基于多核支持向量机的句子分类算法
2023-11-29肖开研
肖开研,廉 洁
(上海师范大学 信息与机电工程学院,上海 201418)
0 引 言
句子分类是一种对评价、意见、情感等各种文本进行分类的任务,是当下自然语言处理领域热门的研究方向之一.句子分类算法在情感分析、信息过滤、智能聊天等方面[1-2]有着广泛的应用,对舆情了解、政策制定、企业营销决策等都起着重要的作用.
目前,句子分类算法主要包括基于深度学习的分类算法和传统分类算法.基于深度学习的分类算法包括卷积神经网络(convolutional neural networks,CNN)[3]、长短期记忆网络(long short-term memory,LSTM)[4]和BERT(bidirectional encoder representations from transformer)模型[5]等.其中,基于CNN 的句子分类算法在实验中取得了优异表现,但是,即使是简单的CNN 也要求在训练前精确设计网络的结构,并设置相应的超参数,导致该算法对实践者要求较高[3];LSTM 的门控机制可处理长期依赖、梯度消失等问题,但是由于缺乏对文本的并行处理能力导致训练耗时过长[4];BERT 模型采用Transformer 作为编码器[6],拥有对文本的强大编码能力,却因参数量过大无法在普通设备上训练、加载[7].可见,深度学习模型不仅对硬件要求较高,且其存在着参数量大、容易过拟合等问题.
传统分类算法包括朴素贝叶斯分类器(naive Bayes classifier)[8]和支持向量机(support vector machine,SVM)[9]等.早期的分类算法通过词袋(bag of words,BOW)模型[10]、TF-IDF(term frequency–inverse document frequency)[11]模型构造基于词频的文本特征,忽略了文本间的结构关联,导致分类效果不佳[12].但随着Word2Vec[13]、GloVe(global vectors for word representation)[14]、FastText[15]等词向量模型的提出,使词向量的表达包含了上下文信息,有效解决了早期词向量存在的维度高、稀疏且缺少关联等问题.BERT 模型生成的词向量表示不仅包含上下文信息,并且能有效提取单词在特定语境下的含义.利用这些词向量表示,对文本中的单词进行简单的加权求和,可以轻松得到文本的向量表示,传统的支持向量机算法可以在这些文本表示上进行训练.支持向量机在全局上将句子分类问题转化为二次规划问题,不用大量的标记样本就能训练出分类性能较好的模型,因此,结合词向量和支持向量机对文本进行分类不仅可以利用到词向量语义信息丰富和SVM 易训练的优点,而且能有效避免深度学习算法中存在的结构复杂、参数量大、容易过拟合等问题.然而目前基于支持向量机的句子分类算法只利用了单一的词向量模型,即用单一核函数映射、提取文本的向量特征表示,因此存在对文本信息提取不全面、映射能力差的问题[16].
如今,多核学习(multi-kernel learning,MKL)在多个领域都得到了成功的推广,各种理论和应用也证明了多核学习相较于单核学习的优越性能[17].为了探析多核学习在句子分类中的应用效果,本文采用4 种主流的词向量表示模型: Word2Vec、GloVe、FastText 和BERT,将多核支持向量机应用于句子分类,并设计了新的核函数系数寻优方法,以更加准确地提取文本特征,从而提升句子分类的准确率.
1 相关工作
1.1 词向量表示模型
1.1.1 Word2Vec 模型
Word2Vec[13,18]是一种使用神经网络概率语言模型来训练词向量的方法,其包含通过上下文预测目标单词的CBOW(continues bag of words)模型和通过目标单词预测上下文的Skip-gram 模型.Word2Vec 采用了层次softmax(hierarchical softmax)和负采样(negative sampling)等优化技巧,将单词转化为词向量,同时所得词向量在空间的余弦距离的大小代表了单词之间语义和语法关系的相似度.
1.1.2 GloVe 模型
GloVe[14]是基于全局词频统计的词向量模型.GloVe 模型先计算词共现矩阵,再利用词向量与词共现矩阵之间的近似关系构建损失函数,最后通过学习得到较低维度的词向量表示.GloVe 模型中词与词之间的相似性也可以通过词向量间的距离大小来衡量,而且相较于Word2Vec,GloVe 模型包含了文本的全局信息,对多义词的处理能力更强.
1.1.3 FastText 模型
FastText[15]是将整个文本作为特征输入来预测文本类别的模型.其中FastText 通过n-grams 方法字符级别地表示一个单词,这样不仅对低频词生成的词向量效果更好,而且对于语料库之外的单词可以通过叠加字符向量来构建相对应的词向量.
1.1.4 BERT 模型
BERT[5]通过双向Transformer 编码器构造基于上下文的词向量.与Word2Vec 不同的是,BERT根据上下文变化,动态地生成词向量,即重复单词会因上下文不同而产生不同的词向量,这让BERT 可以捕捉单词在特定语境中的含义,使其在自然语言处理任务中表现优异.
1.2 支持向量机
文献[9]基于统计学习理论首次提出了支持向量机(SVM)算法.SVM 算法基于VC 维(vapnikchervonenkis dimension)理论和结构风险最小原理,通过构造最大超平面对样本进行分类.早期,线性SVM 难以对线性不可分样本进行分类[19].后来,核函数的使用将线性SVM 推广至非线性SVM,使SVM 的适用范围和分类准确性均得到明显提升.相对于线性SVM 而言,非线性SVM 通过核函数将低维特征空间里的线性不可分样本,映射到更高维甚至无限维的特征空间中,并在高维空间中计算最大超平面对样本进行分类.
近期,很多基于SVM 的不同变体被提出,例如,Sun 等[20]提出的基于Fenchel-Legendre 共轭变换的稀疏半监督学习框架,为稀疏多视图SVM 提供了有效的训练方法;Ji 等[21]提出了一种基于正则化函数最小化的多任务多类别SVM,让多任务多类别学习能有效提取不同类别、不同任务间的内在联系;Sun 等[22]利用多视图正则化项对广义特征值最接近SVM 进行优化,将复杂的优化问题转化为广义特征值问题.此外,有关切线空间本征流行正则化技术的引入[23],包含局部主成分分析所得的局部切空间表示和使相邻切线空间相关的联系,让SVM 可以有效考虑切空间本征流行正则化,以解决半监督学习问题.
1.3 多核支持向量机
核函数的出现让许多问题可由线性推广至非线性情况[22,24],同时,基于单核学习的SVM 已经在许多领域得到成功应用.但是当样本数量庞大[25]、样本数据在高维特征空间非平坦分布[26]或样本特征所含信息具有异构性时[27],采用单核方法对所有样本以相同的方式进行映射的效果并不理想.针对单核学习的不足,众多研究[25-27]聚焦于多核学习,以此来提高决策函数的可解释性,获得更优的分类效果.多核学习主要分为核融合、多尺度核、无限核等方法.本文聚焦于核融合方法,主要思想是将不同特性的核函数进行组合来获得更优的映射性能.然而在实现多核融合时,每个核函数系数的设置直接影响最后的融合效果.因此核系数的寻优方法至关重要,当系数数量较少时常用网格搜索(grid search,GS)[28]、随机搜索(randomized search,RS)[29]等方法.通常,核系数的可行域为[0,1]且求和为1.GS 在可行域中设置一定步长进行网格搜索,步长较短会导致训练非常耗时,步长较长则会导致核融合效果差.RS 在可行域中随机采样,该方法的效果和GS 类似,需要设置较大的采样次数才能获得较好的模型效果.针对这些问题,本文提出的基于参数空间分割与广度优先搜索的系数寻优方法,在训练次数较少的情况下也能获得较好的分类效果.
2 模型构建
本文基于多核SVM,提出了新的系数寻优方法实现多核融合,将融合所得的混合核嵌入传统SVM,从而实现句子分类.
2.1 模型框
基于多核SVM 的句子分类算法框架如图1 所示.该算法主要分为两个阶段: 训练阶段和测试阶段.在训练阶段,首先对输入文本进行文本预处理,包括分词、去除停用词、提取词干、还原词形、转化为小写;随后,分别选用Word2Vec、GloVe、FastText 以及BERT 词向量表示模型,将训练集文本中的单词表示为词向量,并将句子中所有单词的词向量相加后求均值,作为句子的向量表示;之后将句子向量利用核函数进行映射,从而得到核矩阵,再按照寻优所得的核函数系数,将这4 种词向量表示模型所得的核矩阵线性组合,从而得到混合核,实现训练集文本的多核学习;最后,采用支持向量机方法训练出分类器.在测试阶段,对测试集文本同样进行文本预处理、特征提取、核融合后,导入训练所得的SVM 分类器,从而实现句子分类.
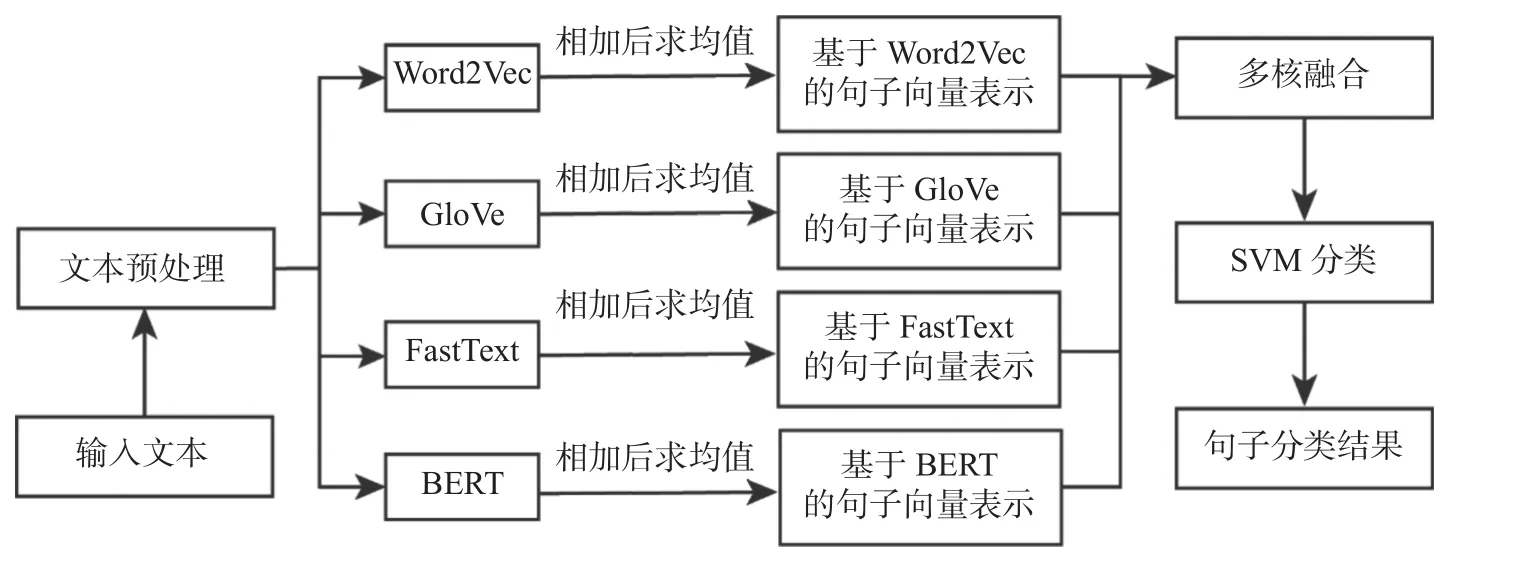
图1 模型框架Fig.1 Model framework
2.2 多核支持向量机
假设某一数据集中含有n个样本,每个样本有M种词向量表示,表示第i个样本的第m个词向量表示,其样本的类标签为yi {1,-1}.多核SVM 主要解决了优化问题
式(1)中:W()m、φ()m、βm分别表示第m个词向量表示的超平面法向量、核函数和核函数系数;ξi、C分别表示第i个样本的损失值和惩罚因子.与传统SVM 的思想一致,可将多核SVM 优化问题转化为对偶形式
约束条件
在实验中,本文利用Word2Vec、GloVe、FastText 以及BERT 这4 种词向量表示模型来计算4 种核函数,然后进行核融合,具体细节详见图2.由图2 所示的热力图及其图例可知,不同词向量表示模型所提取的特征不同(热力图中颜色越蓝的点代表该点数值越接近–0.20,颜色越红的点代表该点数值越接近0.20).

图2 多核融合过程Fig.2 Illustration of multi-kernel fusing
2.3 核函数系数寻优方法
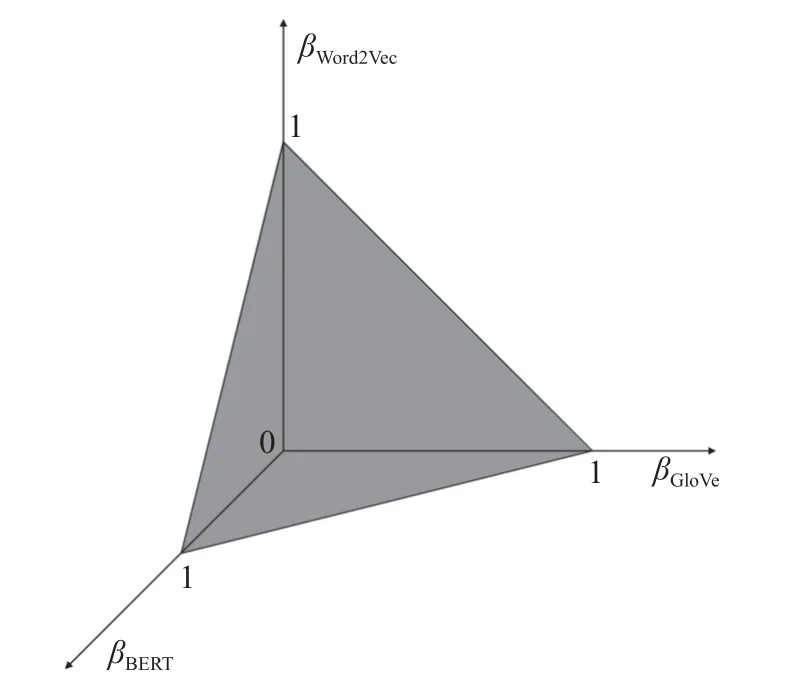
图3 参数空间Fig.3 Parameter space
在目标函数不可导的情况下,假设目标函数存在多个局部最优解,且当βWord2Vec、βGloVe与βBERT变化无限小时,目标函数连续.本文提出的系数寻优方法具体步骤如下.
步骤一: 参数空间为三棱锥体,不断连接参数空间中的最长边中点与其不相邻的2 个顶点将参数空间分割为 2s个三棱锥体区域.
步骤二:(βWord2Vec,βGloVe,βBERT)依次取值为每个区域的重心坐标值并进行 2s次训练.
步骤三: 对步骤二所得的 2s个训练结果进行排序,选择分类效果最优的h个区域作为新的参数空间.
步骤四: 重复步骤一、步骤二、步骤三,达到预设的参数空间分割次数,不断逼近βWord2Vec、βGloVe和βBERT的局部最优值.
以上步骤中涉及的s为预设的分割次数,其分割方式如图4 所示,其中深色区域为下一轮进行分割的区域.该分割方式通过参数空间的分割,快速逼近目标函数的多个局部最优解,最终选取验证集上训练效果最佳的局部最优解作为核函数系数.

图4 参数空间分割Fig.4 Parameter space segmentation
3 对比实验
3.1 实验数据
为了检验本文所提出模型的分类性能,采用以下数据集进行实验.
● SST(Stanford sentiment treebank)-1 数据集: 斯坦福大学情感分类语料库数据集,包含 very positive、positive、neutral、negative 和very negative 这5 个类别标签.①http://nlp.stanford.edu/sentiment/
● SST-2: 在SST-1 基础上仅保留了positive 和negative 这2 个类别标签.
● Subj(subjectivity): 主观性数据集,包含subjective 和objective 这2 个类别标签.②https://www.cs.cornell.edu/people/pabo/movie-review-data/
● TREC(text retrieval conference): 问题数据集,包含abbreviation、entity、description、human、location 和numeric 这6 个类别标签.③http://cogcomp.cs.illinois.edu/Data/QA/QC/
● CR(customer review): 顾客产品评价数据集,包含positive和negative 这2 个类别标签.④https://huggingface.co/datasets/SetFit/CR
● MPQA(multi-perspective question answering): MPQA 意见极性检测子任务数据集,包含2 个类别标签.⑤https://www.mpqa.cs.pitt.edu/
● CT(coronavirus tweets): Covid-19 情感分类数据集,包含positive、neutral 和negative 这3 个类别标签.⑥https://www.kaggle.com/datasets/datatattle/covid-19-nlp-text-classification
数据集详细信息汇总于表1,其中,词库大小是指数据集中共有多少个不同的单词,平均句长是指数据集中每个句子平均单词个数.数据集中部分数据集已预划分训练集、验证集、测试集,对于未预划分的数据集采用十折交叉验证(cross-validation,CV),按照0.8∶0.1∶0.1 的比例随机划分训练集、验证集、测试集.
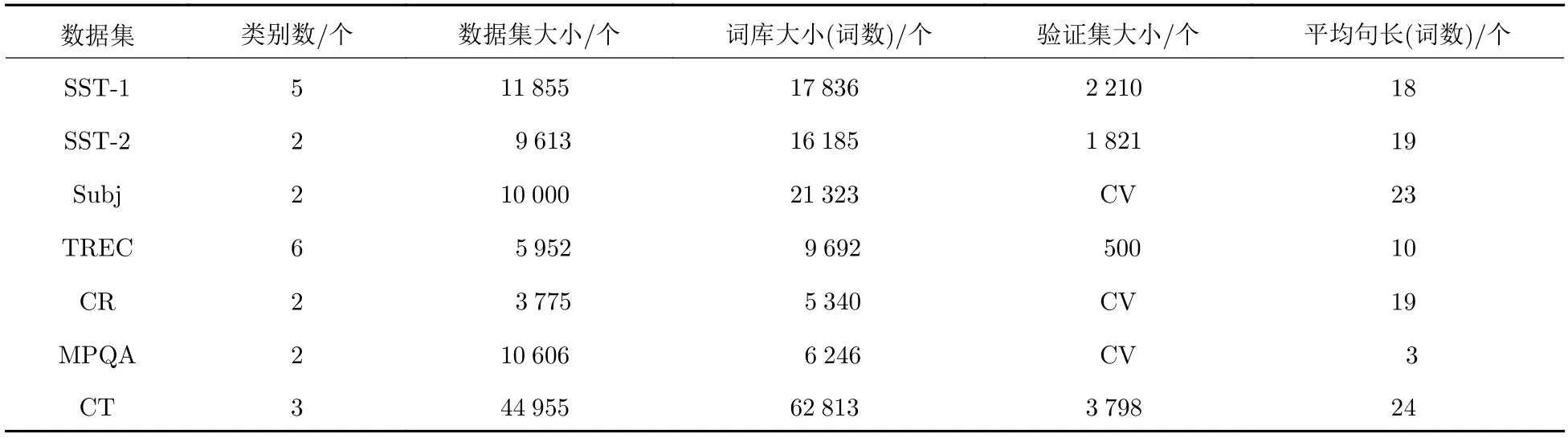
表1 标记数据集统计汇总Tab.1 Summary statistics of the datasets after tokenization
3.2 超参数设置
实验使用预训练的谷歌Word2Vec 词向量文件、斯坦福GloVe 词向量文件、脸书FastText 词向量文件(此3 种词向量维度为300),以及BERT 的词向量(其维度为768)对文本进行映射.若文本中存在不属于Word2Vec、GloVe、FastText 词向量文件中的单词,则采用随机函数生成300 个处于[–0.25,0.25]的随机数组成其词向量.实验选用高斯核函数
其中,高斯核函数的参数γ和SVM 的惩罚因子C的寻优空间分别为[1,0.1,0.01,0.001]、[0.1,1,10,100,1 000].GS 设置步长为 0 .1,在系数寻优空间中总共可以采样 84 个样本点.为了公平比较GS 和RS,RS 方法在系数寻优空间中同样随机采样 84 个样本点.在本文提出的寻优系数方法中,将样本空间分割为 32 个区域,选取训练效果最好的两个区域进行二次分割;二次分割中每块区域分割为16块区域,共选取 64 个样本点进行 64 次训练.
3.3 实验结果
本文共选取了6 种文本表示模型进行对比实验,包括经典的BOW、TF-IDF 算法,以及基于Word2Vec、GloVe、FastText 和BERT 的词向量的文本表示算法,并对比了3 种核函数系数寻优方法.实验使用准确率作为分类器的分类性能评估指标,结果如表2 所示,其中,MKL 表示通过Word2Vec、GloVe、FastText 和BERT 进行多核学习.表2 中数据为10 次实验结果的均值.

表2 模型分类准确率对比结果Tab.2 Comparison of model classification accuracies
实验结果表明,多核学习相较于早期词向量模型BOW、TF-IDF 提升幅度明显,在数据集SST-1、CR 上分别提升了9.2%、7%.在所有数据集中,基于多核支持向量机模型的分类准确率,相较于单核学习中的最好结果都有一定提升,其中在数据集TREC 上准确率提升了2.7%,提升幅度最大.寻优方法中,GS 和RS 训练效果相近,RS 在参数空间随机采样,返回的参数相比于GS 精度更高;但在训练次数少的情况下,随机采样导致了训练结果波动较大,而本文提出的方法通过空间分割的方式不断逼近核系数局部最优值,即使训练次数少于GS 和RS,也取得了更好且更稳定的分类结果.单核学习和多核学习在数据集SST-2 上的ROC(receiver operating characteristic)曲线如图5 所示,其中,纵轴是真阳性率(true positive rate,TPR),横轴是假阳性率(false positive rate,FPR).从其图像和AUC值(ROC 曲线下面积,area under the curve,AUC)可以看出多核学习模型的分类能力更强.

图5 SST-2 数据集上MKL*与单核学习的ROC 曲线Fig.5 ROC curve of MKL* and single-kernel learning on SST-2 dataset
此外,当γ和C的寻优范围分别为[1,0.1,0.01,0.001]、[0.1,1,10,100,1000]时,3 种核系数寻优方法训练次数和训练耗时如表3 所示.从表3 中可以看出,参数空间分割的寻优方法得益于训练次数少,从而使训练耗时大幅度降低.

表3 参数寻优方法训练耗时对比Tab.3 Comparison of training times for parameter optimization methods
4 结束语
在句子分类任务中,过去的研究侧重于单核学习,主要是改进句子分类算法中的词向量表示模型,这类方法往往被其运用的词向量表示模型的缺陷所约束.本文首次将多核学习运用到句子分类任务中,多核学习的思想融合了不同词向量表示模型的优点,让句子分类结果更加精确.此外,针对传统系数寻优方法的不足,本文提出了一种基于参数空间分割的系数寻优方法.在系数寻优过程中,该方法有效减少了训练次数和训练结果的随机性,并获得了更优的分类准确率.
目前,本文实验采用了4 种词向量表示模型进行多核学习,导致多核学习的潜力没有完全开发.当今还有许多优秀的文本表示模型,如ALBERT(a lite BERT)、ELMo(embeddings from language models)、GPT2(generative pre-trained transformer 2)和GPT3 模型等,都可以获得文本的向量表示.考虑到本文所提出的系数寻优方法能自然地扩展至高维空间中,因此,下一步工作将采用更多的模型进行多核学习,进一步提升句子分类准确率.
