基于信誉和聚类的动态拜占庭容错算法
2023-12-04巫光福黄宝珠
巫光福,杨 子,黄宝珠
1.江西理工大学信息工程学院,江西赣州341099
2.密码科学技术国家重点实验室,北京100878
拜占庭容错(Byzantine fault tolerance,BFT)[1]算法自提出以来就广受关注。但由于其通信复杂度高,尚未在实践中应用。直到1999 年提出的实用拜占庭容错(practical Byzantine fault tolerance,PBFT)[2]将BFT 算法的复杂度从指数级降到多项式级,才逐渐应用于工程领域。目前,PBFT 是区块链[3]中应用最多的共识算法。虽然PBFT 相较于其他共识算法提高了吞吐量,减少了交易确认时延,但仍存在很多不足:首先PBFT 对于节点加入或退出没有良好的响应机制,其次主节点选取随意。这些不足会提高拜占庭节点成为主节点的概率,从而降低共识效率,造成资源浪费。
近些年,很多学者针对PBFT 存在的不足进行算法改进。例如,文献[4-7] 将PBFT 与POW、POS 或DPOS 相结合,以提高共识效率,这些算法是选择一定数量的节点作为委员会,然后委员会提供PBFT 算法生成区块,虽然这些改进算法在部分性能方面优于原算法,但其通常适用于令牌场景。文献[8] 提出的SBFT 算法对分散方式进行优化,使其轻松处理超过100 个活动副本,解决了动态性和去中心化的问题。OBFT 算法[4]提出了一种新型协议,该协议保证在没有发生故障的乐观情况下,以全网络速度处理事务,增加了PBFT 的容错性。CBFT[5]算法通过区块缓存、区块同步与签名、节点变更实现,使算法较高的吞吐量和较低的时延,但是其交易处理和达成共识的效率需要进一步提升。虽然这些算法可以有效降低通信开销,提升扩展性,但是在选取可靠主节点的问题上没有有效措施,同时也没有良好的动态响应机制。
对比分析现有的改进PBFT 算法后,本文提出了基于信誉和聚类的动态拜占庭容错(dynamic-layering reputation-evaluation and K-medoids practical Byzantine fault tolerant,DRKPBFT)算法。算法通过改进K-medoids 算法将节点划分为K个共识区域,将传统的PBFT 改进为多中心化,多层次的拜占庭算法,提高了较多节点参与共识时的效率,同时能够动态调整节点加入或退出时的节点数量。为了选取可靠的主节点,提出了信誉评估算法,其能够对节点行为进行信誉值评估,选取信誉值高的节点为主节点,剔除信誉值低的拜占庭节点,提高了可靠节点为主节点的概率,减少了共识过程的资源浪费。
1 相关知识
1.1 区块链
从中本聪首次提到区块链技术以来[6],尚未形成公认的区块链定义。狭义上,区块链是按照时间顺序将区块依次相连的链式数据结构,是由多方维护,使用密码学保证传输和访问安全,能够实现数据一致存储,难以篡改的记账技术[7]。广义上,区块链是使用链式结构和密码学存储验证数据,使用P2P 网络进行消息传播,利用共识算法保证数据的一致性,利用脚本代码和智能合约[8]操作数据,是一种全新的去中心化架构模型。区块链的链式数据结构如图1 所示。
1.2 共识算法
由于区块链中缺乏中央权威,因此需要一个共识算法来保持数据的一致性[9]。共识算法在决定区块链系统的效率和安全性方面起着重要作用,即所选择的算法类型对系统的性能有着重大影响。常用共识算法如下。
1.2.1 工作量证明
工作量证明(proof of work,POW)的过程是各节点通过大量算力竞争来解决一个(求解复杂但验证容易)的难题,最快解出难题的节点将获得区块记账权[10]。在比特币中,POW 就是各矿工共同竞争解决SHA256 这个数学难题(挖矿),当节点最快找出区块头的双哈希值小于或等于目标哈希值的nonce 值时,其就获得区块记账权以及比特币奖励。POW 的优点是可以通过算力竞争保障比特币系统的安全性和去中心性,缺点是需要进行大量无现实意义的计算,而且将近10 min 的交易确认时间不适合某些应用。
1.2.2 权益证明
权益证明(proof of stack,POS)[11]是针对POW 的资源浪费等不足提出的共识机制。它以具有最高权益获得区块记账权。在Peercoin[12]中,权益表现为币龄。当记账竞争开始时,节点以币龄下注,拥有最高币龄的将成为验证者。验证者获得记账权生成区块后,其币龄将清空,然后节点获取相应的利息。POS 是依靠内部币龄和权益,而不是像POW 消耗外部算力和资源,从根本上解决了共识算力浪费的问题,能够在一定程度上缩短共识时间。
1.2.3 委托权益证明
委托权益证明(delegated proof of stake,DPOS)类似于投票选举,即系统中每个拥有token 的股东节点进行投票选举代表[13],获得票数最多且愿意成为代表的前101 个节点将进入候选池,从候选池中选出区块生成者,区块生成者根据随机顺序进行出块,生成的新区块经过2/3 区块生产者验证后,节点获得奖励。由此可知DPOS 中每个节点都能够自主决定其信任的授权节点,同时由这些节点轮流记账生成新区块,因此DPOS 大幅减少了参与验证和记账的节点数量,实现了快速共识验证。
1.2.4 Raft 共识算法
Raft 是用于管理复制日志的共识算法,其过程分为leader 选举和日志复制两个阶段。即首先选取一个leader,赋予leader 记账的权力。然后任何leader 从客户端接收记账请求,完成记账操作,生成区块,并复制其他记账节点。Raft 是非拜占庭故障下达成共识的强一致协议,常用于私有链[14]。
1.2.5 实用拜占庭容错机制
PBFT 的共识过程包括请求阶段(Request)、预准备阶段(Pre-prepare)、准备阶段(Prepare)、确认阶段(Commit)以及响应阶段(Reply)。在PBFT 协议中,有客户端、主节点(Primary)、从节点(Backup)三种身份。PBFT 的共识过程如图2 所示。
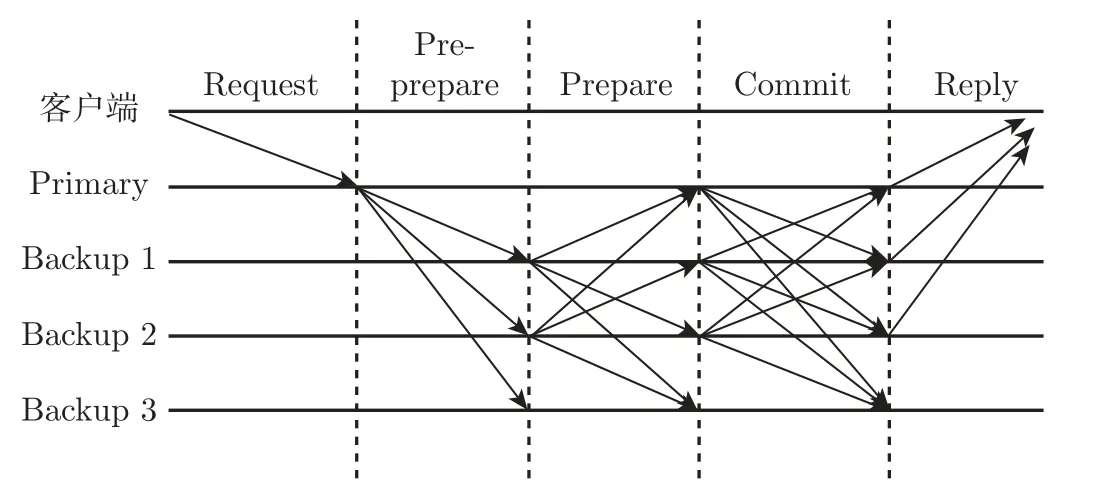
图2 PBFT 共识过程Figure 2 PBFT consensus process
1)请求阶段 客户端向主节点发送请求〈REQUEST,O,T,C〉,O代表具体执行的操作,T代表时间戳,C表示客户端编号。
2)预准备阶段 收到客户端请求后,主节点会检查合法性,然后给请求分配序列号N,然后向从节点广播预准备消息〈PRE-PREPARE,V,N,D,M〉,V表示当前视图序号,D是请求的摘要,M代表客户端的请求信息。
3)准备阶段 从节点收到预准备消息,进行一些验证,验证通过后进入准备阶段,广播准备消息〈PREPARE,V,N,D,I〉,I代表从节点编号。
4)确认阶段 节点收到2f+1 个合法的准备消息,广播确认消息〈COMMIT,V,N,M,I〉,从节点收到确认消息,进行验证,验证通过后将COMMIT 插入本地log。
5)回复阶段 执行此阶段时,所有节点会向客户端发送回复消息〈REPLY,V,T,C,I,R〉,R指执行结果。
根据表1 的共识算法对比,PBFT 具有较高的吞吐量和执行速度,但是仍然存在主节点选取随意,共识速度慢,可扩展性低等问题。基于此,本文提出的DRKPBFT 算法解决了主节点选取的问题,设计了节点动态加入和退出机制,使得算法具有较好的容错性,扩展性。
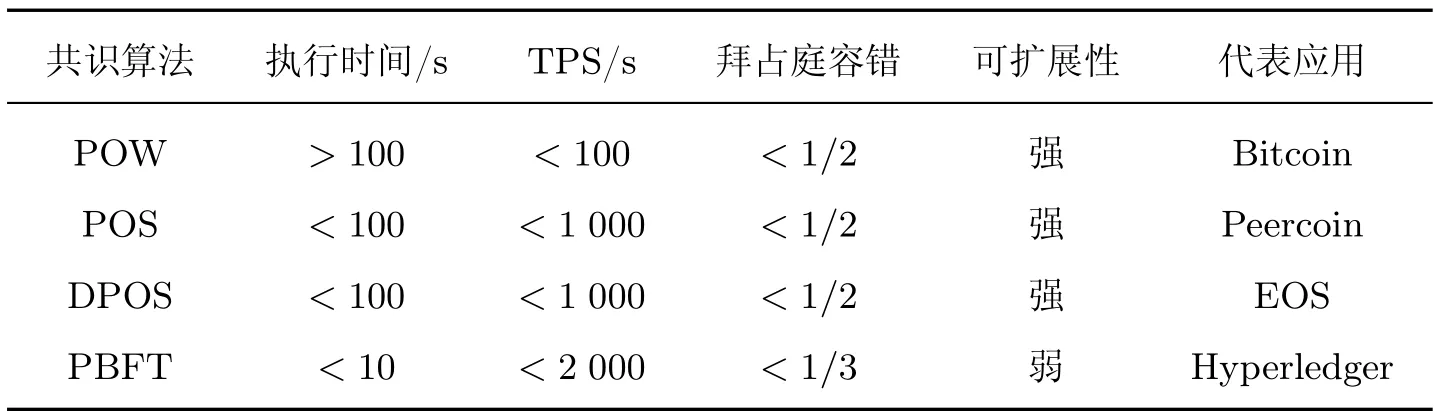
表1 共识算法对比Table 1 Comparison among consensus algorithms
1.3 聚类算法
K-medoids 算法[15]是基于划分的聚类算法,具体过程如下:假设有m个n维特征的对象节点作为聚类数据集。节点数据集V={V1,V2,···,Vm}表达为
算法通过距离函数来表达两个节点的相似度,同时通过隶属函数将数据集分为K 簇和K个聚类中心节点集。
2 DRKPBFT 共识算法方案
DRKPBFT 共识方案包括共识系统初始化,KPBFT 共识以及信誉评估算法3 个部分。
2.1 系统初始化
本文方案为了使K-medoids 更加适用于区块链模型,采用改进聚类算法选取K个聚类中心节点。(K个中心节点不是从所有样本中随机选择的,而是根据具体应用通过监管机构进行严格审查排名,筛选出K个社会公信度较高的节点)。K个中心节点构成代理节点群,然后计算其余节点距离K个代理节点的距离函数和隶属函数,最后根据欧式距离进行聚类分层,形成相应的子共识集群。节点分类如图3 所示。
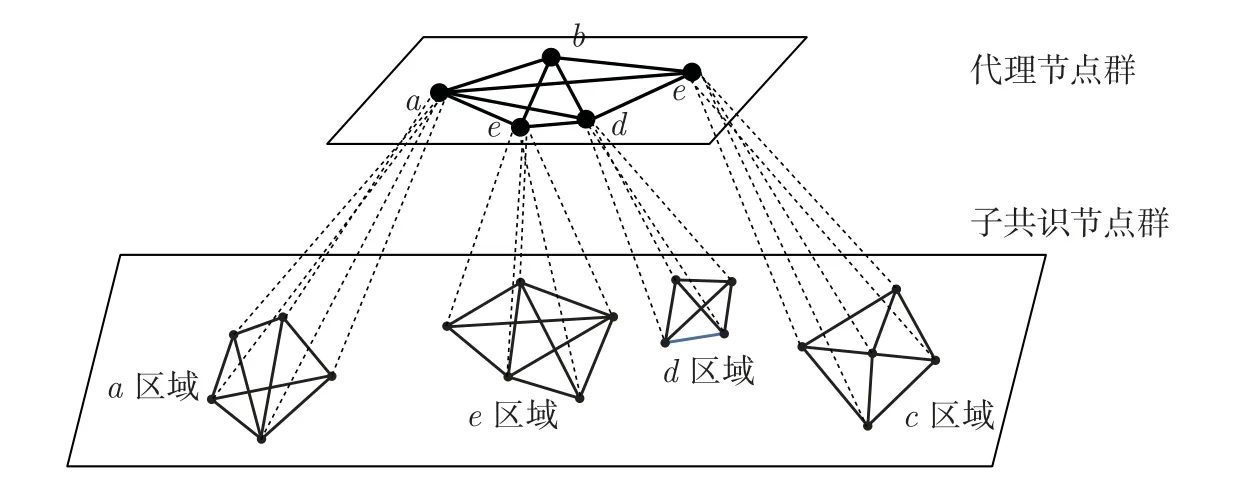
图3 共识节点图Figure 3 Consensus node graph
2.2 KPBFT 过程
KPBFT 共识过程如图4 所示。首先每一个集群内的节点达成共识,然后代理节点收集共识结果。经过一段时间后,根据2.3 节信誉评估算法进行聚类中心(代理节点)更换,然后重新进行共识。
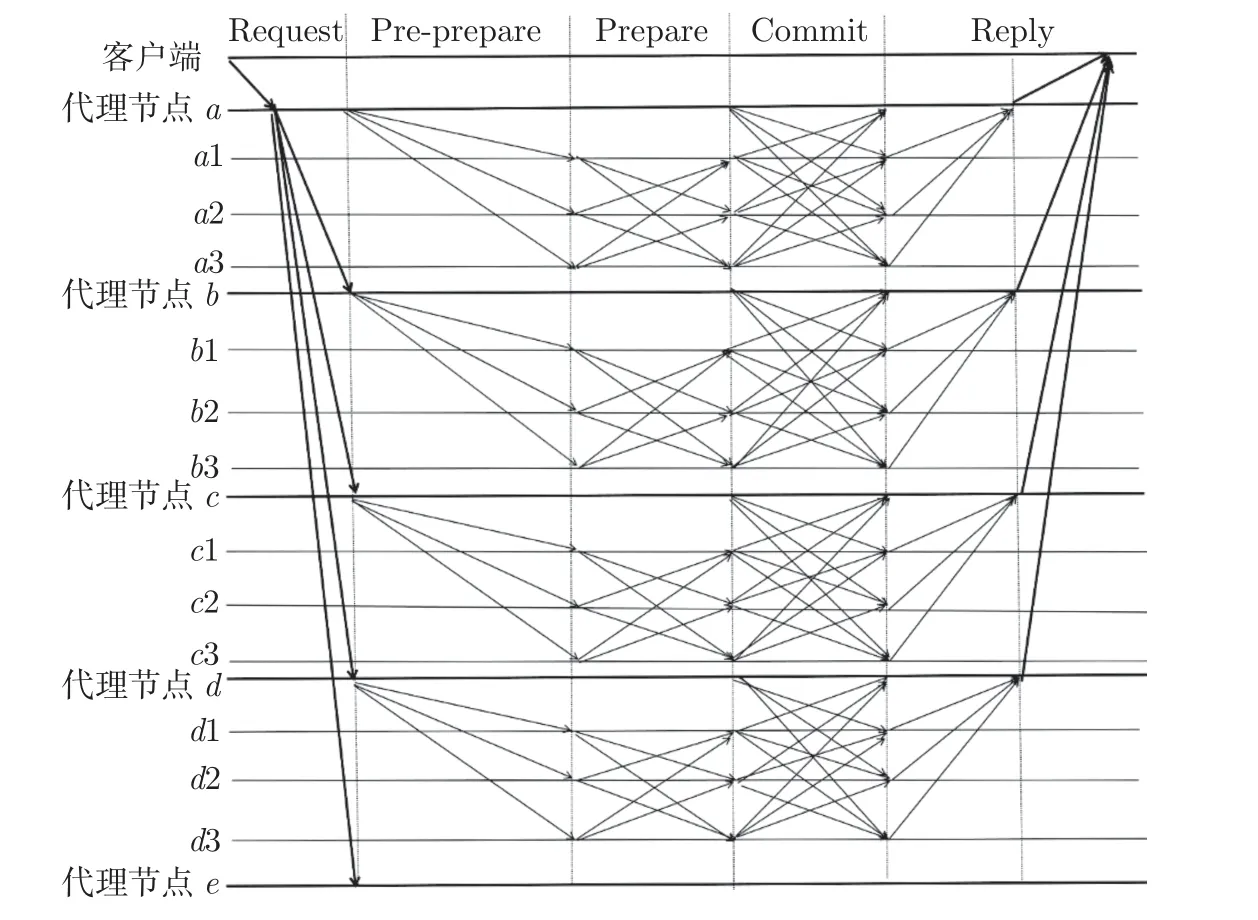
图4 KPBFT 过程Figure 4 KPBFT process
1)请求阶段 客户端C 向第1 层代理节点发送消息,即向代理主节点发送请求消息,代理主节点为客户端的请求进行排序,然后与PBFT 采用广播的方式不同,本模型为了节省网络资源,采用组播向代理节点群中的其他代理节点传递消息。
2)预准备阶段 进入此阶段,共识群里已初步分为K个区域。每个代理节点向其区域内的共识节点群中广播预准备消息,当区域内的子共识节点接受到消息,预准备阶段完成。然后K个代理节点与其子共识节点在各自的区域内进行准备阶段,确认阶段,当每个代理节点收到超过本区域2/3 的回复消息,进入下一阶段。
3)回复阶段 回复阶段分为区内回复和区间回复两部分。区内回复是各个区域内的子共识节点将执行结果发给所属的代理节点;区间回复是代理节点记录各个区域内的区内结果并发送给客户端。客户端根据组播请求的总数和接收到同意消息的总数,即总数是否大于恶意节点总数f+1 来确定是否接收结果。
2.3 信誉评估算法
本文方案在选取K个可信聚类中心(代理节点)问题上,提出了一个信誉评估算法。信誉评估算法包括行为奖罚机制,节点划分机制,角色转换机制,节点剔除机制。即整个模型通过奖惩机制对节点的行为进行信誉值评估,根据信誉值将节点分类成无效节点、普通节点、投票节点、代理节点,并在代理节点中选出信誉值最高的当作下一个视图的代理主节点(如果没有单一最高信誉值,则选取信誉值高且序号最小的当作代理主节点)。节点的等级可以通过信誉值进行动态转换,保证了系统的动态性、稳定性。最后会将信誉值低的无效节点剔除出共识集合,保证了系统的安全性。通过信誉评估算法,为下一视图选择K个代理节点提供依据,增加了可信节点参加共识集合的概率,实现了快速可信的共识。
2.3.1 节点划分机制
在系统初始化时,将K个代理节点的信誉值设为8,其余子共识节点信誉值设为6。经过t轮KPBFT 共识后进行共识节点角色划分。根据奖励惩罚机制对前t轮共识过程的节点行为进行信誉值评估,依此筛选出信誉值小于0 的无效节点,信誉值为0∼6 分的普通节点,信誉值为6∼8 分的投票节点,及信誉值为大于8 分的代理节点,规定最高信誉值为20 分。普通节点服从投票节点的安排,只完成共识过程。投票节点在共识过程中监督代理节点的行为,决定是否更换代理节点。通过节点划分机制可以有效防止网络中故障或恶意节点成为主节点,减少了节点的共识通信开销,提高了整个系统的共识效率。
2.3.2 行为奖惩机制
当节点有如下行为,进行信誉值奖励。若节点实际共识时间小于平均共识时间,信誉值+1;若节点通过反馈举报其他节点恶意行为或宕机行为,也给予信誉值+1;当节点进行如下操作时,则会扣除相应的信誉值。如节点故意拖延一段时间不传递消息,信誉值-1;节点滥用举报消息信誉值-3;节点对收到的信息始终不传播信誉值-5;最后如果传播恶意消息并广播出去,信誉值-8。通过节点的共识行为进行信誉值评估,根据信誉值进行角色划分,然后行使不同的功能,可以很好的维护节点之间的安全与稳定。
2.3.3 角色转换机制
节点的角色是动态转换的,主要跟节点在共识过程中的行为有关。普通节点积极诚实共识可升级为投票节点,投票节点亦可升级为代理节点,所以节点越是积极诚实进行共识,则相应的信誉值就会越高,成为代理节点的可能性越大;反之节点故意或者恶意进行共识,则进行降级变成普通节点,甚至可能变成无效节点,无法参与共识过程。同时,如果代理节点和代理主节点出现错误时,则降级为普通节点;或者投票节点经过一段时间进行投票,将代理节点降级为普通节点,这样可以避免共识过程中系统过度中心化的问题,降低某些节点一直是代理节点带来的安全性问题。节点角色转换如图5 所示。
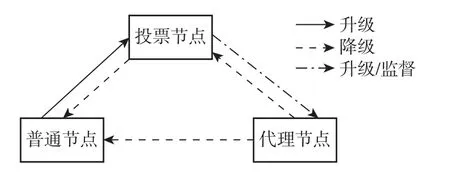
图5 节点角色转换图Figure 5 Node role conversion diagram
2.3.4 节点剔除机制
将信誉值小于0 的节点视为无效节点,剔除共识过程。节点剔除机制进一步降低了共识节点中拜占庭节点存在和作恶的可能性,规范了共识节点的诚实度,提高了系统的共识效率和安全性。
3 DRKPBFT 共识算法流程
假设网络中共有N个节点,节点编号为{0,1,···,N-1},其中包括K个代理节点,N-K个其余节点,共同构成K个区域。算法流程如图6 所示:
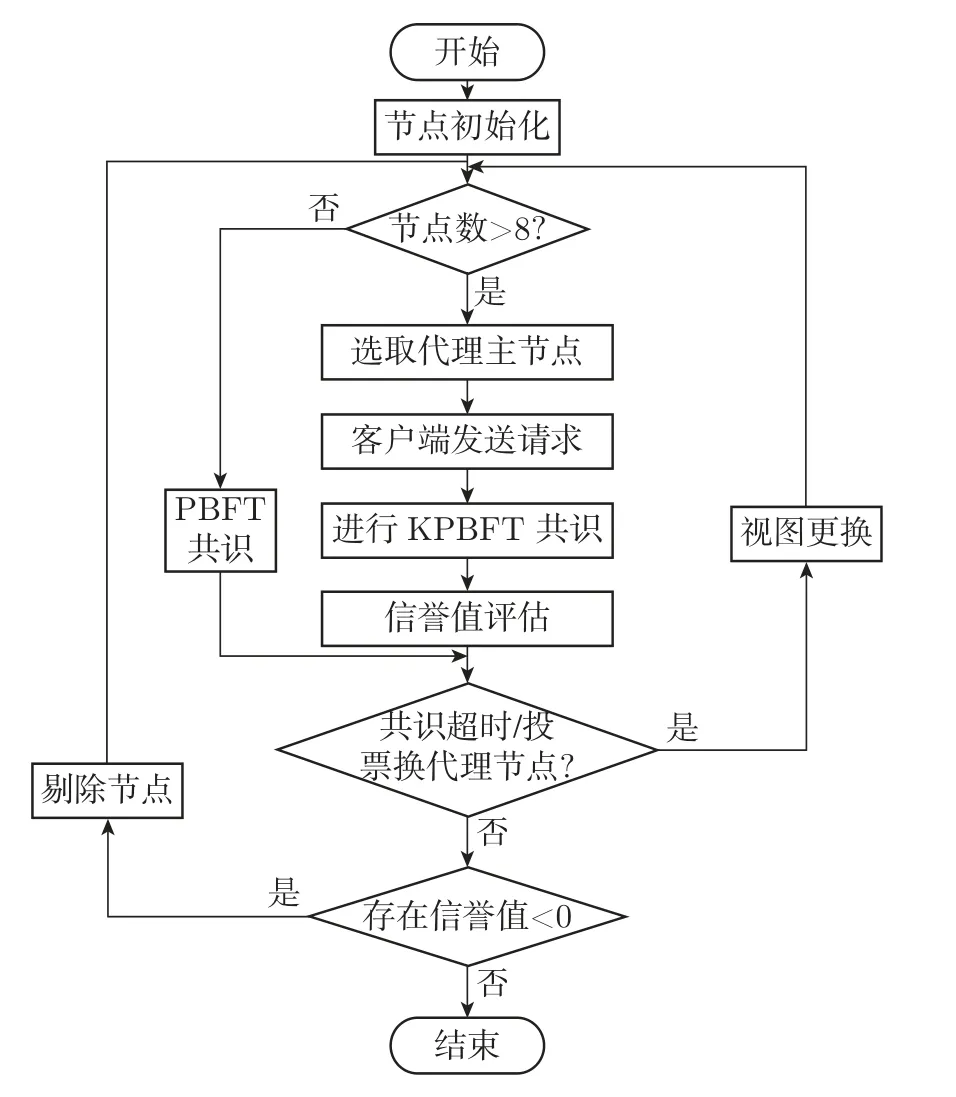
图6 算法流程图Figure 6 Algorithm flow chart
1)节点初始化选取K个代理节点,进行节点聚类划分。同时将代理节点初始化信誉值为8,其余子节点初始信誉值为6。
2)选取代理主节点初始时,代理节点信誉值相同,则对K个代理节点排序,然后从中随机挑选一个代理主节点。其中,若N≥8 时,选取代理主节点;若N<8,系统直接执行PBFT 算法。
3)客户端client 发送交易请求〈REQUEST,M,T,C〉σC,M为请求信息,T是时间戳,σC为客户端签名。
4)代理主节点收到客户端请求后,将消息组播发给代理节点,每个区域内进行共识过程。每个区域进行预准备阶段〈PRE-PREPARE,V,N,D〉M>σα(V是视图编号,D消息摘要,σα代理节点签名;准备阶段〈PREPARE,V,N,D,I〉σα1(I为区域内从节点的编号,σα1为代理子节点的签名);确认阶段〈COMMIT,V,N,M,I〉。
5)K个代理节点收集本区域内结果,然后将信息返回给客户端。
6)客户端根据组播请求的总数和接收到同意消息的总数,即总数是否大于恶意节点总数f+1 来确定是否接收结果.若超时未完成共识或代理节点行为异常,则启动视图更改协议,然后根据信誉值评估算法重新选取代理节点。
7)信誉评估算法评估此共识过程的节点行为,进行信誉值更新,根据信誉值进行节点角色划分,同时将恶意节点剔除,保证系统安全性。
丛晓荣(1983-),女,硕士,助理研究员,主要从事含油气盆地分析、海域天然气水合物成藏与资源评价等方面的科研工作。
4 仿真实验及分析
本节将从动态性、通信开销、容错性、时延、吞吐量这5 个方面进行实验分析,并对比PBFT 来验证本文算法的优越性。仿真实验环境,在Windows10 系统中使用Python 语言,采用虚拟系统Ubuntu18.04.
4.1 动态性分析
传统的PBFT 采用静态请求响应模式,加入和退出时都需要重新启动系统,没有良好的响应机制。本文提出的DRKPBFT 算法采用信誉评估将节点划分,并根据信誉值动态转换,节点的加入或退出由代理节点动态管理。当普通节点加入共识时,根据聚类算法,计算与哪个代理节点距离最为接近,将其加入该子类子群中;当普通节点或投票节点退出共识时,代理节点直接将该节点从子群中删除;当代理节点退出时,降级为普通节点,然后由投票节点根据信誉值选举新的代理节点。
由此可见,DRKPBFT 能够在节点加入和退出时,动态调整节点数量,避免PBFT 节点加入或退出引起整个系统重启的问题,减少了网络资源消耗,增强了共识系统的动态性,保证了系统的稳定性和可靠性。
4.2 通信开销分析
对于PBFT 算法,当系统节点为N时,从客户端请求、预准备阶段、准备阶段、确认阶段到回复阶段,通信次数共为1+(N-1)+(N-1)(N-1)+N(N-1)+N=2N2,其通信复杂度为O(N2)。对于本文的DRKPBFT 算法,采用分类的思想,将N个节点分为K类,每一类中有N/K个节点,客户端向代理主节点发送请求以及代理节点间进行的通信次数为K次,然后子节点进行共识的通信次数为2N2/K2,最后代理节点回复客户端通信次数为K次,求和得出算法总通信次数共为(2K+2N2/K2)。
实验先测试PBFT 与K=3 的DRKPBFT 在节点数增加时,单次交易完成后节点的通信次数,然后测试不同K值下,随着节点数增加,节点的通信开销。实验结果如图7 和8 所示,图7 表明随着网络中节点数目的增多,PBFT 需要大量通信开销才能完成一次共识,而本文的DRKPBFT 进行一次共识的通信开销明显低于PBFT 算法。同时图8 则表明随着节点数增加,在K=4,7,10 的情况下,完成一次共识的通信开销是不断减少的。实验结果表明,随着节点数增加,可以增加K值即增加节点分类数来降低通信开销,原因是由于本文的DRKPBFT 通过聚类算法将节点分类,减少了共识节点的数量,同时在确认阶段降低了共识通信次数。
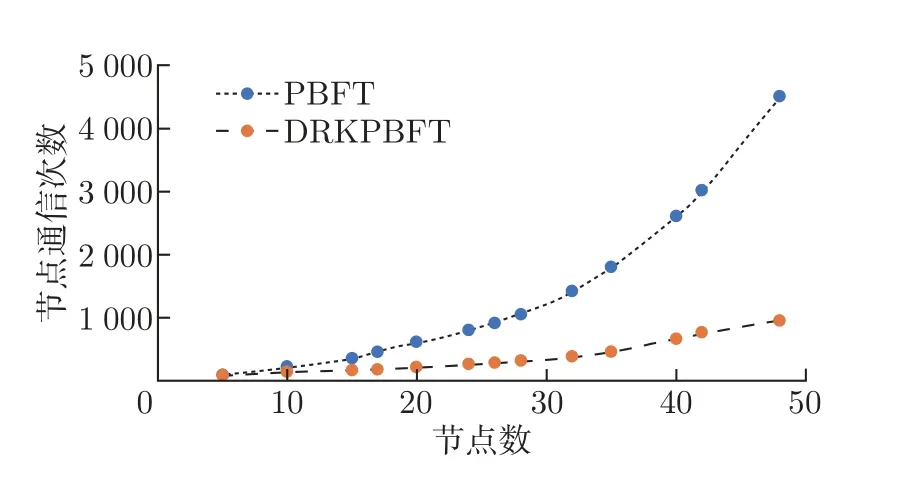
图7 PBFT vs DRKPBFTFigure 7 PBFT vs DRKPBFT
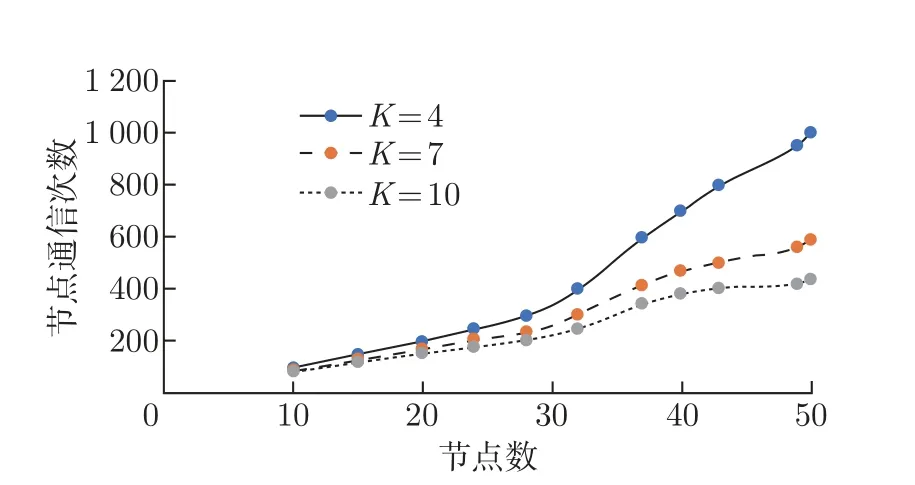
图8 K 值不同的DRKPBFT 通信开销Figure 8 DRKPBFT communication overhead with different values of K
4.3 容错性分析
针对DRKPBFT 算法进行容错性分析,考虑代理节点存在拜占庭节点以及不存在拜占庭节点两种情况。
若拜占庭节点集中在一个聚类中,则该代理节点将会输出错误,此时在代理节点群中的结果将会丢弃,同时投票节点将代理节点降级;若拜占庭节点均匀分布在每个聚类中,那么每个聚类中的拜占庭节点数不超过其区域内节点总数的1/3。现考虑,N个节点被分为K个区域,每个区域最多允许拜占庭节点数为(N/K)/3,同时系统最多允许K/3 个代理节点全部为拜占庭节点,此时整个系统的容错性为
由此可得,本文的DRKPBFT 比PBFT 支持更高的容错性。
4.3.2 代理节点中存在拜占庭节点
这种情况下,该节点可能会影响该区域的从节点,甚至可能篡改共识结果。如果拜占庭节点超过总代理节点数的1/3,那么系统将会崩溃,所以系统的容错性为(K-1)/3。但是本文从高信誉节点中选取代理节点,同时代理节点出错,投票节点会进行投票更换代理节点并进行降级处理,这样有效防止拜占庭节点成为代理节点的可能,保障了系统的安全性。
4.4 时延分析
时延是衡量共识算法的重要指标,过高的时延会使算法的可用性和安全性降低。实验设置客户端发送100 次交易,在节点数10、17、20、28、32、40 时进行3 组时延对比实验。将节点多次测试的时延结果取平均值,得出PBFT 和K=4 的DRKPBFT 的共识时延对比,结果如图9 所示,DRKPBFT 共识算法的交易时延明显低于PBFT,同时计算出PBFT 的平均交易时延为2.15 s,K=4 的DRKPBFT 的平均交易时延为0.27 s。由此可见,本文提出的DRKPBFT 在节点数增加时能够大幅度降低交易时延。
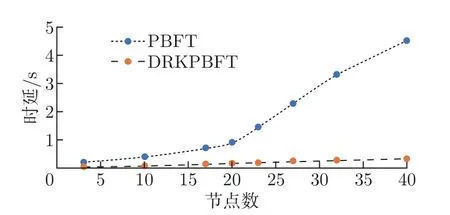
图9 时延对比Figure 9 Time delay contrast
4.5 吞吐量分析
吞吐量是检测共识算法运行效率高低的标准,较大的吞吐量能较好的反应算法的优劣。吞吐量为单位时间内完成的交易数量,计算公式为TPS=B/T(其中B为T时间内打包进区块的交易数,T为出块时间)。实验设置客户端发送200 条交易,然后记录完成共识的时间,最后通过公式计算出不同节点数的吞吐量。如图10 所示,当节点数分别为17、21、25、28、33、37、42、45、48 时,本文算法相比于PBFT 具有更高的吞吐量,同时可以计算出PBFT 的平均吞吐量为87 TPS,K=4 的DRKPBFT 的平均吞吐量为145 TPS。最后根据图10 的趋势可以看出随着节点数的增加,PBFT 吞吐量下降较快,稳定性较差,而DRKPBFT 在节点数增加至27 以后,吞吐量趋于平缓,稳定性较好。原因是:本文方案在聚类分区域时,选取高信誉值节点为代理主节点,且会剔除拜占庭节点,所以主节点是拜占庭节点的概率就会降低,那么试图更换次数随之减少,整个共识节点的数量也会减少,导致完成共识的时间随之缩短。
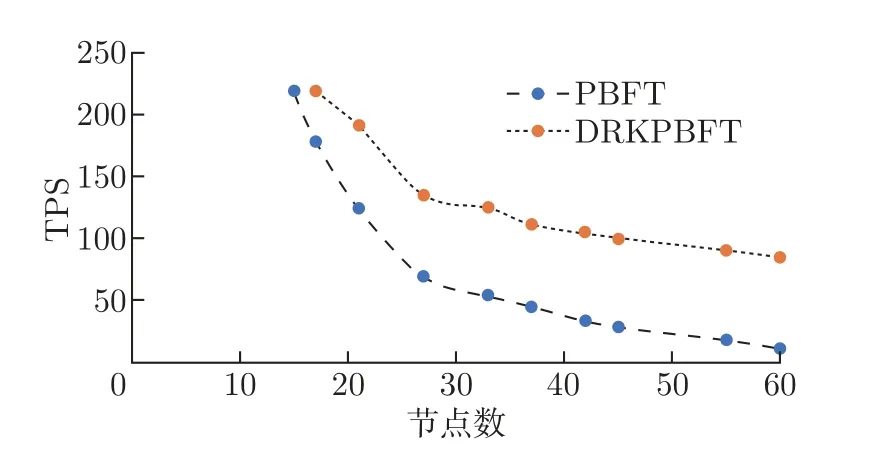
图10 吞吐量对比Figure 10 Throughput comparison
5 结语
本文针对区块链应用广泛的PBFT 共识算法进行了深入研究,提出了基于信誉和聚类的动态拜占庭容错改进算法。与PBFT 相比,本文算法具有通信开销小、低时延,高吞吐量和较好的扩展性等优点。但是本文采用的K-medoids 需要反复计算簇内节点到其他节点的欧氏距离,增加了算法的计算量,未来将考虑根据应用场景选择节点间地理位置,机器条件或网络延迟等具体特征作为分区域的依据,同时将研究更适合的分区域算法,使之更适合应用于现实区块链。
