基于信道排序的认知频谱分配算法∗
2023-11-29蒋孜浩郑安琪秦宁宁
蒋孜浩,郑安琪,秦宁宁
(江南大学轻工过程先进控制教育部重点实验室,江苏 无锡 214122)
认知传感网(Cognitive Radio Sensor Network,,CRSN)利用认知无线电技术(Cognitive Radio,CR)加持传感器节点以克服频谱资源短缺问题,在频谱受限的情况下认知节点利用频谱感知结果判断信道是否可接入,相比传统无线传感器网络(Wireless Sensor Networks,WSN)可以有效减少信道之间的干扰以增加网络的吞吐,适应更加复杂的场景,有着良好的应用前景[1]。
认知节点通过感知并对授权用户进行空洞检测,以机会接入频谱,因此可以实现在不干扰授权用户的情况下积极使用空洞频谱的功能[2]。基于认知无线电技术机会利用频谱的特性,在频谱受限情况下,认知传感网相比于传统无线传感器网络,可以有效减少信道碰撞所产生的能耗,降低信道竞争带来的网络时延与吞吐受限问题。但其较高的资源开销却击中了无线传感器网络的另一个痛点[3]。无线传感器网络节点通常拥有受限的能量且某些情况下无法通过外界供能,而认知无线电技术则需要对环境进行持续的监听以有机会接入空洞频谱,这不仅压缩了节点的休眠时间,同时又产生了额外的能量消耗,增加了节点的续航压力。
不同的频谱有着不同的通信质量,这意味着认知传感网中的节点选择不同的频谱进行通信将会有不同的吞吐量与不同的能耗,因此为网络中次用户进行适当的频谱分配是认知传感器网络中的关键技术。传统认知无线电与传统无线传感器网络的核心技术显然不适合直接搬运至认知传感网的组网与频谱分配中,需要对相关的认知传感网频谱分配方案进行深入研究。
认知传感网的频谱分配问题被明确提出于文献[4],该文献将频谱分配算法大致分为静态分配与动态分配两大类。静态频谱分配主要针对较为稳定的网络环境,分得资源后的节点短期内不会改变其频谱的选择,通常网络会先行给出频谱资源与相关的约束条件,再将网络中的路由固定后,便可将频谱分配问题转换为数学优化问题,通过各类算法求解频谱分配问题。
不少学者将频谱分配问题建模为图染色问题,通过粒子群算法[5]和灰狼算法[6]等群寻优算法实现问题的解决。文献[7]与文献[8]则基于微观经济学中定价拍卖原理对频谱分配问题进行建模,通过确认目标函数与指定赢家胜出规则实现最优化的频谱分配。
针对认知传感网频谱分配对网络能耗的影响,本文提出了适应信道的改进遗传算法(Adapt Channel Improved Genetic Algorithm,ACGA)进行频谱分配。通过一种基于信道贪婪排序的交叉方式与一种混合变异策略实现种群的更新与优化。仿真结果显示,基于信道贪婪排序的交叉方式可以明显增强ACGA 算法的寻优能力与寻优速度,而混合变异策略则在不同的信道数量下有着不同的效果。
1 系统模型及问题描述
1.1 网络模型
网络中存在着M个主用户节点PU 与N个次用户节点SU,其中PU={pum|m=1,2,…,M},SU={sun|n=1,2,…,N},PU 均等占用网络中的频谱资源,即有M个信道C={cm|m=1,2,…,M}平等分配给每个PU。
SU 作为次用户仅可在PU 未占用频谱的状态下使用其频谱的空闲间隙。图1 所示为认知传感网的多跳路由,图中左右虚线圆圈分别为基于双天线认知节点与基于单天线认知节点的多跳路由,网络中实线链路为用于上传节点数据至基站的下跳链路,而虚直线则是传输控制信息的上跳链路,网络中的可用信道集合为{c1,c2,c3}。

图1 单、双天线下认知传感网的多跳路由
显然单天线模式的多跳路由上下行信道相异,势必使得网络存在大量的数据传输冲突进而增加网络能耗,且切换收发信道的能耗浪费也不容忽视。在能耗之外,单天线路由还减少了网络的可用资源,如图1 中网络选择信道c3作为公共控制信道[9]导致了网络的可选择信道数量减少。
因此可采取一种区分接收与发送的工作方式,将一个节点的收发工作分给两根天线完成,在实现单一SU 上下行相不干扰的同时,降低SU 之间的干扰,由此便产生了双天线路由。在双天线的认知路由中,节点间的上下行信道可实现分离,并避免接收控制信息而产生的额外频谱切换次数,降低网络冲突和信道切换带来的额外能耗。
1.2 PU 模型与信道检测
PU 是网络中的主用户,在网络资源的使用中处于优势地位,其对信道的占用行为可类比为一个马尔可夫过程[10],通过能量检测识别PU 对于信道占用情况是最为常见的方式。能量检测通过统计PU 信号一段时间内的能量并与预设阈值对比,判断PU 对于频谱的占用情况。该方案复杂度低且无需知道检测信道中的信号细节,但检测结果易受到环境噪声与PU 信号的影响,在低信噪比的情况下,检测结果的可信度会显著降低[11]。
假设PU 的发射信号xPU服从正态分布,则在SU 处接收的对应信道中信号x也服从正态分布,在节点SU 计算得到所接收PU 的信号强度方差后。可根据已知的呈正态分布的网络噪声方差,计算得到sun认知cm检测概率Qn,m:
式中:Q(•)表示正态分布右尾函数;γ=βNT+(1-β)NT(SNR+1);β为检测因子,其取值区间为[0,1];SNR=
1.3 问题规划
在将频谱资源划分为多条可用信道的情况下,可将CRSN 的频谱分配问题抽象为一个基于图染色理论的信道分配模型。若将各节点发送信道抽象为色块,则可将邻近节点选择不同发送信道的问题转化为相邻色块的染色问题[12]。
假设每个传感器都携带有一个初始能量固定的电池。将通信信道看作简单的路径损耗模型,则使用时隙进行传输的能量消耗建模如下:
式中:Ecir为射频电路的能量消耗,s为一个时隙可以发送的数据大小,εs和εm分别为接收机所需的放大器能量。dn,i为sun与sui之间的通信距离,sui为sun的下跳节点。d0是常数,取决于传感器网络应用的环境。
由于节点需对信道进行认知才能进行接入并开始传输,则sun在信道cm上传输成功一次的统计期望能耗如下:
假设相关冲突节点间使用信道竞争机制进行数据的上传,则节点间的信道竞争也需要能耗。不同的节点若选择相同信道就可能产生认知信道的竞争问题,显然节点的竞争次数与干扰节点数量和干扰节点所传数据量相关。假设节点竞争获得信道的概率相同,有i个节点通过竞争占用信道,则参与竞争的节点sun平均竞争次数tn可建模如下:
式中:Dj表示节点suj的周期数据量,以单位时隙所发数据量作为单位;∑(Dj/Qj,m)表示参与竞争的所有节点理想传输次数之和,则sun使用信道cm的统计期望能耗如下:
其中Ecom为节点的竞争能耗,由此最小化网络能耗U的问题如下所示:
式中:XSU为节点信道分配矩阵,xi为节点sui所选信道编号,即节点cxi所选信道。若以遍历的方式计算最佳的信道分配,意味着需要计算MN次才能确定,这显然是一个NP 难问题。为此论文提出了一种适应信道的改进遗传算法(Adapt Channel Improved Genetic Algorithm,ACGA)进行频谱选择。
2 基于信道排序的频谱分配
2.1 基于信道排序的交叉过程
遗传算法中,解域的编码是算法实现的第一步[13],在该步骤下遗传算法会将解空间进行离散化,如若解域连续,则离散化也势必使得算法的问题求解精度有所下降。在频谱分配问题中,由于可选信道数量是固定的,因此认知节点的解空间可以依据数字编号依次与信道所对应以实现离散化编码,这表明了频谱分配问题是一类解域离散的优化问题。但由于频谱分配问题的可选择信道数量较少,因此在遗传交叉过程中,极易产生父类相似度过高的近亲交叉问题,这会降低算法的交叉有效性,进而影响算法的频谱分配能力。
在频谱分配问题中,一个解X就代表着一个个体,其中每个维度xk,k=1,2,…,K即代表着一个节点的信道选择,也代表着个体中的基因。为保证交叉的有效性,采用了一种基于信道贪婪排序的交叉方法。
①个体相似度
为了适应频谱分配问题中解的交叉问题,论文首先将父类个体Xi和Xj中的基因进行了相似分类。对于Xi和Xj中相同位置的基因,若二者相同则称该基因为相似基因,不同则称作不同基因。显然相似基因无需交叉,因此只需执行不同基因的交叉工作,但若是Xi和Xj相似度过高,则会出现交叉程度不明显的问题,为了数值化个体间的相似度,定义父类个体Xi和Xj之间的个体相似度Si,j如下:
式中:☉为同或运算符号;sum()为计算求和矩阵中的非零值;当Si,j较高时,代表着个体Xi和个体Xj之间的相似程度较高,即此时Xi与Xj是一种近亲的关系。被选择交叉的二者若为近亲关系,也许是两者都已经贴近了全局或局部最优解,又或许两者仅仅只是相似。在遗传算法的运行中,随着迭代次数的增加种群将越来越靠近全局最优解,因此也容易陷入局部最优解中,显然前一种的概率较高,因此近亲交叉极其容易陷入局部最优解。
②个体的信道贪婪排序
假设网络中所有节点间不存在竞争关系,则可以基于不同信道选择下的节点周期能耗对信道进行从小到大的排序,依据从小到大的顺序将1~M编号与信道进行对应形成信道排序矩阵R:
式中:rk内元素需相互不重复,rand(M)为取[1,M]的随机整数,用以对应信道排序后的编号,rk[m]的值代表cm在节点sun中的排序编号。显然这是一类贪婪排序,因为每个节点在排序信道的过程中只考虑了自己的收益。
③基于信道排序的交叉过程
在此信道排序基础上,提出了基于信道收益排序的交叉算法。对于不同基因的交叉,首先计算Xi和Xj中的不同基因对应节点sun的排序和。然后在交叉过程中,随机产生一个小于该排序和的整数,在Rk中选择出与该整数对应的信道作为交叉后Xi的基因,并将排序和与该整数的差对应的信道作为交叉后Xj的基因。
所提交叉算法基于信道的贪婪排序实现交叉信道的重组替换,基于两个父代个体中基因总体收益重选子类的基因,保留了父代的基因信息。
当两个相似度过高的父代进行交叉算法时,不仅容易导致交叉的失效,同时也大大降低了交叉随机性。为了解决近亲交叉带来的子代缺陷问题,论文为交叉算法增加了一种交叉变异机制,以期待减少子代的基因缺陷。
图2 所示是一次基于信道排序的交叉过程,假设可选信道集合为{c1,c2,c3,c4},其中父代个体X1和X2进行交叉并产生两个新的子代个体X3和X4。对比父代个体,可见两个个体在su2位置上的基因不同,因此对该位置进行交叉,依据su2的信道排序,计算得到X1和X2在su4上的排序和为4,随机产生一个随机数2 后,su2位置的基因交叉结果为{c2,c2}并将该两位基于随机给予子代个体X3和X4。
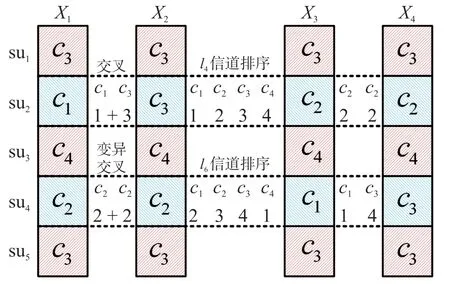
图2 基于信道排序的交叉过程
由于X1和X2中仅存在一位不同基因,因此判断两者相似度过高并进入随机交叉流程,在随机选中su4作为变异交叉基因后,对该su4基因位置执行如su2一样的交叉过程。可见在执行交叉算法后,子代个体X3和X4相比父代保留了较多的基因特征。基于贪婪信道排序的交叉方式在使得子代产生了一定的个体异化的同时,也在一点程度上均衡了子代之间的总体收益。
为了执行变异交叉步骤,需要提前设置相似度阈值S和最小不相似个数SN,当计算得到Si,j大于S时,判断Xi和Xj属于近亲,并基于SN 选择随机基因进行变异交叉。相似度阈值S和最小不相似个数SN 可以通过下式计算:
式中:算法会首先随机产生大量样本解,然后从中选出收益最佳的num 个进行S的计算。并依据以下规则进行交叉变异:当Si,j大于S时,计算相似基因的个数与SN 求差值,然后随机选取与二者差值个数相同的相似基因进行基于信道排序的基因交叉算法。
则输入两个父代个体求取两个子代个体的交叉算法伪代码如下:

其中,calS(X1,X2)为根据式(8)求取两个父代的相似度S12;find(X1≠X2)为找出两个父代不同的基因,并输出不同基因的编号矩阵;choose(temp1,num)为从temp1 中随机抽取num 个基因编号组成新的矩阵;random(point-1)输出一个小于point-1的正整数;Line4~Line8 为判断是否需要执行变异交叉的过程;Line9~Line17 根据需交叉基因矩阵temp 进行交叉,获得子代个体X3和X4。
2.2 混合变异策略
基因变异不仅是为了跳出当前局部最优解,同时也是遗传算法增加新优秀基因的重要渠道。为了更好地增加变异的效果,对于被选中需变异的个体,采用一种混合变异策略,当节点被选中变异时,会随机生成一个[0,1]的随机数η与变异阈值α进行对比,以此判断采取的策略,如式(12)所示:
当η>α时,该个体将会基于随机变异进行个体的异化,通过随机基因的随机替换实现个体的变异,该变异方式无法确定变异后个体收益的好坏,但却可以引入一些较差的解以均衡种群生态。
当η≤α时,该个体将会基于博弈进行个体的进化。该博弈基于帕累托最优规则[14]进行,遵守每次策略的选择都必须符合博弈者只能做出对自己更好且不使其他参与者变差的规则。运用到频谱分配过程中,每个节点的信道选择基于随机顺序产生,且单次博弈过程中,该顺序不产生变化。显然上述博弈过程是一种近似求解算法,因此个体在使用博弈进行变异后,必然会使得该个体变异后收益提升,这可以保证个体变异后种群整体质量的增加。
通过改变变异阈值α可以适当搭配博弈论与随机变异以获得足够的跳出当前局部最优解和寻找其他局部最优解的能力。博弈论可以为种群增加新的局部最优解,而随机变异则会均衡种群的平均收益,尽量为种群注入新的基因。
3 仿真及结果分析
利用MATLAB 建立仿真实验,对均衡能耗的频谱分配问题进行分析,同时验证基于信道排序的交叉算法和混合变异算法对ACGA 的改进作用。仿真实验在已知路由的网络上建立,对ACGA 算法的频谱分配效果进行分析。
仿真假设网络区域为边长为100 m 的正方形,BS 处于正中心,30 个作为次用户的认知节点与M个PU 随机散布在区域中,其余参数如表1 所示。

表1 仿真参数设置
3.1 频谱分配解域分析
由于频谱分配问题是一类NP 难问题,为分析频谱分配在不同主用户数量M下解的大致收益情况,在不同M数量的相同网络快照下,对随机产生的10 000 个初始解进行收益统计。
图3 为去除了离散值后统计得出的周期能耗箱线图,可见,在不同的M数量下,大部分解的收益都分布于箱线图的中间区。当M≤5 时,信道数量对于网络能耗的限制较为明显,随着M数量的增加,网络的能耗中位数与能耗最小值也相应呈现单调下降的趋势,这是节点间信道竞争减少带来的能耗收益。而M数量增加所带来的增益也存在一定的边际效应,即若网络中信道的数量多至节点可以随意选择且不存有干扰后,此时M的增长对网络的影响较为微小。
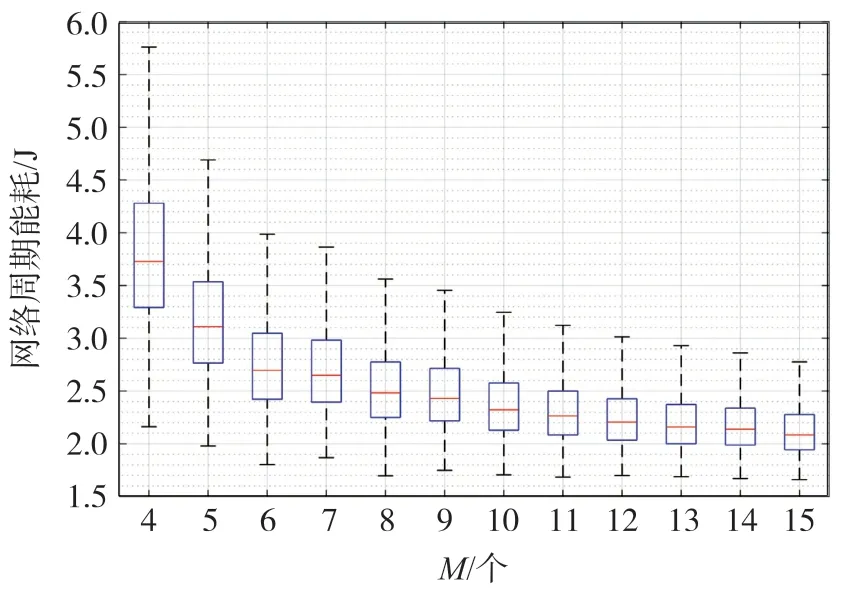
图3 随机样本解能耗在不同M 下的分布情况
基于上述随机样本,取其中收益最佳的100 个解对相似度阈值S和最大相似个数SN 进行求取,对此在不同的M数量下,S和SN 的值如表2 所示,其中SN 需向上取整后才能进行使用。
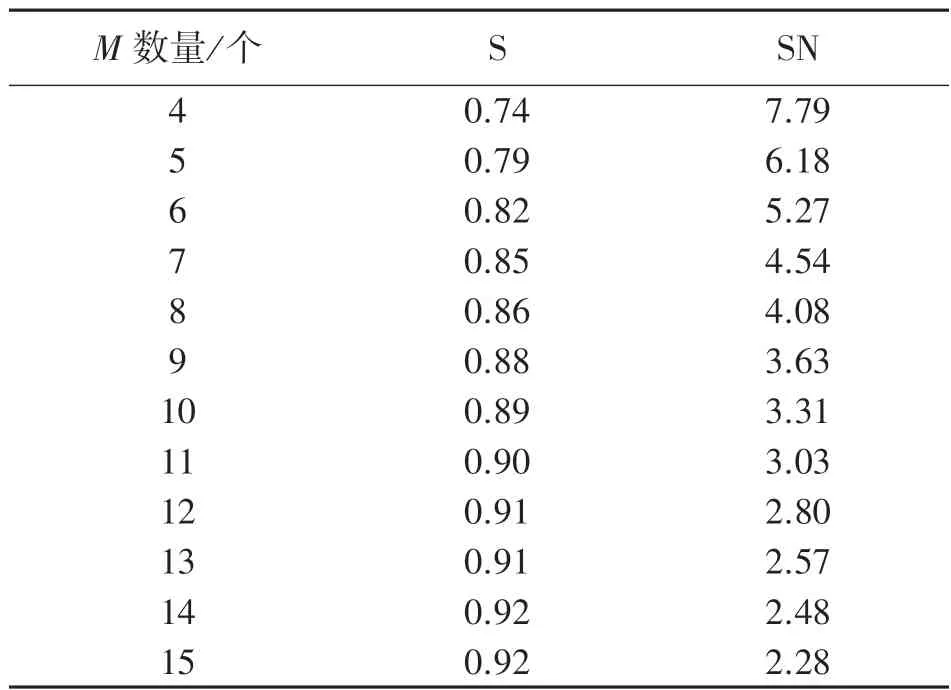
表2 相似度阈值S 和最小不相似个数SN 的取值
可见随着M数量的增加,相似度阈值呈现单调上升趋势。这是因为随着M数量的增加,网络中节点的冲突减少,收益较好解中的节点信道选择会趋向贪婪,即每个节点会选择信道贪婪排序中顺位较高的信道而不考虑节点间干扰。
3.2 交叉与变异性能分析
为分析ACGA 的交叉与变异算法的性能,设置GA 和ACGA 的初始种群数量为1 000,ACGA 中变异概率为0.1 且将变异阈值α分别设置为0、0.5、1,而GA 的交叉概率和变异概率分别设置为0.5 和0.1,且利用10 位二进制对信道进行编码。以M作为变量,每轮均在相同的网络快照下对ACGA 和GA 各进行50 次仿真并取平均值。
图4 和图5 分别为ACGA 和GA 的网络周期平均能耗对比图和算法平均收敛迭代次数图,当变异阈值α=0 时,ACGA 中个体将只进行随机变异,这意味着此时ACGA 对比GA 就只进行了交叉的改进。将GA 与变异阈值α=0 的ACGA 对比,可以看到ACGA 在优化效果和收敛速度上,相比基础GA更具备优势,这说明基于信道排序的交叉算法可以有效增加交叉后子代的优秀率,增强种群的进化速度。
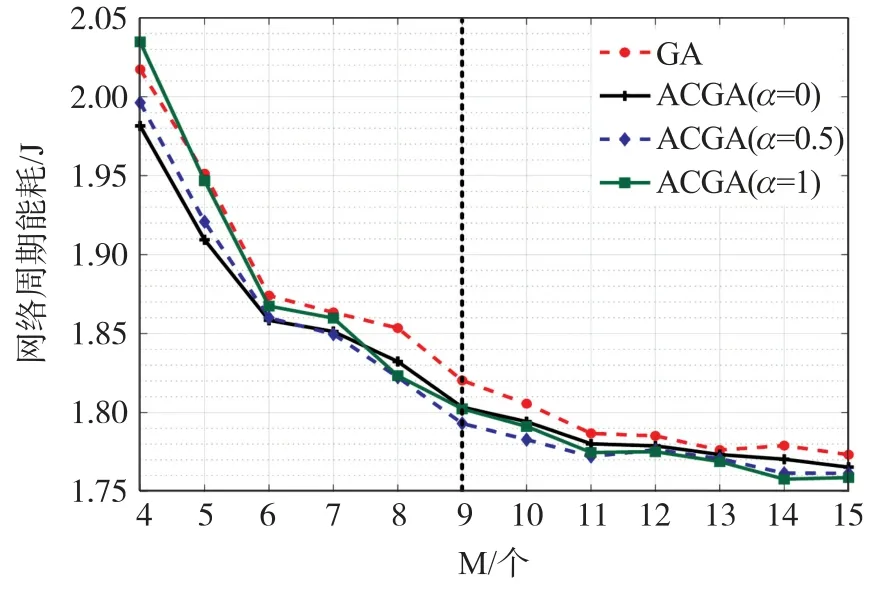
图4 不同M 下GA 和ACGA 网络周期平均能耗

图5 不同M 下GA 和ACGA 算法平均收敛迭代次数
在M≤5 的情况下,ACAG 中基于博弈论的变异方式并不能给种群带来优质个体,反而会因为博弈占用了资源却无法取得良好效果的问题导致算法性能受到影响。对ACGA 算法而言,设置变异阈值α=1 意味着算法在M≤5 时同时失去了博弈变异能力与随机变异的能力,这使得种群快速迭代并收敛到最终较差的局部最优解。而α=0 的ACGA 算法在M≤5 时则可以依靠随机变异的进行更大范围的搜索,通过增加迭代次数的方式增加算法性能。
而在M>5 后,随M的增加,α=1 的ACGA 算法寻优能力逐步加强,在快速收敛的同时也拥有较较强的寻优能力,这是因为博弈在M≥10 之后优异的近似求解性能为算法提供了大量不同的局部最优解,在较少的迭代后就可以进行收敛并取得不错的收益。从总体上看,设置α=0.5 的ACGA 可以获得较为平衡的性能,在利用博弈算法M≥10 寻找局部最优解的同时,又不使得算法失去获取随机基因的能力。
3.3 频谱分配效果分析
为分析ACGA 在频谱分配问题上的寻优效果,将其与离散粒子群算法[15](Discrete Particle Swarm Optimization,DPSO)、离散灰狼算法[16](Discrete Gray Wolf Optimization,DGWO) 和基础遗传算法(Genetic Algorithm,GA)进行仿真对比,以M为变量分析4 种寻优算法的性能。仿真设置DPSO 和DGWO 的初始粒子和狼群数量为1 000,GA 和ACGA 的初始种群数量为1 000,交叉概率和变异概率分别设置为0.5 和0.1,其中设置ACGA 的变异阈值α=0.5。每次仿真均在相同的网络快照下,对ACGA、DPSO、DGWO 和GA 进行50 次仿真。
图6 所示为4 种算法在不同M下进行频谱分配所获得的平均网络周期能耗,可以看到4 种算法的执行结果都符合随着M增大而网络周期能耗减小的趋势,这与3.1 节中分析结果相同。DPSO、DGWO 在频谱分配问题上的求解效果类似,两者的求解效果较GA 和ACGA 均稍差,这是因为DPSO和DGWO 这两类基于步长迭代的算法显然更适合用于连续问题的求解,而在频谱分配问题中解与收益的离散性较强,导致基于步长迭代的两类算法并不能实现较好的迭代效果以增加全局搜索能力,反而因为步长的限制更容易陷入局部最优解中而导致过早停止迭代。

图6 不同M 下4 种算法平均网络周期能耗
对比GA 与α=0.5 的ACGA 的平均网络周期能耗,可以发现二者在M变化下的曲线趋势相似。二者在M=13 和M=8 时分别产生了最大和最小的差值,分别为0.005 2 J 和0.031 1 J,从全局上看,α=0.5 的ACGA 有着较为均衡的性能,相比原始GA 算法有着较强的寻优能力。
图7 给出了4 种算法在不同M值下的平均收敛次数,GA 算法因为本身的全局搜索能力就较强,因此相比DPSO 和DGWO 迭代次数较高且寻优性能较好,但因为频谱分配问题属于NP 难问题,仅靠普通的交叉算法与变异算法很难优到最优解。图中GA在算法在经过高于36 次的迭代后就因难以找到更好的局部最优解而停止了迭代,而DPSO、DGWO 则因为步长迭代的方式以至于算法运行中快速进行了收敛而导致算法停止,相比较GA,两种算法的迭代次数只有GA 迭代次数的75%左右。α=0.5 的ACGA 因为改进了交叉算法以及变异算法,相比GA 可以更多接触到局部最优解,同时较强的全局搜索能力也保证了性能的优势,因此可以在较少的迭代次数下获得较高的收益。显然ACGA 相比其余三类算法在频谱分配的问题上有着较大的优势,由于频谱分配属于一类多维度的离散的NP 难问题,因此在类似的相关问题中,ACGA 也可以实现良好的效果。
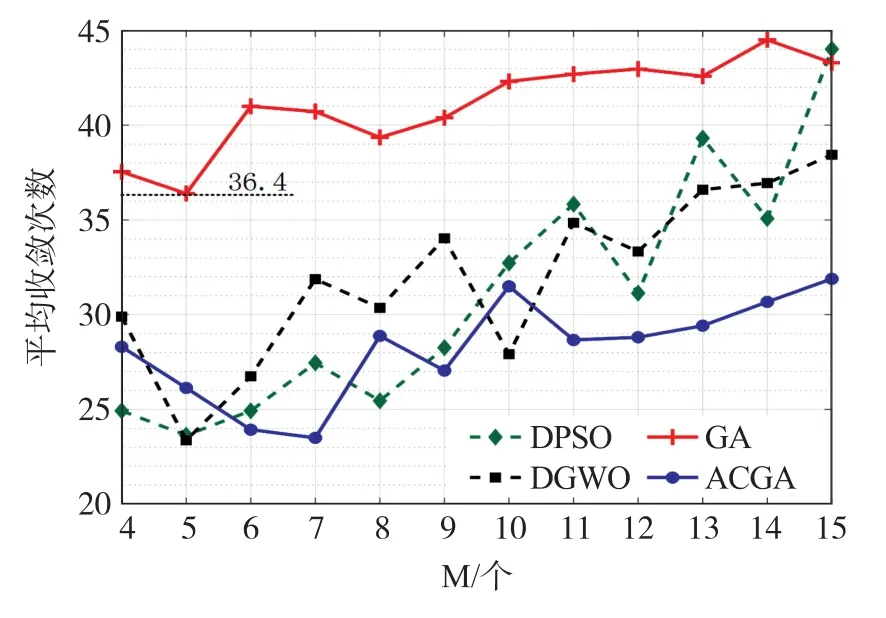
图7 不同M 下4 种算法收敛次数
4 总结
针对认知传感网中的能耗问题,提出了一种基于适应信道问题的改进遗传算法。为了增加执行交叉算法后父代与子代的联系,采用了一种基于信道排序的交叉算法实现种群的交叉迭代。其后利用混合博弈论的变异算法进行个体的异化工作,以在维持种群多样性的同时增加挑选优秀基因的能力。仿真结果表明,ACGA 相比基础的遗传算法在频谱分配问题上有着优秀的寻优性能,可以较好地优化基于网络能耗的频谱分配问题。
