基于Transformer的面部动画生成
2023-12-06豆子闻李文书
豆子闻, 李文书
(浙江理工大学计算机科学与技术学院, 浙江 杭州 310018)
0 引言(Introduction)
在过去的几年里,数字人类引起了广泛关注,它们以高度逼真的方式模拟真实人类,现已被应用于各个领域,比如游戏中的虚拟化身、电影中的角色等[1]。VR设备的普及,使数字人类被更广泛地应用于虚拟现实场景中,这些数字人通过附着于用户各个关节的传感器联合驱动,能够实时模拟现实中真人的动作,但是对于面部的表情,只能通过面捕设备的摄像头捕捉,其不仅操作不便,更会因为遮挡等原因导致无法跟踪。
在过去的研究中,英伟达(NVIDIA)公司发布的唇音同步算法Audio2Face基于深度卷积神经网络,主要集中在学习短音频窗口的音素级特征,偶尔会导致嘴唇运动不准确[2]。TIAN等[3]采用两个双向长短时记忆网络(Bidirectional LSTM),将音频特征作为输入提取高级语义信息,并输出到注意力层学习注意力权重。这种结构使网络能够记住以往的音频特征,并可鉴别对当前动画帧产生影响的音频特征,但是LSTM作为顺序模型仍然存在瓶颈,在有效学习音频数据中跨足够长的时间间隔提取相关信息的能力不足。
Transformer在自然语言处理和计算机视觉任务中都取得了卓越的表现[4]。研究人员在音频特征的提取方面,加入循环卷积和注意力机制,使得输入不再局限于短时特征,并且显著提高了特征精度。受线性偏差注意力的启发,研究人员在查询键注意力评分中添加了时间偏差,并设计了周期性位置编码策略,以提高模型对较长音频序列的泛化能力。在本文研究中,主要关注三维模型上的面部动画,而三维人脸的复现主要分为基于语言的方法和基于学习的方法[5]。
1 相关理论(Related theory)
1.1 唇音同步
基于语言学的方法通常在音素和视觉对应物之间建立一套复杂的映射规则,即视觉语音音素(Visemes)。Visemes用于表示人类口型和面部表情的视觉表示,它们对应于发音时嘴巴的不同形状,在计算机图形学、动画和虚拟现实领域有着广泛的应用,尤其是在语音同步(Lip-Sync)动画中。
也有一些方法考虑了音素和音素之间的多对多映射关系[6]。例如,基于心理语言学的考虑,在面部动作编码系统的基础上,将嘴巴运动音素纳入嘴唇和绑定后的下巴动画,可以产生良好的联合发音效果。唇音同步的理论基于对音频的分解,从每段音素中提取梅尔频谱,得到独立的音素级特征。
1.2 Transformer
Transformer基于encoder-decoder进行架构,使用了自注意力机制(Self-Attention)捕捉序列中任意两个位置之间的依赖关系,解决了长期依赖问题。通过多头注意力机制(Multi-Head Attention)同时关注不同位置和不同语义的信息[7]。整体由多个Encoder和Decoder层堆叠在一起,每一层都包含Self-Attention和Feed Forward Neural Network。每个Encoder和Decoder层都接收整个句子所有的词作为输入,然后为句子中的每个词都做出一个输出。Transformer的机制使得它相较于RNN和CNN每层计算复杂度更优,并且可直接计算点乘结果,不用考虑序列的顺序,可以进行并行处理。在自然语言处理(NLP)和计算机视觉(CV)领域都应用广泛。
1.3 Wav2Vec2.0
Wav2Vec2.0相比Wav2Vec,使用Transformer代替RNN,同时引用了一个乘积量化的操作,使得语音表示更加紧凑或离散[8];其通过对比学习进行自监督学习,首先使用一个卷积神经网络将原始音频信号编码成一个连续的隐层表示,其次使用一个量化模块将这个表示转换成一个离散的潜在表示,最后使用一个Transformer网络捕捉这个潜在表示的上下文信息。Wav2Vec2.0在训练过程中会随机地掩盖一些潜在表示,然后让Transformer网络预测被掩盖的部分,这样就可以学习到语音信号中有用的结构和模式。
2 本文所提方法(The proposed method)
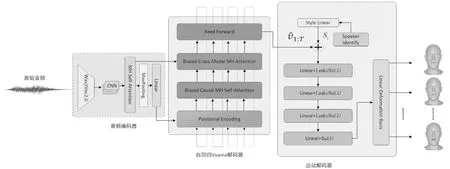
图1 唇音同步模型流程图Fig.1 Flow chart of labial synchronization model
2.1 音频编码器
在编码器的设计方面,研究人员参考了最先进的运动合成模型,使用广义语音模型Wav2Vec2.0编码音频输入。编码器以自监督和半监督的方式训练模型,通过使用对比损失预测当前输入语音的近期未来值,使模型能够从大量未标记的数据中学习。
Wav2Vec2.0接受原始音频信号作为输入,然后在不用手动标注的情况下学习音频特征表示,对原始音频的潜在表示进行建模。Wav2Vec2.0的输出序列是一组潜在向量,这些向量表示输入音频信号的时间结构特征。每个潜在向量都对应输入音频的一小段时间。在音频特征提取阶段,使用一维卷积处理具有时间顺序的数据,它可以捕捉局部特征并保留输入数据的顺序结构,并且在计算方面更加高效,适用于处理大规模数据。一维卷积层的参数如表1所示。

表1 一维卷积层参数
为了捕捉序列中的全局依赖关系,将多头自注意力机制应用于输出序列,在Transformer编码器层中,输入序列首先经过多头自注意力子层,其次通过位置前馈网络(Position-wise Feed-Forward Network,FFN)。该输出将作为动作编码器中Biased Cross-Modal MH Attention层的输入。
经过多头自注意力机制处理后,将序列输入后续的池化层和线性映射层,最终结果作为Postional Encoding层的输入。
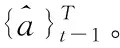
2.2 自回归解码器

(1)
其中,θv为Transformer的可学习参数。
与产生离散文本的传统神经机器翻译(NMT)架构相比,本文研究的输出表示是一个连续的向量。NMT模型使用一个开始和结束的标记指示序列的开始和结束。在推理过程中,NMT模型自回归地生成标记,直到结束。研究人员在输入特征时进行Linear操作,在开始处包含输入信息。然而,由于序列长度T是由音频输入的长度给出的,所以不适用于结束标记。通常将编码时间添加到序列中的Viseme特征中,将时间信息注入序列中。将位置编码的中间表示表述为
(2)
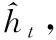
2.3 动作解码器
3 实验与结果(Experiment and result)
3.1 实验数据集
研究人员使用公开的3D数据集BIWI对本文中的面部动画生成模型进行训练和测试。该数据集提供了英语口语的音频-3D扫描对。BIWI包含40个独特的句子,该40个句子覆盖了常用的发音口型,适用于所有说话者。
BIWI数据集是一个包含情感语音和相应的密集动态三维人脸几何的语料库。14名受试者被要求阅读40个英语句子,每个句子分别在中性或情绪化的语境中被录下两次。3D面部几何图形以25 fps的速度捕获,每个图形有23 379个顶点。每个片段平均时长为4.67 s。实验中使用了在情感语境中记录句子的子集。具体来说,将数据分为6名受试者共说192句话的训练集(BIWI-Train),每名受试者说32句话,以及两个测试集(BIWI-Test-A和BIWI-Test-B)。BIWI-Test-A包含6个可见的被试者共说的24句话(每人说4句话),BIWI-Test-B包含8个不可见的被试者共说的32句话(每人说4句话)。
3.2 训练细节
训练Transformer编码器、解码器和嵌入块进行跨模态映射。为了从大规模语料库的语音表示学习中受益,使用预先训练好的Wav2vec2.0权重初始化Transformer编码器。
在编码器的第一阶段,选择AdamW作为优化器,其参数如表2所示。

表2 AdamW参数设置
在第二阶段,用Adam优化器训练时间自回归模型,训练时间为100个epoch,其他超参数不变。
3.3 评价结果
使用唇形同步度量评估嘴唇运动的质量。所有唇边顶点的最大误差定义为每一帧的唇型误差。误差是通过比较预测和捕获的三维人脸几何数据计算得来的。表3统计了使用MeshTalk[9]、FaceFormer[10]和本文方法得出的唇形顶点误差比较结果。

表3 唇形顶点误差率比较
3.4 相关方法之间的结果比较
人类的感知系统能够理解细微的面部动作和捕捉唇形同步。因此,在语音驱动的面部动画任务中,人类的感知仍然是一个最可靠的度量。本文进行了一项用户调查研究,并与MeshTalk、FaceFormer和Ground Truth(GT)进行感知结果比较。采用A/B(两种方法在各种数据上的比值)测试每个比较,即在逼真的面部动画和口型方面与上述方法的比较。对于BIWI,分别从BIWI-test-B中随机选取30个样本,得到四种比较的结果。为了在说话风格方面达到最大的变化,必须确保抽样结果可以相应地涵盖所有的条件反射风格。因此,本文基于BIWI-test-B创建了120对A和B,共30个样本、4个对照。每组由至少3名不同的参赛者分别评判,最终共收集到372组评价结果。表4为模型在测试集BIWI-Test-B上的用户学习结果的对比,分别比较了同步率和真实值,证明本文所提方法相比MeshTalk和FaceFormer有较显著的提升。

表4 在BIWI-Test-B上的感知评价对比
3.5 结果可视化
为了验证算法的效果,以美国前总统奥巴马的一次演讲Obama Delivers Thanksgiving Greeting中的片段作为音频输入用于合成面部动画帧,从音频到面部动画的生成结果如图2所示。
4 结论(Conclusion)
通过使用一维卷积和自注意力机制,本文所提的方法更好地捕捉到了Wave2Vec2.0输出的特征,帮助研究人员在面部动画合成算法中合成高质量的动画。此外,研究人员展示了在离散空间中将语音驱动的面部动画转换为代码查询任务的优势,即显著地提高了对抗跨模态模糊运动的合成质量。实验结果表明,该方法在实现准确的唇形同步和生动的面部表情方面具有优势。
