基于随机森林的离合器制造过程质量控制方法研究
2023-12-04沈维蕾张鑫洋杨雪春
沈维蕾, 张鑫洋, 杨雪春
(合肥工业大学 机械工程学院,安徽 合肥 230009)
汽车在日常生活中不可或缺,近年来,人们对汽车的需求持续增长,汽车产量呈现飞速增长的趋势[1]。离合器由于使用的特殊性,其市场容量比汽车整体的市场容量大[2],提高离合器的质量对提高汽车整体质量、降低经济损失有重要意义[3-4]。目前针对改进汽车传动系统质量的研究,大多从离合器设计方面进行改进,对生产制造过程的研究并不多。因此,本文通过收集生产数据,并对制造过程进行统计过程分析,以研究如何提高制造过程质量的稳定性。
文献[5]针对以小样本、多变量为主要特征的油田产量预测问题,对比发现随机森林预测的结果最接近油田真实产量;文献[6]采用傅里叶变换红外光谱与随机森林结合的新方法进行试验,结果表明该方法对低浓度泰乐菌素的预测结果比较准确;文献[7]实现并设计开发了植物叶片病害分类模型,对比发现随机森林分类器分类效果最好;文献[8]就滚刀故障诊断问题,提出基于谱图小波变换与随机森林相结合的故障诊断方法,试验结果表明该方法能达到90%以上的识别精度;文献[9]研究了滚动轴承工作故障信息获取困难的问题,提出一种基于随机森林的故障识别方法,建立相关故障识别模型,并与多种分类器相比较,结果表明提出的方法准确度更高;文献[10]提出将随机森林与频繁模式相结合的分类方法,该方法可通过最大化来控制每个子模型的欠拟合与过拟合问题;文献[11]就面部识别问题,提出使用聚合方法与随机森林相结合的方法,实际应用证明该方法比以前的方法更优越;文献[12]针对多类疾病的分类问题,提出结合属性评价者方法和实例过滤方法改进的随机森林算法,实践结果表明,针对多类疾病数据集,改进后的算法性能更佳;文献[13]提出基于随机森林的糖尿病预测模型,结果表明该模型的预测结果可信度较高;文献[14]建立基于随机森林的机器学习算法模型,从而预测药物依从性,对过去8年的数据进行回顾性分析,结果表明该方法可应用于多因素的预测;文献[15]提出基于随机森林的心脏病预测方法,通过与多目标粒子群算法相结合生成多样化和精确的决策树,结果表明该方法可以提高预测精度。
综合发现,随机森林在多个领域应用良好,在分类上识别结果准确度高。相较于其他机器学习方法,随机森林具有运算量小、实现简单的优点。因此,本文将研究随机森林在控制图模式识别方面的应用。
1 控制图模式识别
休哈特控制图是统计过程控制(statistical process control,SPC)中最重要的工具之一,可以实现对生产过程的监视与控制,用于反映指定进程是否按计划运行,体现可能存在的一些不规则进程变化的原因。控制图中的正常模式表示进程处于正常状态,没有任何故障或变化。除正常模式外,还有周期模式、阶跃上升模式、阶跃下降模式、逐渐增加模式、逐渐减少模式等异常模式,如图1所示。

图1 控制图模式分类
1) 正常模式下控制图的产品质量观测值符合正态分布规律,在控制限内随机分布,上下不断波动。
2) 周期模式的图像中产品质量观测值围绕中心线上下呈周期性变化趋势。
3) 逐渐下降模式和逐渐上升模式表现为质量观测值呈现下降或者上升趋势,这种趋势是持续发生的。
4) 阶跃下降模式的质量观测值会在某一观测点突然整体向下偏移,且偏移过后质量观测值不再上升;阶跃上升模式则是在某一观测点质量观测值整体突然向上偏移,且偏移过后不再回落。阶跃模式最显著的特点是断崖式偏移。
准确地识别控制图模式(control chart patterns,CCP)可以监控生产过程是否正常,防止不合格品的产生。
2 随机森林算法
在机器学习方法中,随机森林是一种比较经典的算法。文献[16]提出了随机森林方法,该方法通过随机的方式建立一个由决策树组成的森林,每一棵树之间相互独立。决策树通过拆分预测变量并递归划分数据集来描述因变量与1个或多个自变量之间的关系[17-18],其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样本集。
因此,随机森林是一个由单株分类器{h(X,θk);k=1,2,…}组成的分类器,其中θk是独立同分布的随机变量。在输入X后,每棵决策树只投1票给它认为最合适的分类标签,最后选择投票多的那个分类标签作为X的分类。
引入随机变量θk是为了控制每棵树的生长,通常针对于第k棵决策树引进随机变量θk,它与前面的k-1个随机变量是独立同分布的,利用训练集和θk生成第k棵树,也就等价于生成一个分类器h(X,θk),其中X为一个输入向量。
对于给定的一系列分类器h(X,θ1),h(X,θ2),h(X,θ3),…,h(X,θk),随机地选择一些样本,设其中的X为样本向量,Y为正确分类的分类标签向量。定义边际函数为:
mg(X,Y)=aVk(I(h(X,θk)=y))-
(1)
其中:I()表示示性函数;aV()表示取平均值。边际函数表示在正确分类Y之下X的得票数目超过其他分类的最大得票数目,该值越大表明分类的置信度越高。
泛化误差公式为:
PE=PX,Y(mg(X,Y)<0)
(2)
其中,X、Y表示概率的定义空间。
根据大数定律中的辛钦定理,当决策树数目增加时,对于所有的序列θk和PE都会收敛到下式,对应于大数定律里的频率收敛于概率,即
PX,Y{Pθ[h(X,θ)=y]=
(3)
因此随机森林不会随着决策树的增加而过度拟合,并且有一个有限的泛化误差值。随机森林算法在小样本、多特征的数据集上表现良好,在学习过程中具有很好的抗噪声能力,分类识别结果准确度高。
3 基于随机森林的识别模型
3.1 随机森林模型的搭建
随机森林外部应用Bagging框架,基模型为决策树。Bagging框架中的子训练集是通过训练集自助采样得到的,具有相互独立性,测试集得到的预测结果是对基模型的结果综合。Bagging框架下的综合预测一般采用投票法,随机森林框架如图2所示。
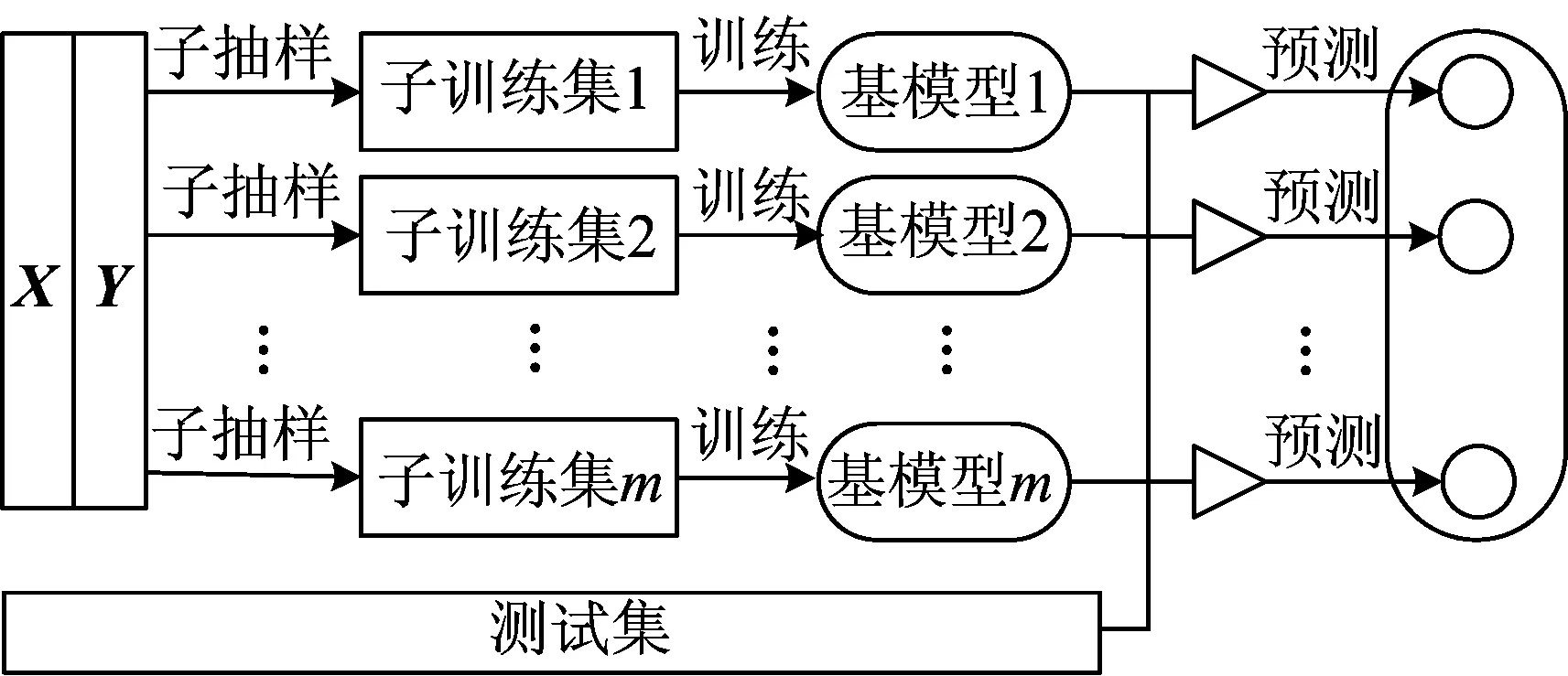
图2 随机森林框架
2种采样方法保证了算法的随机性,因此随机森林的基模型不需要进行减枝,可以做到尽可能地生长也不过拟合。故随机森林在各类数据集上表现良好,可以最大可能地保留原始数据特征,不需要进行数据特征选择,这也是它的优势。
随机森林中最重要的是树的生成,每棵树的生成遵从一定的规则。
1) 假设模型总训练集的大小为N,则对每棵决策树,都是通过自助采样法从训练集中抽取一定数量的样本作为训练样本,总共抽取N个样本作为该树的训练集,重复k次,对应生成k组训练样本集。
2) 每个特征的样本维度为M,指定一个常数m∈M,从M个特征中随机选取m个特征。
3) 利用m个特征让每棵树生长到最大程度,不需要剪枝,尽可能保留数据特征。
最终得到应用随机森林模型进行分类的算法流程,如图3所示。
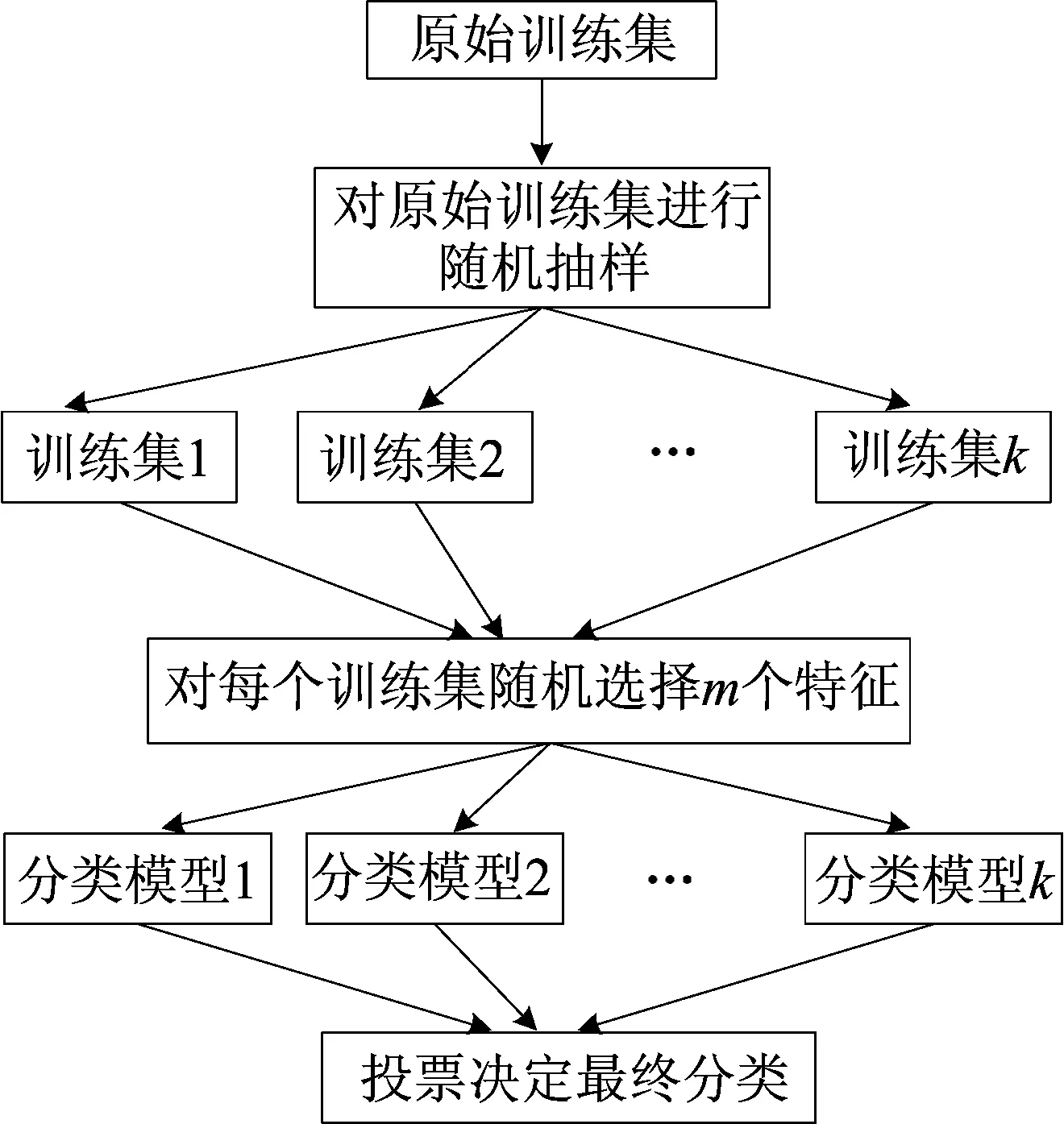
图3 随机森林分类算法流程
3.2 基于随机森林的识别模型
基于随机森林的控制图模式识别模型如图4所示。该识别模型主要工作步骤如下:

图4 基于随机森林的控制图模式识别模型
1) 确定生产工艺中的关键工序,并获取关键参数相关数据;运用SPC有目的地收集生产数据;对生产数据进行处理,并根据生产数据特征选择合适的控制图。
2) 当生产异常模式样本数据不足时,可以根据生产数据关键参数特征进行仿真实验,从而获取充足的生产数据;从仿真数据中抽取适量的生产数据样本,对随机森林模型进行训练,抽取k个样本,同时生成k个数据模型,完成模型训练。
3) 使用该模型对预测集数据样本进行预测,通过预测结果进行分析,证实其可行性和有效性,并分析其识别精度。
4) 通过模式输出结果确定生产质量控制模式,判断生产状况是否正常,并进行质量诊断分析。
3.3 模型评价指标
模型的评估指标有准确率、精准度、召回率和F1值。其中准确率也是最简单的指标,但存在明显的缺陷,且存在错误率。测试集中被判定为正样本的数量记为TP,判定为负样本数量记为FN;负样本被判定为负样本的数量记为TN,被判定为正样本的数量记为FP。本文采用精准度、召回率以及精准度与召回率的加权调和平均进行模型评价[19]。
1) 精准度(Precision)P1也叫查准率,定义为:
(4)
2) 召回率(Recall)R也叫查全率,定义为:
(5)
3)F1值来自精准度与召回率的加权调和平均,定义为:
(6)
4 应用实例
SPC通过控制图理论对关键工序进行过程诊断与控制,可以避免大量不合格品的出现。离合器是汽车传动系统中的重要元件,汽车离合器有摩擦式离合器、液力变矩器(液力耦合器)、电磁离合器等几种。从装配过程来看,离合器的装配分为两大部分,即盖及压盘部分和从动盘部分。通过现场调查发现,压盘升程既是盖及压盘总成特殊特性,也是工序零件特殊特性。因此本文基于SPC对离合器装配过程的关键质量特性——压盘升程进行控制图模式识别,找出引起质量问题的系统性因素,并对出现的质量问题及时进行识别和纠正。
压盘升程是指压盘离开摩擦片后的轴向后移距离,是离合器能否正常分离的重要参数。若压盘升程偏小,将发生离合器半分离半接合的现象,即分离不彻底;不彻底将使离合器磨损过快,换挡产生冲击,甚至可能导致离合器损坏,在行驶过程中无法换挡,行驶速度不受控。压盘升程的质量合格与否直接影响离合器的功能。
根据特殊特性选择压盘升程,从压盘升程的计算原理、数据特点上按照控制图选取流程,最终选择均值极差控制图。压盘升程的技术标准为1.30~1.65 mm。因为生产实际过程中异常模式生产样本数据不足,获取足够的异常模式样本所耗费的成本过大,所以通过采用蒙特卡洛方法生成样本数据,确定了6种基本控制图模式的参数,利用MATLAB仿真获取。
为满足模型训练样本的需求,模型应用的控制图采用均值控制图。本文将所得数据处理为均值控制图所需的样本数据,最终得到每种均值控制图模式的样本量为50组,其中每一组包含25个数据均值样本点,共300组生产数据。从样本数据结果计算得出,压盘升程的均值控制上限为1.540 mm,控制中心限为1.495 mm,控制下限为1.450 mm。
对所获得的样本数据进行预处理,并将6种不同模式分别标注,标签为1,2,…,6;每种模式内的特征值有25个,标注为d1,d2,…,d25。
本文总共利用300组数据,为避免数据分布不均等造成模型结果的误差,采用五折交叉验证法对模型进行评估。五折交叉验证法即将样本数据随机、均匀地分为5份,轮流用其中4份训练模型,余下的1份作为测试集,以此来测试模式的准确率,最后取5次模型的准确率均值作为模型的准确率。
4.1 基于随机森林的离合器质量控制
基于随机森林的离合器控制图模式识别模型结果评价采用五折交叉验证法,其中一组测试结果的混淆矩阵如图5所示。

图5 混淆矩阵结果
从图5的混淆矩阵可以直观地看出,实际结果与预测结果基本吻合,预测结果中仅有1例实际类别为类别3的模式判断为类别6,导致输出结果错误。
模型预测结果数据如下所示:
1) 实际结果为[1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6];
2) 预测结果为[1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 6 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6];
3) 精准度为0.983 333 333 333 333 3;
4) 召回率为0.983 333 333 333 333 3;
5)F1值为0.983 333 333 333 333 3。
五折交叉验证所得结果见表1所列。
从表1可以看出,接受者操作特性曲线(receiver operating characteristic curve,ROC)平均值为0.989。平均值为模型的最终评估数据,代表模型的准确度。
ROC曲线如图6所示。
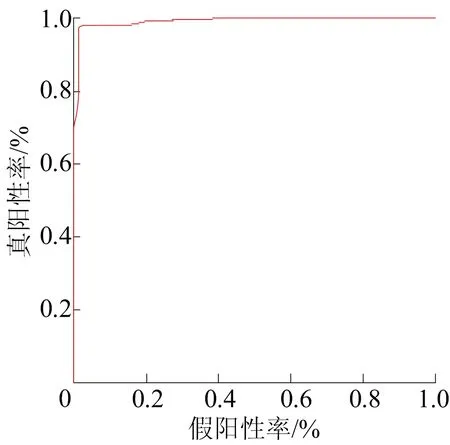
图6 ROC曲线
4.2 与其他机器学习算法的对比
随着训练数据的增加,模型的预测精度必然有所提升。为验证随机森林的模型性能,本文采用同样的数据样本,将随机森林算法与不同机器学习算法所建模型的结果进行对比分析。分别构建基于支持向量机(support vector machine,SVM)的控制图模式识别模型和基于逻辑回归(logistic regression,LR)算法的控制图模式识别模型,并采用离合器的相关数据进行模型训练与测试。
SVM五折交叉验证结果见表2所列。由表2可知,该模型准确率为0.953。
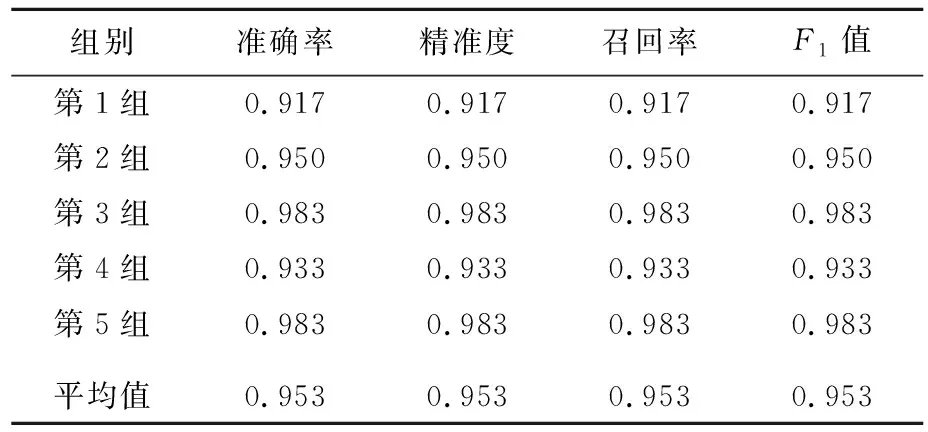
表2 SVM算法下五折交叉验证结果
LR五折交叉验证结果见表3所列。由表3可知,该模型准确率为0.654。

表3 LR算法下五折交叉验证结果
最终获取3种不同机器学习算法的模型预测结果指数,见表4所列。

表4 不同机器学习算法模型预测结果指数对比
从表4可以看出,基于机器学习算法的控制图模式识别模型中,同样的数据样本条件下,随机森林要优于其他算法。可知,随机森林具有非常明显的优势,它不需要过多的模型训练就能达到一个极高的精确度,从效率上要高于其他算法,适用于现有的小批量多品种生产模式,能够有效地提高生产质量控制。
5 结 论
本文针对控制图模式识别问题搭建了基于随机森林的控制图模式识别模型,通过离合器的实例应用验证其可行性与实用性,提高了生产人员在生产过程中对产品质量的控制,从而为减少产品质量问题,提前预知异常的发生提供技术支持。本文的主要工作如下:
1) 针对控制图控制线内系统性因素识别能力不足的问题,提出了基于随机森林的控制图模式识别分类模型,搭建了随机森林算法的学习框架,并采用网格搜索对随机森林模型进行参数优化,建立了基于随机森林的控制图模式识别模型。
2) 以离合器制造过程为应用实例,将基于随机森林的控制图模式识别模型应用于离合器装配关键质量特性——压盘升程中,并与SVM和逻辑回归的控制图模式识别模型进行比较,通过五折交叉验证进行模型评估;结果表明,在控制图分类识别方面随机森林算法比其他机器学习算法准确率最高、性能更优越。
