关联规则挖掘驱动的盾构机刀盘健康评估方法
2023-12-01刘尧陈改革刘振国孔宪光常建涛
刘尧 陈改革 刘振国 孔宪光 常建涛
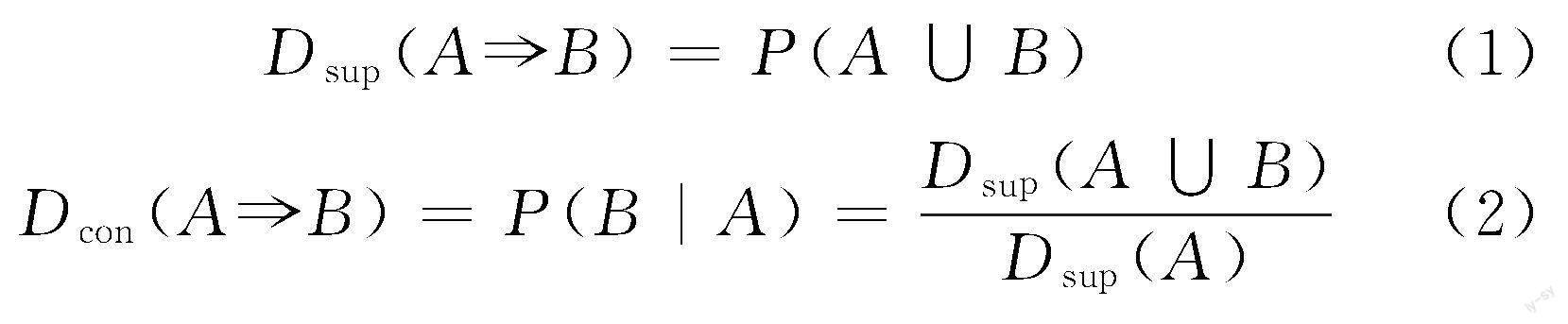


摘要:傳统机理建模研究与实际施工环境误差较大,而数据驱动建模多采用黑箱模型,不利于知识发现与理解,为此提出一种基于知识挖掘的盾构机刀盘健康评估方法。针对盾构掘进数据维数众多、海量异构、强噪声干扰等特点,结合盾构掘进领域知识与机器学习算法提出针对性的数据预处理、特征筛选以及连续特征离散化方法,以此建立知识挖掘数据集。在此基础上,利用关联规则挖掘算法提取关键特征与不同刀盘健康状态之间的映射关系,采用融合可靠度、完整度与简洁度的综合评价指标适应度准则对原始规则进行评价排序,最终实现盾构机刀盘健康评估。基于厦门地铁3号线某掘进区间的实际工程数据对所提方法进行了应用验证。研究结果表明,所挖掘的知识规则与实际数据分布具有良好的吻合度(平均值93%以上),验证了该方法的有效性。
关键词:盾构机刀盘;健康评估;关联规则;数据挖掘;知识挖掘
中图分类号:TH17; U455
DOI:10.3969/j.issn.1004132X.2023.11.008
Health Assessment Method of Shield Machine Cutterheads Driven by
Association Rule Mining
LIU Yao1,2 CHEN Gaige1,2 LIU Zhenguo3 KONG Xianguang4 CHANG Jiantao4
1.School of Communications and Information Engineering,Xian University of Posts and
Telecommunications,Xian,710121
2.Research Institute of Industrial Internet,Xian University of Posts and Telecommunications,
Xian,710121
3.Key Laboratory of Industrial Equipment Quality Big Data,MIIT,Guangzhou,510000
4.School of Mechano-Electronic Engineering,Xidian University,Xian,710071
Abstract: Traditional mechanism modeling method had large errors with the actual construction environment, whereas data-driven modeling mostly used black-box models, which was not conducive to knowledge discovery and understanding, therefore a knowledge mining-based shield machine cutterhead health assessment method was proposed. For the characteristics of shield excavation data with many dimensions, massive heterogeneity and strong noise interference, specific data pre-processing, feature screening and continuous feature discretization methods were proposed to establish a knowledge mining dataset combining the domain knowledge of shield excavation and machine learning algorithms. Then, the association rule mining algorithm was used to extract the mapping relationship among key features and different cutterhead health levels. The original rules were evaluated and ranked by using a comprehensive evaluation index that integrated reliability, completeness and simplicity to finally realize the shield machine cutterhead health assessment. The proposed method was validated based on the actual engineering data of one tunneling section of Xiamen Metro Line 3. The results show that the mined knowledge rules have a good agreement with the actual data distribution (average 93% or more), which verifies the effectiveness of the method.
Key words: shield machine cutterhead; health assessment; association rule; data mining; knowledge mining
0 引言
刀盘系统是盾构机实现破岩掘进的核心部件。由于施工环境复杂恶劣,以及长时间在低速、重载和动态变工况条件下工作,刀具过度磨损与异常破坏成为盾构机故障停机的最主要原因,也是盾构安全高效掘进最主要难题之一[1]。在盾构施工过程中,对刀盘系统退化状态进行有效监测评估,对提高盾构机刀盘维护和盾构掘进效率、降低维修风险和成本都具有非常重大的意义和价值。
对于盾构机刀具刀盘退化状态分析,当前国内外的研究方法可分为直接检测、磨损机理分析建模及数据驱动建模三种。直接检测法一般使用电气、液压、气体等检测装置监测刀具磨损状态,按照测量结果可分为极限式和连续式两种[2-3]。文献[4]设计了一种基于电阻排式磨损传感器的刮刀和撕裂刀实时监测系统,采用电阻变化原理通过电流值与磨损量的线性关系计算刀具磨损量。文献[5]提出了一套基于电涡流传感器的在线滚刀磨损测量系统,在实验室和实际工业现场的滚刀上进行了应用验证。使用传感器直接测量刀具磨损量是一种非常直观的方式。然而,实际盾构施工环境非常恶劣复杂,外加传感器要承受振动、高温、岩石渣土、水压等综合载荷作用,同时受到传感器安装防护、安装数量、数据传输方式的限制,现有直接检测方法在实时检测的准确性和可靠性方面还有待进一步提高。
磨损机理分析建模方法通过理论分析建立解析模型,预测刀具磨损量大小[6]。文献[7]基于滚刀在掘进过程中的应力状态分析和摩擦能量理论,综合考虑盾构机运行参数、刀具载荷、当下岩石特性等,建立了滚刀磨损量预测模型,并分别在均匀地层和复合地层中进行了应用验证。文献[8]通过对滚刀与岩石接触作用的力学分析和滚刀磨损形态的理论分析,确定了影响滚刀磨损演化的关键因素,之后基于摩擦学和接触疲劳裂纹传播理论,建立了滚刀磨损演化预测模型。然而,当前磨损机理模型只能预测正面滚刀的均匀磨损,无法预测非均匀磨损(如断裂、偏磨等),也无法预测因岩渣堆积造成的二次磨损。此外,由于实际地质往往不均匀且持续动态变化,理论模型与实际施工中的刀具岩石接触状态、地质特性均具有较大差异,导致在实际应用中预测误差较大。
此外,地质勘探与盾构机数据采集与监控(supervisory control and data acquisition, SCADA) 系统中存储着大量掘进线路地质特性数据与盾构机运行数据,为基于数据驱动的盾构机性能预测研究提供了丰富的资源,近年来引起了学者的广泛关注[9-12]。在盾构机刀具刀盘退化评估和预测方面,亦有学者开展了相关研究[13-14]。文献[15]基于多个岩石隧道掘进工程数据研究了岩石单轴抗压强度等岩体特性参数与滚刀破岩体积磨损速率之间的关系,通过数据回归分析提出了滚刀磨损评价方法。文献[16]通过提取反映刀盘性能的状态参数构成原始高維特征矢量样本,采用t-SNE流形学习方法进行降维,得到了数据样本在低维空间的分布,最后使用马氏距离计算得到刀盘健康指数。文献[17]以刀盘推力、扭矩、滚刀安装半径、岩石单轴抗压强度、Cerchar磨蚀性指数为输入,使用浅层神经网络建立刀具磨损量预测模型,并获得了较高的精度。
基于数据驱动的刀具刀盘磨损评估预测方法无需外加专用传感器,而是借助地质勘探数据与盾构机本体实时测量数据进行刀盘系统退化监测评估建模,系统抗干扰性和实时性更强,具有广阔的应用前景。然而当前研究大多基于专家经验,只选择少数经验上与刀盘磨损退化相关的特征进行分析,未充分挖掘利用盾构机SCADA系统所采集的海量运行数据的价值。此外,当前研究多基于隐式黑箱模型,结果可解释性差,不利于通过大数据分析提取显性知识,以对传统经验知识进行验证和扩充来实现领域知识的凝练与传播。关联规则是一种常用的数据挖掘方法,用于从大量数据中挖掘关联性或相关性,从而描述一个事物中某些属性同时出现的规律和模式[18]。关联规则挖掘结果方便理解,便于形成知识规则,因而在装备状态监测与故障诊断领域也获得了广泛的应用[19-22]。
本文通过深层次挖掘刀盘性能退化与盾构机运行状态特征之间的非线性映射关系,提出一种关联规则挖掘驱动的盾构机刀盘健康评估方法。根据盾构机运行原理,提出针对性的原始盾构掘进数据预处理方法;利用轻量级梯度提升机(light gradient boosting machine, LightGBM)算法对高维运行参数进行重要度评分,筛选得到对刀盘性能具有较高区分能力的特征子集;通过决策树算法和分箱配合实现高维连续数值特征离散化,获得可用于关联规则挖掘的数据集;利用频繁模式增长(frequent pattern growth, FP-Growth)算法挖掘出关键特征与刀盘健康状态之间的映射关系,并构建综合评价准则对规则集合进行评分排序;最后基于评分最优的规则实现盾构机刀盘的健康评估。
1 关联规则挖掘
关联规则是一种挖掘和描述数据项或数据项集之间统计关系的算法,用于发现潜在的关联关系[23]。假设I={i1,i2,…,in}表示所有项目的集合,T表示某个频繁项集,由集合I中的k项组成,记作T={t1,t2,…,tk}。设A、B分别为频繁项集T中的一个项集,则关联规则可表示为
(T中包含A)(T中包含B)
其意义在于,数据关系中若存在A项目,则会存在B项目。
频繁项集T中的规则AB由支持度Dsup(support)和置信度Dcon(confidence)约束,计算公式如下:
支持度表示规则出现的频率,置信度表示规则的可信程度。综合设置最小支持度和最小置信度可以评价和筛选规则的可靠性和可用性。关联规则挖掘的最终目标是在数据集中找到强关联规则,即拥有较高支持度和置信度的规则。
常用的关联规则算法有Apriori算法和FP-Growth算法[24]。FP-Growth算法于2000年被提出,该算法基于Apriori算法原理,通过将数据集存储在频繁模式(frequent pattern,FP)树上,再从中挖掘频繁项集。相比于Apriori算法,FP-Growth算法只需要对数据库进行两次扫描,而Apriori算法对每个潜在的频繁项集都会扫描数据集,判定给定模式是否频繁,因此FP-Growth算法减少了对数据集的访问和读取,执行效率更高,并且FP-Growth算法用FP树存储数据可以减小存储空间,得到非常高的压缩比。
2 基于关联规则挖掘的刀盘健康评估
一个典型的知识挖掘过程通常包含三个步骤,即数据预处理、应用数据挖掘算法、结果后处理[23],因此,基于关联规则挖掘的刀盘健康评估方法也主要包含数据预处理、关联规则生成、规则评价三个步骤,如图1所示。
在数据预处理阶段,主要任务包括:对不同状态下的原始数据进行筛选以构建分析建模数据包,按照刀具磨损测量维护记录划分不同的刀盘健康等级,筛选特征,并对连续数值特征进行离散化。在关联规则生成阶段,将对筛选的特征和刀盘健康状态记录应用关联规则挖掘算法,以生成可用于识别刀盘健康状态的规则。然后,基于适应度准则对所生成的规则进行评价排序。最后,经过优化后的关联规则即可用于盾构机刀盘的健康评估。
2.1 数据预处理
2.1.1 数据包构建
数据包的构建包含如下三个方面:剔除非掘进状态数据、地质类型分割、司机主控参数约束。盾构机在掘进过程中数据记录是不间断的,所采集的数据中同时包含掘进状态和非掘进状态(如拼装、停机等),而非掘进状态下是没有磨损发生的,故需要首先将非掘进状态下的数据剔除。筛选过后的数据全部处于掘进状态,虽然在时间上不连续,但在刀盘的性能退化上是连续的。基于盾构机的工作机理,可将刀盘转速和总推进力同时大于零作为条件从而筛选出盾构机处于掘进状态下的数据。
其次,盾构机在掘进过程中会经历不同的地质条件,不同地质的岩土特性不同,刀盘的受力情况会发生变化,表现在数据特征上也会有较大差异。地质的不同不仅会影响刀具的磨损速率,也会影响同样磨损量的刀具在数据上的表现。为了消除不同地质条件造成的数据差异对后续分析建模的影响,需要根据地质情况对数据进行分割,构建不同的数据包,然后将同样的分析方法分别应用于不同地质条件下的数据。
此外,盾构机运行数据也受到司机掘进控制参数设定的显著影响,为了确保分析结果的准确性,要保证司机的控制参数保持在一定波动区间内。通过盾构施工参数匹配分析,总推进力可以综合反映司机控制参数的影响,因而选取总推进力处于特定区间内的数据用于后续分析。
综合以上三方面的数据筛选,得到全部处于掘进状态下的数据,同时尽可能消除地质和司机控制参数设定的影响,所构建的数据包将能更好地支持后续分析建模。
2.1.2 刀盘健康等级划分
关联规则分析旨在挖掘出与刀盘健康状态强相关的盾构机运行特征,所以数据集标签的构造非常重要。连续的盾构机刀具磨损标签的获得非常困难,只能依靠每次开仓换刀检查的结果来评估刀盘健康状态。在盾构機掘进过程中,刀具磨损不断加剧,刀盘性能不断退化,因而可以将刀盘健康状态分为健康、轻度磨损、中度磨损、严重磨损四个等级。具体方法为依据领域专家经验及刀盘机械结构信息,根据每次开仓检查后最终更换的刀具数量来判定,不同换刀数量区间对应不同的刀盘健康状态。
2.1.3 特征筛选
在关联规则挖掘中,一方面,无用的特征会对挖掘算法造成混淆,导致结果中出现不准确或无用的知识;另一方面,过多的特征也会对计算效率造成负面影响,因此需要对原始特征进行筛选以获得真正有效的规则。
本研究中特征筛选分为两步:首先,原始特征中包含大量人工设定参数和累计特征(如刀盘转速设定、推进压力设定、掘进距离、工作时间、电量总累计量等),这些特征与刀盘性能退化间没有直接关系,需要手动剔除;接下来利用嵌入式的特征筛选方法,从分类的角度出发,使用机器学习算法进行特征重要度排序,本研究使用了LightGBM算法[25]训练分类模型,对四种刀盘健康状态进行分类。LightGBM算法会统计所有迭代中每个特征的分裂对损失函数贡献的总量,并以此为依据对特征打分,因而可以选取排序结果中排名靠前的若干特征(即对刀盘健康状态最具区分度的特征)形成特征子集作为最终筛选结果。
2.1.4 连续特征离散化
关联规则挖掘算法不能直接应用于连续数据,所以需要将连续特征进行离散化,即在信息损失最小的前提下将连续数值划分为一系列数值区间,从而将连续值特征转换为一系列类别特征。这是关联规则挖掘中非常重要的一步,错误选择的划分节点将导致知识挖掘过程变得没有价值。
常用的连续特征离散化方法有分箱方法及其变种、基于卡方的离散方法和基于熵的离散方法等[26]。对于有监督问题,一般采用基于熵的方法对数据进行离散化,但大量离散节点信息熵的计算非常繁琐耗时。为解决这一问题,本研究采用决策树与等距分箱结合的方法来实现特征离散化。决策树在进行特征划分时,可自动在候选特征集合中选择使得划分后数据集纯度更高的特征作为最优划分节点。而等距分箱几乎不需要耗费时间,但它具有一定随机性,很容易遗漏一些关键分割节点。决策树的决策原则本身基于熵或基尼指数,因而利用决策树与等距分箱共同进行离散化可以平衡计算效率与准确率。
特征离散化的具体步骤分为两步,首先利用需要离散化的特征建立决策树模型。在这个步骤中需限制决策树的最大深度来避免过拟合。在有限的深度下训练完成的决策树只包含部分特征,因此第二步是将已经被决策树划分过的特征从特征集合中删除,用剩下的特征集合重复第一步的做法。当某一步中生成的决策树结构非常复杂时就停止迭代。决策树结构的复杂度在一定程度上代表了训练特征对标签的分类能力,复杂的树结构表示训练特征无法轻松地将数据分类,使用这样的结果容易造成过拟合。
离散化完成后将得到一系列类别特征,同时与刀盘的健康状态标签一并作为关联规则挖掘的输入。当关联规则挖掘结束时,所生成的规则可被转换回原始的格式并展示给用户。
2.2 关联规则生成
由于盾构机运行数据维数众多,样本数据量大,即使经过前期数据预处理和特征筛选后,所得到的训练数据集依然庞大,在此基础上开展关联规则挖掘会对算法的计算性能提出较高的要求,为此,本文使用拥有更高计算效率的FP-Growth算法进行关联规则的生成。
2.3 关联规则评价
对于一条关联规则,其评价标准主要取决于预测精度和可理解性。目前,衡量关联规则预测精度的指标是其置信度。然而实际应用中仅使用置信度则无法保证所生成的规则对其他测试数据集的预测精度。基于上述分析,本研究使用适应度值Vfit(fitness value)[27]来对生成的规则进行评价。
适应度值由三个独立参数计算得到,分别是:可靠度Dre(reliability)、完整度Dcom(completeness)和简洁度Dsim(simplicity)。可靠度和完整度这两个参数是根据混淆矩阵计算得到的,可用于描述规则的预测精度,如表1所示,其中NTP表示预测为正、同时真实结果也为正的样本的个数(true positive, TP),NFP表示预测为正、真实结果为负的样本的个数(false positive, FP),NFN表示预测为负、真实结果为正的样本个数(false negative, FN),NTN表示预测为负、真实结果同样为负的样本个数(true negative,TN)。
显然,适应度值应与NTP成正比,与NFP和NFN成反比。根据表1所示的混淆矩阵,可靠度与完整度的计算公式如下:
简洁度表示规则的简洁程度,用于描述规则的可理解性,可用关联规则前键中的特征个数来表示,其计算公式如下:
式中,N为关联规则前键中的特征个数。
综合可靠度、完整度和简洁度,可得到适应度值的计算公式如下:
Vfit=ω1(DreDcom)+ω2Dsim(6)
其中,ω1、ω2为权重,用于控制规则的可靠度、完整度和简洁度。本研究中,ω1、ω2分别取0.7和0.3。
2.4 刀盘健康评估
对于一条测试记录,刀盘健康评估的步骤如下:①挑选出所有满足测试记录前键的规则,构成备选集;②依据所有备选规则的适应度值按照分值从高到低进行排序,拥有最高适应度值的规则被认定为最优规则,据此得到刀盘的健康状态评估结果。基于该优选策略可避免一条测试记录对应多个状态标签的不一致问题,从而提高评估结果的准确度与实用性。
3 应用验证
本节以厦门地铁3号线某施工区间的盾构掘进数据对本文所提出的盾构机刀盘健康评估方法进行验证。在该区间盾构机掘进长度约500环,每环长度为2 m。根据刀盘维修记录,该区间共发生38次开仓换刀。本区间使用了土压平衡式盾构机,图2所示为盾构机刀盘布局,该布局为辐条+面板复合式结构,开口率为35%。刀盘直径6.4 m,共安装中心双联滚刀6把,单刃滚刀35把,边刮刀12把,刮刀43把,超挖刀1把,其中滚刀用于挤压破碎岩石,安装位置更突出刀盘面板,是刀具磨损和破坏失效的主体。
图3展示了掘进线路的地质分布,图中百分比表示不同环号所对应地层中不同岩石成分的百分占比,实曲线表示根据岩石成分百分比和不同岩石力学参数计算得到的等效岩土承载能力值(代表岩土能够承受的最大应力,其数值越大表明岩层的磨蚀性越强,刀具越容易磨损),虚竖线表示刀盘维修记录显示的开仓换刀位置。由图3可以看到,该施工区间的地质以微风化花岗闪长岩为主,该地层具有最强的磨蚀性,实际在该地层下也发生了多次换刀。从图3中也可以看到在中等风化花岗闪长岩地层下出现了密集的换刀,经与施工人员沟通,此段为风险较高的掘进区间,因而人为增加了开仓检查的次数。
盾构机SCADA系统采集的数据共155维,主要包括推进系统参数、刀盘系统参数、电力系统参数、导向系统参数、螺旋输送系统参数、土仓压力等,所有数据每秒钟采集一次。
3.1 数据预处理
如图3所示,施工区间包含多种地质类型,其中微风化花岗闪长岩地质占比最大,也是刀具磨损最为剧烈的地质,因此,本文选取微风化花岗闪长岩这一地质类型下的数据进行分析示例,其他地质类型下的数据分析可采取相似步骤。
基于盾构机的工作机理,以刀盘转速和总推进力同时大于零为条件筛选出盾构机处于掘进状态下的数据,保证数据在刀盘磨损上的连续性。同时进一步选取总推进力处于10~20 kN之间的数据,以削弱司机掘进控制参数设定的影响。
根据刀盘维修记录,每次开仓检查滚刀的更换数量由几把到几十把不等,取不同换刀点前后的一部分数据,根据换刀数量将其分为四个健康等级,换刀数量越多表明磨损越严重。选取部分微风化花岗闪长岩地层下的掘进数据作为训练集,具体的健康等级划分如表2所示。
根据机理知识,人工剔除一些与刀具磨损无关的特征,如累计量、时间、人工设定控制的参数等。接下来利用LightGBM算法对剩余特征进行重要度排序,取排序前20的特征记为特征子集S,特征名称及其重要度分值如表3所示。
提取僅含特征子集S的数据记作数据集DS,利用DS建立决策树模型并可视化。第一次迭代的决策树结构如图4所示,图中显示决策树模型根据基尼指数对一部分特征先后进行了划分,并展示出了四个健康等级的分类样本数。其中X[1]对应特征为左上铰接位移,X[13]对应特征为右中土仓压力,具体划分节点如图4所示,基于对应分割点即可对相应特征进行离散化。
从特征子集S中删除第一次迭代选取的特征,利用剩下的特征进行第二次迭代建立新的决策树并可视化,如图5所示。
重复上述过程,得到第三次迭代建立的决策树并可视化,如图6所示,可以看出,第三次迭代训练生成的决策树结构已经略显复杂,这是由于用于训练决策树的特征对标签的区分性减弱,也是过拟合的表现,因此仅取本次迭代生成的决策树的前两层作为有效结果。
从三次迭代中可以看出,决策树会优先划分对健康等级区分能力强的特征。在第一次迭代中,只划分了一部分优秀的特征分类精度就达到了要求,这种情况下就无法得到其他特征的分割节点。从特征子集中删除已经被划分的特征就是强制决策树去找到那些重要性相对较低的特征的分割点,但是,如果强制迭代多次就容易造成过拟合,因此本文只选取3次迭代。
本研究將每个特征离散化为四个区间,决策树生成的划分节点不能覆盖所有的特征,因此采用等距分箱将余下的特征进行离散化,所有20个特征的区间划分如表4所示。
3.2 关联规则生成与评价
利用FP-Growth算法对特征离散化后的数据记录进行关联规则挖掘,生成一系列规则。根据式(6)计算出所有规则的适应度值,并按照从高到底的顺序对所有规则进行排列,表5展示了排名靠前的部分规则。
3.3 刀盘健康评估验证
由于整个分析过程在微风化地质下进行,因此选取微风化地质下未参与训练的数据作为测试数据对结果进行验证。结合地质分布图,分别选取247~248环、268~269环的数据进行测试。根据刀具磨损测量与维护记录,在第249环时共更换7把刀具,根据专家经验可判定在刀具更换前的247~248环刀盘处于轻度磨损状态;在第270环时共更换5把刀具,同样根据专家经验可判定在刀具更换前的268~269环,刀盘也处于轻度磨损状态。
表6展示了247~248环、268~269环两段数据部分特征的取值区间占比。经过分析对比,相关特征的取值区间与表5中规则1({右中土仓压力1, 刀盘控制油压检测2, 刀盘磨损压力2, 膨润土压力1, 推进压力1→轻度磨损})吻合,平均重合度均在93%以上,且该条规则具有最高的适应度值(0.750),据此可判定刀盘处于轻度磨损状态,与专家经验判定结论一致,从而验证了所建立规则的可信度。
基于本文所挖掘的所有知识规则可通过编制软件方便施工现场应用,当刀盘到达中度磨损或严重磨损时应及时开仓进行换刀维修。
4 结语
本文提出一种基于关联规则挖掘的盾构机刀盘健康评估方法,系统性地提出了针对性的盾构掘进数据预处理、特征筛选、特征离散化、关联规则生成与评价方法,基于所抽取的规则可实现刀盘健康评估,克服传统机理建模研究存在的与实际施工环境误差较大和数据驱动建模多采用黑箱模型而难以解释的不足,便于工业应用和行业知识积累。实际盾构施工数据应用结果表明所提出的方法具有较高的准确性,可满足工业现场应用需求。
受实际工程限制,本文所抽取的规则是在微风化花岗闪长岩这一特定地质环境下得到的,并不一定完全适用于其他地质环境。未来可搜集其他地质条件下的掘进数据,采用本文所提出的技术路线进行分析,扩充刀盘健康评估的知识规则。
参考文献:
[1] 周建军, 宋佳鹏, 谭忠盛. 砂卵石地层地铁盾构盘形滚刀磨蚀性研究[J]. 土木工程学报, 2017,50(增刊1):31-35.
ZHOU Jianjun, SONG Jiapeng, TAN Zhongsheng. Study on Abrasive Properties of Shielded Hob in Subway Shield of Sandy Gravel Formation[J]. China Civil Engineering Journal, 2017,50(S1):31-35.
[2] 张晓波, 刘泉声, 张建明. TBM掘进刀具磨损实时监测技术及刀盘振动监测分析[J]. 隧道建设, 2017,37(3):380-385.
ZHANG Xiaobo, LIU Quansheng, ZHANG Jianming. Real-time Monitoring Technology for Wear of Cutters and Monitoring and Analysis of Cutterhead Vibration of TBM[J]. Tunnel Construction, 2017,37(3):380-385.
[3] 刘招伟, 王百泉, 尚伟. 基于超声波的盾构切刀磨损无线检测系统研究[J]. 隧道建设, 2017,37(11):1469-1474.
LIU Zhaowei, WANG Baiquan, SHANG Wei. Study of Wireless Detection System of Shield Cutter Wear Based on Ultrasonic[J]. Tunnel Construction, 2017, 37(11):1469-1474.
[4] ZHUO Xingjian, LU Yati. Real-time Wear Monitoring System for Scrape Cutters and Tearing Cutters[J]. Tunnel Construction, 2018,38(6):1060-1065.
[5] LAN Hao, XIA Yimin, JI Zhiyong, et al. Online Monitoring Device of Disc Cutter Wear—Design and Field Test[J]. Tunnelling and Underground Space Technology, 2019,89:284-294.
[6] SUN Zhenchuan, ZHAO Hailei, HONG Kairong, et al. A Practical TBM Cutter Wear Prediction Model for Disc Cutter Life and Rock Wear Ability[J]. Tunnelling and Underground Space Technology, 2019,85:92-99.
[7] REN D J, SHEN S L, ARULRAJAH A, et al. Prediction Model of TBM Disc Cutter Wear during Tunnelling in Heterogeneous Ground[J]. Rock Mechanics and Rock Engineering, 2018,51:3599-3611.
[8] WANG Lihui, LI Haipeng, ZHAO Xiangjun, et al. Development of a Prediction Model for the Wear Evolution of Disc Cutters on Rock TBM Cutterhead[J]. Tunnelling and Underground Space Technology, 2017,67:147-157.
[9] MASOUD Z N, MASOUD S, MASOUD R, et al. State-of-the-art Predictive Modeling of TBM Performance in Changing Geological Conditions through Gene Expression Programming[J]. Measurement, 2018,126:46-57.
[10] QIN Chengjin, SHI Gang, TAO Jianfeng, et al. Precise Cutterhead Torque Prediction for Shield Tunneling Machines Using a Novel Hybrid Deep Neural Network[J]. Mechanical Systems and Signal Processing, 2021,151:107386.
[11] ZHANG Qianli, HU Weifei, LIU Zhenyu, et al. TBM Performance Prediction with Bayesian Optimization and Automated Machine Learning[J]. Tunnelling and Underground Space Technology, 2020,103:103493.
[12] 石茂林, 孙伟, 宋学官. 隧道掘进机大数据研究进展:数据挖掘助推隧道挖掘[J]. 机械工程学报, 2021,57(22):344-358.
SHI Maolin, SUN Wei, SONG Xueguan. Research Progress on Big Data of Tunnel Boring Machine:How Data Mining Can Help Tunnel Boring[J]. Journal of Mechanical Engineering, 2021,57(22):344-358.
[13] ELBAZ K, SHEN S L, ZHOU A N, et al. Prediction of Disc Cutter Life during Shield Tunneling with AI via the Incorporation of a Genetic Algorithm into a GMDH-Type Neural Network[J]. Engineering, 2021,7(2):238-251.
[14] YU Honggan, TAO Jianfeng, HUANG Sheng, et al. A Field Parameters-based Method for Real-time Wear Estimation of Disc Cutter on TBM Cutterhead[J]. Automation in Construction, 2021,124:103603.
[15] 杨延栋, 孙振川, 张兵, 等. 基于多个隧道掘进机工程数据回归分析的滚刀磨损评价方法[J]. 中国机械工程, 2021,32(11):1370-1376.
YANG Yandong, SUN Zhenchuan, ZHANG Bing, et al. Disc Cutter Wear Evaluation Method Based on Regression Analysis of Multiple TBM Engineering Data[J]. China Mechanical Engineering, 2021,32(11):1370-1376.
[16] 張康, 黄亦翔, 赵帅, 等. 基于 t-SNE 数据驱动模型的盾构装备刀盘健康评估[J]. 机械工程学报, 2019,55(7):19-26.
ZHANG Kang, HUANG Yixiang, ZHAO Shuai, et al. Health Assessment of Shield Equipment Cutterhead Based on t-SNE Data-driven Model[J]. Journal of Mechanical Engineering, 2019,55(7):19-26.
[17] AGRAWAL A K, MURTHY V M S R, CHATTOPADHYAYA S, et al. Prediction of TBM Disc Cutter Wear and Penetration Rate in Tunneling through Hard and Abrasive Rock Using Multi-layer Shallow Neural Network and Response Surface Methods[J]. Rock Mechanics and Rock Engineering, 2022,55(6):3489-3506.
[18] KARTHIKEYAN T, RAVIKUMAR N. A Survey on Association Rule Mining[J]. International Journal of Advanced Research in Computer and Communication Engineering, 2014,3(1):2278-1021.
[19] YANG Z, TANG W H, SHINTEMIROV A, et al. Association Rule Mining-based Dissolved Gas Analysis for Fault Diagnosis of Power Transformers[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2009,39(6):597-610.
[20] 張天瑞, 于天彪, 赵海峰,等. 数据挖掘技术在全断面掘进机故障诊断中的应用[J]. 东北大学学报 (自然科学版), 2015,36(4):527-532.
ZHANG Tianrui, YU Tianbiao, ZHAO Haifeng, et al. Application of Data Mining Technology in Fault Diagnosis of Tunnel Boring Machine[J]. Journal of Northeastern University(Natural Science), 2015,36(4):527-532.
[21] LI Y, WANG J, DUAN L, et al. Association Rule-based Feature Mining for Automated Fault Diagnosis of Rolling Bearing[J]. Shock and Vibration, 2019,2019:1518246.
[22] 陈勇刚, 孙向东, 崔丽娟,等. 基于关联规则挖掘的航空设备故障诊断研究[J]. 数学的实践与认识, 2021,51(9):99-107.
CHEN Yonggang, SUN Xiangdong, CUI Lijuan, et al. Study on Fault Diagnosis of Aviation Equipment Based on Association Rules Mining[J]. Mathematics in Practice and Theory, 2021,51(9):99-107.
[23] KAUSHIK M, SHARMA R, PEIOUS S A, et al. A Systematic Assessment of Numerical Association Rule Mining Methods[J]. SN Computer Science, 2021,2(5):348.
[24] SAXENA A, RAJPOOT V. A Comparative Analysis of Association Rule Mining Algorithms[J]. IOP Conference Series:Materials Science and Engineering, 2021, 1099:012032.
[25] KE G, MENG Q, FINLEY T, et al. LightGBM:A Highly Efficient Gradient Boosting Decision Tree[J]. Advances in Neural Information Processing Systems, 2017,30:3146-3154.
[26] GARCIA S, LUENGO J, SAEZ J A, et al. A Survey of Discretization Techniques:Taxonomy and Empirical Analysis in Supervised Learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2013,25(4):734-750.
[27] FREITAS A A. A Survey of Evolutionary Algorithms for Data Mining and Knowledge Discovery[M]∥GHOSH A, TSUTSUI S. Advances in Evolutionary Computing:Theory and Applications. Berlin:Springer Berlin Heidelberg, 2003:819-845.
