指导生成细分割网络的输入数据.如算法1中3~7行的描述,通过迭代的执行粗分割阶段以获得若干张概率图Pj,j={1,2,…,T}.受到主动学习策略的启发,该模块通过计算KL(Kullback-Leibler)散度来找到与平均分割概率图分布差异最小的一个,之后利用一个共享的自控机制来学习生成位置偏移向量.如图3所示,具体过程可描述为:
(3)
(4)
r=J[v(Pc)‖v(Pkl)]
(5)
式(5)中:v(·)是自定义的定位函数,该函数根据概率图寻找最小包围盒的左上顶点坐标、包围盒的宽度和高度以及预测目标的质心.J[·‖·]可以被看做是共享卷积核,‖表示堆叠操作.根据偏移向量r,本文设计了一个剪裁函数,Crop(·,Po,r)其中,Po作为参考图像,并将其二值化Zo=(Po≥0.5),找到覆盖所有激活像素的最小矩形,然后根据偏移向量生成一个新的裁剪区域.整个过程可描述为:
(6)
DSC Loss[15]是用于分割任务广泛使用的损失函数,当感兴趣的对象仅占输入图像数据的非常小一部分时,它能够定位对象的主要部分,但是它难以获得精细的对象形状,根据现有的工作[11],本文采用DSC Loss和BCE Loss对每个阶段进行训练:
(7)
整体损失函数为:
(8)
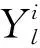
算法1网络训练阶段算法
输入:沿纵轴方向的2D切片Xl,l∈{1,2,…,L},L是该组CT的切片数量.最大迭代次数T
1)t←0,Y0←Xl
2)Pc←Fcoar(Y0)
3)循环
4)Yt←Xl·g[Pc;η]
5)Plist[t]←Fcoar(Yt)
6)t←t+1
7)untilt=T
10)r←J[v(Pc)‖v(Pkl)]
11)P←Ffine(crop(Xl·g[Pc;η],Pc,r))
12)返回:Z=B(P≥0.5)
2 实验结果与分析
2.1 数据集和评价指标

2.2 实现细节
本文提出的框架基于开源的深度学习框架PyTorch编码实现,并在型号为Nvidia GTX 3080的显卡上训练该框架,并使用RMSProp优化器,学习速率为1e-5,权重衰减为1e-7,学习动量为0.9.在训练期间并没有执行过多的数据增强操作,仅以75%的概率水平或垂直翻转切片.由于该框架使用单通道图像作为框架输入,并且没有合适的自然图像数据集进行预训练,所以训练方案是从头开始的,但框架仍然可以快速收敛.框架使用U-net[18]作为粗分割阶段和细分割阶段网络的主干网络,并去掉了最后一层下采样.制作标签部分,设置p=0.64,q=0.53.在损失函数部分,设置μ=1/3,Lcu中α=2/3,β=1/3,Lfu中α=1/3,β=2/3,以此来鼓励粗分割网络进行小前景定位的同时不要忽略边缘细节和细分割网络做出更精确的分割.
2.3 NIH数据集
为了证明本文提出的方法优于现有方法,本文在NIH数据集上对现有方法(一阶段方法[16,19-21]和两阶段方法[12,15,22-24])进行测试.如表1所示,一阶段方法和两阶段方法由虚线隔开,用粗体突出显示最佳结果,“/”表示基线方法没有提供相应的结果.以DSC作为评价指标来衡量不同方法的性能.首先可以看出现有方法平均DSC非常接近,这表明NIH胰腺数据集上的分割任务非常具有挑战性.

表1 不同方法在NIH胰腺分割数据集上的准确性比较(DSC,%)
与单阶段方法相比,两阶段方法的性能普遍较为优秀.与基线方法相比,本文提出的框架所需的计算时间大约只是基线方法的1/3,但框架平均DSC比之前的最佳方法[23]高出0.25%,而最低DSC略低于基线方法[14].一个可能的原因是,本文提出的框架为了节省计算时间,既没有采用伪3d策略,也没有在精细阶段迭代细化分割结果,导致只有微小前景目标的单个切片分割性能较差.
为了定量比较转换函数和ALOT模块的有效性,本文进行了消融实验.首先将转换函数和ALOT模块分别与基线方法融合,改进后的框架的平均DSC值分别达到了84.63%和84.94%,均有一定程度的改进.进一步验证了转换函数融合了上下文信息,有效的对细分割网络提供了指导从而提高了精细阶段的性能.更重要的是,将原始图像标注为边界框来训练和测试U-net(这并不能在实践中应用,只是为了测试了模型的上界).最终的平均DSC达到86.48%,而ALOT达到84.94%,相比基线方法高出0.44%,略低于86.48%.这表明,本文提出的ALOT模块在一定程度上缓解了网络的过拟合,提高了分割性能.图4直观地展示了视觉分割的结果,并与其他方法进行了比较.从视觉效果来看,本文提出的框架实现了更精细的分割边缘.进一步验证了通过这两个模块学习空间上下文和定位信息,有效的提高了框架的分割性能.

图4 不同方法胰腺分割结果对比图(蓝、红、绿分别表示预测区域、标签和重叠区域)
2.4 MSD数据集
为了证明本文提出方法的泛化性,进一步在MSD数据集上进行了胰腺肿瘤分割.现有研究中关于胰腺肿瘤分割的报道较少,这也反映了这项任务的难度.在表2中,本文提出的方法在精度方面与现有的方法进行了对比.相比于最好的方法,本文提出的方法平均DSC提升了0.5%.可视化结果如图5所示.显然本文提出的框架获得了更好的DSC分数和更精细的分割边缘.
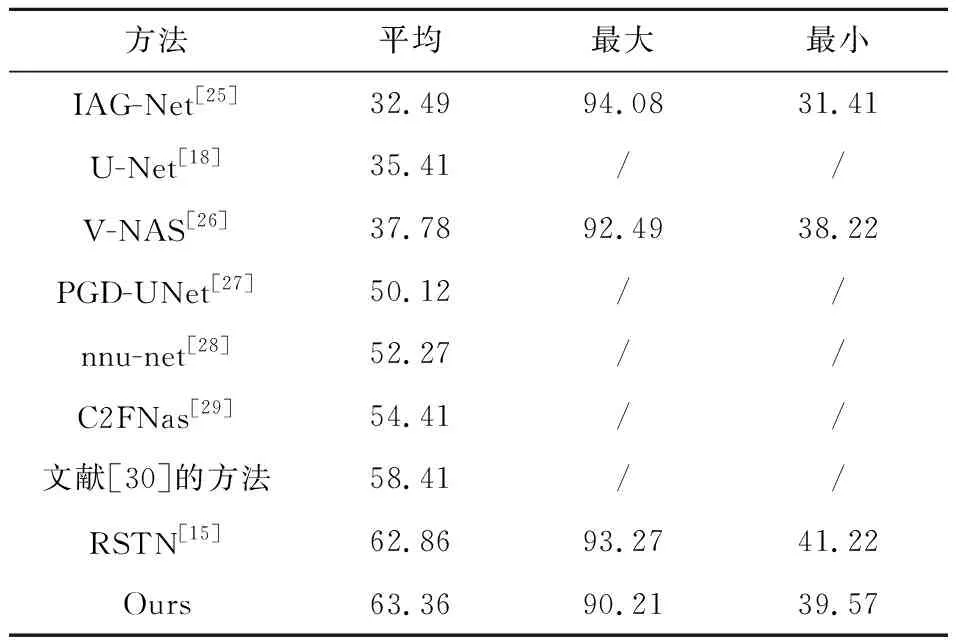
表2 不同方法在MSD 胰腺肿瘤分割数据集上的准确性比较(DSC,%)

图5 不同方法胰腺肿瘤分割结果对比图(蓝、红、绿分别表示预测区域、标签和重叠区域)
3 结论
本文工作的动机是医学影像中小器官由于类别失衡、对比度差、边界模糊而导致的分割困难.本文基于从粗到细的方案,提出了转换函数和ALOT.转换函数通过融合视觉线索并转换为空间权重图来更新输入数据,ALOT在粗分割迭代过程中动态的调整定位结果.这两个模块共同优化粗阶段的结果,为精细阶段提供高质量的输入,从而实现更精细的分割结果.本文提出的框架应用于两个数据集(NIH和MSD)的胰腺分割和胰腺肿瘤分割,并在一定程度上优于现有的方法.本文的策略可以为小目标或少量数据的任务提供一些新的思路,未来将继续进一步研究如何利用主动学习理论的优势对框架进行优化.
