基于知识图谱的问答系统设计
2023-11-30秦丽娟

基金项目:2019年度江苏省高校哲学社会科学研究专题项目;项目编号:2019SJB154。
作者简介:秦丽娟(1983— ),女,江苏南京人,讲师,硕士;研究方向:教育信息化。
摘要:随着网络数据的爆发式增长,知识泛滥和知识过载问题日益凸显。传统的问答系统通常采用简单的关键词匹配模式,往往无法准确理解用户的真实意图,难以提供准确的答案。为解决这一问题,文章设计了一种基于知识图谱的智能问答系统。首先,通过本体层构建、数据爬取、数据存储等步骤构建知识图谱。其次,分别采用BERT+BiLSTM+CR模型和BERT+TextCNN模型进行命名实体识别和用户意图识别。最后,使用Flask封装后台API,以便提供更加灵活和个性化的服务。
关键词:知识图谱;问答系统;用户意图
中图分类号:TP391.3 文献标志码:A
0 引言
Web3.0时代充斥着巨量信息,导致知识泛滥和知识过载等问题[1]。传统的问答系统通常采取简单的关键词匹配模式,然后罗列一大堆数据供用户查看,用户往往很难辨别这些数据的准确性[2]。近年来,知识图谱的理论研究取得了迅猛的发展,特别是在知识图谱中的信息抽取环节方面,为构建问答系统的初期特征抽取任务提供了极大的帮助[3]。这种方法不仅显著减少了人工干预的需求,还提高了问答系统的准确率和效率。OpenAI的ChatGPT引起了人工智能界的广泛关注,给问答系统和搜索引擎帶来了一种全新的形态,即基于深度学习的形态。与传统方法相比,这些方法通过深度学习技术来提高问答系统的准确性、召回率和效率,并能从复杂的知识结构中高度概括和挖掘所需信息,使得问答平台能更有效地获取知识,为各个领域的发展提供服务。本文旨在探讨如何利用Web3.0时代丰富的数据资源和现代人工智能技术,构建一种基于知识图谱的智能问答系统模型。
1 相关技术
1.1 BERT模型
BERT(Bidirectional Encoder Representations from Transformers)模型是由Google于2018年提出的。它的主要目的是利用大量的未标注数据来学习一种通用的语言表示方法。与其他的基于深度学习的自然语言处理技术相比,BERT具有许多优点。首先,它可以适应各种类型的任务,因为它的训练方法可以学习到语言的各种特征,从而在不同的应用场景中都可以得到良好的效果。其次,BERT也易于微调,这使得它在面对特定任务时可以快速适应并进行优化。此外,BERT可以充分利用大规模的未标注数据,让模型学习到更多的语言特征,并在后续的微调过程中更好地适应任务。因此,BERT在自然语言处理领域受到了广泛的关注,被认为是最强的预训练语言模型之一。
1.2 DBNet网络
DBNet在图像分割任务中具有较高的准确性和鲁棒性,被广泛应用于计算机视觉领域。系统使用DBNet网络进行文本检测任务。DBNet网络结构主要由3个模块构成,分别是FPN、FCN和DB操作。FPN结构为了获取多尺度的特征,分为自底向上的卷积操作与自顶向下的上采样。首先,根据卷积公式获取原图大小比例的1/2、1/4、1/8、1/16、1/32的特征图;其次,自顶向下采样2次,之后同样进行自底向上的操作;最后,对每层输出结果进行采样,变成1/4大小的特征图。FCN模块是将特征图经过卷积核转置卷积获取概率图P和阈值图T、Z最后对2张图进行DB(可微二值化)方法得到二值图。
1.3 长短时记忆网络
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络,由Hochreiter等人提出。它将记忆单元添加到隐藏层的神经单元中,由此来控制时间序列中的记忆信息。LSTM是循环神经网络(Recurrent Neural Networks,RNN)的一个变种。RNN的内部状态可以表现动态时序行为,也称为记忆信息。与RNN不同,LSTM改变了RNN的记忆单元,使其包括了一个“处理器”cell,它可以决定要保留哪些信息。一个cell由输入门、遗忘门和输出门组成。信息在进入LSTM网络后,cell会根据规则判断该信息是否有用,只有符合算法要求的信息才会被保留,而不符合要求的信息将通过遗忘门被丢弃。
2 总体设计方案
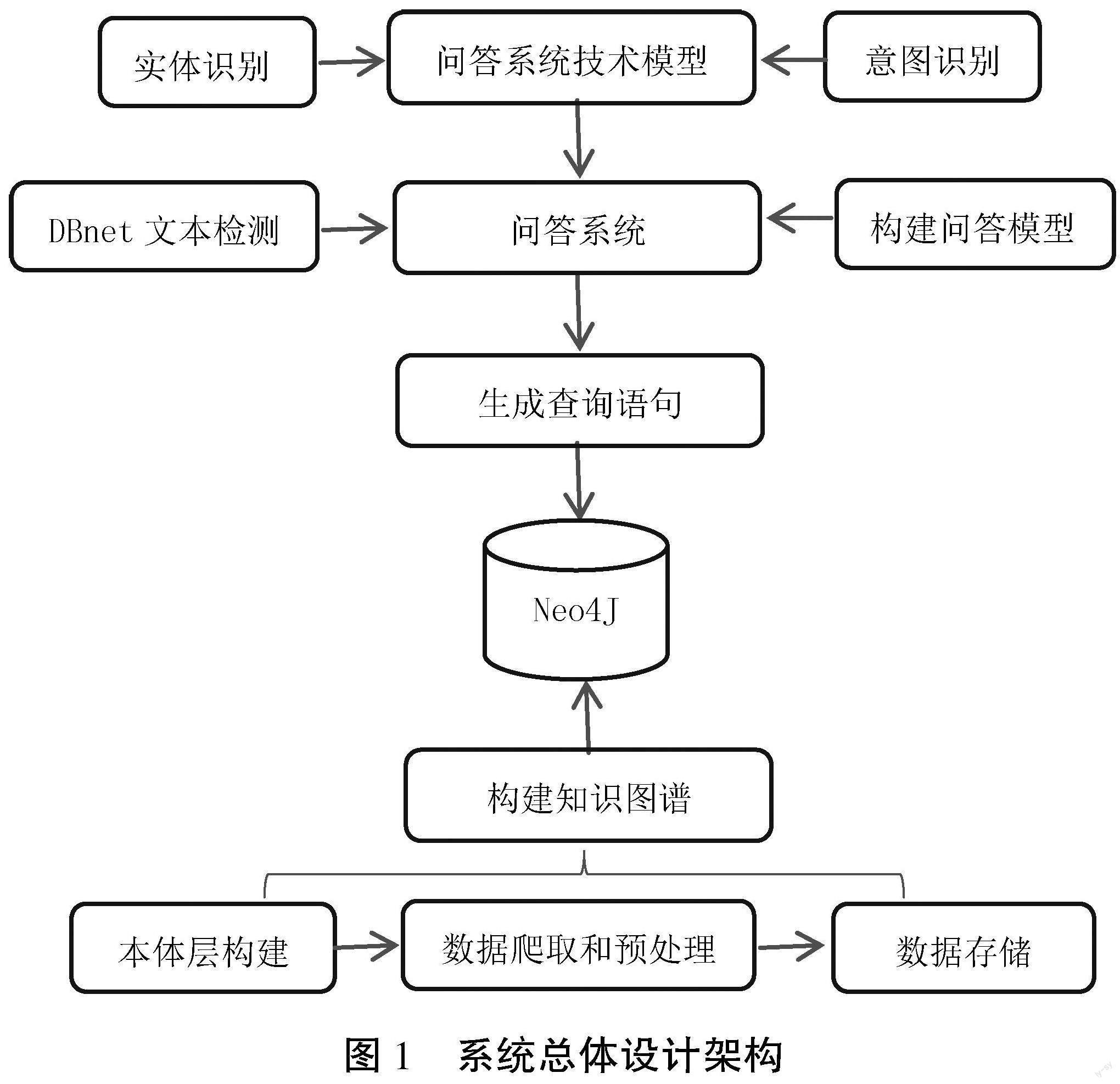
系统主要分为3个主要任务,即知识图谱的构建工作、问答系统相关技术模型的设计以及问答系统的设计,具体如图1所示。
问答系统相关技术模型的设计训练主要分为命名实体识别和用户提问意图识别。问答系统整体使用Flask封装后台API,用户的需求为输入,然后判断为文本还是图片,如果是图片则使用DBnet识别图片内容,如果是文本则通过NLP的BERT+BiLSTM+CRF构建提问实体,之后用CNN进行分类来识别意图,最后构建查询语句,将数据返回给用户。
3 知识图谱的构建
3.1 基本流程
知识图谱的构建相关流程,如图2所示。首先,通过爬虫行采集结构化或半结构化数据;其次,通过中间数据库进行存储;再次,进行知识抽取,将数据转为知识图谱的结构化数据;最后,存储进Node4J数据库。
3.2 本体层构建
在知识图谱中,本体层是一种用于描述实体、属性、概念以及它们之间关系的结构化资源模型。本体层可以看做是整个知识图谱中最核心的一层,通过对相关实体和概念的分类、定义和关联规范,能够为下层数据集成提供更加明确的语义表示和分层约束。在已经建立好本体层之后,只要将需要被存储/表达的实体映射到本体层上,就可以很方便地继承/获取其相关属性信息或者推理出新的事实或知识。将知识隐式编码到本体层的方式,可以使得知识图谱更加具有可理解性、自解释性和可维护性,并且便于进行知识推理、查询和分析。
3.3 数据爬取和预处理
系统主要通过request、Selenium和XPath相结合来爬取网站。具体爬取过程为:首先,进入网站找到相应数据对应的URL地址,分析URL地址之间跳转的关系;其次,在网站中定位所需要的元素;最后,编写爬虫代码依次爬取每个URL的数据。网页中存在着部分缺失值,需要对提取到的数据进行清洗和预处理,去除无用的标签、特殊字符或者HTML实体,使数据更加规范和易于处理。
3.4 數据存储
数据预先只存储在本地磁盘中,不易于系统后台进行查询工作,需要将其导入数据库,知识图谱主要具有实体、关系、属性3个主要元素,而图数据库的点、边、点的相应值正好与其一一对应。图数据库具有天然的优势存储知识图谱,且其和结构化数据库一样提供了类SQL的查询语言,因此将数据存储进图数据库。Noe4J是一个开源的数据库,易于使用,所以选择其作为后台知识库。
4 问答系统相关技术模型设计
4.1 基于BERT-BiLSTM-CRF模型的命名实体识别
实体抽取即从非结构化文本中识别出实体信息,最早期采取字典和规则的方法,但过分依赖专家人工,费时费力,难以适应数据改变,后来被最大熵模型,支持向量机,条件随机场的机器学习方法所替代。近年来,深度学习也不断走入NLP的视野,CNN、RNN都开始被用于实体识别。基于RNN在解决长距离依赖问题的过程中出现的梯度消失和梯度爆炸,专家们引入了门控机制,创造了LSTM的新模型来解决长期依赖问题,由此也衍生出了BiLSTM来解决双向的语义依赖问题。系统使用BERT-BiLSTM-CRF模型,该模型是一种结合了BERT、BiLSTM和CRF的序列标注模型,用于解决命名实体识别(NER)任务。该模型的核心思想是利用BERT模型的语义表示能力、BiLSTM模型的上下文信息捕捉能力和CRF模型的标签约束能力,从而提升NER任务的性能。
首先,系统选择使用BERT动态语言模型作为词嵌入层。BERT模型包含多层双向Transformer语言模型,并大量使用Attention机制,在编码过程中考虑每个词的上下文信息。与CNN和RNN不同,BERT模型只包含前馈神经网络和自注意力机制,通过Transformer网络的Encoder部分解决了RNN长距离依赖问题。BERT的输入向量包括3部分:词分隔、句子分隔和位置分隔。
其次,经过BERT词嵌入层后,这些向量将会进入特征提取层,去除掉那些无关紧要的特征,获取能够典型代表这一向量的特征,同时也减少了向量的维度,方便后续的处理。系统采用BiLSTM作为特征层。LSTM根据前文描述,解决了RNN可能出现的梯度消失、梯度爆炸等问题,且由于中文文本前后文的关系性,系统使用两层LSTM进行双向提取,最后将结果连接到CRF标注层。
最后,特征提取完成后,需要获取每一个字符的BIO标注。前文讲述的CRF是一种基于概率图模型的序列标注方法,且CRF利用了输出的全局概率分布来建模,同时将原本单独考虑的每个标注之间的相互作用融合在一起,具有极强的建模能力,所以选择CRF作为特征分类层。CRF将会最终输出类似B-DIEASE、I-DIEASE、O等标注类型,用于后续直接读取获得识别出来的实体。
4.2 基于BERT+TextCNN模型的用户意图识别
识别出实体后,还需要判断用户对于实体需要具体哪一属性或者关系的识别。由于定义了本体层,意图识别可以转化为机器学习的分类和NLP方向的情感识别问题,KNN、SVM、朴素贝叶斯是最常见的机器学习方法。随着技术的发展出现了TextCNN、RNN等模型处理此类任务。BERT作为预处理语言模型,在NLP领域受到广泛的关注,相较于LSTM,Transformer可以更好地处理长距离依赖,并且其本身就是基于注意力机制,因此系统采用BERT+CNN进行意图抽取的任务。BERT+TextCNN模型从特征提取层、特征分类层和数据增强层面综合应用了BERT和TextCNN的特点,能够充分利用语义表示和卷积神经网络特征提取的优势,同时通过数据增强来提升模型的鲁棒性和泛化能力。
首先,利用BERT模型作为特征提取器,学习文本的语义表示。BERT模型通过无监督预训练,在大规模语料上学习到了丰富的上下文相关的词向量表示,能够捕捉词语和句子之间的语义关系。这些语义表示作为输入,提供了丰富的语义信息,用于后续的特征提取和分类。
其次,利用TextCNN模型进行特征提取和分类。TextCNN模型通过卷积和池化操作提取文本的局部和整体特征。卷积操作利用不同尺寸的滤波器对文本进行卷积,捕捉不同长度的局部特征。池化操作则提取出每个特征维度上的最重要特征。这样TextCNN模型能够有效地提取文本的特征,将其输入到分类器中进行分类。
最后,采用各种数据增强技术来提升模型的鲁棒性和泛化能力。例如,可以使用数据增强方法如随机替换、随机插入、随机删除等,对输入文本进行扰动,生成新的训练样本。这样可以增加模型对不同变体的文本的适应能力,提升模型的泛化能力。
5 系统架构
系统参考MVC架构分为3个部分:前端显示层、逻辑处理层和数据访问层。前端显示层向最终用户提供易于使用的界面,使用了BootStrap和Jquery框架来简化前端界面的开发。逻辑处理层主要响应前台发送的异步请求,然后返回相应的数据供前端显示给终端用户。其主要工作是调用模型获取模型的结果,再进入数据访问层获取数据。Flask可以更容易地实现一个轻量、灵活、易扩展的 Web 应用,并且能够快速进行迭代和部署,所以系统选择Flask将后台封装。数据访问层通过第三方的PYNEO包来对Neo4J数据库进行访问,其使用方式与JDBC类似,用户只需要编写数据库连接的参数和相应的CQL语句即可完成查询。
6 结语
笔者通过介绍知识图谱和问答系统的设计和实现过程,展示了如何利用现代技术手段构建高效的知识管理和问答系统。通过这些技术手段,可以更好地管理和利用知识资源,提高用户获取信息的效率和准确性。在未来的工作中,笔者将进一步优化和改进该系统,如增强知识图谱的構建效率和准确性,提高问答系统的智能水平和服务质量。此外,笔者还将探索更多的应用场景,如智能客服、智能推荐等,以更好地发挥新技术的实际价值。
参考文献
[1]杜睿山,张轶楠,田枫,等.基于知识图谱的智能问答系统研究[J].计算机技术与发展,2021(11):189-194.
[2]王天彬,黄瑞阳,张建朋,等.融合机器阅读理解的知识图谱问答系统设计与实现[J].信息工程大学学报,2021(6):709-715.
[3]赵浩宇,陈登建,曾桢,等.基于知识图谱的中国近代史知识问答系统构建研究[J].数字图书馆论坛,2022(6):31-38.
[4]卢经纬,郭超,戴星原,等.问答ChatGPT之后:超大预训练模型的机遇和挑战[J].自动化学报,2023(4):705-717.
(编辑 姚 鑫)
Design of knowledge graph based Q&A system design
Qin Lijuan
(Jiangsu Second Normal University, Nanjing 210013, China)
Abstract: With the explosive growth of online data, the problem of knowledge flooding and knowledge overload is increasingly prominent. Traditional Q&A systems usually use a simple keyword matching model, which often fails to accurately understand the real intention of users and makes it difficult to provide accurate answers. To solve this problem, the article designs an intelligent Q&A system based on knowledge graphs. Firstly, the knowledge graph is constructed through the steps of ontology layer construction, data crawling and data storage. Secondly, BERT+BiLSTM+CR model and BERT+TextCNN model are used for named entity recognition and user intention recognition, respectively. Finally, the backend API is wrapped using Flask in order to provide more flexible and personalized services.
Key words: knowledge graph; Q&A system; user intention
