机器学习模型输入指标选择方法研究
——以上市公司财报舞弊判别为例
2023-12-01刘佳进博士
刘佳进(博士)
(福州大学计划财务处 福建福州 350116)
上市公司信息披露准确与否将对财报使用者的决策产生较大的影响。近年来,上市公司的舞弊手段越发多样化和隐蔽化,且更加具有针对性,仅依靠传统分析手段较难发现舞弊行为。机器学习模型不同于传统分析手段,其通过输入特定的样本数据进行训练和拟合并进行预测分析的方法,能发现传统分析手段难以识别出的问题,目前已经有越来越多的研究开始关注这一领域。机器学习模型的应用较为简单,只需输入特定的财务报告指标,根据模型输出结果即可快速判别上市公司是否存在财务舞弊,其财务报告数据是否可以信赖,这对于财务报告使用者决策将大有助益。
机器学习模型本身不依赖数据背景,仅仅是通过分析数据之间的内在逻辑进行训练和拟合,因此,要想提升判别的效果,一是训练集样本的分类需要足够准确,二是输入指标反映的信息要尽可能全面,信息缺失将影响机器学习模型的训练效果。
一、现有研究选取输入指标的特点和存在的不足
现有相关研究聚焦于机器学习模型的应用,尝试利用不同的机器学习模型判别上市公司是否存在舞弊行为,并利用测试集验证判别的效果。在模型选择方面,相关研究主要选取支持向量机、神经网络和随机森林模型等作为判别模型,在输入指标的选取方面,不同研究之间差异较大,具体有如下特点:
(一)依据经典舞弊模型选取指标
部分研究在选择输入指标时,会参考经典的舞弊模型,如冰山理论、舞弊三角论、GONE 理论等,根据舞弊产生的动因对应的指标作为输入指标进行机器学习模型的训练和分析。根据现有研究结论,这种输入指标的选取方法确实可以取得较为满意的实证结果,但带有主观的色彩,同时,这种研究方法更倾向于验证现有的舞弊而非发现潜在的舞弊,实际上是利用现代的方法验证传统的理论。若有舞弊行为的上市公司意识到经典舞弊模型的相关指标可能会被重点关注,就会通过技术手段粉饰这些关键指标,如果仍依据经典舞弊模型选取指标,则训练形成的模型就可能会在识别舞弊上误判。
(二)依据主观判断选择输入指标
除了上述依据经典舞弊模型选择指标的方式外,也有一部分研究在选择输入指标时并没有明显的模型依据,仅根据研究者个人的判断选取输入指标,这将导致此类研究选择输入指标缺乏统一的标准,使得不同研究之间选择的指标差异较大,甚至存在不同研究采用完全不同的两套输入指标体系的情况。此类研究之间唯一可以比较的结果就是判别准确率,但该准确率受到模型参数、输入指标和输入样本等各方面的影响,很难比较不同的输入指标对舞弊判别结果的影响程度。
(三)聚焦于静态指标
现有的研究选取指标会倾向于选择静态的指标,对于不同年度之间变动率的指标选择较少。上市公司的舞弊行为,一般会影响超过一年的财务数据,反映到财务报告数据中,就是进行财务舞弊前以及舞弊后的年份,上市公司特定的指标值会出现异常的反弹,因此,变动率的指标就显得尤为重要,也应当加入输入指标体系的构建中。
综上所述,现有的研究在选择输入指标方面缺乏统一的标准,选择方式也较为主观,使得不同研究之间输入指标差异较大,导致许多财务信息并未进入到机器学习模型中进行训练,输入信息的缺失可能会影响机器学习模型判别的效果。
二、改进输入指标选取的思路
根据现有研究选取输入指标存在的问题,结合机器学习模型有别于传统的财务分析模型,本文改进了输入指标的选择方法。
(一)输入指标要尽可能覆盖可取得的各类财务信息
为确保能够充分利用现有的各类财务信息,机器学习模型需要大量的输入指标,在选取的过程中,应当避免人为因素干扰导致财务信息的缺失。因此,初始的输入指标体系应该尽可能涵盖所有可获取的有用的信息。
(二)指标选择应当最大化正负样本的特征差异
上市公司财务舞弊判别的本质就是一个“是否”“有无”二分类的问题。因此,在机器学习模型的训练过程中,如能将正负样本的特征差异最大的几个指标筛选出来,则能有效提升判别的效率。因此在选择输入指标的过程中,要尽可能选取正负样本差异较大的指标,以提升舞弊判别的效率。
(三)利用实证模型对指标进行筛选
在选择上述正负样本差异较大的指标时,应当采用经典舞弊模型的因子、因素进行筛选,而非主观判断选择,这样能够避免人为干预造成的信息遗漏。另外,还应当比较初始输入指标和筛选后的输入指标在构建机器学习模型中的判别效果,以确认筛选指标的有效性。
综上所述,要想提升机器学习模型舞弊判别的效果,需要尽可能多的指标组成初始指标集,并筛选出正负样本差异较大的指标输入并进行训练,比较初始输入指标和筛选后的指标训练的模型在测试集中的判别效果。而利用Logistics 回归分析模型,可以从大量的指标中筛选出较为显著的指标,因此,本文将使用初始输入指标体系和利用Logistics 回归分析模型筛选后的敏感指标体系,分别使用机器学习模型训练和验证判别效果。
三、模型构建
(一)样本选取
确定上市公司财务报表是否存在虚假披露行为,可以依赖的判断标准有两个,一是年度报告的审计意见,二是监管机构的处罚记录。若上市公司财务报告被会计师事务所出具了非标准审计意见,且该审计意见的内容和公司当年披露盈利相关,则可以认为上市公司发生了财务舞弊行为;若监管机构对上市公司某一年的财报定性为虚假披露,那么即使当年该上市公司的财务报告审计意见为无保留意见,同样可以认为该上市公司在当年发生了舞弊行为。
根据上述思路,本文按照如下方法选择舞弊样本:选择2008—2021年度会计师事务所出具非标准审计意见,该审计意见的内容和公司当年披露盈利相关的沪深A股上市公司,以及2008—2021 年度会计师事务所出具无保留意见,后续监管机构对该公司的违规行为提出处罚,处罚的违规期间属于2008—2021年,且该违规行为涉及当年披露盈利的沪深A股上市公司作为“舞弊组”,取得处罚记录的截止日期为2022年10月31日。
在选取舞弊公司样本时,同时选取与舞弊公司同行业①行业分类依据IFind同花顺行业分类,取最明细类、资产规模相近、年度报表审计意见为无保留意见且后续年度未被监管机构处罚的沪深A 股企业作为正常公司,通过舞弊公司与正常公司1∶1 进行配对,以减少行业及规模因素造成的数据特征差异。
若舞弊样本在不同年份连续发生同类型的舞弊行为,只取发生舞弊行为的首年作为研究样本,以消除重复舞弊造成的研究差异;如在同年或者不同年份发生了超过一类的舞弊行为,则视同为不同的舞弊样本。由于金融类公司财务报告格式与其他类公司不同,本文剔除所有的金融类上市公司,因同一家公司在同年度发生不止一种舞弊行为视同为不同的样本,本文选取了461家舞弊公司,共531个舞弊样本。舞弊样本所属行业分布如表1所示。

表1 舞弊公司样本行业分类
由此可见,舞弊公司样本分布是以制造业为主的各类行业。将各个样本根据舞弊手段及发生舞弊的年份分类如表2所示。

表2 样本舞弊手段汇总
以上为样本舞弊公司的数量,研究过程中依据上述要求共选取了531 个样本,其中舞弊类型为关联方交易的样本130 个、隐瞒大额事项的样本76 个、虚构交易的样本172 个、准备计提的样本153 个。对照公司的样本数量与舞弊公司1∶1配对,数量相同。
(二)确定初始输入指标
输入指标很大程度决定了所提取的数据走向,如前述分析,若输入指标不足,一些特征信息被遗漏,可能对研究结果造成较大的影响。本文结合现有文献常用的分析指标,结合同花顺数据库中评价上市公司偿债能力、营运能力、盈利能力、成长能力以及财务报告常见的各类财务指标,剔除重复的、不易获得的指标,最终确定了91 个指标作为初始输入指标(见表3),以减少人为选择因素造成的指标缺失,影响模型的初始输入指标分布于各类财务报表,并涵盖了各类的财务信息。
其中“是否法人股东”和“是否变更事务所”这两个指标为哑变量(虚拟变量),公司第一大股东为法人的取1,公司股东为自然人的取0,在舞弊公司发生舞弊行为的当年,变更过会计师事务所的取1,否则取0,正常公司是否变更事务所的年度取与其配对的舞弊公司的舞弊年度,首次上市视同为不变更,因会计师事务所合并等客观原因造成的事务所变更也视同为不变更。含有Δ 标记的指标为舞弊当年对上一年的指标变动率。
(三)筛选敏感指标
根据舞弊种类的不同,将数据分四类输入Logistic 回归分析模型,在因变量的选取中,舞弊公司结果选择1,正常公司结果选择0,选择前向步进方法,筛选出如下指标:
1.关联方交易舞弊敏感指标。从下页表4 可以看出,经过筛选,对于关联方交易舞弊公司,其与正常公司的敏感指标集为S1,有息税折旧摊销前利润/负债合计、已获利息倍数、净资产收益率ROE(扣除/加权)、应收账款周转天数、经营活动产生的现金流量(亿元)等5 个指标。可以看出,关联方交易会引起应收账款数量的变动,因此应收账款的相应指标也可能指向关联方交易舞弊。
2.隐瞒大额事项舞弊敏感指标。从表5 可以看出,对于隐瞒大额事项舞弊公司,其与正常公司的敏感指标集合为S2,有Δ速动比率、每股留存收益、Δ营业总收入、Δ基本每股收益、现金流量比率、Δ 现金净流量、净资产收益率ROE(加权,公布值)等7个指标。可以看出,如果企业隐瞒大额的事项,其在一些指标的前后年度变动率上的变化将较为明显。
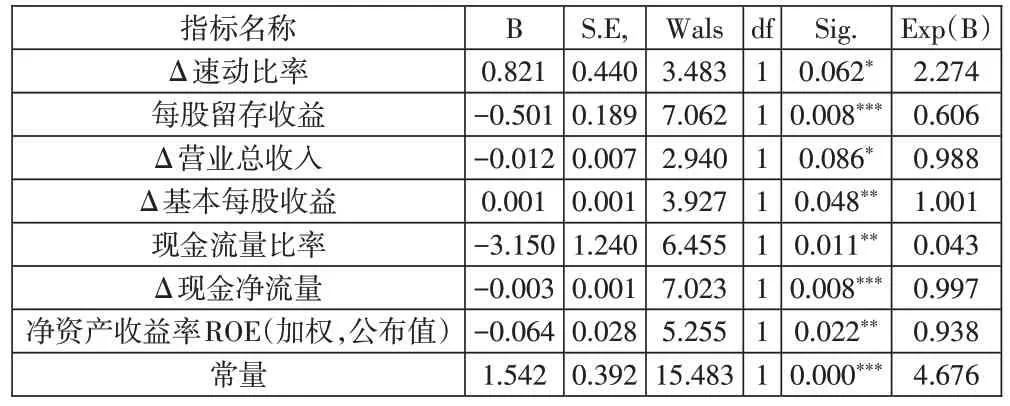
表5 隐瞒大额事项敏感指标
3.虚构交易舞弊敏感指标。对于虚构交易舞弊公司,其与正常公司的敏感指标集合为S3,有每股留存收益、Δ毛利、Δ营业总收入、投入资本回报率ROIC、流动资产周转率5个指标。这些指标说明如果上市公司发生了虚构交易舞弊行为,主要通过盈利能力和成长能力指标表现出来。其中“Δ 毛利”的“B”值(回归系数)为-0.00031,“S.E,”值(标准误差)为0.00016,限于篇幅,表格中保留三位小数,故仅显示为-0.000和0.000。见表6。

表6 虚构交易舞弊敏感指标
4.准备计提舞弊敏感指标。对于采用准备计提手段进行舞弊的公司,其与正常公司的敏感指标集合为S4,有Δ 应收账款周转率、Δ 固定资产营业收入比、存货周转率、Δ利润总额、投入资本回报率ROIC、应收账款周转率6个指标。这说明,准备计提舞弊公司和正常公司在营运能力指标上存在较大的差异。表7中“Δ利润总额”的“B”值(回归系数)为0.00023,“S.E,”值(标准误差)为0.00011,限于篇幅,表格中保留三位小数,显示为0.000。

表7 准备计提舞弊敏感指标
5.总体敏感指标。我们发现,“Δ 应收账款周转率”这一指标在模型中并未在10%的显著性水平上统计显著。考虑到本文采用的是Logistic逐步回归的方式,尽管在准备计提舞弊敏感指标中,“Δ 应收账款周转率”这一指标的显著性不佳,但通过加入该指标能够对Logistic回归分析模型整体的显著性有贡献,因此本文采用了该指标作为准备计提舞弊敏感指标之一。
通过上述实证分析可以发现,四类舞弊的敏感指标不完全相同,但是部分指标存在重合,说明不同的舞弊手段可能造成同样的指标敏感,取S1—S4指标集的并集形成总体敏感指标集合S 进行机器学习模型训练和测试,总体敏感指标集合S共计20个指标,具体包括:息税折旧摊销前利润/负债合计、已获利息倍数、净资产收益率ROE(扣除/加权)、应收账款周转天数、经营活动现金流量(亿元)、Δ速动比率、每股留存收益、Δ营业总收入、Δ基本每股收益、现金流量比率、Δ 现金净流量、净资产收益率ROE(加权,公布值)、Δ毛利、流动资产周转率、Δ应收账款周转率、Δ固定资产周转率、存货周转率、应收账款周转率、投入资本回报率ROIC、Δ利润总额等。
四、实证结果及分析
(一)实证结果
依次选取现有研究常用的机器学习的人工神经网络、支持向量机和随机森林模型,利用2008—2020年A股上市公司选取的926个样本作为训练集分别输入各个模型进行训练,并将2021年的140个样本作为测试集测试各模型的泛化效果。
1.人工神经网络模型判别结果。作为机器学习应用较为广泛的算法,人工神经网络算法在模式识别、回归分析等多个领域中均有较为稳定的表现,而人工神经网络的种类也较多,本文采用学术界应用较为广泛的BP神经网络作为分类判别的模型。使用人工神经网络算法的判别混淆矩阵结果见表8。

表8 人工神经网络判别混淆矩阵
2.支持向量机模型判别结果。构建支持向量机模型中,本文采用RBF 核函数进行模型构建,RBF 核函数有C(惩罚因子)和γ(核参数)两个必备的参数,为保证训练的质量,本文通过网格搜寻和交叉验证的方法,寻找最优的参数。支持向量机模型的判别结果见表9。
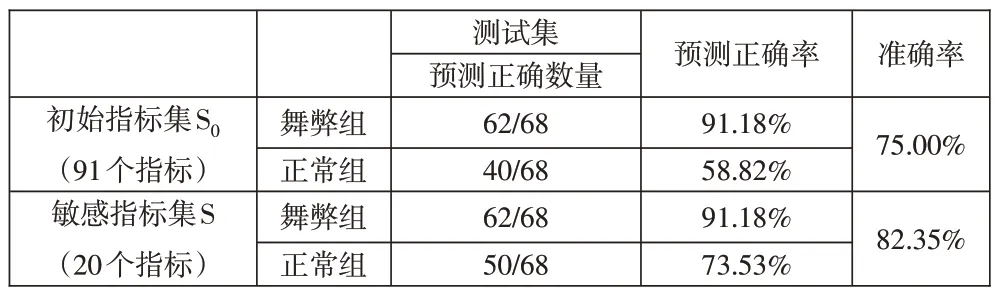
表9 支持向量机判别混淆矩阵
3.随机森林模型判别结果。随机森林模型是以决策树为基础的集成模型,当输入待分类的样本时,通过抽样形成子样本,并将每个子样本通过决策树进行分类,依据每个决策树的判别结果,通过投票法决定最终模型的输出。利用随机森林模型进行上市公司舞弊判别结果见表10。
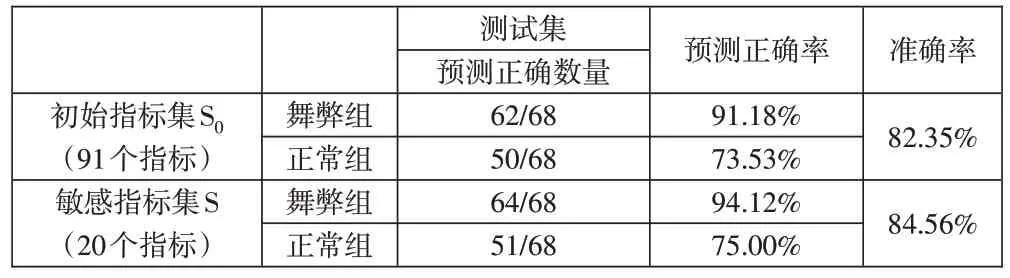
表10 随机森林判别混淆矩阵
(二)结果分析
通过分析上述回归分析以及不同机器学习模型判别表格,可以得出以下结论:
1.Logistics 回归分析模型可以用于敏感指标筛选。通过Logistics 回归分析模型的步进方法筛选后,这些敏感指标大多数都在模型中在10%的水平上统计显著,这说明筛选出的指标在正负样本中差异较大,可以用于模型的训练。
2.通过Logistics 回归分析筛选的指标能够提升机器学习舞弊判别效率。对比上述三种机器学习的效果可知,通过Logistic 回归分析前向步进方法筛选出的敏感指标作为输入指标,在测试集中的判断准确率均有了一定程度的提升,这是因为敏感指标作为输入指标,机器学习模型能够更加容易地区分开“舞弊组”与“正常组”样本,且有一定的泛化能力。
3.随机森林模型在初始指标集就有不错的表现。在初始指标集作为输入指标时,随机森林模型的判别准确率就超过了80%,这说明随机森林模型自身能够较好地利用训练集样本信息,其算法是通过抽样的方式形成决策树并通过投票法组合多棵决策树的预测结果来形成最终结果,该方法本身就是现有信息的筛选,因此利用初始输入指标训练判别效果也比较好。
五、结论
本文的结论与贡献主要有:第一,克服了现有相关研究中模型输入指标选取较为随意的问题,选择了尽可能多的、涵盖范围广的财务报告指标作为初始输入指标体系,充分利用了上市公司披露的财务信息;第二,构建了初始输入指标后,根据舞弊手段的不同,通过Logistics回归分析筛选出最大化舞弊组和正常组上市公司的相关指标形成敏感指标集,并实证检验了敏感指标集的筛选有助于提升机器学习模型的舞弊判别效率;第三,比较了常见机器学习模型应用于上市公司财报舞弊判别的效果,在实际应用于未知样本的舞弊判别时,可以综合几个模型的识别结果,若某个上市公司的样本数据在这几个判别模型中得到一致的结果(如都被模型判别为是舞弊公司或都是正常公司),则无疑更能说明其是否存在舞弊行为。
