大数据如何影响劳动收入份额?
——来自国家级大数据综合试验区的证据
2023-12-01高远东
卜 寒 高远东 寻 舟
一、引 言
近些年来,数据技术的进步、云计算的广泛运用、物联网的发展以及智能手机和社交媒体的普及使得世界步入了大数据时代(Pan et al.,2017)。大数据是指海量、高速增长、类型多样和价值巨大的数据,它们来自各种不同的数据源,如社交媒体、移动设备、互联网和传感器网络等(Chen et al.,2014)。目前,大数据已经渗透到生产、销售、营销以及售后的各个领域(Li,2020),成为可以与物质资产、人力资本相媲美的重要生产要素(谢康等,2020),不仅在促进经济增长、提高生产效率、提升创新能力、改善环境等方面发挥着重要作用(杨俊等,2022;张叶青等,2021;Ghasemaghaei and Calic,2020;许宪春等,2019),同时改变了传统生产函数形式(刘国武等,2023),冲击了传统要素收入分配结构,并对劳动收入份额产生了重要影响。从理论上看,大数据对劳动收入份额的影响是复杂的。一方面,大数据能够通过缓解融资约束、创造新任务(Begenau et al.,2018;Gardiner et al.,2018),提高劳动收入份额(Duygan-Bump et al.,2015;Acemoglu and Restrepo,2019)。另一方面,大数据会进一步推动自动化技术快速发展与广泛应用(Helbing,2019),导致劳动收入份额降低(Acemoglu and Restrepo,2019)。然而,遗憾的是,现有研究并未从理论和实证上充分回答大数据是否以及如何影响劳动收入份额。
党的二十大报告明确强调,要“努力提高居民收入在国民收入分配中的比重,提高劳动报酬在初次分配中的比重”。劳动收入份额的增长,不仅关系着国内大循环新发展格局的形成,更是保证全体人民共享经济发展成果、推动更多人群迈入中等收入行列和实现共同富裕的重要机制(钞小静、周文慧,2021)。伴随着数字经济的快速发展,如何在数据要素的冲击下稳定并提升劳动收入份额就显得尤为关键。因此,从理论和实证上深入探索大数据与劳动收入份额的关系,有助于准确把握数字经济时代数据要素对要素收入分配结构的综合效应,为政府制定大数据相关的产业政策、深化收入分配制度提供理论依据与经验证据。
中国一直致力于推动大数据的发展。2015 年8 月,国务院印发了《促进大数据发展行动纲要》,将大数据作为国家重要战略进行全面部署,并提出开展国家级大数据综合试验区建设。国家级大数据综合试验区建设是我国推动大数据发展迈向实际应用的重要一步①国家级大数据综合试验区建设如何推动大数据发展在政策描述部分进行了进一步说明。,具有里程碑意义。该试点政策的实施为研究大数据与劳动收入份额的关系提供了绝佳机会。一方面,国家级大数据综合试验区试点政策的实施对企业劳动收入份额而言,是相对外生的。因为国家级大数据综合试验区建设的初衷是为了在数据资源管理、数据资源整合、数据资源共享、数字资源应用等方面做探索,从而发挥其辐射作用和示范作用(陈文、常琦,2022)。另一方面,国家级大数据综合试验区分批确定名单,使得在不同时间点存在差异化的实验组和对照组样本,让本文可以在错层发生事件形成的准自然实验情境下构建双重差分模型,更为清晰地揭示大数据与劳动收入份额变化的因果关系。
为此,本文尝试利用上市公司微观层面的劳动收入份额数据,对大数据是否以及如何影响劳动收入份额展开研究。与以往研究相比,本文可能存在的边际贡献有:第一,本文在理论和实证上深入探讨了大数据对劳动收入份额的影响,不仅丰富了劳动收入份额影响因素的相关研究,而且拓展了大数据经济后果的研究视角。尽管信息通讯技术(ICT)、人工智能、智能机器人、企业数字化转型对劳动收入份额的影响已有部分研究进行了探讨(Karabarbounis and Neiman,2014;郭凯明,2019;Acemoglu and Restrepo,2020;黄逵友等,2023),但对大数据与劳动收入份额之间的直接关系缺乏足够的关注,这也成为了本文研究的一个重要缺口。第二,本文基于数据要素已经成为数字经济发展的关键要素,能够助推各类数字技术不断深入发展这一基本事实,以大数据作为研究切入点,在一定程度上回应了“数字技术如何影响劳动收入份额”这一争议性话题(黄逵友等,2023),进一步厘清了二者之间的关系,为数字经济趋势下收入分配结构的变动规律提供了新的证据。第三,本文通过将国家级大数据综合试验区试点作为我国大数据发展的一项准自然实验展开研究,不仅有助于大数据与劳动收入份额之间因果效应的准确识别,而且丰富了国家级大数据综合试验区试点政策评估的相关文献。在评估国家级大数据综合试验区试点政策效应的文献中,学者们大多研究国家级大数据综合试验区建设对全要素生产率、企业创新等的影响(邱子迅、周亚虹,2021;陈文、常琦,2022),缺乏对劳动收入份额的探讨。第四,大数据如何改变劳动收入份额的影响机制探究更是缺乏,本文提出并检验了表现为新任务创造效应、自动化扩张效应、自动化加深效应与融资约束缓解效应的影响机制,有助于更为全面地认识数字经济时代下数据要素如何改变要素收入分配结构,为政府部门强化大数据在改善收入差距的作用提供了决策参考。
二、文献综述、政策背景与典型事实
(一)文献综述
劳动收入份额问题一直是经济学关注的重要话题。大量研究探讨了劳动收入份额变化的成因,但都未达成共识。Elsby et al.(2013)认为贸易和离岸外包是美国劳动收入份额下降的主要原因。Piketty(2014)强调了社会规范和劳动力市场制度在解释劳动收入份额变化中的重要作用,比如工会和最低工资的实际价值等。Ergül and Göksel(2020)发现技术进步能够解释20世纪80年代后大多数发达国家和发展中国家劳动收入份额的下降。Autor et al.(2020)发现超级明星企业的崛起是劳动收入份额下降的重要原因。还有一些研究从经济增长(Rubin and Segal,2015)、金融发展(刘长庚等,2022)、资本市场开放(江轩宇、朱冰,2022)等方面研究了劳动收入份额变化的原因。
数字经济时代下,数字技术作为技术进步的一种表现,其对劳动收入份额的影响也得到了学界的广泛关注。理论上而言,数字技术对劳动收入份额的具体影响是不能确定的,这取决于资本对劳动的替代效应、产业部门之间的替代效应、生产率效应以及新任务创造效应的相对大小。首先,数字技术的发展与应用能够降低资本设备成本以及推动生产方式进一步自动化和智能化,从而加快资本对劳动的替代,导致劳动收入份额降低(Karabarbounis and Neiman,2014;Acemoglu and Restrepo,2020)。其次,数字技术的发展与应用催生出新业态、新产业、新需求等,这会创造出劳动具有比较优势的新任务,从而通过岗位增加所带来的就业效应提升劳动收入份额(Acemoglu and Restrepo,2020)。然后,数字技术的发展与应用促进了传统产业生产率提升,使得劳动需求增加,从而引起劳动收入份额增加(Acemoglu and Restrepo,2020)。最后,数字技术的发展与应用会造成生产要素在产业部门之间的差异,如果数字技术使得生产要素流动到资本密集型产业或者自动化产业,就会导致劳动收入份额下降(Aghion et al.,2018;郭凯明,2019)。从实证来看,一些研究从ICT、工业机器人、自动化、人工智能的角度发现了数字技术的应用显著降低了劳动收入份额(Cette et al.,2022;Acemoglu and Restrepo,2020;钞小静、周文慧,2021)。然而,也有实证研究发现,人工智能以及数字化转型能显著提升企业劳动收入份额(金陈飞等,2020;黄逵友等,2023)。
综上,尽管现有研究关注到数字技术对劳动收入份额的影响,但仍然存在几点不足。第一,数字技术作用于劳动收入份额的本质在于,数据投入生产对原先的要素收入结构造成了冲击。然而,现有研究在理论和实证研究上都忽略了数字技术是由数据驱动的本质,对数据要素与劳动收入份额之间的直接关系缺乏足够的重视。第二,由于研究对象选择的局限性,现有研究往往无法清晰地评估数字技术对劳动收入份额的作用机制。第三,现有研究在度量人工智能、自动化、数字化转型、大数据应用等发展程度上仍然未能形成统一的标准,这会造成研究结论的偏差。本文通过选择国家级大数据综合试验区建立这一外生冲击研究大数据对劳动收入份额的影响及其作用机制,不仅补充了数字技术影响劳动收入份额的相关研究,而且在一定程度上弥补了上述三点不足。
(二)政策背景
随着互联网、5G、物联网、云计算等信息技术的发展与普及,世界步入大数据时代。如何从大数据中发现知识并将其转化为生产力已经成为赢得全球竞争的重要因素。近年来,中国和世界其他国家一样,一直致力于推动大数据的发展。总体来说,我国大数据发展可以分为三个阶段。第一个阶段为初步阶段。该阶段位于2014年以前,更多的是对大数据理念和技术的探讨,未能形成完整的体系。第二阶段为落地阶段。该阶段位于2014年到2019年之间,大数据发展已经上升到国家战略,大数据综合试验区有序推进,各个省份大数据相关政策陆续出台。第三阶段为深化阶段。该阶段位于2019年之后,数据已经正式成为新型生产要素,并明确提出数据要素是数字经济发展的关键要素。
其中,国家级大数据综合试验区试点政策是中国推动大数据发展迈向实际应用的重要一步,具有里程碑意义。该试点政策主要从三个方面推动大数据发展。第一,建立健全的市场体系是大数据发展的重要基础,大数据综合试验区通过建立法律法规、产业生态和安全保障体系等方式完善市场体系。第二,完善大数据基础设施是大数据发展的必要保障,大数据综合试验区将加强大数据共享、交易、聚集和应用等平台建设,从而形成完整的大数据基础设施,以促进数据资源的共享和应用。第三,优质的数据资源是大数据发展的关键,大数据综合试验区将加大大数据产业投资,推动当地产业数字化,以提升数据资源的质量。这些举措将有助于中国在大数据领域取得更大的进步,推动数字经济的快速发展。
此外,尽管国家级大数据综合试验区与“宽带中国”示范城市和智慧城市等一系列相近政策都能够促进数字经济和信息化的发展,但在政策目标、重点领域和实施手段等方面存在着本质差异,以推动多个方面的数字经济发展和适应不同层面的需求。在政策目标方面,大数据综合试验区政策是以数据创新和应用为主要目标,通过充分挖掘和利用大数据的经济社会价值,加速数字经济的转型升级;“宽带中国”示范城市政策是以推进信息基础设施建设为主要目标,通过提升网络速度和质量,促进数字经济发展;智慧城市政策的目标是建设具有智能化和互联网化特征的城市,通过促进城市数字化、信息化发展,加强城市智能治理。在重点领域方面,大数据综合试验区政策主要关注大数据技术的创新和应用,以及大数据产业的发展;“宽带中国”示范城市政策主要关注信息基础设施建设,以及网络速度和质量的提升;智慧城市政策则注重城市数字化、信息化建设,推动城市智能化和互联网化发展。在实施手段方面,大数据综合试验区政策主要通过组建试验区、推动科技创新、扶持创业创新等多种手段来推动大数据产业和应用创新;“宽带中国”示范城市政策主要加强网络基础设施建设,如宽带网络覆盖率的提升和网络质量的优化;智慧城市政策主要是通过数字技术应用对城市管理进行变革,例如城市智慧交通、智能医疗等。
目前,大数据综合试验区总共分为两批获批建设。第一批建设名单为贵州省,于2015年获批成为全国首个大数据综合试验区建设省份。第二批建设名单在2016 年公布,包括京津冀、珠江三角洲、上海、河南、重庆、沈阳以及内蒙古。至此,国内一共有八大大数据综合试验区,将共同引领东部、中部、西部、东北等“四大板块”的大数据产业发展,实现数据共享、区域内协同发展、加快产业转型。国家级大数据综合试验区的设立,将在大数据创新与应用、大数据产业发展、数据共享与利用等方面发挥示范与引领作用,进而推动我国大数据发展迈向新的台阶。
(三)典型事实
本文通过分别测算劳动收入份额整体趋势变动以及非试点城市与试点城市劳动收入份额变化①城市劳动收入份额为城市内上市企业的平均劳动收入份额。,对试点政策与劳动收入份额之间的关系进行直观上的探讨。由图1可知,劳动收入份额整体存在一个上升趋势,这与现有的研究结论一致。另外,在2015 年大数据试点区第一批名单实施后,劳动收入份额整体有一定幅度的下降,而随着2016年大数据试点区第二批名单实施,劳动收入份额整体又出现上升。与此同时,由图2可知,在试点政策实施之前,非试点城市和试点城市劳动收入份额非常一致,变化趋势相同。在试点政策实施之后,非试点城市和试点城市劳动收入份额出现明显差异,试点城市的劳动收入份额水平开始显著高于非试点城市的相应水平②图1 与图2都显示在2020年劳动收入份额存在一个大幅度下降,这可能是由于新冠疫情所引起的反应。。因此,初步推断大数据试点区的实施与劳动收入份额可能存在一定的正相关关系。
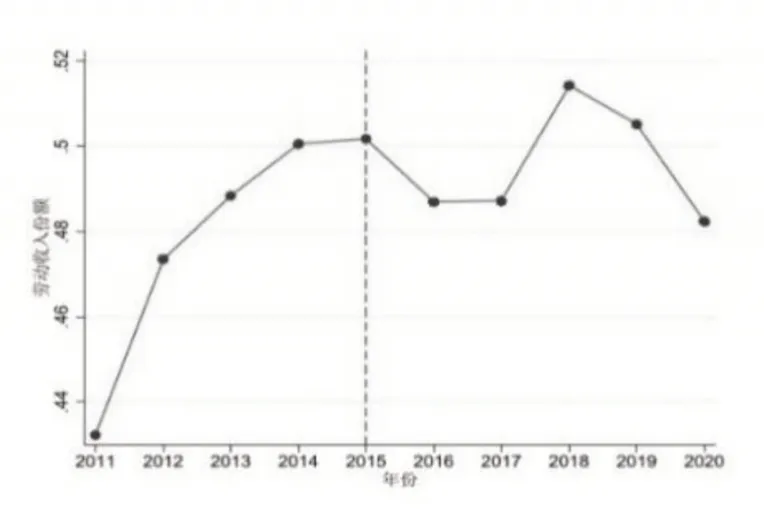
图1 劳动收入份额整体变化趋势
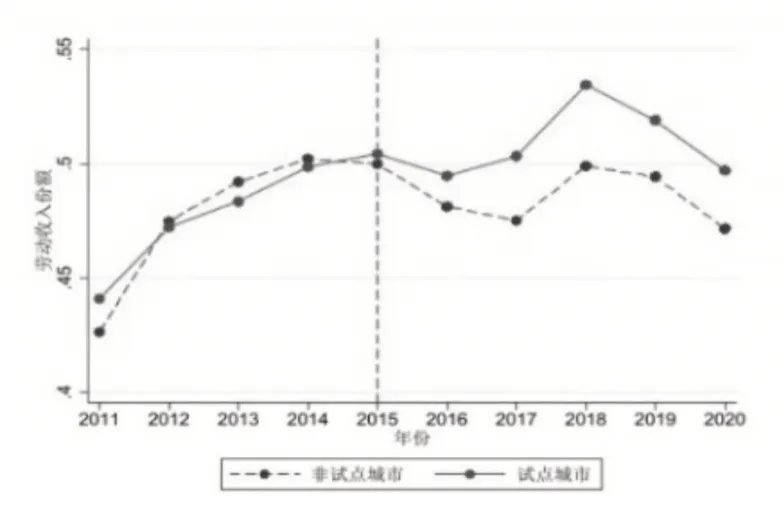
图2 非试点城市与试点城市劳动收入份额变化
三、理论分析
本文在Acemoglu and Restrepo(2019)的任务模型框架下进行理论分析,包括构建基本模型与提出研究假说两部分内容。
(一)基本模型
假设企业总产出是由一系列任务构成的服务(产品)生产,且服从C-D 函数形式:
其中,Y 为总产出;y(x)为任务x 提供的服务(产品);积分上限N 代表任务上限,定积分在[N-1,N]可积。之所以将积分下限和上限设定在N-1 到N 之间,是为了保证在任务总量不变(任务总量始终为1)的情况下考虑任务变化带来的影响。
假设存在一个自动化界限I,任务x ∈[N - 1,I]能够从技术上实现自动化,而任务x ∈(I,N]不能够从技术上实现自动化。那么,任务x ∈[N - 1,I]既可以由劳动生产,也可以由资本生产,而任务x ∈(I,N]只能够由劳动生产。因此,y(x)的函数可以进一步表示为:
其中,L( x )与C( x )分别为任务x的劳动投入与资本投入,τL( x )与τC( x )分别为劳动生产率与资本生产率。
为了简化讨论,进一步假设:
其中,W和R分别为劳动的均衡工资率与资本的均衡成本。第一个不等式意味着新任务会引起总产出的增加。第二个不等式意味着任务x ∈[N - 1,I]将全部由资本生产,即全部自动化。
在式(3)的假设下,任务x的劳动需求C(x) 为:
假设市场上总劳动供给L 是固定且无弹性的。那么,在市场出清的条件下,总的劳动需求可以表示为:
进一步地,可以得到市场的劳动收入份额LIS:
(二)研究假说
1.大数据、新任务创造与劳动收入份额
由式(6)对工作任务N求偏导:
由式(7)可知,创造劳动具有比较优势的新任务能提高劳动收入份额。与此同时,大数据投入生产会形成新任务创造效应,增加对高、中低技能劳动力的需求。一方面,大数据中所提取的知识能够直接用于改进决策和提高绩效,进而帮助企业获得竞争优势(Shan et al.,2019)。因此,利用大数据获得竞争优势的企业发展战略正在冲击就业市场,形成了对统计人员、数据分析师、数据工程师、数据科学家以及处理数据的其他专业人员的强烈需求(Gardiner et al.,2018),有助于高技能劳动力就业。另一方面,大数据发展对平台经济、共享经济发展的推动(Lobel,2018),进一步催生了更为灵活的数字劳动平台(Schmidt,2017),从而产生了连接供给和需求两端的新任务和新就业,如外卖配送员、网约司机、线上销售、网络主播等,这极大地增加了对中低技能劳动力的需求。基于上述分析,提出如下假说:
假说1:大数据通过新任务创造效应提升劳动收入份额。
2.大数据、自动化扩张与劳动收入份额
由式(6)对自动化界限I求偏导:
由式(8)可知,自动化扩张会降低劳动收入份额。这是因为自动化扩张会产生替代效应,将原先劳动执行的任务替换为更廉价的资本,导致劳动力的需求减少,降低了劳动收入份额(Acemoglu and Restrepo,2019)。与此同时,大数据的普及和发展将进一步推动自动化的扩张(Helbing,2019)。大数据能够通过促进人工智能技术发展(Allam and Dhunny,2019)和推动农业、工业以及服务业机器人“智能化”(Li and Lai,2022),扩展机器人在生产和服务中的应用场景,引起更广泛的自动化应用。不仅如此,大数据已经渗透到生产、销售、营销以及售后的各个领域(Li,2020),实现了部分程序自动化,例如个性化医疗服务、无人零售超市、物流智能分拣等。智能机器人应用边界的扩展以及部分程序自动化的实现使得更多的不同技能劳动力面临被替换的风险。基于上述分析,提出如下假说:
假说2:大数据通过自动化扩张效应降低劳动收入份额。
3.大数据、自动化加深与劳动收入份额
对式(5)求微分:
dln(Y N) dI 表示自动化扩张对生产率的影响即自动化加深效应(Acemoglu and Restrepo,2018)。由式(9)可知,如果自动化扩张能够形成自动化加深效应,那么自动化加深效应就可以促使工资的增加来提升劳动收入份额。与此同时,大数据会促进生产率的提升(张叶青等,2021)。具体而言,大数据主要通过帮助企业决策、推动企业实现智能生产以及促进企业创新三个渠道提升企业生产率。第一,信息理论认为更详细和准确的信息有利于决策者决策(Blackwell,1953)。由于大数据的存在,管理者可以更全面地衡量和了解自身业务以及客户需求,并将这些知识直接转化为改进的决策,提高生产率(Brynjolfsson et al.,2011)。第二,大数据通过物联网实时自动采集,并将其应用于产品设计、生产计划、制造和预测性维护等各方面,推动企业实现智能生产,从而带来更高的生产率(He and Bai,2021)。第三,一方面,大数据可以通过提升企业新知识发现率与知识分享和合作能力促进企业创新(Ghasemaghaei and Calic,2020)。此外,大数据还能够通过帮助企业充分了解客户的产品和服务需求(Farboodi et al.,2019),提前分析并预测客户的偏好,创造新的产品和服务。另一方面,创新能够显著促进企业生产率的提升(Mukhametzhanova et al.,2019)。基于上述分析,提出如下假说:
假说3:大数据通过自动化加深效应提升劳动收入份额。
4.大数据、融资约束与劳动收入份额
企业的投资行为和创新活动受到融资约束制约(Chen and Yoon,2022;赵扬、杜凯,2023)。那么,自动化升级与开发新产品和新服务势必也会受到融资约束的影响,从而对劳动收入份额造成影响。不仅如此,融资约束所引起的留存利润分配效应、流动性约束效应与要素配置效应同样会制约劳动收入份额的增长(熊家财等,2022)。然而,大数据能够有效缓解融资约束(Begenau et al.,2018)。一方面,大数据通过规避信息不对称与道德风险缓解企业融资约束。信息不对称与道德风险不利于企业获得融资机会以及降低其利率(Armstrong et al.,2010;Momtaz,2021)。投资者可以通过使用大数据深度挖掘企业生产、交易、财务等信息,以尽量规避事前的信息不对称。同时,在大数据的基础上,投资者也可以运用机器学习、人工智能等技术,建立相应动态分控模型,以规避事后的道德风险。另一方面,大数据能够助推数字金融平台发展(Gomber et al.,2017),进而缓解融资约束(熊家财等,2022)。数字金融发展使得原来单调的融资服务更为多元,从而引起融资增量的提升。此外,数字金融发展带来的市场竞争效应有利于传统金融机构贷款利率的降低以及贷款意愿的提高。基于上述分析,提出如下假说:
假说4:大数据通过融资约束缓解效应提升劳动收入份额。
基于上述全部理论分析,提出如下假说:
假说5a:大数据能够提升劳动收入份额。
假说5b:大数据能够降低劳动收入份额。
四、研究设计
(一)计量模型
考虑到国家级大数据综合试验区试点地区并非在同一时点被批复,参考已有文献(陈文、常琦,2022),本文使用多期双重差分模型进行评估,具体模型设定为:
其中,被解释变量LISit代表企业i在t年的劳动收入份额;核心解释变量BDcit表示在t年企业i的注册地所在城市c是否为国家级大数据综合试验区试点城市,是则取值为1,否则为0;δi和μt分别为公司固定效应和年份固定效应;ϵit为干扰项;Zt表示一系列影响劳动收入份额的控制变量,包括企业层面和城市层面的控制变量。θ为本文关注的核心结果,衡量了大数据对劳动收入份额的影响效果。
(二)变量选取
1.被解释变量为劳动收入份额(LIS)。本文使用江轩宇、朱冰(2022)的要素成本增加值法度量劳动收入份额,即劳动收入份额(LIS)表示为“支付给职工以及为职工支付的现金”与“营业收入-营业成本+支付给职工以及为职工支付的现金+固定资产折旧”之比。
2.核心解释变量为BDcit。若在t年企业i的注册地所在城市c为国家级大数据综合试验区试点城市,BDcit取值为1,否则为0。
3.中介变量。(1)员工雇佣(EN_LN)。借鉴刘长庚等(2022)的做法,以企业职工人数自然对数作为其员工雇佣的代理变量。(2)全要素生产率(TFP_OP 和TFP_LP)。分别以OP 法和LP 法计算企业全要素生产率。(3)融资约束(SA)。以SA指数衡量企业融资约束程度。
4.控制变量。为了避免遗漏重要变量对估计结果造成的影响,参考施新政等(2019),江轩宇、朱冰(2022)等文献,本文选取以下控制变量:企业层面的控制变量包括总资产自然对数(TA_LN)、总资产负债率(TALR)、销售收入增长率(SRGR)、销售毛利率(SGP)、上市年限自然对数(AGE_LN)、总资产收益率(RTA)、资本产出比(COR)、资本密集度(CI)、托宾Q(QB)、员工收入自然对数(INCOME_LN)、第一大股东占比(FP)、管理层持股比例(MSR)、董事会规模(BS)、独立董事占比(IDR);城市层面的控制变量包括生产总值自然对数(GDP_ln)、年末人口总量自然对数(TP_ln)、产业结构(IS)、人均国际互联网用户数(PINTER)、人均移动电话用户数(PMOBILE)、人均电信业务总量(PTB)。
(三)数据说明
考虑到国家级大数据综合试验区的批复时间以及数据的可得性,本文选取2011—2020年我国A股上市公司作为研究对象。在样本处理过程中,参考施新政等(2019)以及江轩宇、朱冰(2022)的做法:(1)剔除金融和保险行业的上市公司;(2)剔除ST 和*ST 公司;(3)剔除关键变量缺失的样本;(4)剔除劳动收入份额大于等于1 或者小于等于0 的样本。经过上述处理,最终得到21927 个观测值的非平衡面板数据①以劳动收入份额的样本个数为最终样本数据总量。。本文使用的企业数据来源于CSMAR 数据库和Wind数据库,城市数据来源于《中国城市统计年鉴》。主要变量的描述性统计结果见表1。
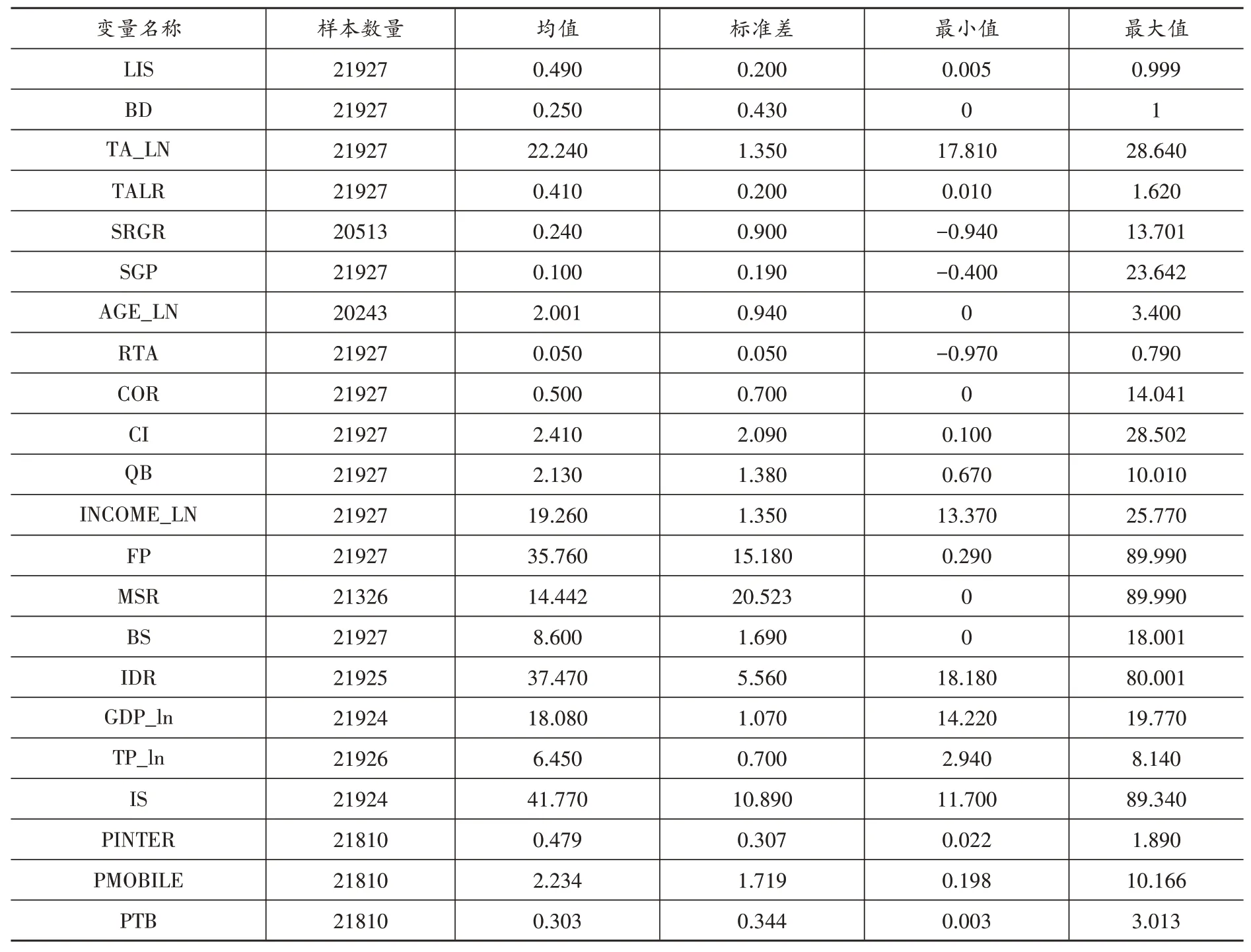
表1 变量描述性统计结果
五、实证结果与分析
(一)基准回归结果
表2报告了多期DID 的基准回归结果,其中列(1)仅考虑核心解释变量;列(2)进一步加入企业层面控制变量;列(3)则加入全部控制变量。三个回归结果显示,虚拟变量BD 的回归系数分别在10%、5%和1%的统计水平上显著为正。该结果说明,国家级大数据综合试验区试点政策的实施显著提高了试点城市企业的劳动收入份额。以列(3)为基准,从经济意义看,国家级大数据试点政策实施后,试点城市企业的劳动收入份额平均提高了0.7个百分点。因此,假说5a初步得到验证。

表2 基准回归结果
表3 稳健性检验
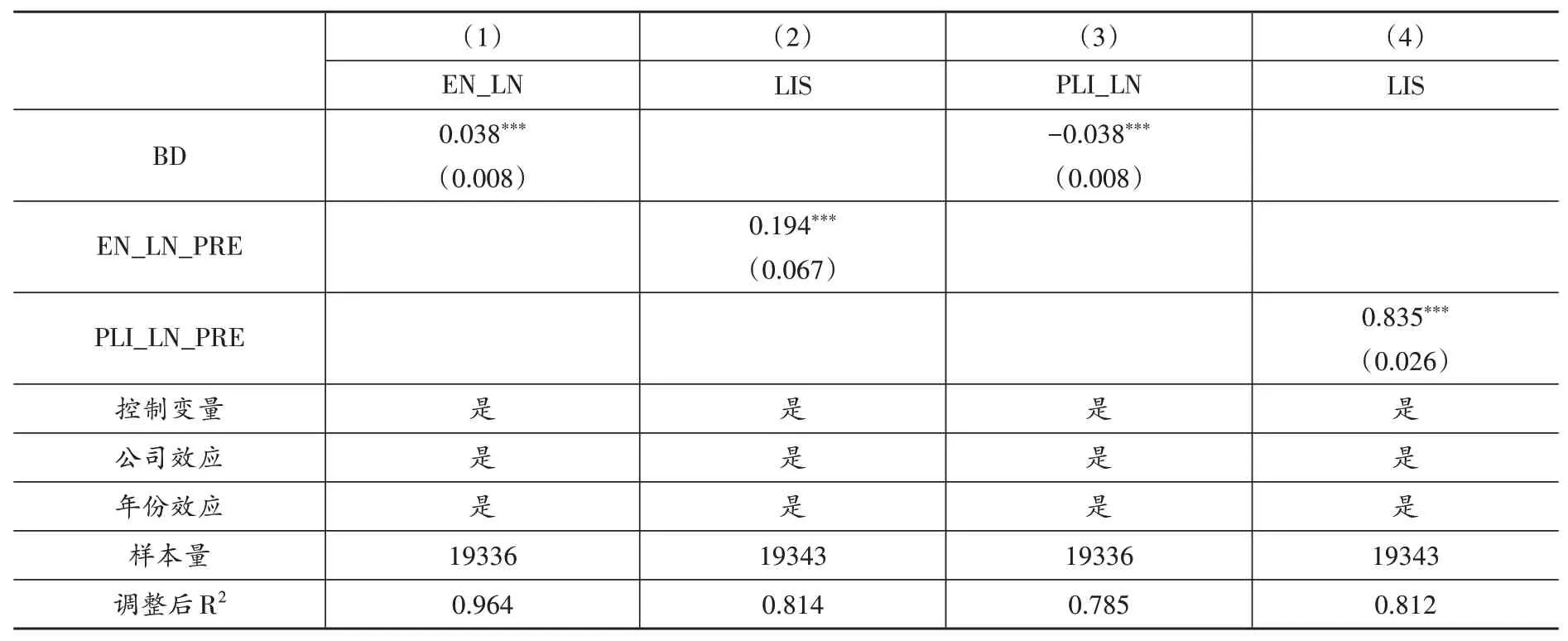
表4 新任务创造与自动化扩张
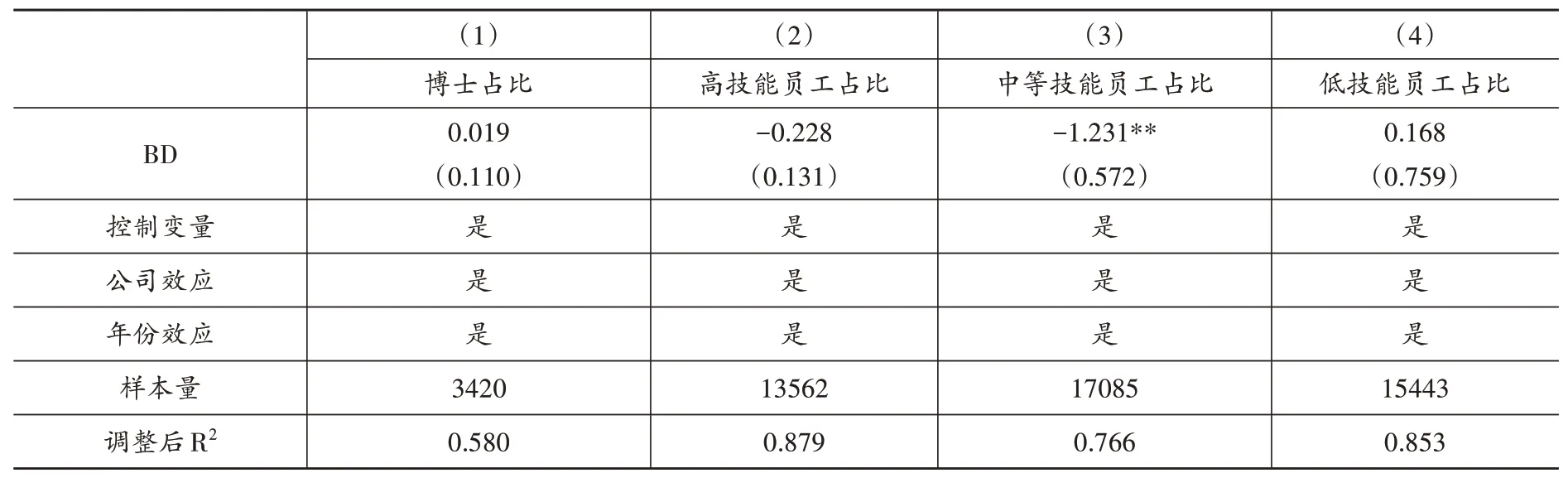
表5 大数据对不同类型员工的影响
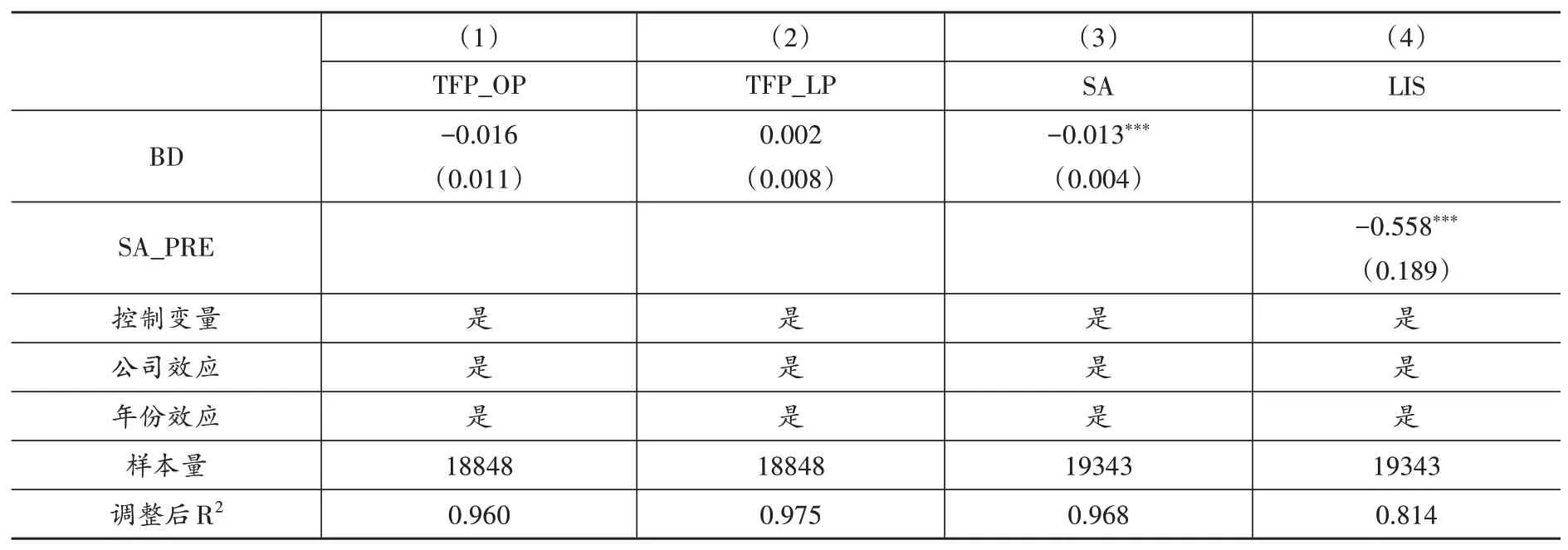
表6 自动化加深与融资约束缓解
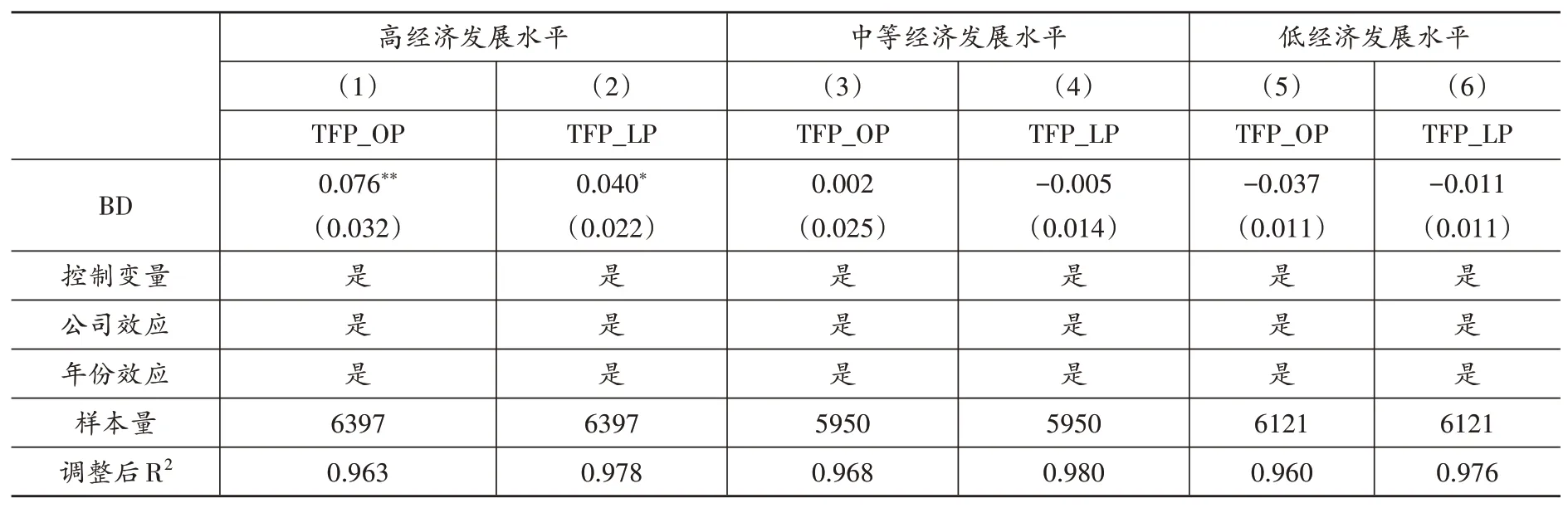
表7 自动加深效应的进一步分析结果
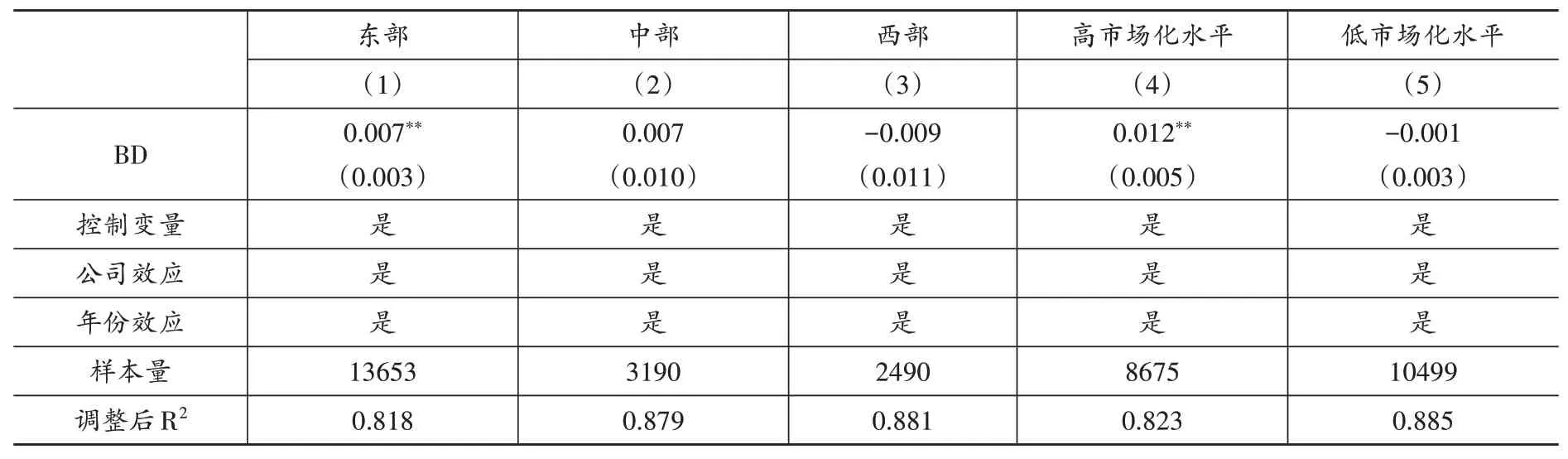
表8 区分区域和市场特征的回归结果
(二)稳健性检验
1.平行趋势检验
平行趋势假设是多期DID 模型准确识别因果关系的关键前提,即在政策实施前,试验组和控制组的劳动收入份额变化趋势必须是平行的。为此,本文使用事件研究法检验该假设,其具体模型表示为:
该式中各变量的符号含义与式(10)一致。本文重点关注系数θt,其反映了大数据综合试验区建立的第t年,试点城市与非试点城市企业的劳动收入份额差异。此外,本文将大数据综合试验区建立前5 年的数据汇总到第-5 期,大数据综合试验区建立后5 年的数据汇总到第4 期,并以第-5 期为基期。图3所示的平行趋势检验结果显示,大数据综合试验区建立前各年份的系数估计值均不显著①图3 中的短竖线代表90%水平置信区间,实心原点代表式(11)中的θt估计值。。该结果说明,试点城市和非试点城市企业的劳动收入份额在大数据综合试验区建立前无显著差异,研究样本通过了平行趋势检验。同时,该结果显示大数据综合试验区的建立对企业劳动收入份额存在持续的促进效应。

表9 区分要素结构和所有制特征的回归结果
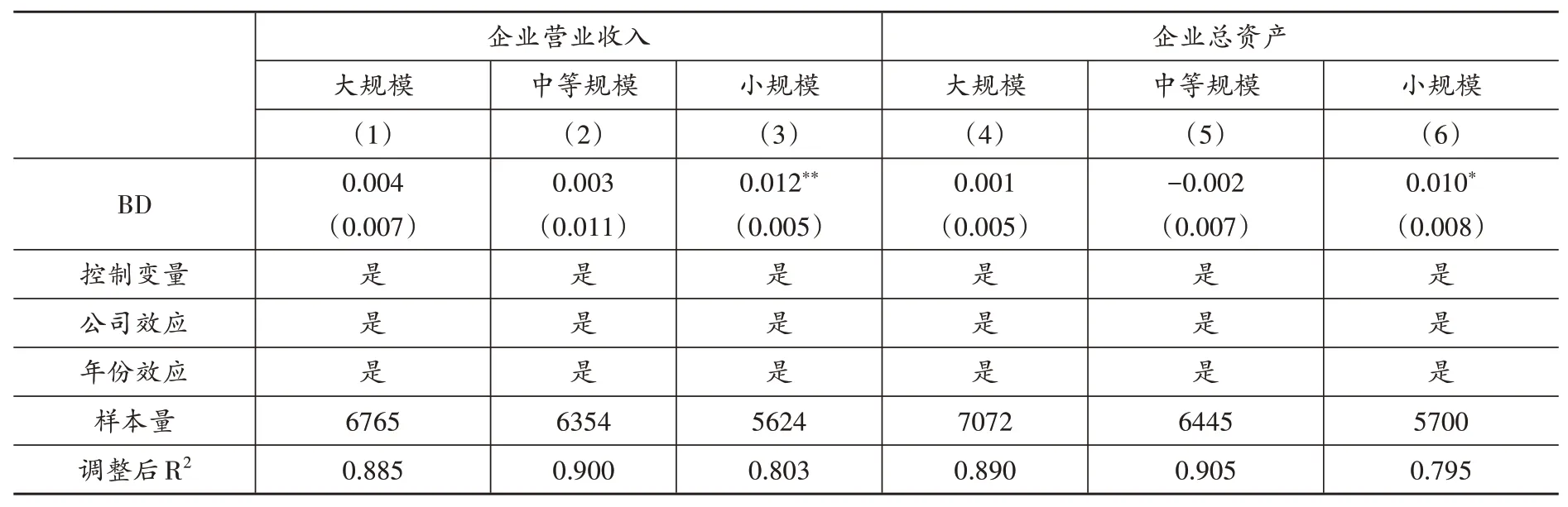
表10 区分规模特征的回归结果
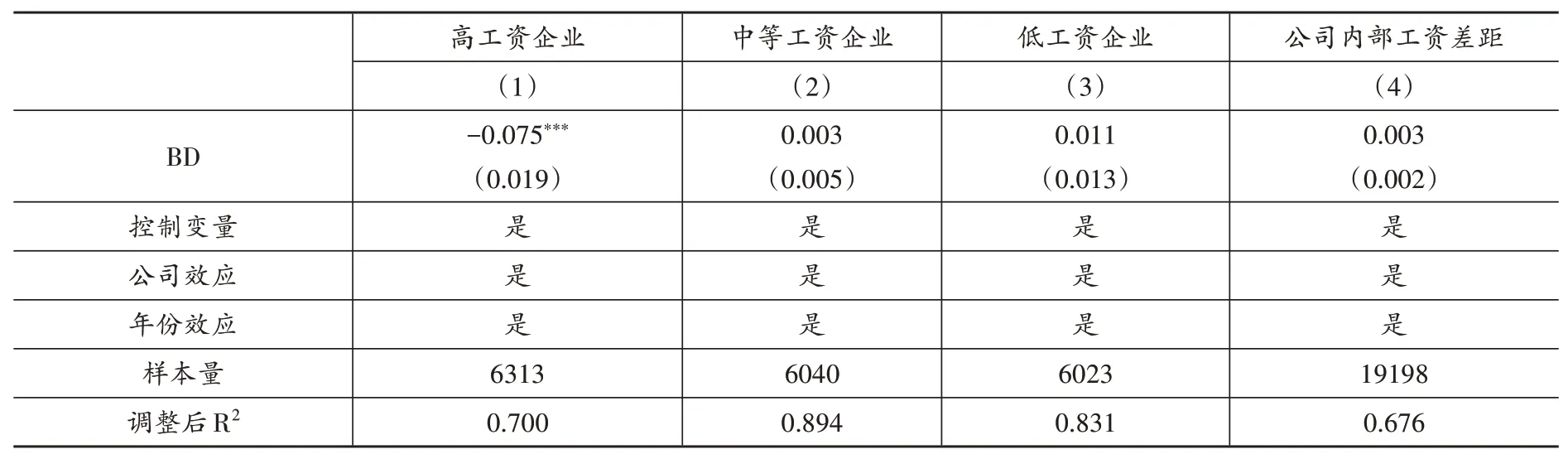
表11 大数据对工资差距的影响
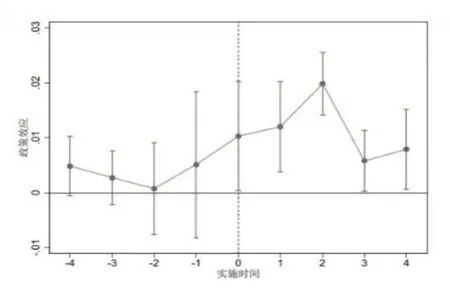
图3 平行趋势检验图
2.安慰剂检验
为了进一步排除不可观测因素对基准回归结果的影响,本文通过随机处理城市与年份进行安慰剂检验。在所有样本中随机假定大数据综合试验区试点政策实施时间与地区,用以代替模型(10)中的BD 变量,并对其重新进行回归。为使安慰剂检验结果更加稳健可靠,本文重复上述过程500 次,结果如图4 所示,虚假的θ 值大都落在0 附近且服从正态分布,绝大多数结果的P 值均大于0.1。另外,真实θ 值大于大多数的虚假θ 值,这表明该结果在安慰剂下是极小概率会发生的情况。因此,可以说明基础回归结果通过安慰剂检验,大数据综合试验区试点地区所属企业劳动收入份额的提升作用与不可观测因素的因果关系不大。
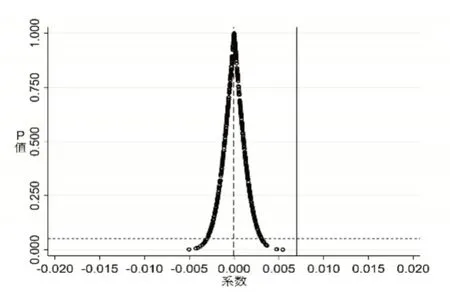
图4 安慰剂检验
3.PSM-DID模型
为了避免样本选择性偏差所造成的内生性问题,本文使用了PSM-DID 模型,重新对式(10)进行估计。结果如表3第(1)、(2)以及(3)列所示,分别采用最邻近匹配法、核匹配法和半径匹配法后,BD的估计系数仍然在10%、5%和5%的水平上显著,该结果与基础回归结果一致。
4.其他稳健性检验
为了进一步保证研究结论的稳健性,本文还从样本数据筛选、排除重大事件的干扰、排除其他政策干扰以及控制高维固定效应等多个维度进行分析。
(1)样本数据筛选。为了避免极端值对研究结论的影响,根据变量LISit对研究样本进行1%的缩尾处理,重新对式(10)进行估计。结果如表3 第(4)列所示,在剔除极端值后,BD 的估计系数仍然在1%的水平上显著为正,该结果与基准回归结果一致。
(2)排除重大事件的干扰。2020 年新冠疫情爆发对企业的生产和经营都产生了重大影响,为了避免在样本期间所发生的重大事件影响劳动收入份额,造成基准结果的估计偏误,本文删除2020年的样本数据,重新对式(10)进行估计。结果如表3 第(5)列所示,在删除2020 年的样本数据后,大数据综合试验区试点政策仍然在5%的显著水平上提升了劳动收入份额,该结果与基础回归结果相似。
(3)排除其他政策干扰。在大数据综合试验区政策实施期间,其他相近政策可能也会对大数据发展以及劳动收入份额产生影响,例如“宽带中国”示范城市、智慧城市建设等政策①本文的政策背景部分已对国家级大数据综合试验区建设与“宽带中国”示范城市、智慧城市建设等相似政策的本质差异进行了说明。。为了避免样本期间由于这些相似政策干扰所产生的估计结果偏误,本文在基准回归中加入“宽带中国”示范城市(POLICY1)、智慧城市建设(POLICY2)等政策的虚拟变量,重新对式(10)进行估计。结果如表3 第(6)列所示,在加入“宽带中国”示范城市以及智慧城市试点政策的虚拟变量后,大数据综合试验区试点政策仍然在1%的显著水平上提升了劳动收入份额,该结果与基础回归结果一致。
(4)控制高维固定效应。尽管同时控制年份和公司固定效应能缓解一部分遗漏变量引起的估计偏误,但仍然存在一些随时间变化的不可观察的行业因素对研究结果产生影响。为此,本文进一步控制“行业-年份”层面的固定效应,重新对式(10)进行估计。结果如表3 第(7)列所示,在控制“行业-年份”层面的固定效应后,大数据综合试验区试点政策仍然在5%的显著水平上提升了劳动收入份额,该结果与基础回归结果相似。
六、影响机制的经验分析
(一)直接效应:新任务创造与自动化扩张
理论分析表明,大数据能通过新任务创造与自动化扩张效应影响劳动收入份额。为了验证该渠道是否成立,本文从如下三方面展开研究:
首先,检验大数据对企业员工雇佣规模的影响。大数据投入生产所导致的新任务创造与自动化扩张效应会直接影响企业员工雇佣规模。本文以员工人数自然对数(EN_LN)作为企业雇佣的代理变量,并借鉴陆雪琴、鲁建坤(2022)的做法使用两阶段回归法识别影响机制,表(4)第(1)和第(2)列分别报告了第一阶段和第二阶段回归结果。第一阶段回归中,BD 的估计系数显著为正(0.038),说明大数据综合试验区试点城市企业雇佣规模相对于其他企业上升了3.8%。第二阶段回归中,将第一阶段回归得到的因变量员工人数自然对数预测值(EN_LN_PRE)作为自变量,来分析大数据综合试验区试点政策是否通过扩大企业员工雇佣规模对劳动收入份额产生作用。第二阶段回归中,EN_LN_PRE 的估计系数显著为正(0.194),说明大数据综合试验区试点政策实施所引起的企业员工雇佣规模增加导致了企业劳动收入份额的上升。上述结果表明,大数据能够通过新任务创造效应提升劳动收入份额,假说1 得到印证。但是,对于是否存在自动化扩张效应,还需进一步验证①员工雇佣规模取决于新任务创造效应与自动化扩张效应的相对大小。。
其次,检验大数据对企业不同类型员工雇佣规模的影响。理论分析表明,大数据引起的新任务创造效应既能创造高技能任务,也能创造中低技能任务。同时,大数据引起的自动化扩张效应不仅会减少低技能任务,还会进一步替换掉部分中等技能任务。本文按照教育程度,将硕士及以上学历的员工视为高技能员工,本科及专科学历的员工视为中等技能员工,高中及以下学历的员工视为低技能员工。表(5)报告了大数据综合试验区试点政策影响不同类型员工雇佣规模的回归结果。第(1)列表明,大数据综合试验区试点政策对博士学历员工的需求存在一个正向影响,但并不显著。第(2)—(4)列结果显示,大数据综合试验区试点政策显著降低了中等技能员工需求,而对高技能与低技能员工需求影响不显著。上述结果至少可以得出两点结论:第一,大数据能够通过自动化扩张效应降低劳动收入份额,假说2得到印证;第二,大数据可能会引起“就业极化”现象。
最后,检验大数据对企业员工工资水平的影响。大数据投入生产所引起的新任务创造与自动化扩张效应会导致劳动市场需求与供给的相对变化,从而引起工资水平变化,这会直接影响劳动收入份额。为此,本文以企业员工人均工资自然对数(PLI_LN)作为企业员工工资水平的代理变量,并使用两阶段回归法识别影响机制,表(4)的第(3)和第(4)列分别报告了第一阶段和第二阶段回归结果。第一阶段回归中,BD 的估计系数显著为负(-0.038);第二阶段回归中,企业员工人均工资自然对数预测值(PLI_LN_PRE)的估计系数显著为正(0.835)。该结果说明,大数据主要通过扩张低工资岗位提升劳动收入份额。
(二)间接效应:自动化加深与融资约束缓解
理论分析表明,大数据能通过自动化加深与融资约束缓解效应影响劳动收入份额。为了验证该渠道是否成立,本文从如下两方面展开研究:
首先,检验大数据对企业全要素生产率的影响。自动化加深的标志是生产率的提升(Acemoglu and Restrepo,2018)。因此,本文分别采用OP 法与LP 法测算企业全要素生产率(TFP_OP 和TFP_LP),并以企业全要素生产率作为企业自动化加深的代理变量来识别该作用机制,表6前两列报告了回归结果。从第(1)和第(2)列来看,BD的估计系数并不显著,说明大数据综合试验区试点政策并未提升企业全要素生产率。之所以会出现这种情况,原因可能在于缺乏与大数据匹配的新型基础设施、缺乏大数据人才、大数据与企业生产融合度不够等。也就说,在经济发展水平高的地区,可能才会产生自动化加深效应。为此,本文进一步以样本内各年份地区GDP 的1/3 分位数以及2/3 分位数为临界点,分别将样本划分为高经济发展水平地区、中等经济发展水平地区与低经济发展水平地区三组后进行回归,表(7)中报告了该分组回归结果。结果表明,在经济发展水平高的地区大数据才能显著地提升全要素生产率,即产生显著的自动化加深效应。因此,假说3得到验证。
其次,检验大数据对企业融资约束程度的影响。本文使用SA指数(SA)衡量企业融资约束程度,并使用两阶段回归法识别作用渠道,表(6)的第(3)和第(4)列报告了两阶段回归结果。第一阶段回归中,BD 的估计系数显著为负(-0.013),说明大数据综合试验区试点城市企业融资约束程度相对于其他企业下降了1.3%。第二阶段回归中,将第一阶段回归得到的因变量SA指数预测值(SA_PRE)作为自变量,来分析大数据综合试验区试点政策是否通过降低融资约束对劳动收入份额产生作用。第二阶段回归中,SA_PRE的估计系数显著为负(-0.558),说明企业融资约束的增加会导致企业劳动收入份额的下降。上述结果表明,大数据能够通过缓解企业融资约束提升劳动收入份额,假说4 得到验证。
七、进一步分析
(一)企业外部环境的异质性影响
1.区域差异。区域发展不平衡是我国长期存在的问题。区域发展不平衡所导致的各地区大数据发展与应用的不平衡,会使得大数据对劳动收入份额的影响存在差异。为了考察大数据对劳动收入份额影响的区域异质性,本文按照企业注册地,将全样本划分为东部、中部与西部三组后分别进行回归,表(8)中的第(1)-(3)列分别报告了三组回归结果。从回归结果可知,大数据综合试验区的建立显著提高了东部地区试点城市企业的劳动收入份额,而对中西部企业的劳动收入份额影响不显著。出现该情况的原因可能在于,东部地区相对中西部地区拥有更完善的新型基础设施建设、巨大的人力资本优势以及良好的融资环境,这有利于当地企业发挥大数据在生产中形成的新任务创造效应、自动化加深(生产率)效应以及融资约束缓解效应,进而提升企业劳动收入份额。
2.市场化差异。市场化水平越高的地区,该地区企业技术效率越高(李胜文等,2013)。市场化水平会影响大数据技术效率,进而对劳动收入份额产生影响。大数据对劳动收入份额的影响可能因为市场化水平的不同而存在差异。为了考察大数据对劳动收入份额影响的市场化异质性,本文根据王小鲁等(2021)编制的省级市场化水平总指数,以各年份省份市场化水平总指数的中位数为界,将全样本划分为高市场化水平与低市场化水平两组后分别进行回归,表(8)中的第(4)-(5)列分别报告了两组回归结果。从回归结果可知,大数据综合试验区的建立显著提高了高市场化水平地区试点城市企业的劳动收入份额,而对低市场化地区试点城市企业的劳动收入份额影响不显著。在高水平市场化地区,大数据技术效率更高,这有利于企业基于大数据提高生产效率,开发新产品、新服务,创造出新的岗位,进而提升劳动收入份额。
(二)企业内部特征的异质性影响
1.要素结构差异。相对于资本密集型行业,技术密集型行业与劳动密集型行业更依赖于劳动力。大数据对劳动收入份额的影响可能因企业不同要素结构而存在差异。为了考察大数据对企业劳动收入份额影响的要素结构异质性,本文根据鲁桐、党印(2014)的做法将样本划分为资本密集型企业、技术密集型企业与劳动密集型企业三组后进行回归,表(9)中的第(1)-(3)列分别报告了三组回归结果。从回归结果可知,大数据综合试验区的建立显著提高了试点城市资本密集型企业的劳动收入份额,而对试点城市技术密集型企业与劳动密集型企业的劳动收入份额影响不显著。可能的原因在于,相对于技术密集型与劳动密集型企业,资本密集型企业拥有更完备的信息基础设施与较少的中低技能劳动力,这使得大数据在资本密集型企业中产生了更大的新任务创造效应与自动化加深效应以及更小的自动化扩张效应,这有助于资本密集型企业提升劳动收入份额。
2.所有制差异。相对于国有企业,非国有企业具有更高的逐利性和更大的竞争压力。大数据对劳动收入份额的影响可能因企业所有制不同而存在差异。为了考察大数据对企业劳动收入份额影响的所有制异质性,本文将样本划分为国有企业与非国有企业两组后进行回归,表(9)中的第(4)-(5)列分别报告了两组回归结果。从回归结果可知,大数据综合试验区的建立显著提升了试点城市非国有企业的劳动收入份额,而对试点城市国有企业的劳动收入份额影响不显著。可能的解释为,非国有企业为了保持竞争力、取得更大利润,大力投资并应用大数据,充分发挥了大数据在生产中形成的新任务创造效应、自动化加深(生产率)效应以及融资约束缓解效应,进而提升企业劳动收入份额。
3.规模差异。劳动收入份额会受到企业规模的影响(陆雪琴、田磊,2020)。因此,大数据对劳动收入份额的影响可能因企业规模不同而存在差异。为了考察大数据对企业劳动收入份额影响的规模异质性,本文以样本内各年份企业营业收入与总资产的1/3 分位数以及2/3 分位数为临界点,分别将样本划分为大规模企业、中等规模企业与小规模企业三组后进行回归,表(10)中的第(1)-(3)列报告了以企业营业收入为划分标准的回归结果,第(4)-(6)列报告了以企业总资产为划分标准的回归结果。从回归结果可知,两种企业规模划分标准下,大数据综合试验区的建立均显著增加了试点城市小规模企业的劳动收入份额,但并未在试点城市大规模企业与中等规模企业中产生显著的影响。一个可能的原因是,对于规模大的企业而言,大数据既能产生较大的新任务创造效应,又能产生较大的自动化扩张效应,这不利于劳动收入份额的提升。然而,对于规模小的企业而言,大数据带来的企业发展更倾向于使得其扩展业务,这会产生新任务创造效应与自动化加深效应,进而提升劳动收入份额。
(三)大数据与劳动收入内部分配
由于社会大多数群体都是企业雇员,且收入主要是工资,企业工资分配对整体社会收入分配格局具有重要影响(Gartenberg and Wulf,2020)。前文已经回答了大数据对企业劳动收入份额的影响,那么大数据在企业工资分配中的具体效应又是如何呢?为了回答该问题,本文进一步地从企业间和企业内部的工资收入差距实证检验大数据对劳动收入内部分配的影响。首先,为了考察大数据对企业间工资收入差距的影响,本文以样本内各年份企业人均工资的1/3 分位数以及2/3 分位数为临界点,分别将样本划分为高工资企业、中等工资企业与低工资企业三组后进行回归,表(11)中的第(1)-(3)列分别报告了三组回归结果。回归结果显示,大数据综合试验区的建立仅显著降低了试点城市高工资企业的劳动收入份额,而对试点城市中等工资企业与低工资企业的劳动收入份额影响不显著。该结果表明,大数据能够通过降低高工资企业的人均工资收入改善公司间的工资收入差距。其次,为了考察大数据对企业内部工资收入差距的影响,本文借鉴张克中等(2021)的做法,使用企业管理层与普通员工工资二者的比值衡量企业内部公司收入情况,表(11)中的第(4)列报告了回归结果。回归结果显示,大数据不会对企业内部工资差距产生显著的影响。
八、研究结论与政策启示
提高劳动收入份额关系着国内大循环新发展格局的形成以及共同富裕目标的实现。本文立足于数据已经成为中国经济发展最重要的生产要素之一这一基本事实,以大数据作为研究切入,在理论分析的基础上,基于2011—2020 年中国A 股上市公司数据,利用国家级大数据综合试验区建立这一外生事件,采用多期双重差分方法系统探讨了大数据如何影响劳动收入份额。实证结果表明,大数据能够显著提升企业劳动收入份额,且在经过平行趋势检验、安慰剂检验等一系列稳健性检验后,该结论依然成立。机制分析发现,大数据可以通过直接效应和间接效应影响企业劳动收入份额。其中,直接效应表现为新任务创造和自动化扩张效应,间接效应表现为自动化加深和融资约束缓解效应。进一步分析显示,大数据的劳动收入份额提升效应仅存在位于东部地区和高市场化水平地区的企业、资本密集型企业、非国有企业以及小规模企业。此外,大数据主要通过缓解企业间的工资收入差距,而非企业内部的工资收入差距来改善劳动收入内部分配结构。
基于上述研究结论,本文得到如下政策启示:
第一,坚定数字经济发展方向,充分发挥大数据在要素分配中的作用。本文研究结论表明,大数据切实提高了企业劳动收入份额,并且能够通过缓解企业间的工资收入差距来改善劳动收入内部分配结构,这对于加快国内大循环新发展格局的形成以及促进共同富裕目标的实现至关重要。因此,以大数据为支点撬动生产方式和治理方式的变革势在必行,政府应当加大大数据产业投资,推动产生数字化,并为企业提供充足的数字化转型动能。
第二,努力提升人力资本水平,积极适应大数据发展带来的技术红利。通过本文研究可知,大数据通过自动化扩张效应产生的劳动收入份额降低能够被新任务创造与自动化加深效应有效缓解。高质量的人力资本不仅能够补充新任务创造产生的中高技能岗位,而且可以进一步促进自动化加深效应的实现。因此,政府应当顺应时代需求,积极推行教育改革以适应数字时代下新的人力资本需求,从而充分利用大数据发展带来的技术红利,提高劳动收入份额。
第三,推进大数据发展需要“因地制宜”,不能一刀切。本文的研究表明,在市场化水平不强的地区,企业可能因为无法有效利用市场促进大数据发挥其新任务创造和自动化加深效应;国有企业因其竞争压力不大、公司治理水平不足等导致其无法充分发挥大数据的价值。因此,考虑到大数据在不同环境与不同企业中的劳动收入份额提升效应存在差异,在实施相应政策时,政府应当统筹兼顾,稳步推进。比如,对市场化水平不高的地区,由于无法有效发挥市场在促进效率中的作用,政府应当给予更多的市场支持政策。
