基于用户画像的高校图书馆可视化系统的构建与实现
2023-12-01崔乐乐
崔乐乐
(昆明医科大学图书馆,云南 昆明 650500)
1 高校图书馆用户画像研究概述
用户画像的概念最早是由交互设计之父A la n Cooper在1998年提出的,是建立在现实生活中一系列真实数据上的用户目标模型,是对真实用户的虚拟化[1]。在国外,用户画像已经成为广告、市场营销和数据分析等领域的重要工具。例如,Facebook和Google等科技公司在个性化推荐、广告投放和用户体验方面都充分利用了用户画像。此外,欧美一些图书馆也开始使用用户画像来提升服务质量[2]。在国内,随着大数据和人工智能技术的快速发展,用户画像也逐渐被应用于多个领域,在图书馆领域,用户画像也成为提高管理效率和服务水平的一种重要手段[3]。
目前,图书馆领域的用户画像主要围绕建立用户画像模型等展开研究,如何利用用户画像为读者提供个性化服务模式是当前图书馆管理与服务重点关注的领域[4],而其中以构建多维度、多层次、立体化的用户画像模型,实施图书的个性化推荐、个性化信息检索、个性化借阅、个性化参考咨询等个性化服务[5]成为提高图书馆服务效能的重要手段之一。随着信息化、数字化和智能化的发展,基于大数据的用户画像模型及相关技术也在更新迭代中,基于此,本文以高校多维度用户数据类型为依托,构建适应高校图书馆的用户画像模型,进而构建多样化的高校图书馆可视化系统,图书馆可视化系统对用户查询意图、兴趣等进行推理和预测,为用户及相关部门提供有效的调查结果,同时馆员根据可视化系统对读者服务及系统建设提供决策依据。
2 用户画像模型的构建流程
高校图书馆的用户画像模型构建流程是:首先收集高校图书馆用户的各类信息数据进行预处理,去掉脏数据,使用户的属性数据和行为数据相关联,然后对关联后的用户数据进行深入挖掘和分析后建立用户标签,初步建立用户画像模型,细分用户形成个人用户画像和群体用户画像。
2.1 用户画像数据的采集与处理
图书馆用户数据的获取从自然属性、用户偏好属性、交互行为属性和社交行为属性四个维度着手,一般可从图书馆后台管理系统、闸机打卡系统或图书馆搜索引擎中获取。其中,图书馆后台管理系统中保存了用户入学注册时的身份信息、注册信息和登录信息等,这些用户的自然属性数据和交互行为数据均可通过系统数据库直接导出。用户偏好数据一般从图书馆检索借阅系统和互联网搜索引擎中获取。用户在线浏览、在线评论、留言等交互信息可以运用网络爬虫技术从用户经常使用的操作页面爬取、识别。
采集完用户数据后,在充分保障用户数据隐私的前提下,首先对用户基本信息、借阅行为数据、图书标签数据、检索数据、交互行为数据等进行清洗,过滤去除与用户特征不相关的数据,然后利用数据挖掘算法对用户数据进行深入挖掘和分析,形成真实可用的图书馆用户画像数据集。高校图书馆用户画像数据的构成如图1所示。
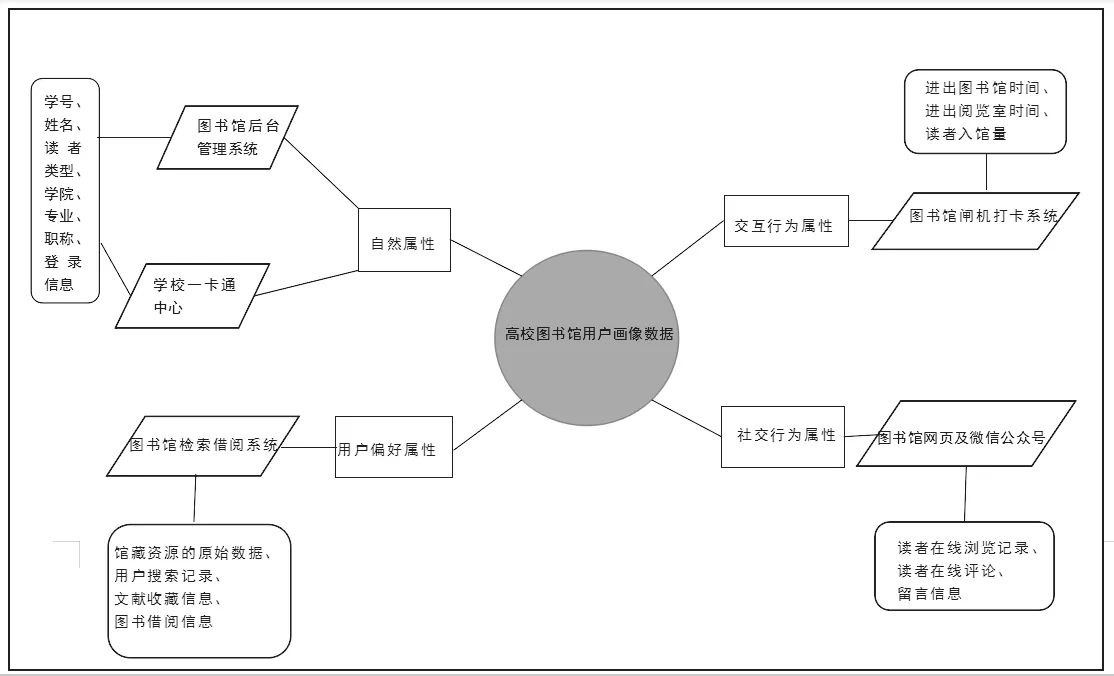
图1 高校图书馆用户画像数据构成
2.2 建立用户画像数据标签体系
构建准确的用户画像需要将用户数据标签化、向量化,为后续数据挖掘和数据分析提供可计算的数值信息[6]。针对图书馆数据,如偏好图书类别——哲学、文学、工业技术、社会科学等可形成描述用户兴趣爱好的标签。标签体系的建立需要结合真实业务场景下的用户需求,有目的性地提炼出能够代表用户特征的标签,建立有需求偏向的标签体系。针对图书馆数据的标签提取,本文从收集高校图书馆用户群体自然属性数据、内容偏好数据、交互行为数据和社交行为数据四个维度的具体信息来构建用户画像的标签体系。
2.3 构建用户画像模型
高校图书馆用户画像模型是一个描述读者特征和行为的模型,由数据来源层、数据分析处理层以及数据标签层3个层次构建而成。具体构建过程如图2所示。
在构建用户画像模型时,需要注意以下几个方面。
(1)数据质量:确保收集到的数据完整、准确、可靠,避免噪声和异常值对模型训练产生不利影响。
(2)标签体系:建立起合理、完备、可扩展的标签体系,以便对读者特征和行为进行描述和识别。
(3)模型选择:根据具体需求选择合适的模型,避免过拟合或欠拟合等问题对模型应用产生不利影响。
(4)模型评估:对建立的模型进行准确性、鲁棒性、稳定性等方面的评估和测试,以验证其适用性和有效性。
3 基于用户画像的可视化系统的实现
用户画像模型建立后,我们通过设计通用技术框架构建可视化系统。该系统框架由用户交互界面、服务接口层interfaceServer和数据适配器3个部分组成。
用户交互界面通过可视化编程组件实现,内置多种可视化组件,如折线图、柱状图、饼状图、气泡图、词云等,并提供任务管理、可视化设计与UI编排、数据加载、可视化预览和发布功能。
接口服务层interfaceServer通过从后台获得的数据为为前端提供restful接口。
数据适配器运用dataAdapter适配器和数据库进行交互,并缓存、汇总数据然后通过interfaceServer提供给用户交互界面使用。本文以高校图书馆应用的读者兴趣画像、读者阅读报告、院系阅读报告为例,具体实现内容如下。
(1)读者兴趣画像。读者兴趣画像包含读者的基本信息、进馆信息、借阅下载信息、使用学科、数据库分析、热点主题等内容,通过这6个方面形成的用户画像能够对读者的使用进行进行分析统计。界面实现如图3所示。

图3 用户兴趣画像界面
(2)读者阅读报告。读者阅读报告的展示以HTML5动画展示,个人阅读报告主要有借阅量、进馆次数、进馆时间、访问图书馆门口网站、检索下载文献量等统计信息,其界面展示如图4所示。

图4 读者阅读报告界面
(3)院系阅读报告。院系阅读报告主要包括学院读者入馆趋势、入馆读者类型、读者借阅情况、热门借阅TOP10统计、资源下载情况、热门检索关键词等内容,旨在提高“学院-图书馆”互动频率,提升二级学院对图书馆的满意度。在此基础上通过与各个二级学院交流工作,可发掘出更多有价值的数据和分析点,为图书馆读者服务水平提升提供一定的数据支撑。其画面展示如图5所示。

图5 院系阅读报告
4 结束语
本文面向高校图书馆,以图书馆用户画像的可视化构建与表达为研究重点,详细探讨了高校图书馆用户画像可视化系统的数据体系、系统框架、构建流程与技术实现,最后形成了一套高校图书馆的可视化系统,该系统以多种形式的用户兴趣画像及图书馆阅读报告的形式呈现,为读者提供满足其个性化需求的精准推荐服务,对智慧化的图书馆借阅服务及管理具有重要的参考及应用意义。■
