基于SASK 和双分支结构的服装图像识别方法
2023-12-04周啸辉张睿婷熊邦书欧巧凤
周啸辉,余 磊,张睿婷,熊邦书,欧巧凤
南昌航空大学图像处理与模式识别江西省重点实验室,江西南昌330063
近年来,随着电子商务行业的快速发展,通过网络销售的服装数量飞速增加,由此产生了大量的服装图像数据。对服装图像进行识别不仅有利于准确检索服装图像,而且可以更好地预测服装商品的消费趋势,为构建服装商品推荐系统奠定基础[1]。因此,服装图像识别越来越受到国内外学者的关注[2]。
传统方法通过手动方式提取图像特征,并结合相应的分类器进行识别[3]。这种方法提取的特征往往不能准确表征服装类别,识别准确率较低。深度学习在计算机视觉、自然语言处理和语音识别等领域取得了巨大成功[4-6],因其能够自动提取图像特征,在服装识别领域优于传统方法,并逐渐成为该领域的研究热点[7]。
研究人员将深度学习方法运用于服装识别领域,因而出现了一系列识别方法。文献[8] 提出了基于残差模块和胶囊网络(capsule network,CapsNet)模块的ResCaps 网络识别方法,该方法增强了胶囊网络的特征提取能力。文献[9] 提出了基于Inception-v3 和迁移学习的识别方法,该方法结合迁移学习思想解决了训练样本不足的问题。文献[10] 提出了基于最大边距多尺度卷积因子分析(max-margin multi-scale convolutional factor analysis,MMCFA)模型的识别方法,有效利用了最大边距学习能增强判别性能的特性。文献[11] 提出将VGG16 模型与层次卷积神经网络(hierarchical convolutional neural networks,H-CNN)结合的识别方法,提升了VGG16 模型的识别效果。文献[12] 基于注意力机制提出双重注意力胶囊网络(dual attention mechanism capsule network,DA-CapsNet),提升了分类性能。
上述方法虽然都取得一定效果,但仍存在不足:首先,上述方法均为单分支神经网络,对于较亮的图像识别效果较好,而对于较暗的图像,因其特征不明显,会导致网络提取整体特征不足,从而识别效果较差;其次,网络卷积核大小固定,对于不同尺度的图像,识别对象呈现的位置、大小不同,使得网络未能较好地关注服装对象形态特征信息,从而导致识别效果不佳。在日常生活中,光照强度不同会导致图像明暗不一,拍摄距离不同也会使图像尺度各异。因此,研究具有不同光照、尺度特点图像的识别方法,在服装识别领域具有重要意义。
针对神经网络卷积核固定,从而对不同尺度图像识别效果不佳的问题,文献[13] 设计了SKNet(selective kernel network)模型,根据不同对象可以自适应地调节神经元感受野大小,从而增强识别能力。然而,对于能更好表征对象形态信息的空间特征,该模型并未进一步增强,使得识别效果仍然不佳。
为解决上述问题,本文提出了一种基于空间注意力选择核(space attention selective kernel,SASK)模块和双分支结构的服装图像识别方法:首先,构建双分支神经网络模型,充分提取图像的整体特征,解决现有网络对较暗图像提取特征不足的问题;其次,从空间注意力角度出发设计SASK 模块,使网络能更多地关注识别对象形态特征信息,从而解决SKNet模型识别精度不足的问题。FashionMNIST 和DeepFashion 数据集在服装识别领域应用广泛,且图像具有明暗不一、尺度各异的特性,因此本文选择在这两个数据集上验证模型性能;同时,还在同样具有这两个特性的书写体数据集EMNIST Digits 上进行实验,用以验证模型的泛化性能。
1 基于SASK 的双分支神经网络模型
1.1 SASK 模块
SKNet 基于通道注意力而设计,但对于不同尺度的识别对象,并未很好地关注能更好表征识别对象形态特征的空间信息,使得识别效果仍有待提高。于是本文从空间注意力角度出发,设计了SASK 模块,构建一种动态选择机制使神经元可以针对不同对象调整感受野,从而能够更多地关注识别对象形态特征信息。该模块由Split、Fuse 和Select 三个子模块组成,如图1 所示,具体内容如下。
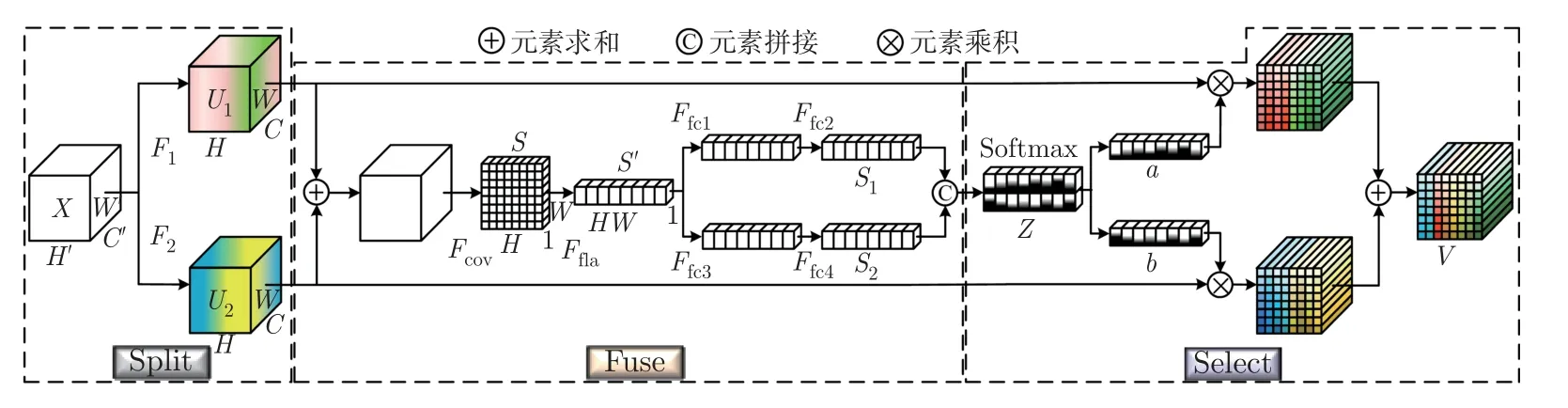
图1 SASK 模块Figure 1 SASK module
1)子模块Split。对于任意给定特征图X ∈RH′W′×C′(H′、W′、C′分别表示X的高、宽和通道数),进行如下两个变换。
F1、F2是分别经过核大小为3×3、5×5 的卷积操作,批归一化(batch normalization)和ReLU 激活函数处理的映射过程,其中,H、W、C分别表示经变换后所得特征图U1和U2的高、宽和通道数。
2)子模块Fuse。对空间像素的相关性进行建模,得到表征图像空间像素点重要程度的描述符,具体过程如下:
首先,对特征图U1和U2逐元素相加,以进行特征融合,具体为
其次,使用1×1 卷积对融合特征图U进行通道压缩,将通道信息压缩到空间描述符中,生成空间信息的统计量S ∈RHW×1,具体为
再次,调整S的维度S′=Ffla(S),S′∈RHW×1。为了能更好地表征图像空间关系,对空间统计信息S′,经过两个全连接层以进行充分的信息交互,并且使用ELU 激活函数增强非线性表达能力,之后通过Sigmoid 函数获得归一化权重。
经过上述两个独立的变换,得到不同尺度(经过3×3、5×5 卷积映射)下,表征空间像素点重要程度的描述符S1、S2,S1∈RHW×1,S2∈RHW×1,δ为ELU 激活函数,σ是Sigmoid激活函数,W1,W2,W3,W4∈RHW×HW。
最后,联接两个描述符,得到联合描述符Z ∈RHW×2,C表示在通道维度上进行拼接。
3)子模块Select。计算经不同卷积操作所得特征对应像素点权重,据此进行特征筛选,增强重要信息,具体过程如下。
首先,使用Softmax 函数对Z进行归一化处理,可得两个描述U1、U2对应像素点重要程度的权重向量a、b。
式中:e 为自然底数。
其次,将a、b分别乘以U1、U2后再相加,得到最终优化后的特征图V
式中:Vi ∈R1×C表示特征图V第i个像素点的特征信息,ai和bi分别表示a和b的第i个元素,V=[V1,V2,···,Vi,···,VHW]。其中,H、W表示特征图高和宽。
1.2 双分支神经网络
针对单分支网络提取整体特征效果较差的问题,本文设计了双分支神经网络模型,其结构如图2 所示。该模型中的池化层参数均相同,核大小为3×3,步长为2,填充为1,卷积与全连接层的相关参数如表1 所示。为了更丰富地表征原始图像信息,本文在双分支结构之前,采用多尺度卷积[14]提取输入图像特征。

表1 基于SASK 的双分支神经网络相关参数Table 1 Correlation parameters of two branch neural network based on SASK

图2 基于SASK 的双分支神经网络模型Figure 2 Two branch neural network model based on SASK
结合跳跃连接[15]和稠密连接[16]的思想,本文设计了双分支结构中的Conv Block1 模块。其中,跳跃连接融合浅层与深层特征,实现不同层次信息之间的交互;稠密连接聚合多个卷积之间的信息,一方面加强特征的传递,另一方面可以更有效地利用特征信息。这样使Conv Block1 模块能够保证各层间信息最大程度地传递,增强特征提取能力。
结合多尺度卷积和通道拆分[17]的思想,本文设计了双分支结构中的Conv Block2 模块。其中,多尺度卷积可以提取多样化的特征信息;通道拆分操作可以减少冗余信息,增加信息交互。这样使Conv Block2 模块能够保留更多的细节信息,从而提升网络的分类性能。
此外,本文舍弃在全连接层之后接一个Dropout 操作的方式,而是进行批归一化处理。这样可以避免梯度分散,从而保证特征信息稳定分布,提高网络的泛化性能和收敛速度。
2 实验结果与分析
2.1 数据集
FashionMNIST 和DeepFashion 作为服装数据集中的经典代表,备受国内外学者的关注;EMNIST Digits 是手写体数据集中的典型代表,且具有明暗不一、尺度各异的特性。本文使用这3 个数据集验证模型的性能及泛化性。
FashionMNIST 数据集由德国公司Zalando 提供,共有10 类商品的7 万幅正面图像。数据集为28×28 的灰度图,其中6 万幅图像作为训练集,1 万幅图像作为测试集。该数据集10类商品如图3 所示,依次是T 恤、裤子、套衫、裙子、外套、凉鞋、衬衫、运动鞋、包和短靴。

图3 FashionMNIST 数据集示例Figure 3 Example of FashionMNIST dataset
DeepFashion 数据集包含不同角度、不同场景46 类,共289 222 幅图像。为了便于与文献[18] 进行对比,本文选择Dress(连衣裙)、Jeans(牛仔裤)、Joggers(慢跑裤)、Shorts(短裤)、Skirt(半身裙)、Sweater(毛衣)、Tank(背心)、Tee(T 恤)等8 个类别,如图4 所示。

图4 DeepFashion 数据集示例Figure 4 Example of DeepFashion dataset
EMNIST Digits 数据集包括10 类手写体数字,共28 万幅28×28 的灰度图,其中训练集包含24 万幅图像,测试集包含4 万幅图像。该数据集10 种类别(数字0∼9)如图5 所示。

图5 EMNIST Digits 数据集示例Figure 5 Example of EMNIST Digit
从图3∼5 可以看出,图3 中裙子和外套,图4 中(e) Skirt 和(h)Tee,图5 中数字7 和9等是在不同光照强度下拍摄的,图3 中包和短靴,图4 中(d) 两张Shorts 的对比图,图5 中数字1 和8 等具有不同的尺度特性。
2.2 实验参数
本文在Debian 操作系统下,使用NVIDIA GTX1080Ti GPU 运行程序,以Pytorch 为基础框架编写代码。训练过程选用交叉熵损失函数,并且采用Adam 优化算法,学习率设置为0.000 1。在FashionMNIST 中总批次设置为200 轮,批大小为64;在DeepFashion 中总批次设置为200 轮,批大小为128;在EMNIST Digits 中总批次设置为80 轮,批大小为128。
2.3 结果与分析
2.3.1 本文模型测试结果
根据以上参数进行实验,在FashionMNIST 数据集上测试准确率为94.21%,每个类别的混淆矩阵如图6 所示。
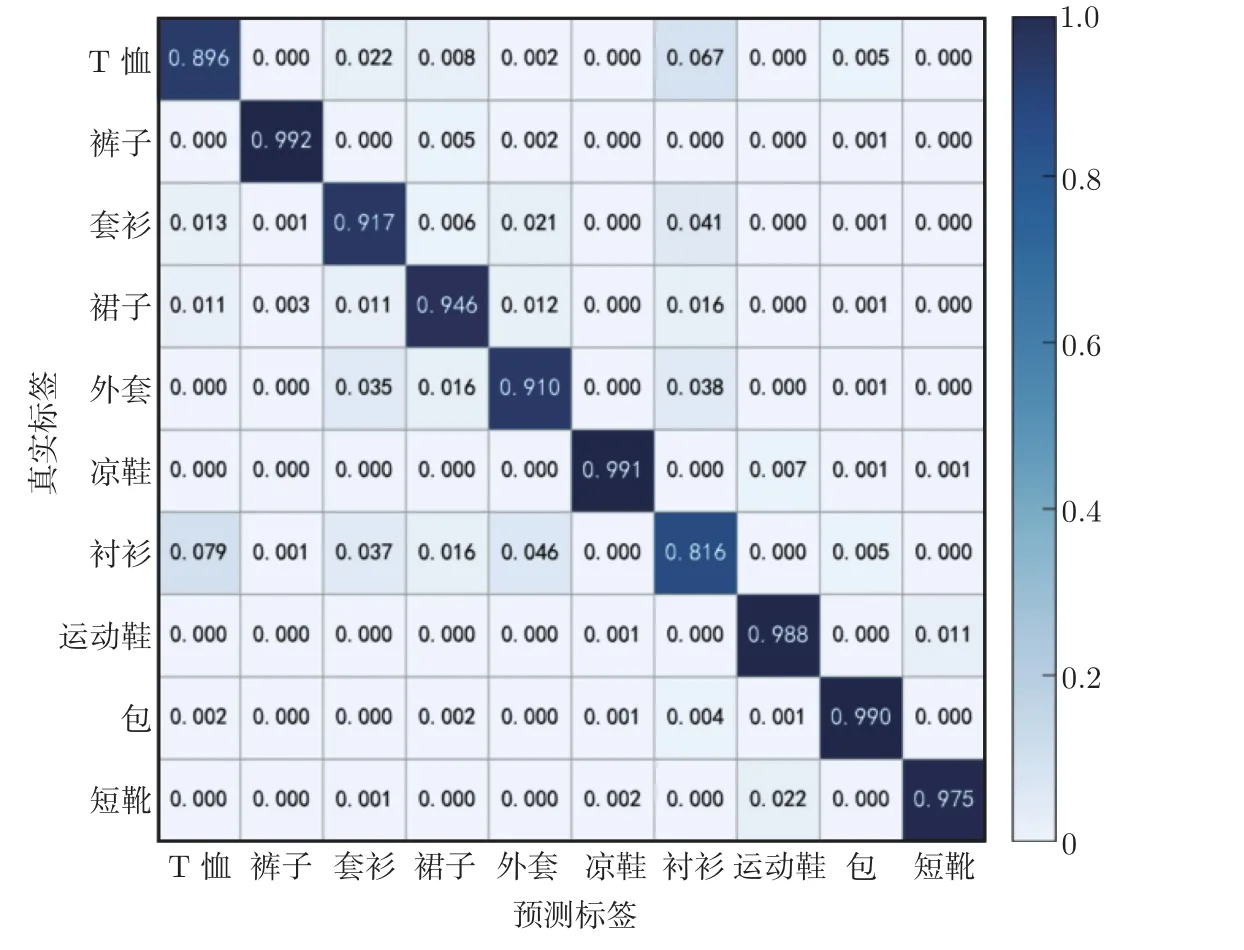
图6 FashionMNIST 数据集混淆矩阵Figure 6 FashionMNIST dataset of confusion matrix
从图6 可以看出,衬衫的识别率最低,为81.6%,这是因为其易与T 恤、套衫和外套混淆。错误识别的图像示例如图7 所示。

图7 衬衫错误识别图像示例Figure 7 Example of an incorrectly identified image of a shirt
从图7 中可以看出,误判的图像与这3 类图像存在较高的相似性,表明FashionMNIST数据集样本存在显著类别间相似性的问题;可以借鉴细粒度图像识别领域的研究思想,引入相关特征增强(correlation feature strengthening,CFS)模块。首先,提取具有判别性的局部区域特征;其次,根据区域特征内部的相关性,采用加权的方式融合局部区域的特征,从而增强每个区域的特征,提高网络的识别性能。
除此之外,其他各类别的识别率均在89%以上,这表明本文模型识别精度较高。在EMNIST Digits 数据集上,测试准确率为99.78%,每个类别的混淆矩阵如图7 所示。从图8中可以看出,各个类别的识别率都在99.67% 以上,这表明本文模型识别效果较好,仅有极少数由于书写不规范而难以区分。
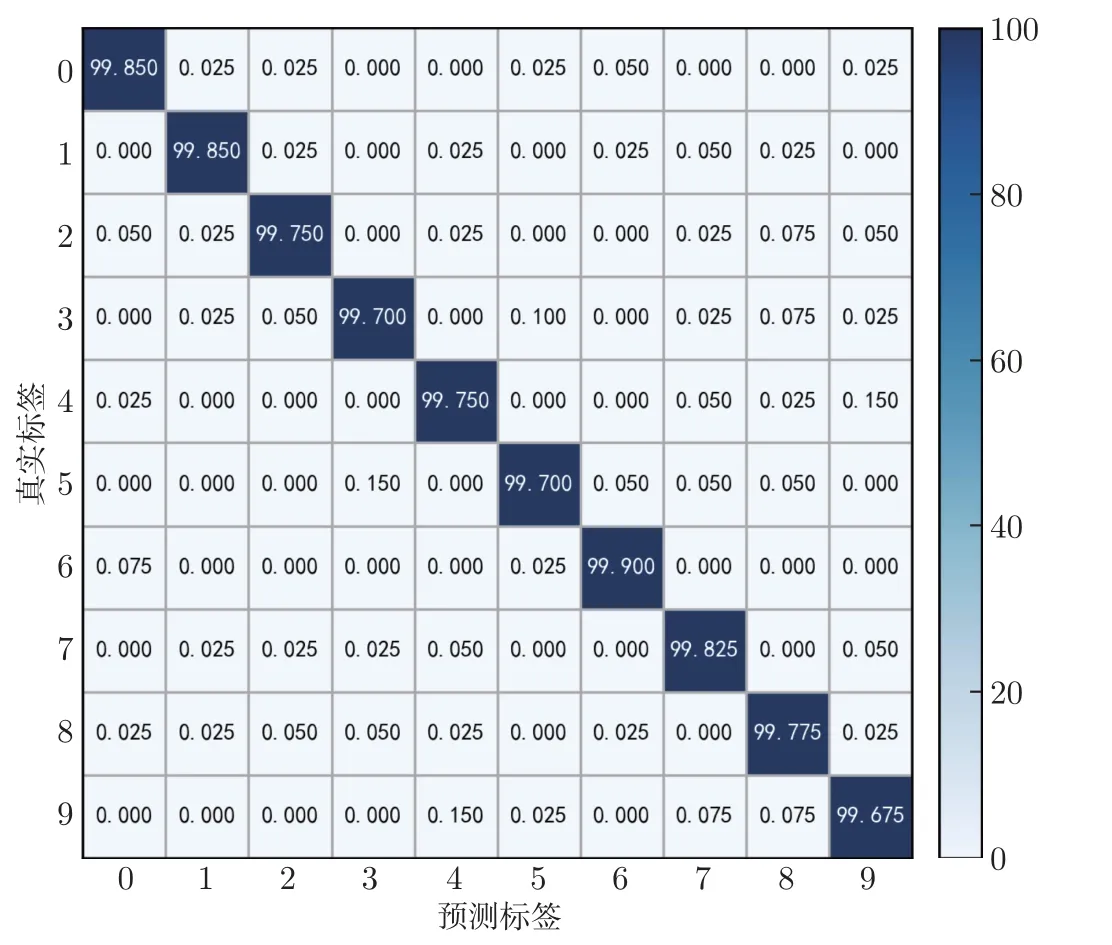
图8 EMNIST Digits 数据集混淆矩阵Figure 8 EMNIST Digits dataset of confusion matrix
2.3.2 SASK 与SK 模块对比实验
SASK 模块旨在更多地关注识别对象形态特征信息,提高网络识别精度。为验证其有效性,保持其他条件不变,将本文所提出的网络模型(双分支结构+SASK)与用SK 模块替换SASK 模块构成的网络模型(双分支结构+SK)进行对比实验,结果如表2 所示。

表2 SASK 模块实验结果对比Table 2 Comparison of experimental results of SASK module %
从表2 可以看出,在FashionMNIST、DeepFashion 和EMNIST Digits 中,相对于SK 模块,SASK 模块提高了0.40%、0.46% 和0.12% 的识别精度,表明该模块性能优良。
此外,为了便于观察网络模型学习的关键区域特征,本文对由SASK 模块或SK 模块构成的双分支神经网络模型,采用Grad-CAM(gradient-weighted class activation mapping)算法将其提取的图像特征进行可视化呈现,结果如图9 所示。
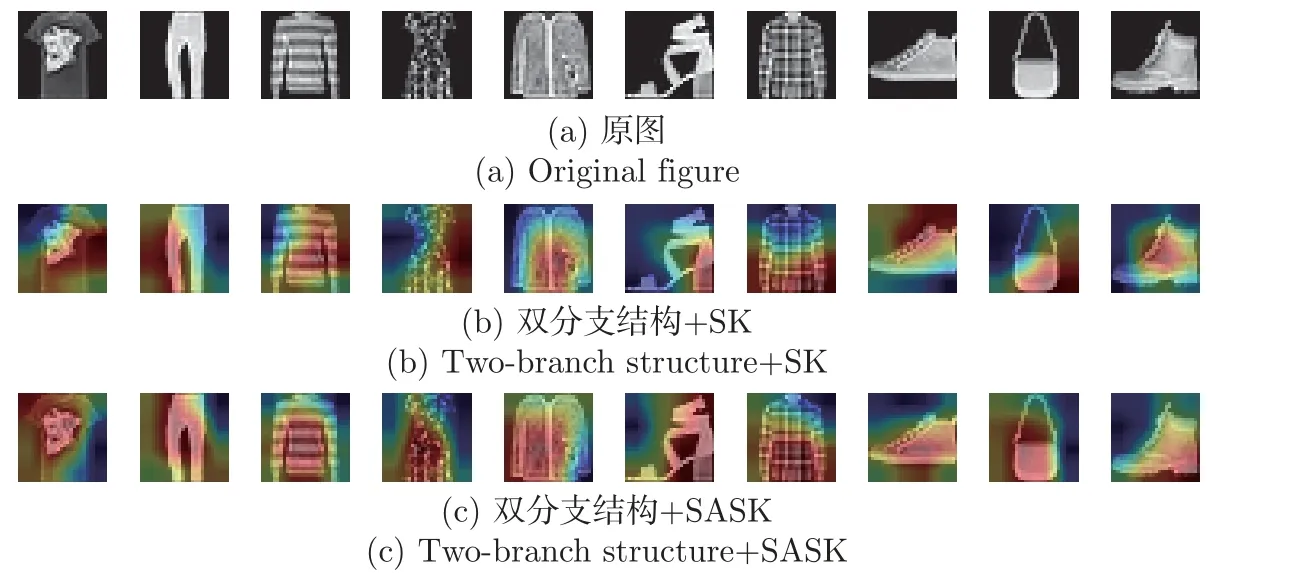
图9 特征分布热力图Figure 9 Characteristic distribution thermodynamic diagram
图9(a) 为原始服装图像,图9(b)∼(c) 为特征热力图,颜色越深表示识别越依赖该区域信息。从图9 可以看出,SASK 构成的模型提取识别对象的特征更加全面,细节信息也更加丰富。
2.3.3 与主流算法对比结果
在FashionMNIST 数据集上,目前一些较新的主流识别方法,如ResCaps、MMCFA、VGG16 H-CNN、DA-CapsNet 等,均取得较好的效果。将本文构建的网络模型与这4 种方法进行对比,实验结果如表3 所示。

表3 FashionMNIST 实验结果对比Table 3 Comparison of FashionMNIST experimental results %
从表3 可以看出,本文模型识别率达到94.21%,比这4 种方法分别高出了1.95%、1.85%、0.68%、0.23%。在DeepFashion 数据集上,本文与文献[18] 所述方法的对比如表4 所示。

表4 DeepFashion 实验结果对比Table 4 Comparison of DeepFashion experimental results %
从表4 可以看出,本文模型准确率为82.75%,高于文献[18] 所述方法。
从上述两个数据集的对比实验中可以看出,本文模型识别率超出了现有方法,具有一定的先进性。
在EMNIST Digits 数据集上,目前一些经典的识别方法,如CSA-CNN[19]、Genetic DCNN[20]、NeuroEvolved CNN[21]、CELM[22]等,均取得较好的识别效果。CSA-CNN 运用克隆选择算法(clonal selection algorithm,CSA)自适应地构建神经网络模型;Genetic DCNN利用遗传进化算法设计神经网路模型;NeuroEvolved CNN 利用神经进化算法来优化神经网络结构;CELM 结合极限学习机(extreme learning machines,ELM)和卷积神经网络设计而成。将本文构建的网络模型与这4 种方法进行对比,实验结果如表5 所示。从表5 可以看出,本文模型取得最高准确率99.78%,高于CSA-CNN、Genetic DCNN 和NeuroEvolved CNN方法,与CELM 方法相当。这表明本文模型泛化性能良好。

表5 MNIST Digits 实验结果对比Table 5 Comparison of MNIST Digits experimental results %
在FashionMNIST 数据集和EMNIST Digits 数据集上的实验结果表明,本文所提出的模型具有良好的识别能力和泛化性能。
3 结语
本文提出了一种基于SASK 和双分支结构的服装图像识别方法。首先,结合跳跃连接、稠密连接和多尺度卷积、通道拆分的思想,设计双分支神经网络模型;其次,从空间注意力角度出发,构建SASK 模块。该方法不但可以充分提取服装对象的整体特征,而且能够较好地关注服装对象形态特征信息。本文所提方法在典型服装数据集FashionMNIST 和DeepFashion上的识别精度分别为94.21% 和82.75%,在具有明暗不一、尺度各异特性的手写体数据集EMNIST Digits 上的识别精度为99.78%,均优于经典方法,充分体现其具有优异的识别效果和良好的泛化能力。
