MatChat: A large language model and application service platform for materials science
2023-12-02ZiYiChen陈子逸FanKaiXie谢帆恺MengWan万萌YangYuan袁扬MiaoLiu刘淼ZongGuoWang王宗国ShengMeng孟胜andYanGangWang王彦棡
Zi-Yi Chen(陈子逸), Fan-Kai Xie(谢帆恺), Meng Wan(万萌), Yang Yuan(袁扬),Miao Liu(刘淼), Zong-Guo Wang(王宗国),§, Sheng Meng(孟胜), and Yan-Gang Wang(王彦棡)
1Computer Network Information Center,Chinese Academy of Sciences,Beijing 100083,China
2University of Chinese Academy of Sciences,Beijing 100049,China
3Institute of Physics,Chinese Academy of Sciences,Beijing 100190,China
4School of Physical Sciences,University of Chinese Academy of Sciences,Beijing 100190,China
5Songshan Lake Materials Laboratory,Dongguan 523808,China
6Center of Materials Science and Optoelectronics Engineering,University of Chinese Academy of Sciences,Beijing 100049,China
Keywords: MatChat,materials science,generative artificial intelligence
1.Introduction
At present, large language models (LLMs) have established a robust foundation for various applications.OpenAI’s ChatGPT and GPT-4.0,[1]with 175 billion and 18 trillion parameters,respectively,clearly represent a new era in the development of artificial intelligence (AI).However, OpenAI has not disclosed the specific details of the training methods and parameters of the model.Tsinghua’s GLM base model[2,3]provides a compelling option for natural language processing.It supports both English and Chinese,offering high accuracy,cross-platform compatibility, reproducibility, and fast inference.Baidu’s Ernie 3.0 Titan,an evolution of the Ernie series models[4–6]with an impressive 260 billion parameters,stands as the largest Chinese dense pre-training model to date, with great potential for deep language understanding and applications.The LLaMA and LLaMA2 models,[7,8]ranging from 7 billion to 70 billion parameters, contribute to the diversity of open-source large language models,catering to various applications.The Ziya-LLaMA-13B pre-training model[9]exhibits robust capabilities across domains such as translation,programming,text classification,information extraction,summarization, copywriting, common sense question answering,and mathematical computation.The outstanding performance of these models offers strong support for various tasks and holds the promise of unlocking potential in other domains.
Fine-tuning open-source large models has emerged as an effective method for tailoring AI capabilities to meet the specific demands of various domains.Currently, finetuning techniques have demonstrated considerable success in vertical fields, including healthcare, education, and finance.In the field of healthcare, models like HuatuoGPT[10]and DoctorGLM[11]have been developed to address medical challenges,these models exhibit a high degree of professionalism and offer invaluable insights within the healthcare domain.In the finance sector, notable strides have been made with the XuanYuan[12]model, its application has brought substantial benefits and advancements to financial operations.Similarly,in the education sector, the EduChat[13]model has demonstrated its worth by delivering valuable capabilities tailored to educational contexts.Additionally, the Fengshenbang[14]large model system, a product of the Cognitive Computing and Natural Language Research Center at IDEA Institute,has gained widespread recognition.The Fengshenbang large model system is a Chinese language-centric ecosystem that includes pre-training of large models and fine-tuned applications tailored for specific tasks,benchmarks,and datasets.Its overarching objective is to create a comprehensive, standardized,and user-centric ecosystem.
In recent years,researchers have achieved significant and innovative results in the discovery of new materials[15–19]and their theoretical interpretation[20,21]by leveraging the existing database such as Atomly,[22]OQMD,[23]MaterialsProject,[24]and others.They have successfully explored the intricate relationships between material structure and properties,[25]addressing the challenges posed by the scarcity of materials data through the development of more accurate artificial intelligence optimization[26]and training methods.[27]With the application of large models,researchers in materials science have explored the use of these models to tackle challenges such as the intricate nature of chemical reactions and structures.One notable example is the MatSciBERT[28]model which is derived from BERT.[29]MatSciBERT exhibits the capability to automatically extract information from literature,conduct data mining, and construct knowledge graphs, thereby ushering in new possibilities for the application of language models in materials science.To the best of our knowledge, there has been no reported utilization of large language models in material science until now.
To advance the innovative application of large language models in materials science, this study employs a carefully constructed knowledge question–answering database to explore their potential in materials science.We propose a viable solution for predicting inorganic material chemical synthesis pathways and provide a preliminary demonstration of the feasibility of this approach.To optimize the performance of the large model in answering questions related to material synthesis knowledge,our research adopts the LLaMA2-7B model as a pre-training model.This approach involves a combination of supervised fine-tuning and reinforcement learning,incorporating valuable human feedback to enhance model optimization.The dataset selected for this purpose comprises 35675 solution-based synthesis processes[30]extracted from scientific papers.Following thorough processing, we obtain a dataset consisting of 13878 high-confidence synthesis pathway descriptions.Although the relatively modest model parameters used in this study result in cost-effective training,the model has showcased impressive comprehensive reasoning abilities.
The highlights of this study include two primary aspects.(1)Fine-tuning the LLaMA2-7B pre-training model using the preprocessed dataset of inorganic material synthesis program instruction.(2) Development of a question–answering platform for the materials synthesis large language model,aimed at facilitating work in materials science and providing an accessible and user-friendly interface for dialogue.This paper’s basic structure comprises the following sections.Section 2 focuses on the details of the model fine-tuning process.In Section 3,we explore the construction of the question–answering platform, covering aspects such as architecture design, parallel processing,resource management,and other technologies.Section 4 presents the experimental findings, and Section 5 serves as the conclusion of this study.
2.Fine-tune MatChat model methods
2.1.Base model
LLaMA2, an updated iteration of LLaMA1, has been trained by Hugo’s team[8]on a revised combination of publicly available datasets.The pretraining corpus size has been increased by 40%,the model’s context length has been doubled,and a grouped-query attention mechanism has been adopted.Variants of LLaMA2 with 7B, 13B, and 70B parameters are being released to the public.Based on the results of the paper,both LLaMA2 7B and 30B models outperform MPT models of equivalent sizes in all categories.[8]
The model in our work was fine-tuned based on the opensource large language model, LLaMA2-7B, which has 7 billion parameters,a content length of 4k,and supports up to 2.0 trillion tokens.
2.2.Materials knowledge data
The dataset used for fine-tuning the model in this paper was derived from 35675 solid-phase synthesis processes of inorganic materials extracted from over four million papers.After rigorous screening,deduplication,and cleaning,we obtained a training set consisting of 13878 highly reliable synthesis pathway descriptions.This dataset was further preprocessed and integrated into an instruction question–answering format,as shown in Fig.1.The prompts involve specific material synthesis method inquiries,and the responses provide the corresponding chemical reactions and synthesis conditions.

2.3.Training process
The model fine-tuning process utilized the following parameters, a learning rate of 10-4, a batch size of 8, and one epoch for fine-tuning.All fine-tuning operations were executed on NVIDIA A100 GPUs.In this work, one GPU card was used to fine-tune LLaMa2-7B and techniques such as low-rank adaptation(LoRA)[31]were adopted,to save storage memory and accelerate the fine-tune process by greatly reducing the trainable parameters.
When fine-tuning the LLaMA2 model, we used two methods and respective resource management strategies.Firstly, the “Parameter Efficient Model Fine-Tuning” approach aimed to make fine-tuning economically feasible on a single consumer-grade GPU.This method involved freezing the entire model and adding small learnable parameters or layers, training only a fraction of the model’s parameters.Methods like LORA, LLaMA Adapter, and Prefix-tuning were employed, addressing cost, deployment,and avoiding catastrophic forgetting.Alternatively, the“Full/Partial Parameter Fine-Tuning” method offered flexibility.We could freeze most pre-trained model layers and fine-tune only the task-specific head, add extra fully connected layers, or fine-tune all layers.For larger models,multiple GPUs might be required, especially when a single GPU couldn’t accommodate the model.To tackle multi-GPU training challenges, we used the “Fully Sharded Data Parallel” (FSDP) technique as noted on the GitHub Repository(https://github.com/facebookresearch/llama-recipes#installwith-optional-dependencies).FSDP shards data, model parameters,gradients,and optimizer states across GPUs,saving memory and enabling larger models on the same number of GPUs.
3.MatChat platform
To support researchers in obtaining fast and accurate model inference results,we have developed a set of web-based dialogue service interfaces based on LLaMA2.This section focuses on explaining how to construct these service interfaces,including the associated technical details and implementation methods.
3.1.Architecture and method design
In the development of the MatChat platform, we employed PyTorch as the core computing framework to handle tasks such as loading, running, and reasoning with large models.For the web service interface, we chose Python Flask to manage both HTTP and WebSocket requests, facilitating seamless integration with PyTorch.SocketIO was implemented for efficient,event-based two-way communication.When users request model reasoning, SocketIO delivers the model’s output in real-time,eliminating traditional polling delays.Flask is responsible for handling user HTTP requests,parsing input parameters,and scheduling model runs.
To ensure rapid user authentication and system stability,we implemented lightweight data storage in Redis for token verification and resource isolation during concurrent usage.Redis,as an in-memory data structure storage,offers fast read and write capabilities,making it suitable for high-concurrency scenarios.Furthermore, Redis-based token verification enhances system security.When a user submits a request, the system queries Redis to validate tokens,thereby enhancing security against potential malicious activity.
3.2.Concurrency processing and resource management technologies
In scenarios with concurrent access from multiple users,efficient resource management becomes crucial.To address resource contention, we implemented a waiting queue based on condition variables.This design offers several advantages as follows:
1.Automatic entry into waiting state: In situations where resources are occupied, new requests seamlessly transition into the waiting state.
2.Sequential awakening of queued requests: Upon resource release, requests within the waiting queue are sequentially awakened,allowing them to acquire the resources.
3.Thread locks for exclusive access: Thread locks guarantee exclusive resource access for a single request at any given time,mitigating potential data competition issues.
This mechanism ensures the system’s functions consistently provide services to each user, even in a highconcurrency environment,maintaining stability throughout.
3.3.Deployment and optimization of LLaMA2 model
As a deep learning model, the deployment of the LLaMA2 model presents a myriad of challenges, including high computing resource requirements, a complex model structure, a substantial number of parameters, and extensive demands on memory and processing power.To meet the need for real-time user responses, the model must exhibit swift inference capabilities.
We devised a mode employing half-precision floatingpoint numbers(float16)for loading the model.This approach significantly reduced both memory usage and computation time.Additionally, we leveraged PyTorch’s compile function to further optimize the model’s runtime efficiency.Furthermore, we implemented a streaming output feature for the model,allowing users to observe results in real time during the model’s execution,thereby enhancing the user experience.
Considering the intricacy and computational demands of the LLaMA2 model, we introduced a resource scheduling mechanism to ensure seamless responses for concurrent users.When a user requests model resources,the system assesses resource availability by competing for locks.If GPU resources are occupied and in the inference state, the user’s request is placed in a waiting queue, persisting until the resources become available.Through this mechanism,the system guarantees that only one request accesses the model at any given time,mitigating potential resource contention issues.Conversely,when a user obtains the lock resource and initiates inference,the streaming output doesn’t wait for the entire sequence to complete.Instead, it continues to generate and dispatch results in real time.
4.Experiment
4.1.Baseline
In the experimental stage, given the lack of large models specifically tailored for inorganic material synthesis knowledge question–answering, we opted for the widely-used general large models—ChatGPT,Ernie Bot, Spark Desk, Chat-GLM—for a comparative experiment on the performance of inorganic materials synthesis question–answering.Details can be found in Table 1 for information.Among them, the information on the Spark Desk model is not disclosed.
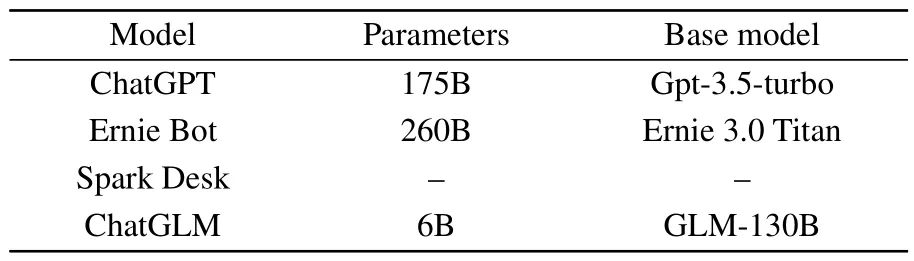
Model Parameters Base model ChatGPT 175B Gpt-3.5-turbo Ernie Bot 260B Ernie 3.0 Titan Spark Desk– –ChatGLM 6B GLM-130B
4.2.Metrics
When evaluating natural language processing models, a comprehensive assessment often involves a combination of BLEU and ROUGE metrics.BLEU primarily measures the accuracy and exact matching of translation,with an emphasis on precision, while ROUGE evaluates information completeness and coverage in summaries,emphasizing recall.
However, when dealing with extensive language models in the domain of inorganic material synthesis question answering, our primary focus is on observing the safety, accuracy,and usability of the generated answers — a metric we refer to as SAU.Safety involves ensuring that the resulting material synthesis process does not pose potential dangers or can highlight possible hazards.Accuracy requires that the generated answers are as precise as possible, factoring in crucial elements such as required raw materials, time, and temperature.Usability emphasizes that the model’s answers should be highly specific, encompassing operational details like the synthesis environment and utilized devices.
Furthermore, we demonstrated the generative inference capability of our model,showcasing its proficiency in providing synthesis processes for structures not present in the training set.
4.3.Results
We conducted a comprehensive performance evaluation,comparing our model against several baseline models.The questions posed were primarily skewed towards probing the knowledge of inorganic material synthesis processes, with an emphasis on extracting synthesis methods mentioned in the literature.[32,33]To enhance clarity,we extracted key synthetic raw material contents from model answers, as illustrated in Table 2.Identical questions were input to both our model and the baseline models during the experiment, and the corresponding output responses were observed.To maintain brevity, we condensed lengthy model answers by extracting essential synthetic raw material details.Furthermore, our input questions were rooted in relevant synthesis literature, utilizing chemical formulas such as K2CaMoB2P2O13[32]and Nd2Zn60B40Si19O161.[33]
We first delve into the analysis of the answer regarding K2CaMoB2P2O13.In terms of safety,all models perform similarly.Concerning accuracy, both ChatGPT and Spark Desk provide answers, but the raw materials mentioned in their responses are found to be incorrect based on relevant literature.Ernie Bot and ChatGLM models fail to furnish answers.Notably,our MatChat model not only provides an answer but also presents synthetic raw materials that are closely aligned with those detailed in the literature.Moreover,our model outshines others in terms of usability by offering the most informative responses.
Then, turning our attention to the answers concerning Nd2Zn60B40Si19O161, the models demonstrate comparable performance in terms of safety.However,in terms of accuracy,ChatGPT and ChatGLM models provide vague raw material information for various elements, lacking practical guidance.The Spark Desk model offers guidance in the form of oxides for each element,but the literature indicates that the source of the B element is H3BO3.Ernie Bot fails to provide a relevant answer.On the other hand, our MatChat model delivers raw material information closest to the literature, showcasing the highest guiding value.
In summary,MatChat proves to be highly valuable in predicting material synthesis processes, particularly for its accuracy and usability.
Furthermore, we showcase the dual capabilities of our model,encompassing both generative and inferential aspects.Our training set comprises a total of 13878 diverse chemical formula synthesis data.When we query the model using chemical formulas present in the dataset, the output exhibits a degree of inconsistency with the training set data, highlighting the model’s generalization capabilities.Moreover,when posing questions with chemical formulas absent from the dataset, the output format and content align in structure with the dataset, offering valuable insights for the synthesis process.
5.Conclusion
Based on the LLaMA2-7B pre-training model, we have developed MatChat, a ground breaking large language model explicitly designed for materials science.This model primarily focuses on synthesizing knowledge related to the inorganic materials synthesis process.It can engage in logical reasoning based on the queried materials formula and provides answers in the format of the training set, including formulas, temperature, time, environment conditions, and other relevant information.To facilitate the usage of MatChat, we have further developed a dialogue platform for users based on this model.This platform is currently accessible online at http://chat.aicnic.cn/onchat and is open to researchers in the materials field.This work is poised to inspire and bring new innovative ideas in materials science.
MatChat represents a pioneering effort in the applications of large models in materials science.It currently only supports English languages due to the lack of text data in other languages within the training set.The accuracy of its responses is an area we aim to further refine.The material large language model presented in this study focuses on inorganic chemical synthesis.We aspire for this work to be the‘the Wright brothers’ one-minute flight’ in the field of inorganic material synthesis pathway prediction.In the future,the research team intends to enhance the model’s usability and accuracy by incorporating literature data and information from existing material databases such as Atomly.net, OQMD, etc.Furthermore, we will also develop an expert knowledge database to handle the questions including dataset biases and uncertainties,and supply more precise corpus for models.Additionally, we plan to optimize the training methodology to enable the large aircraft of inorganic materials synthesis pathway prediction to fly higher and farther.
Program availability
The relevant code of this article has been published on GitHub at https://github.com/materialsCnicCas/CASMatChat and is also openly available in Science Data Bank at https://doi.org/10.57760/sciencedb.j00113.00174.The dataset used for fine-tuning the model is available upon request.
Acknowledgements
This work was supported by the Informatization Plan of the Chinese Academy of Sciences (Grant No.CASWX2023SF-0101),the Key Research Program of Frontier Sciences, CAS (Grant No.ZDBS-LY-7025), the Youth Innovation Promotion Association CAS (Grant No.2021167), and the Strategic Priority Research Program of Chinese Academy of Sciences(Grant No.XDB33020000).
杂志排行

Chinese Physics B的其它文章
- Optimal zero-crossing group selection method of the absolute gravimeter based on improved auto-regressive moving average model
- Deterministic remote preparation of multi-qubit equatorial states through dissipative channels
- Direct measurement of nonlocal quantum states without approximation
- Fast and perfect state transfer in superconducting circuit with tunable coupler
- A discrete Boltzmann model with symmetric velocity discretization for compressible flow
- Dynamic modelling and chaos control for a thin plate oscillator using Bubnov–Galerkin integral method