基于Q学习的智能车间自适应调度方法
2023-12-04蔡静雯马玉敏黎声益
蔡静雯,马玉敏,黎声益,刘 鹃
(同济大学 电子与信息工程学院,上海 201804)
0 引言
近年来,在智能制造背景下,随着定制化程度的提升,产品的生命周期缩短,制造过程中的动态不确定性因素对制造系统性能的影响越来越不容忽视[1],具有适应能力的动态调度方法得到越来越多的关注。其中,智能车间动态不确定环境下的自适应调度方法就是关注点之一[2]。智能车间实现自适应调度的关键在于,系统在环境发生动态变化时,依据科学合理的调度知识在减少人工干预的情况下自主完成调度策略的确定和实施。
以传感技术和物联网技术为基础的智能车间使生产状态数据采集实时可靠[3],数据驱动的调度优化方法成为主流。例如,JUN等[4]为了解决柔性作业车间调度问题,从历史最佳调度方案中学习到在性能和鲁棒性方面表现优异的调度规则;ROSSIT等[5]针对智能制造和工业4.0带来的制造过程分散化和自主性特点,提出基于信息物理融合系统的数据驱动调度体系架构,提高调度决策效率,实现智能制造系统的有序运行。由此可见,数据驱动的调度方法能够充分利用车间生产过程中产生的大量历史数据或仿真数据,从中挖掘出实时可靠的调度知识来指导车间生产运行,从而增加调度策略的实时性、科学性与可行性[6]。
在数据驱动的调度方法中,机器学习算法在应对动态场景下的大规模、高复杂性数据问题上具备优势[7],为解决智能车间生产调度问题提供了有效途径。机器学习算法不需要建立精确的数学模型,通过学习样本数据的内在规律,获取数据的分布式特征,确立从输入到输出的映射关系[8]。从样本数据的组成结构层面分析,机器学习可以分为监督学习算法和强化学习算法[9]。监督学习算法使用具有多维特征的带标签样本进行训练,能够对新样本的标签进行分析与预测[10]。例如,SHAO等[11]为解决车间调度中NP-hard问题,设计了多尺度特征融合卷积神经网络,从动态环境中提取特征,根据特征预测最优策略,该方法可以有效处理复杂调度问题;ZANG等[12]利用卷积变换将生产过程中的不规则数据转换为以调度策略为标签的规则样本数据,用于训练混合深度神经网络调度器,该调度器具有较强的泛化能力,能够解决大规模调度问题。在调度问题中,带标签样本是通过优化处理生成的使调度目标达到最优的样本,即最优样本。样本优化处理过程需要大量人工参与,会产生较高的人力与时间成本,且可能存在最优样本准确度难以保证的问题[13],从而影响调度策略的有效性。强化学习方法不依赖于带标签样本,通过与环境的不断交互试错获取反馈数据,基于最大化奖励反馈不断优化行为策略,能有效解决此问题[14]。例如,WANG等[15]考虑到车间生产环境的动态性和不确定性,提出一种基于聚类和动态搜索的加权Q学习自适应调度算法,通过与环境的直接交互学习最优操作,该方法在不同调度环境下具有良好的适应性。ZHOU等[16]在分布式制造系统中,利用多智能体强化学习方法对多个调度器进行动态协同,该方法有效地提升了调度器的学习和调度效率,同时对突发扰动具有一定的应对能力。ZHAO等[17]针对动态作业车间调度问题建立深度Q网络,将多种启发式调度规则作为动作集合,根据调度期结束时的生产状态确定下一调度期的规则,该方法的泛化性以及对生产性能的优化作用均优于单一启发式调度规则和基于有监督学习的方法。由此可知,强化学习算法通过与环境的自主交互,学习使目标最优化的调度知识,具有强大的自学习能力[18],能够在生产调度过程中最大程度地减少人工干预。
同时,在监督学习中,训练所用的优化样本由历史数据得到,导致学习到的调度知识具有时效性,在应用于环境动态变化的智能车间生产调度问题时,存在失效的可能性,以至于生成的调度决策产生偏差甚至失真,难以实现全生产过程的自适应调度。强化学习基于其交互学习和在线训练特性[19],在获取动态调度知识方面具备优越性。此外,现有的生产调度决策多考虑单一调度规则,其解空间有限,无法涵盖所有决策可能性,存在调度决策对生产目标优化效果不明显的问题,而组合式调度规则综合考虑多个面向不同调度目标的调度规则,能够兼顾多种单一规则的优点,同时提高解空间维度[20]。因此,本文研究了一种基于Q学习的自适应调度方法,该方法通过与智能车间的交互,自主学习与更新能够适应车间动态生产环境的调度知识,同时基于组合式调度规则,在变化的车间生产环境下实时地调整最优调度决策,从而保持对智能车间生产全过程性能指标的持续优化。所提出的自适应调度方法将在MiniFab半导体生产线模型上进行测试,并通过衡量其对综合性能指标以及人力与时间成本的优化效果,来验证该方法的有效性与优越性。
1 智能车间自适应调度解决方案
以物联网为基础的智能车间能实时感知车间生产状态,在此基础上,本文借鉴车间的动态调度框架[21],提出了如图1所示的基于强化学习交互训练机制的智能车间自适应调度解决方案。其中,调度模型是对调度知识进行抽象后的形式化表达,该方案通过学习生产数据内部逻辑与规律,构建适应智能车间调度目标与动态生产环境的调度模型,确立从生产状态到调度决策的映射关系,进而根据调度模型实时指导智能车间最优调度决策的生成与实施。
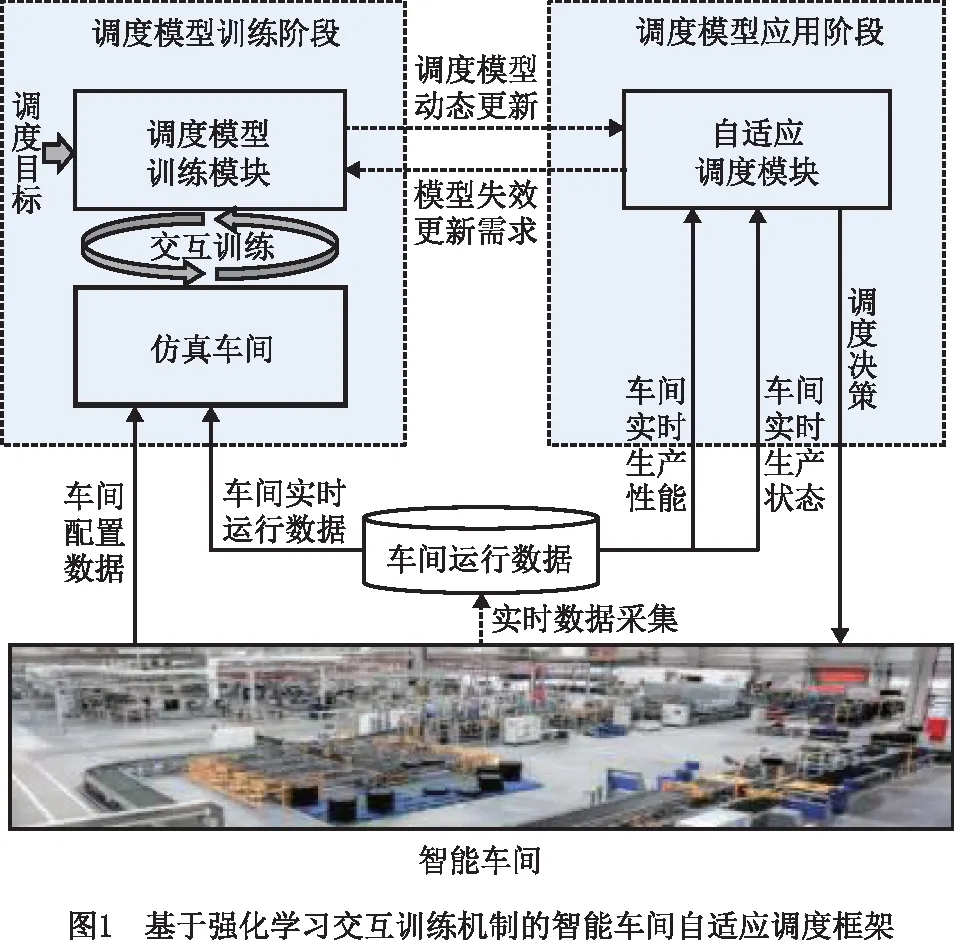
该方案的整体运行框架由多个功能模块组成,包括存储车间历史与实时运行数据的数据池、强化学习交互训练机制所需的仿真车间平台、利用强化学习算法进行模型生成与更新的调度模型训练模块,以及指导车间生产调度的自适应调度模块,各功能模块之间协调配合,共同完成智能车间自适应调度过程。该方案的运行过程分为调度模型训练过程和调度模型应用过程,具体实现如下:
(1)仿真车间构建与更新 根据智能车间配置数据与实时生产数据进行仿真车间模型的构建与更新,用于支撑调度模型训练模块的高效、高重复性迭代训练。仿真车间与真实物理车间运行状态保持一致性、同步性,使得训练生成的调度模型能够有效应用于实际生产车间。
(2)车间数据采集 利用车间传感器实时采集车间运行过程信息,对其进行清洗、合并等预处理操作后形成标准类型的车间运行数据进行存储,同时提供给自适应调度模块和仿真车间。
(3)调度模型训练 调度模型训练模块基于强化学习交互训练机制,结合调度目标和训练算法,通过与仿真车间的在线交互训练,使调度模型始终适应生产环境的变化,保持模型有效性,从而能够根据需求及时更新自适应调度模块,降低更新的迟滞性。
(4)自适应调度 自适应调度模块通过接收当前时刻车间生产状态作为自适应调度模型的输入,输出相应的最优调度决策施加给智能车间,指导下一阶段的车间生产运行,从而实现动态生产环境下的自适应调度决策。同时,将生产性能与调度目标进行周期性对比分析,评估调度模型是否能支持当前车间动态环境下的生产调度,若调度模型失效,则激活调度模型动态更新操作。
上述智能车间自适应调度框架中,自适应调度模块是依据自适应调度模型的指导,根据实时感知到的生产状态变化动态更新调度决策,使调度决策始终保持最优,从而实现动态环境下车间的平稳高效运行。因此,基于强化学习生成与应用合理有效的自适应调度模型是实现智能车间自适应调度过程的关键。
2 基于Q学习算法的自适应调度模型
2.1 基于Q学习算法的调度智能体设计
本文的自适应调度模型由调度模型训练模块生成,应用于自适应调度模块。为了降低训练过程中人工参与优化样本处理过程带来的时间与人力成本,减小模型生成或更新过程的迟滞,保证自适应调度的实时性与准确性,本文采用强化学习算法进行训练。强化学习是一种交互试错式的学习方法,不需要带标签的样本数据,通过与环境的不断交互获得用于训练的数据。实现强化学习需要搭建相应的智能体与环境,智能体用于向环境施加动作,环境则对智能体施加的动作作出反应,如图2所示。
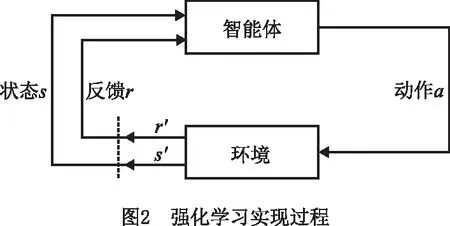
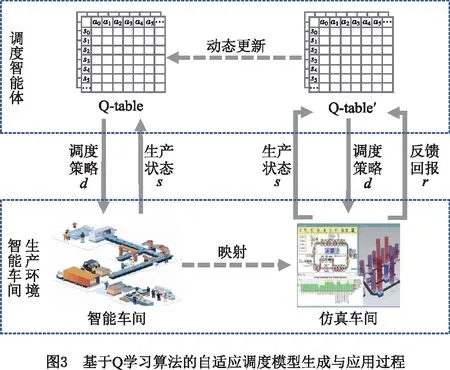
在生产调度问题中,智能体与环境可分别对应于做出调度决策的调度智能体和智能车间生产环境,如图3所示。调度智能体一方面不断向生产环境施加决策动作,另一方面不断接收来自环境的反馈,反馈基于调度目标,可能是惩罚也可能是奖励,调度智能体则根据反馈选择下一步的决策,不断循环上述过程,通过多次迭代探索后获得最大化反馈奖赏的调度模型。
Q学习算法是经典的基于值函数的强化学习方法,是强化学习的基础算法[22]。在生产调度问题应用方面,其主要优点体现为[23]:① 车间调度问题一般为组合优化问题,基于值函数的方法在离散空间模型中具有更好的优化效果;②单步更新的学习过程能够提升调度模型的训练效率,同时模型对于环境的变化更为敏感,有利于最优调度策略的及时调整;③根据不同的策略,支持在线学习与离线学习两种模式,可以学习到历史生产数据中的知识,也可以通过与环境的交互进行在线学习,进而满足调度模型同步训练与实时更新的需求。
Q学习算法将状态S与动作A构建成一张Q-table来存储Q值,采用类似梯度下降的渐进方式逐步靠近目标Q值,减少估计误差造成的影响,Q值计算如下:
Q(s,a)′=Q(s,a)+α(r+γmaxQ(s′,a′)-Q(s,a))。
(1)
式中:α表示学习率,其值大小决定模型训练获得最优解的速度,学习率过大可能会导致错过最优解而使模型无法收敛,反之则会影响训练效率;γ表示折扣率,表示长期决策对当前行为的影响;Q(s,a)表示在某一环境状态s(s∈S)下智能体采取动作a(a∈A)能够获得的收益的期望;r表示环境对智能体动作的反馈;Q(s′,a′)表示环境在当前动作作用下进入的新状态s′(s′∈S)在Q-table中对应的最大期望值,当每个迭代回合结束时不需考虑新的生产状态,此时取Q(s′,a′)=0。
将Q学习算法用于自适应调度问题求解时,s表示智能车间生产状态,a表示调度智能体施加的调度决策d,s′表示车间按照调度决策运行得到的新生产状态,r表示基于调度目标的反馈回报,Q-table即为表征生产状态与调度决策间映射关系的自适应调度模型。
Q学习算法的主要思想是在智能体与环境的交互迭代中不断更新Q-table,最后根据当前状态的Q值选择能够获得收益最大的动作,从而生成最优行动轨迹,据此,基于Q学习算法的自适应调度模型生成与应用过程如图3所示。其中,调度模型的生成过程为,根据智能车间配置数据与实时生产数据搭建或更新仿真车间,以支持调度智能体与环境的不断交互,调度智能体则根据式(1)更新Q-table,通过与仿真车间生产环境的交互试错,学习使奖励最大化的调度决策,该过程对应自适应调度框架中的调度模型训练阶段。调度模型的应用过程为,训练完成的调度智能体基于当前Q-table,在车间生产运行过程中的每个调度点观测生产状态数据,据此选择使调度目标最优化的相应调度决策,该过程对应自适应调度框架中的调度模型应用阶段。
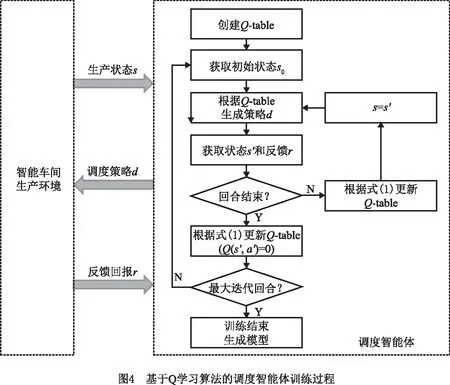
2.2 调度智能体训练过程
自适应调度模型由调度智能体利用Q学习算法训练得到,训练过程如图4所示。
基于Q学习算法的调度智能体具体训练步骤如下:
步骤1调度智能体依据环境特征与调度目标,选定车间生产状态维度和决策维度,建立n×m的矩阵Q-table,初始化为零矩阵。
步骤2从智能车间生产环境中观测初始生产状态s0;
步骤3根据贪心算法ε-greedy在Q-table中选择对应的动作a(即调度决策d)施加于环境,观测运行后的新状态s′,并计算实际生产性能与目标性能之间的偏差,得到奖励反馈或惩罚反馈。其中,ε-greedy贪心算法基于概率对探索和利用进行折衷,即以探索率的概率ε进行探索,以1-ε的概率进行利用,防止陷入局部最优解,基于此,设计式(2)所示的动作a作出决策:
(2)
其中rand=random[0,1]。
步骤4根据式(1)更新Q-table。
步骤5判断该回合训练是否结束,若结束,则进入下一训练回合,重复执行步骤2~步骤4;若没有结束,则重复步骤3~步骤4继续训练。
步骤6达到预设最大训练回合数,总奖励值收敛则智能体训练完成,生成自适应调度模型Q-table。
基于Q学习的调度智能体训练过程算法如下:
算法1基于Q学习的调度智能体训练算法。
参数:学习率α、折扣率γ、探索率ε
初始化Q-table(Q(s,a))=0,∀s∈S,a∈A)
Repeat (for each episode):
观测初始状态
Repeat (for each step of episode):
使用贪心算法ε-greedy从Q-table中选择动作a(决策d)
对环境施加动作a,并观测反馈r和新状态s′
根据式(1)更新Q(s,a)

Until 所有步骤结束
Until 所有回合结束
输出Q-table
将利用Q学习算法训练得到的调度模型应用于车间自适应调度框架(如图1)中的自适应调度模块,调度模型在每个调度决策点根据获取到的实时车间生产状态数据,选择使目标最优的调度决策指导整个调度周期车间的生产运行。此外,在生产环境发生较大变动或调度目标改变导致调度模型失效时,调度智能体根据当前生产需求更新自适应调度模块的调度模型,以适应新的生产状况。
3 实验
为验证本文中所提出的基于Q学习的智能车间自适应调度方法的有效性,该方法在基于经典半导体生产车间MiniFab[24]模型搭建的半导体智慧制造单元上进行验证,如图5所示。该制造单元包含5台设备(3个设备群)、3个缓冲区和3种加工产品,用于构造仿真车间的软件平台选用西门子的Tecnomatix Plant Simulation。
3.1 实验设计
3.1.1 数据结构设置
本文所设计的调度智能体通过不断向生产环境施加调度决策,并观测环境的生产状态变化和相应的反馈回报来训练自适应调度模型。因此,本实验需要设计合适的数据结构以提升交互学习的效率,包括智能车间生产状态S、调度决策D和回报函数R。
(1)生产状态S生产状态选取扩散区、离子注入区、光刻区中3种产品P_a、P_b、P_c的在制品数。车间的日投料数量设置为在[5,7]区间内均匀分布。为了得到涵盖多种生产状态的数据,本实验在随机调度规则下运行仿真车间模型,获得600组生产状态数据,并对原始状态数据进行编码,即对每一类在制品按照数据量均等的原则划分区间,将其转换为适合模型训练的状态数据。
根据表1的划分依据,本实验可将原始生产状态编码为8 748种类型,即调度模型Q-table的生产状态维度n=8 748。
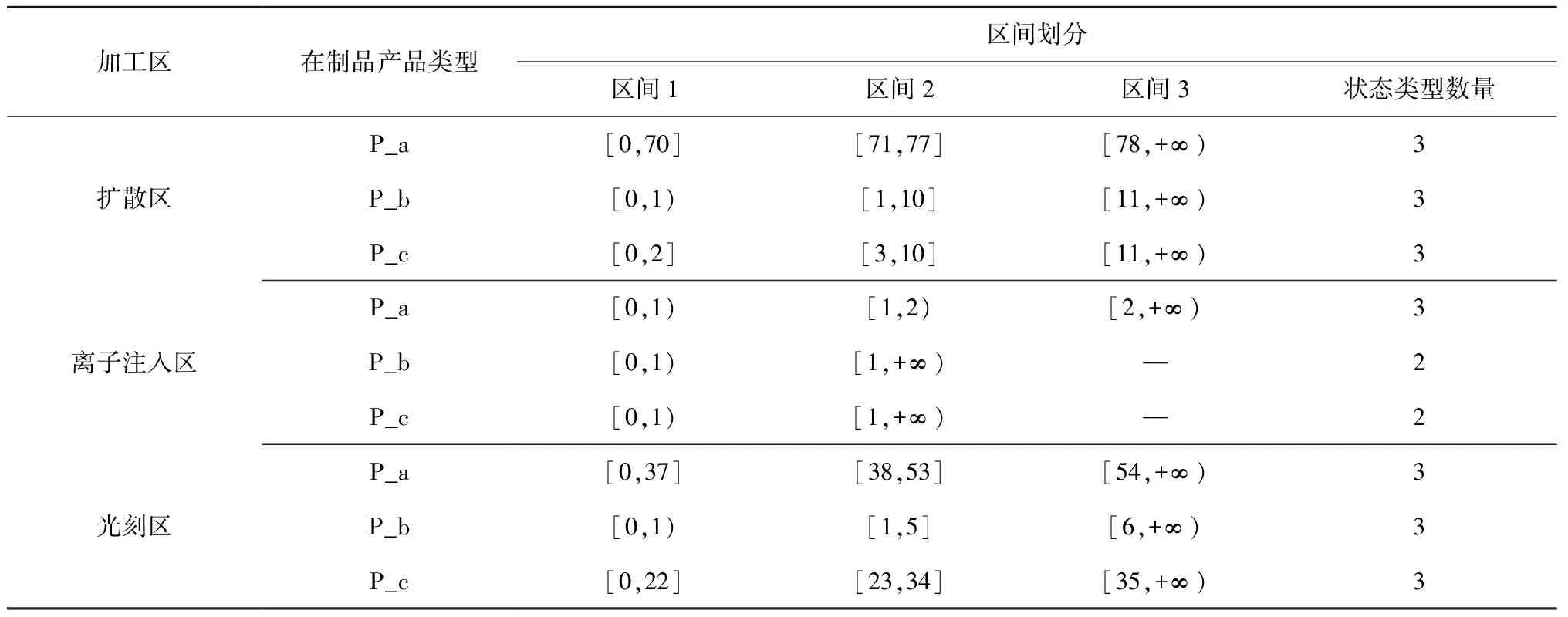
表1 车间生产状态数据划分依据
(2)调度决策D调度决策设置最早交货期优先规则EarliestDueDate,EDD)、最短剩余加工时间优先规则(ShortestRemainingProcessingTime,SRPT)、关键比例规则(CriticalRatio,CR)3种启发式调度规则进行组合,形成组合式调度规则D={d1,d2,...,dm}[20],其中di=(ωEDDi,ωSRPTi,ωCRi),1≤i≤m,m表示调度决策的类型数量。调度决策根据式(3)和式(4)计算得到:
P=ωEDDPE+ωSRPTPS+ωCRPC,ω∈[0,1],
(3)
ωEDD+ωSRPT+ωCR=1。
(4)
其中:P表示待加工产品的加工优先级,ωEDD、ωSRPT、ωCR分别表示3种启发式调度规则的权重,PE、PS、PC则分别表示在3种启发式调度规则下的产品加工优先级,设置权重ω间隔为0.05,因此本实验中共有255种调度决策类型,即调度模型Q-table的决策维度m=255。
(3)回报函数R针对多目标优化问题,回报函数选择日产量Tp和日移动步数Mov作为关键评价指标,回报值与指标间呈正相关,指标数值越高表示调度决策效果越好,此时环境对训练智能体的奖励越高。实验设置车间日产量阈值Tp_th,日移动步数阈值Mov_th,高于阈值则回报函数为正值(奖励),低于阈值则回报为负值(惩罚),回报函数数值r(r∈R)根据式(5)进行计算:
r=(Tp-Tp_th)+(Mov-Mov_th)。
(5)
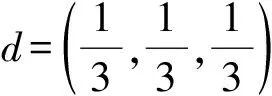
3.1.2 超参数设置
调度智能体训练时根据式(1)更新Q-table,需要确定超参数折扣率γ和学习速率α。由于本文研究的调度问题是采用最优调度决策优化整个调度周期内车间生产性能,折扣率γ取较大值0.9,表示未来调度决策对当前决策行为的影响较大。在学习速率α的选择上,为了获得最大收益并使实验迭代次数在可接受范围内,开始学习时设置较大的学习速率来修正智能体的行为,随着实验次数的增加,逐渐减小学习速率防止错过最优解[25]。实验中采用式(6)动态减小学习速率。
(6)
初始学习率α0设置为0.5;学习率动态变化的最大回合数max_episode设置为1 500。
训练过程中智能体的行为策略依据贪心算法ε-greedy(式(2)),以ε的概率在动作空间随机选择一个决策,通过不断探索可以获得更佳的决策,以1-ε的概率在已知决策中选择一个回报最大的决策。实验采用式(7)动态减小探索速率,随着探索率减小,总回报逐渐收敛于最高值,达到探索—利用平衡。
(7)
初始探索率ε0设置为0.5;探索率动态变化的最大回合数max_episode设置为1 500。
在1 500回合之前,学习率和探索率动态减小,1 500回合之后,学习率和探索率保持在0.01,即仍然存在探索和学习的可能。
3.2 实验结果
在3.1节中所设置的实验数据结构和超参数基础上,训练基于Q学习算法的调度模型,用于动态环境下的智能车间自适应调度决策(Q学习调度方法)。实验以日产量Tp和日移动步数Mov为性能评价指标,调度模型根据生产状态变化对最优调度决策进行每日更新,将该决策与单一调度规则EDD、SRPT、CR和基于支持向量回归(Support Vector Regression,SVR)算法的有监督调度模型输出的长期调度决策对车间生产性能指标产生的影响作对比,同时对比SVR调度方法与Q-learning调度方法所需的时间与人力成本,验证基于Q学习的智能车间自适应调度方法的可行性与有效性。实验中,车间生产环境的动态不确定性体现在日投料数量的随机性上。对比实验采取控制变量法,除调度决策外,其余实验条件一致。
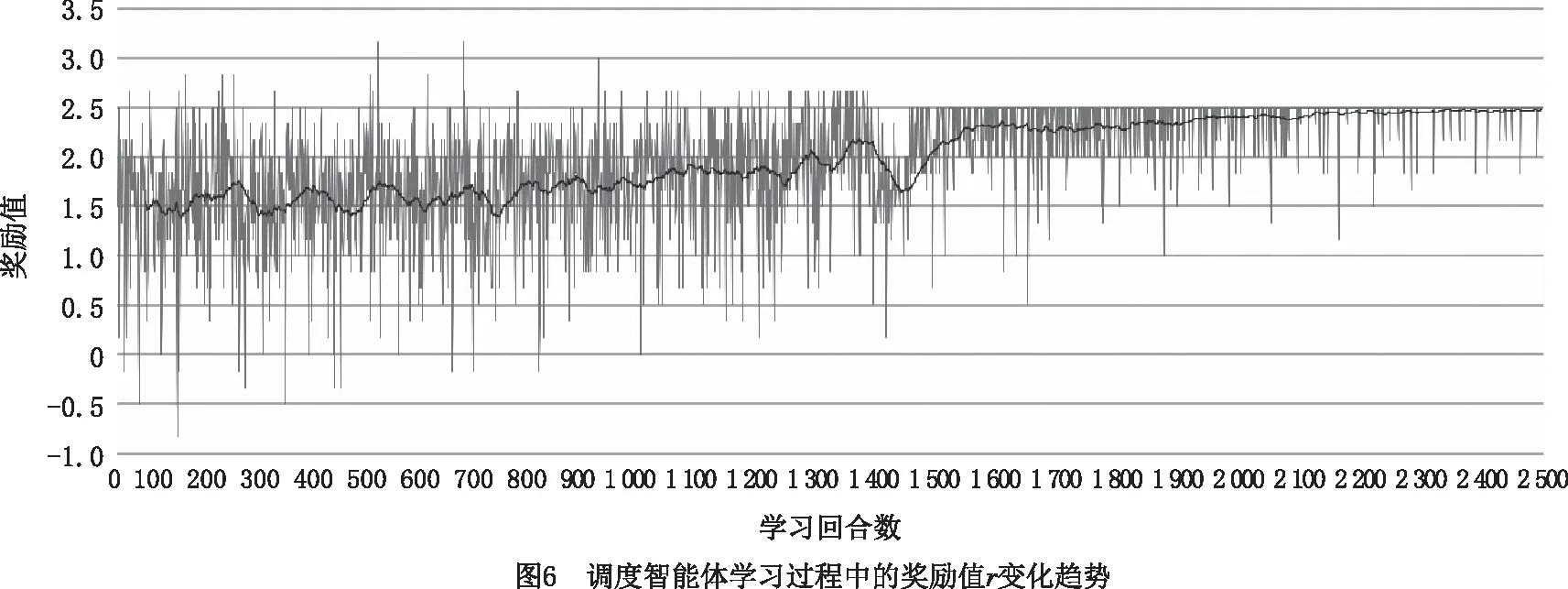
调度智能体在2 500回合学习过程中的奖励值数据记录如图6所示。在学习初期,奖励值存在剧烈波动,但曲线总体呈不断上升的趋势,此时智能体的探索能力和学习能力较强。随着回合数的增加,智能体学习速率和探索率减小,奖励值逐渐收敛于一个较高的数值,则表明训练完成,生成的调度模型能够用于指导该场景下的车间生产调度。
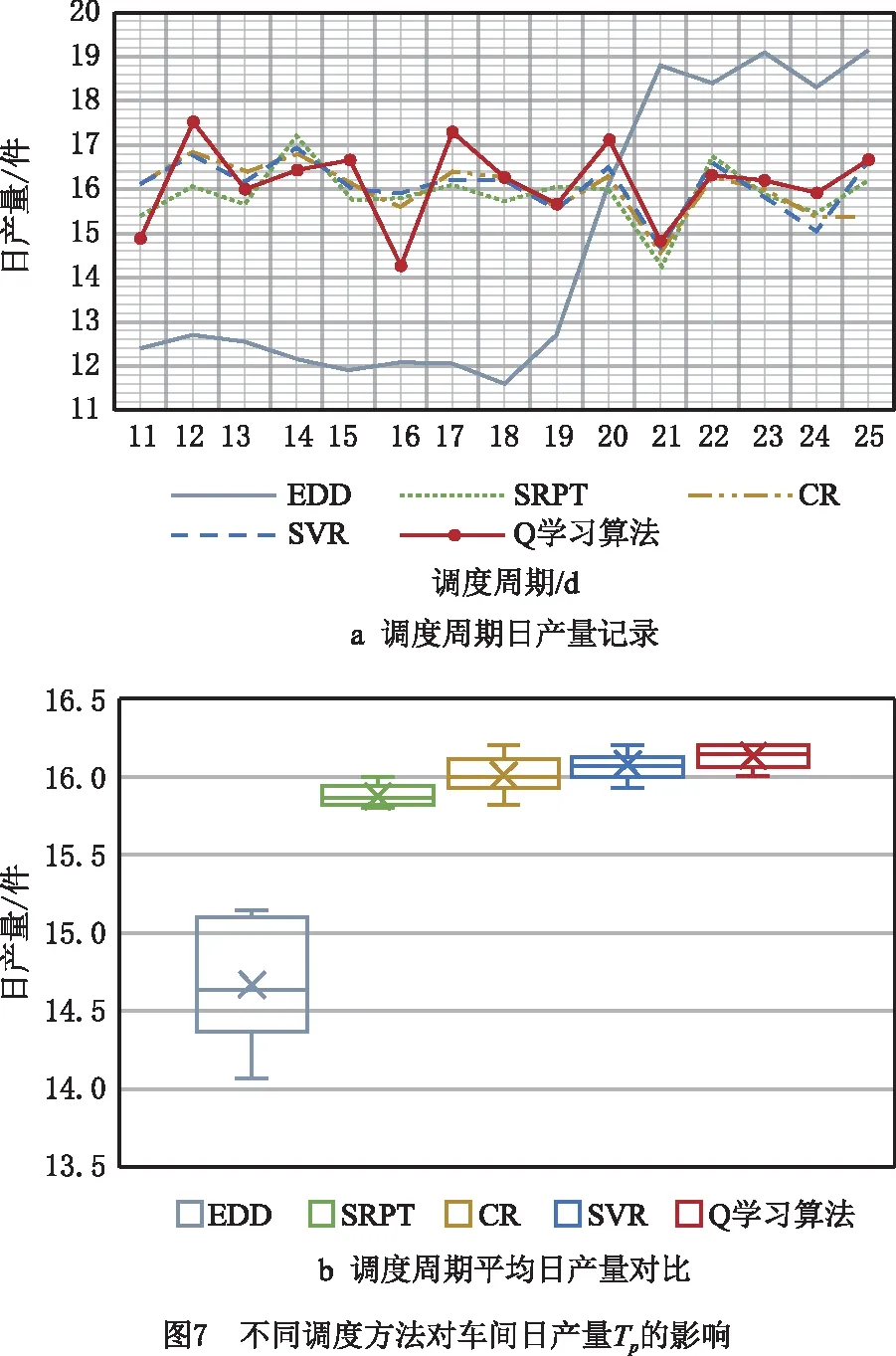
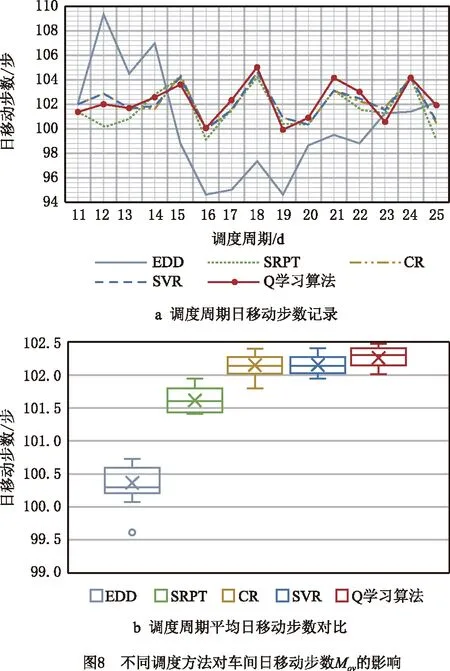
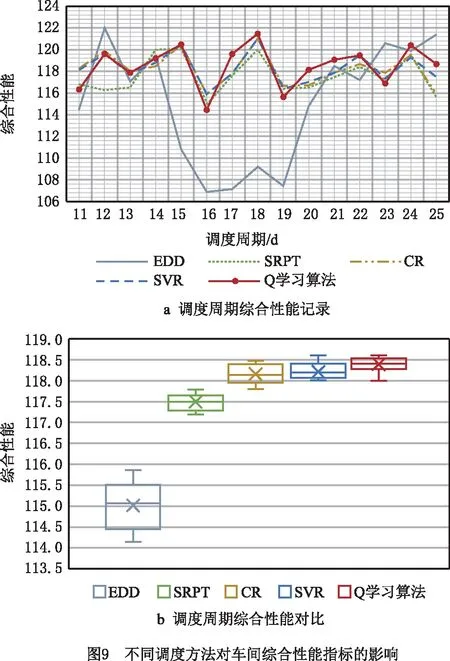
在相同实验场景下,对生成的调度模型进行有效性验证。为了消除实验结果偶然性的影响,随机选取20种不同投料模式,对5种调度方法得到的每日生产性能进行记录,如图7~图9a所示,同时,对不同调度方法下的生产性能数据分布进行对比,如图7~9b的箱型图所示。其中,生产前10d预热时间,调度周期为11~25d。
统计性能指标平均值(如表2),对比分析发现,Q学习算法在日产量、日移动步数、综合性能上均表现出了最优的效果。数值上,Q学习算法调度方法的日产量较EDD、SRPT、CR和SVR分别提升了9.978%、1.617%、0.771%和0.332%,日移动步数分别提升了1.903%、0.636%、0.131%和0.112%,综合性能则分别优化了2.933%、0.769%、0.217%和0.147%。
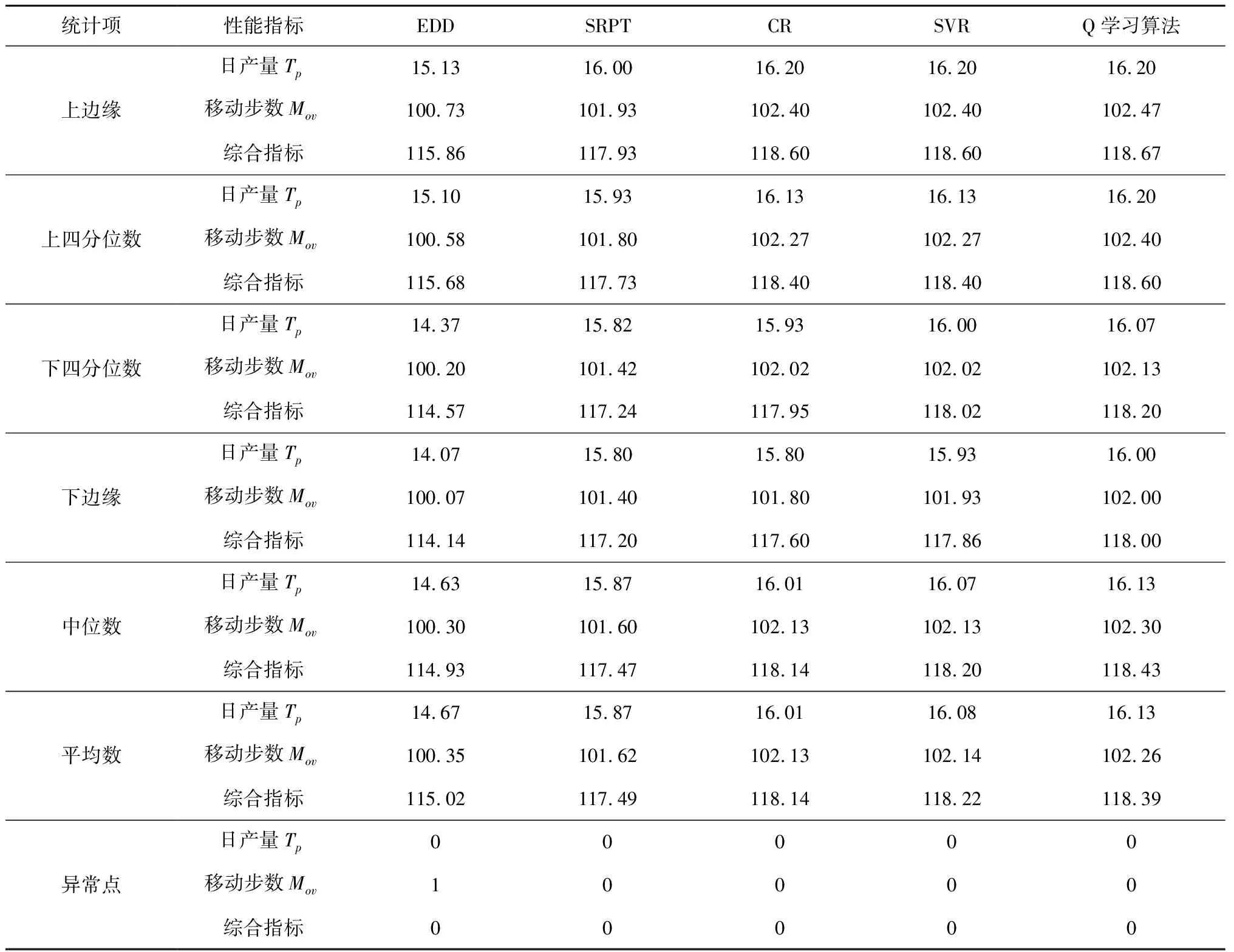
表2 车间性能指标统计数据记录
为了更好地分析不同调度方法对于整个调度周期内生产性能的影响,横向对比20组不同投料机制下的实验结果,绘制箱型图,分别表示统计数据的上边缘、上四分位数、中位数、下四分位数、下边缘、平均数和异常点(数据如表2)。在调度周期内的平均日产量方面,Q学习算法对应的生产性能明显优于EDD和SRPT,与CR、SVR具有相近的影响效果,其箱型图的上边缘相同,但整体分布区间包括中位数、平均数、下边缘等均高于CR与SVR。在调度周期平均日移动步数方面,同样地,Q学习算法所得到的性能远优于EDD和SRPT,同时所有评价指标均略微优于CR和SVR。在调度周期综合性能指标方面,Q学习算法相较于SVR和GCR,整体分布的优化效果则更为明显,据此能够验证本文基于Q学习算法自适应调度方法的有效性与优越性。
此外,强化学习算法在人力与时间成本方面均有优化作用,基于SVR的有监督方法与基于Q学习算法的强化学习方法实现时间记录如表3所示,表中带*号步骤表示需人工参与完成。其中,SVR方法利用有标签样本进行训练,样本采集和样本标注时间占总时间的99.19%,对应地,Q学习算法方法采集的样本仅用于状态数据划分,相较于SVR而言,时间减少了97.92%(271515.83s)。Q学习算法方法通过与智能体与环境的交互获取样本与训练调度模型,模型训练时间占总时间的85.63%,是SVR训练时间的15.14倍(32146.80s)。但是,在调度模型生成与应用总时间方面,Q学习算法较SVR减少了85.62%(239364.89s),需要人工参与的步骤时间较SVR减少了98.00%(264600s),极大降低了人力与时间成本,提升了模型动态训练与更新的实时性。
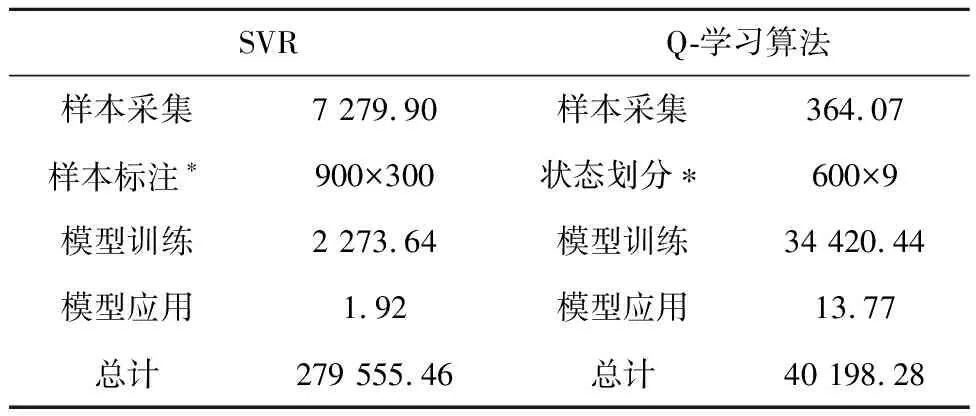
表3 SVR与Q学习算法调度方法实现时间 s
由此可知,基于Q学习的智能车间自适应调度方法能够在尽可能减少人工参与的同时,始终保持调度模型的有效性,并根据车间实时状态变化输出最优组合式调度规则,使得车间生产性能保持稳定高效。
4 结束语
为了降低生产过程中动态不确定性因素对智能车间生产性能的影响,本文提出一种基于Q学习的智能车间自适应调度方法。首先,提出基于强化学习交互训练机制的智能车间自适应调度框架,在此框架下,利用Q学习算法,通过智能体与车间仿真环境的实时交互反馈训练调度模型,得到生产状态与调度决策的映射关系,用于指导车间在线调度,并根据生产环境变动及时更新调度模型,使其适应变化的生产环境。最后,将此方法在MiniFab生产线模型上进行验证,相较于单一调度规则和调度模型不更新的有监督调度方法,基于Q学习的自适应调度方法能够实现对车间综合性能指标的持续优化,同时大幅度降低调度过程的时间与人力成本。据此,本文所提出的方法能够实现在生产全过程中,根据车间生产状况动态变化及时生成相应的最优调度决策,形成最优决策轨迹,对动态生产过程具有良好的适应性。
但是,Q学习算法在空间维度上存在局限性,高维模型会出现训练过程缓慢、难以收敛到最优的问题,因此选择科学合理的状态与动作空间尤为重要。在今后的研究中可以通过相关性分析选择更为有效的状态、动作数据用于模型训练,或对算法进行改进,使调度模型适用范围更广、泛化能力更强。
