Self-supervised segmentation using synthetic datasets via L-system
2023-12-01JuntaoHuangXianhuiWuHongshengQi
Juntao Huang·Xianhui Wu·Hongsheng Qi
Abstract Vessel segmentation plays a crucial role in the diagnosis of many diseases,as well as assisting surgery.With the development of deep learning, many segmentation methods have been proposed, and the results have become more and more accurate.However,most of these methods are based on supervised learning,which require a large amount of labeled data as training data.To overcome this shortcoming,unsupervised and self-supervised methods have also received increasing attention.In this paper,we generate a synthetic training datasets through L-system,and utilize adversarial learning to narrow the distribution difference between the generated data and the real data to obtain the ultimate network.Our method achieves state-of-the-art(SOTA)results on X-ray angiography artery disease(XCAD)by a large margin of nearly 10.4%.
Keywords L-system·Adversarial learning·Vessel segmentation
1 Introduction
For recent years, medical image segmentation [1, 2] has become a very active research filed,which is now dominated by the technique of deep learning[3]but is still full of various challenges.Vessel segmentation is a mainstream direction of this filed and attracts much attention from researchers.The reasons why vessel segmentation is so welcomed by researchers are mainly from the following two aspects:one is that it has huge medical value,the other is that there exist so many challenging problems about vessel segmentation and researchers can be rewarded with fulfillment by solving these problems.Vessel segmentation can involve different types of vessels,for example,retinal vessels or vessel structures from coronary angiograms.The morphological characteristics of vessels can be affected by some diseases, thus vessel segmentation can help doctors diagnose some specific diseases correctly.For example, diabetic retinopathy can cause the proliferation of retinal vessels and the distribution of vessels from X-ray angiography [4] is a main factor to be utilized to diagnose coronary artery disease which causes millions of deaths every year.X-ray angiography helps doctors diagnose coronary artery disease by injecting a certain amount of radioactive contrast agent into the patient’s body to make the blood vessel system present a clear image.
As early as 1998,neural networks[5]were used to solve partial differential equations.Alwan and Hussain[6]found that if the deep learning controller is deep enough, it can outperform conventional controllers in terms of the settling time of the system output transient response to the unit step reference signal.After so many years of development, the relationship between deep learning and control system had become increasingly close[7].
Vessel segmentation is a special semantic segmentation and in fact it not only faces the difficulties of usual semantic segmentation but also must settle the specific difficulties of its own[8].Different from usual semantic segmentation,the structures of vessels are more intricate and contents of medical images are duller compared with natural images.By analogy, it seems to ask neural networks to do more work with fewer resources.Besides, in the process of vessel imaging, it is possible to produce background artifacts which is hardly distinguished from real vessels.Further,like usual semantic segmentation, supervised vessel segmentation need pixel-level annotations.However, annotations of medical images need more expertise than natural images,which is extremely time-consuming and laborious.All of these make vessel segmentation more challenging than usual semantic segmentation.In this paper, we try to settle these difficulties by a method of self-supervised learning which do not need vessel ground truth avoiding laborious annotations.The idea of our method is from CycleGAN[9].
Our contributions in the paper can be summarized into the following three points.
1.We are the first to introduce L-system into vessel segmentation.We used the L-system to generate ground truths images of blood vessels, and performed style transfer with CycleGAN to fuse the background of the target data with the generated blood vessels to obtain a relatively realistic training datasets.
2.As the number of iterations increases, the classification loss gradually decreases, and the loss produced by the discriminator is much larger than that produced by the classifier, which makes the training process more difficult.Therefore,in the middle of training,we modify the loss function of the discriminator to keep it at a suitable scale.
3.We achieve the results of SOTA with great advantage on the X-ray angiography artery disease(XCAD)datasets,our Dice coefficient and Jaccard coefficient are both improved by ten percentage points over [4].Similar improvements are also reflected in the X-ray coronary angiography(XCA)dataset,which proves the effectiveness of our method.
2 Related works
As mentioned above,medical image segmentations are now dominated by the technique of deep learning and vessel segmentations are not special case.Therefore, we mainly introduce the related works of vessel segmentation based on deep learning.We classify all researches into two categories,which are supervised methods and unsupervised methods.Their difference lies in whether vessel ground truths are used or not,at the same time we make no difference between selfsupervised methods and unsupervised methods and consider them as a category.
2.1 Supervised methods
UNet[3]may be the most welcomed neural network in the fieldofmedicalimagesegmentationeveninthewholefieldof image segmentation.It consists of two paths,one is the contracting path and the other is expansive.The expansive path is gradually upsampling process which has a large number of feature channels and allow the network to propagate context information to high resolution layers.UNet and its variants are also frequently applied to vessel segmentation.For example,DeepMind[10]utilized a 3D UNet to realize a segmentation of 15 kinds of pathological areas from retinal OCT images in 2018,achieving the international leading level.Fan et al.[11] applied octave convolution to UNet’s promotion for accurate retinal vessel segmentation.Another common segmentation model is SegNet[12],which has similar structures with UNet but saves more computational resources by a different upsampling method in decoder.A series of models based atrous convolution are also used to medical image segmentation like DeepLab series[13,14].Atrous convolution can relieve the resolution reduction in the process of training of neural networks and handle the problem of segmenting objects at multiple scales.
2.2 Unsupervised domain adaptation methods
Domain adaptation[15]is a commonly used method for processing unlabeled datasets,which requires a similarly labeled datasets.This method is widely used in classification[15]and segmentation[16].The core of this method is to reduce the difference between the source domain and the target domain.Approaches derived from this idea include maximum mean discrepancy [17], adversarial learning [18], etc.Roels et al.[19] incorporated regularized encoder features into the network structure,thereby extending the domain adaptation technique of classification-based classification to segmentation networks.Ma et al.[4] proposed a self-supervised framework in the field of vessel segmentation, where they fused CycleGAN and adversarial learning together to obtain an end-to-end segmentation network.But we split it into two steps:first use CycleGAN to generate synthetic datasets,and then use adversarial learning for training.
3 Proposed method
For vessel segmentation, self-supervised vessel segmentation(SSVS)[4]proposed that utilize the fractal algorithm to generate ground truths images which is a wise idea.However,its deficiencies are also obvious.First, the form of ground truth(GT)drawn based on fractal algorithm is limited,and it is difficult to obtain rich GT pictures,thus it limits the generalization ability of the model.Second,since the thickness of blood vessels is very abrupt when using fractal algorithm to generate GT pictures,the same problem also occurs when the real data is segmented.Finally,when the synthetic image is generated,it needs to use a background images which similar to the real datasets.Nevertheless,the acquisition of the back-ground is also a very difficult process.As shown in Fig.1,we can clearly see that the width of blood vessels in the segmented image suddenly becomes thinner.
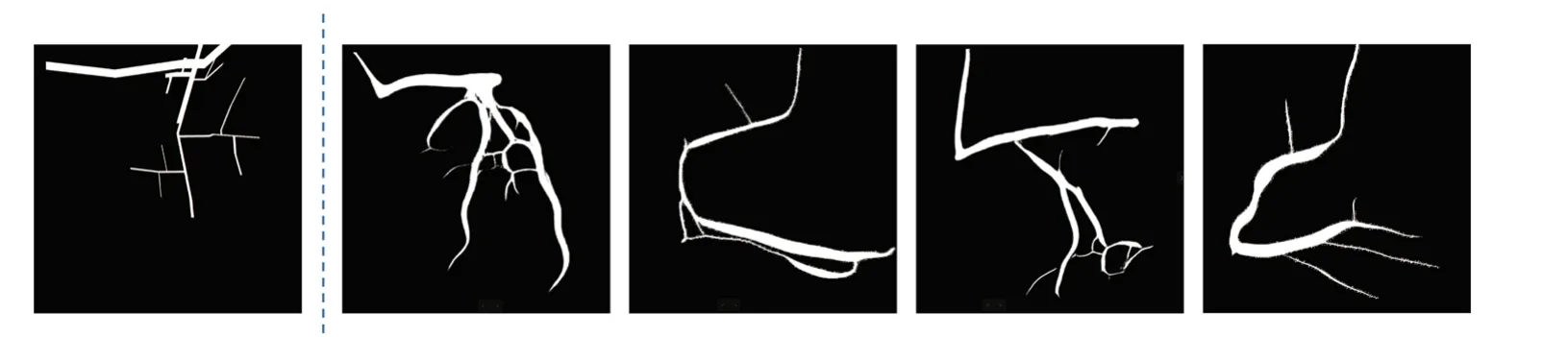
Fig.1 The picture is taken from[4].The left side of the dotted line is the GT image generated by the fractal algorithm,and the right side of the dotted line is the segmentation result obtained by the method in[4]
3.1 L-System
In order to solve the first two shortcomings, we introduce the L-system[20]in the generation of GT pictures,which is often used in the simulated growth of tree crowns or roots.We know that paired vessel images are difficult to acquire,but unpaired vessel images may be easily generated in some way.This is because vessel structure is a fractal structure which can be easily simulated by L-system.Specifically,the L-system is an ordered tripletG= 〈V,ω,P〉, whereVrepresents the character set of the system,ωis the initial string or axiom of the system, andPis a finite set of production rules.For example,suppose we define the following:V={a,b},ω=b,P={a→b,b→ab}.In other words,we let the character set be{a,b},the initial character string beband we have the two following generating expressions{p1:a→b,p2:b→ab}.Through constant iterations,the process of producing a series of character strings by the defined L-system is as follows:
The above process can be illustrated by Fig.2.
The general L-system combined with the turtle interpretation method can draw many fractal images.For example,Fig.2 is similar to a fractal tree.Its deficiency lies in that morphologies it can express are too monotonous to present the diversity of plants and represent finer part of structures of plants and blood vessels.To overcome this deficiency,people introduced stochastic L-system [20] and parameter L-system[21].Stochastic L-system mainly changes the way of using generating expressions.At every iteration, it no longer uses all generating expressions at the same time but instead randomly chooses one generating expression among all generating expressions according to some given probability distribution.Parameter L-system adds a parameter set and every character in the character set is accompanied by some parameters in the parameter set.At every rewriting iteration, some conditional judgments are used according to the magnitudes of some parameters of some character.In other words, conditional judgments are integrated into generating expressions.By combining parameter L-system with stochastic L-system, people can simulate all kinds of structures of plants successfully and it enlightens us how to simulate vessel structures by L-system.
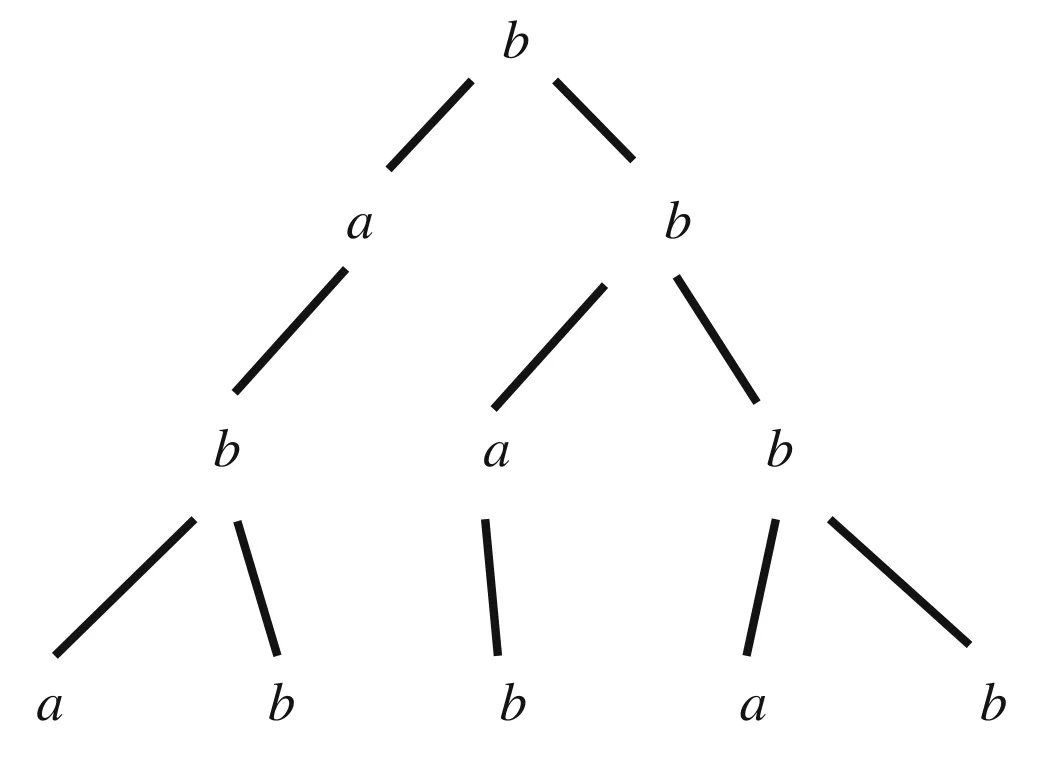
Fig.2 The iterative process of L-system based on initial character string and generating expressions
3.2 Generating synthetic datasets
After acquiring unpaired vessel images from L-system,CycleGAN can be directly applied to a preliminary segmentation of vessels.The last row of Fig.3 is the GT image we synthesized through the L-system.The main idea is as follows.We know that CycleGAN mainly learns two mappings,one isFwhich is a mapping from a source domain to a target domain, the other is an inverse mappingGfrom the target domain to the source domain.In our task, the source domain is medical vessel images such as color fundus photos or coronary angiograms,the target domain is the synthetic images of vessel structures by L-system.And we expect the mappingFlearned by CycleGAN can serve as a preliminary vessel segmentation network.Next,we can useFproducing paired images which can be further applied to supervised learning.By these two steps,we achieved a satisfactory result in the task of vessel segmentation without using any annotated image.By the way,CycleGAN has been applied to vessel segmentation in[22],but they did not workverywell.First,their fractal syntheticmodulecannot produce vessel structures as good as L-system which causes a more severe deviation of the synthetic target domain from the truly desired target domain than ours.Second,they do not utilize CycleGAN to further produce paired images for supervised learning and in experiment we have verified that this step improves the segmentation ability of the neural network a lot.
We can clearly see that the blood vessels of the images generated by the L-system are smoother and richer than the synthetic images generated by the fractal algorithm.At the same time,no background of real data is required.
3.3 Network structure
In the paper, we use DeepLabV3 [23] as the training network,in which the backbone part adopts ResNet50[24],and its overall framework is shown in Fig.4, which shows the structure of a typical domain adaptive network[18]based on adversarial learning.
We assume that the unannotated datasets which can be calledtargetdomaintobesegmentedisDt={x1,x2,...,xm}.The synthetic annotated datasets called source domain isDs= {x1,x2,...,xn}and corresponding annotationsY={y1,y2,...,yn}.Our goal is to train a segmentation network with datasetsDtandDsto segment datasetsDt.G fis responsible for extracting the feature information of the input images,which include the source domain imagexsand the target domain imagext.The features obtained byG fcan be expressed as
wherexs∈Dsandxt∈Dt.Gsconsists of Atrous Spatial Pyramid Pooling (ASPP) [14] layers, convolutional layers and an upsampling layer.The ASPP layer can perform convolution calculations on images with different scales,and can focus on fine blood vessels in the input image.Similar toG f,throughGswe can get
Since the source domain data has corresponding annotations,we calculate its binary cross-entropy(BCE)loss:
whereys∈Y.After we train the entire neural network, ˆytis the segmentation result we need.
Gdis composed of a gradient reversal layer (GRL) [18]and a convolutional layer,and determines whether its input is real image or artificially synthesized image.The function of GRL is to change the sign of gradient when it is back propagated.We can mark the data of the source domain as 0 and the data of the target domain as 1,so that the network branch consisting ofG fandGdcan train a binary classifier.In this branch, we also use BCE loss function for training,and mark the loss asLd:
wheresi,t jrepresent thei-th andj-th samples in the source and target domains, respectively.Therefore, the total loss function can be expressed as

Fig.4 The overall structure of the network.Sub-network G f is responsible for extracting feature vectors from the original image,Gd is used to determine whether the data belongs to artificial synthesis,and Gs restores the obtained features to segmentation results
whereλis a trade-off coefficient, and its value is 1 in this paper.
As the training time increases,the discriminatorGdgradually becomes unable to correctly distinguish real samples from synthetic samples.At this time,the loss of the discriminatorGdis much greater than the loss of the classifierGs,which leads to a decrease in the accuracy of the classifier.Therefore,after training for a certain period of time,we modify the loss function as follows to prevent this phenomenon:
4 Experiments and results
4.1 Dataset and implementation details
XCAD[4]is datasets of coronary angiography images generated by the General Electric Innova IGS 520 system.XCAD contains a total of 1621 training pictures,which can be used to generate artificially synthesized datasets.It also contains 126 test data annotated by experienced radiologists.The resolution of each picture is 512×512 pixels with one channel.
XCA [25] and XCAD represent the same part of the human body, but obtained by different machines, and its background is obviously different from that of XCAD.It contains a total of 134 images with a resolution of 300×300,all of which we use as test data.
The resolution of images used in the paper is 256×256.It is worth noting that when we train and test on XCAD or XCA,we do not use data from another datasets,and we do not need any background images as well.On both datasets,we use the Jaccard index,Dice coefficient,accuracy(Acc.),sensitivity(Sn.),and specificity(Sp.)as the evaluation metrics.
We implement all deep methods based on the PyTorch framework.The backbone network is ResNet50, and the scale of the extracted features is 1/8,and then restored to the size of the original image through the ASPP layer and the upsampling layer.We employ the Adam[26]withβ1=0.9,β2= 0.999, and the learning rate strategy implemented as following: first, a small learning rate is used for warm-up.We set the epoch of warm-ups to 5, and then the learning rate increases linearly to the initial value of 2×10-4, and finally decreases according to the cosine function.When the learning rate is large,the network will swing back and forth when it converges to the local optimum, so we need to let the learning rate decrease continuously with the number of training rounds:
whereNis the total number of epochs trained and its value is 200.eis the value of current epoch.As for the parameter of GRL, we gradually change from 0 to 1 according to the method of [27], which can prevent the introduction of noise in the initial training stage.We gradually change it by
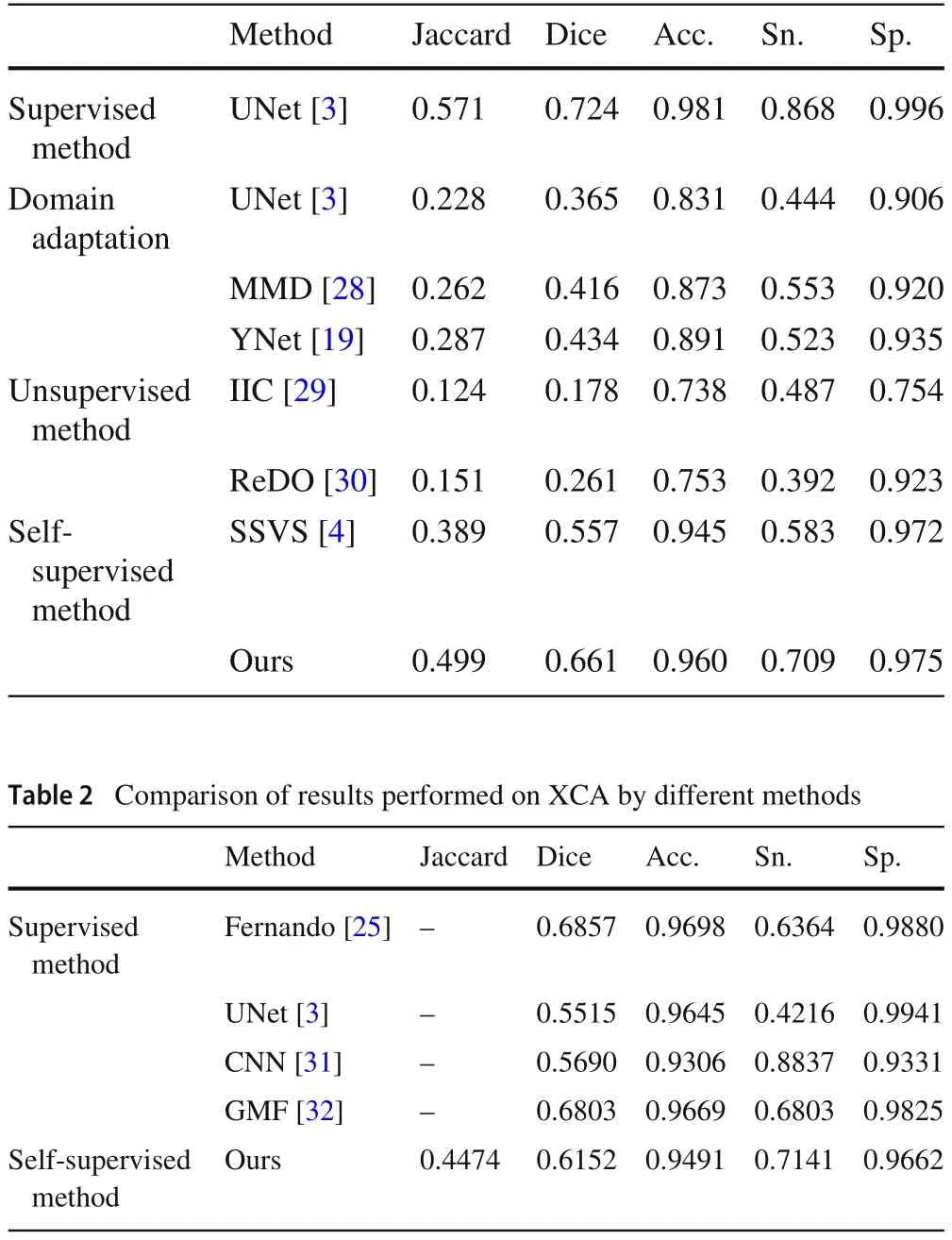
Table 1 Comparison of results performed on XCAD by different methods
4.2 Results
In Table 1, except for our proposed method, other results are directly used data in [4].We can see that except for a slight drop in Sp.,the other four metrics outperform all the remaining methods.Jaccard, Dice and Sn.all have significant improvements, 11.0, 10.4 and 12.6 percentage points,respectively,all of which are currently the SOTA results on XCAD.The above results illustrate the extremely important application of L-System in self-supervised blood vessel segmentation.
Some results of [25] which releases XCA datasets are extracted and put in Table 2 for comparison.We can see that ourproposedself-supervisedmethod,althoughnotasgoodas the best supervised methods,has surpassed the performance of some supervised methods.The results on this datasets can demonstrate some generalization of our method.
We put the partial segmentation results of the dataset in Fig.5,from which we can see that there is no sudden thinning of vascular branches in Fig.1 in our results.
Ablation study Table 3 shows the results of ablation experiments on two different datasets.‘Base’consists of two partsG fandGsshown in Fig.4.‘Ad’stands for the adversarial learning part, which is theGdin Fig.4.We can see that the results of adding ‘Ad’ networks to all datasets and evaluation metrics have improved.
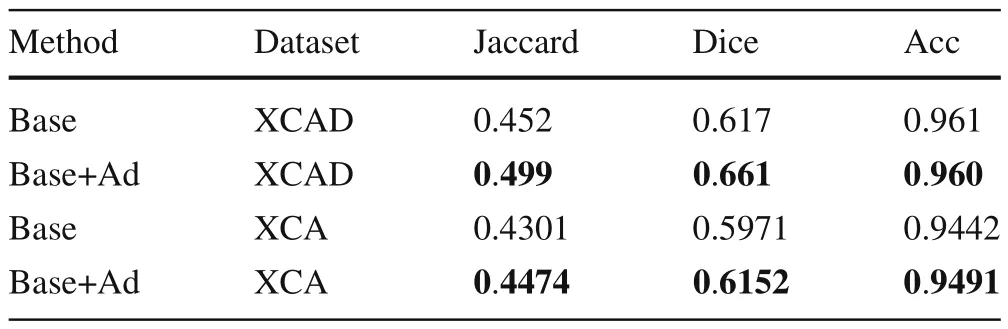
Table 3 Ablation study

Fig.6 The impact of different loss functions on the results
We also analyzed the impact of different loss functions on the evaluation indicators,and the results are shown in Fig.6.The blue dotted line only uses Eq.(6) as the loss function,and the orange solid line uses Eq.(7)as the loss function after training to a certain extent.We can see that no matter which dataset is used, the results obtained by using the modified loss function are better than the results of the original loss function.
5 Conclusion
In this paper,we introduce the L-system into vessel segmentation.We generate GT of synthetic data through L-system,and then use CycleGAN to generate images similar to the target data.This constitutes a labeled artificial datasets,and then uses adversarial learning to do unsupervised domain adaptation training data.We achieve SOTA results for selfsupervised segmentation on the XCAD datasets, and even outperform some supervised methods on the XCA datasets.These illustrate the effectiveness of our method.
Data Availability The data that support the finding of this study are openly available in Ref.[4]and Ref.[25].
杂志排行

Control Theory and Technology的其它文章
- Consensus control of second-order stochastic discrete-time multi-agent systems without velocity transmission
- Robust non-aggressive three-axis attitude control of spacecraft:dynamic sliding mode approach
- Algebraic form and analysis of SIR epidemic dynamics over probabilistic dynamic networks
- Erratum to:Modular supervisory control for multi-floor manufacturing processes
- Active resilient defense control against false data injection attacks in smart grids
- Adaptive feedback control for nonlinear triangular systems subject to uncertain asymmetric dead-zone input