分层级描述感知的个性化推荐系统
2023-11-29陈道佳陈志云
陈道佳,陈志云
(1.华东师范大学 计算机科学与技术学院,上海 200062;2.华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
在信息爆炸的时代,推荐系统可以减少用户在众多产品和服务面前决策的复杂度,同时增加平台提供服务的机会,因此其被广泛应用于现今的在线服务平台.其中,电商和社交等网站上,用户写下大量关于消费物品的意见和评论.这些评论中包含着丰富的用户偏好和物品属性的语义信息,挖掘评论信息能显著提升推荐系统预测评分的效率.大量的工作专注于利用评论数据进一步提升推荐系统的性能.
推荐系统的关键在于从用户历史行为中学习用户表示和物品表示.传统的协同过滤算法使用如评分、购买记录和观看历史等显性反馈建模用户表示和物品表示,如矩阵分解(matrix factorization,MF)方法分解用户–物品评分矩阵为2 个隐因子分别代表用户和物品.这些方法因仅仅依赖显性交互而遭遇数据稀疏问题的困扰,而且无法处理新用户或物品加入的冷启动问题.考虑到评论中仅利用评分和购买记录等显性反馈不能完全传达内容语义信息,使用评论建模用户偏好和物品特征可以缓解以上问题并且为推荐结果提供解释性.早期的方法基于主题技术从评论中提取主题分布作为MF 的隐因子,比如,HFT(hidden factors as topics)[1]和RMR(ratings meet reviews)[2]整合MF 与主题技术,分别从评分和评论中学习物品的隐表示、用户的隐表示.
基于深度学习(deep learning,DL)的方法通常使用神经网络用评论编码物品和用户,可以简单分为平行对称模型和交互模型.平行对称模型使用对称的网络分别建模用户和物品,例如,DeepCoNN(deep cooperative neural networks)[3]模型使用2 个对称的卷积神经网络(convulutional neural network,CNN)去学习用户和物品表示,然后输入因子分解机预测评分;D-Attn(dual attention)[4]模型使用2 个基于注意力的网络去关注评论中重要的单词;NARRE(neural attentional regression model with review-level explanations)[5]基于注意力学习每条评论的有用性.交互模型建模用户和物品的评论交互,基于推荐的上下文动态地学习物品和用户表示,例如,DAML(dual attention mutual learning)[6]模型基于用户和物品评论词向量之间的欧氏距离,学习物品和用户之间单词的相关性;CARL(context-aware user-item representation learning)[7]模型学习物品和用户评论文档的语义矩阵,并映射到相同的隐空间计算用户–物品对之间的相关性;ANR(aspect-based neural recommender)[8]模型基于方面的协同注意力提取不同方面的交互信息.
尽管通过上述方法取得了显著的推荐性能的提升,但仍有一些问题没有系统研究.为了全面理解建模物品和用户,应该考虑如下挑战: ①分层建模.DeepCoNN 和CARL 将评论拼接成一个长文档,没有考虑每条评论的独立性,直接建模包含了大量异质信息的文档,可能忽视句子和评论级别的细粒度信息,引入的注意力机制的变体模型可视为仅有单词级别注意力;NARRE 和ERP(enhanced review-based rating prediction)[9]引入辅助信息学习每条评论的有用性,但忽视了不同单词的有用性.② 动态兴趣建模.大多现有的推荐方法通常学习静态的用户和物品表示,如建模用户时,没有考虑用户面对不同目标物品可能显示不同的兴趣偏好;MPCN(multi-pointer co-attention networks)[10]引入基于指针的学习方法,强调用户和物品的交互;每次基于相似度得到选取K条评论会让模型变得不稳定,CARL 和DAML 同样基于评论文本相似性,动态地学习不同单词的有用性,但是过度依赖文本语义相似可能让模型仍缺乏灵活性.③个性化.用户通常有个性化的偏好,物品也有个体的特征,对于一条同时描述价格和质量的评论,不同用户会侧重不同的方面,对价格敏感的用户更关注价格的评论,但是现有的推荐模型大多为所有的用户和物品学习统一的模型,不能识别特定用户的差异个性化特征,仅从普通注意力机制捕捉重要单词,不能体现相同单词对不同用户的重要性不同.HUITA(hierarchical user and item representation model with three-tier attention)[11]和HSACN(hierarchical self-attentive convolution network)[12]分别采用普通注意力和自注意力模块,从单词、句子和评论这3 个层级建模,但是缺乏建模动态交互且缺乏个性化;CARL 仅考虑单词级别的交互,但是缺乏层级.因此,本文同时考虑这3 个关键挑战,提出了分层的描述感知的个性化推荐方法.
在单词层级,评论中相同的单词对不同的用户或者物品有着不同的信息量,本文从用户ID 或物品ID 推导注意力向量,设计注意力网络选择重要且个性化的单词,获得每条评论的个性化表示.在评论层级,用户的评论是对不同物品的历史评论,用户面对不同的物品,可能会激发不同的评论有用性,受到深度兴趣网络启发,本文从物品ID 推导注意力向量,形成物品感知的交叉注意力网络选择和当前目标物品相关的用户评论,从而动态地获得用户表示,同理,获得物品表示.此外,考虑到评论的摘要文本包含的信息更加简洁和密集,通常都是对特定方面描述的短句,拼接评论摘要成一个文档可用作物品或用户的客观描述信息,本文针对物品和用户的描述,设计协同注意力网络捕捉上下文感知的动态兴趣偏好和物品特征.注意到评论的语义特征只反应部分的内容信息,基于描述的特征可动态表示关键方面的特征,基于评分矩阵的评分特征有丰富的协同信息,将评论特征和评分特征融合可以完成互补得到更全面的物品和用户表示.本文的主要贡献如下.
(1)分别设计了单词层级和注意力层级的注意力网络,学习了不同单词和评论的有用性,提取了个性化的用户偏好和物品属性.
(2)将评论摘要拼接为客观描述,基于用户和物品描述,设计了协同注意力网络,以捕捉上下文感知的动态特征.
(3)在5 个数据集上进行的大量实验证明了本文所提方法的有效性.
1 相关工作
基于评论的推荐系统,早期基于矩阵分解(MF)的协同过滤技术仅仅利用评分矩阵分解得到用户和物品的隐因子表示,假设隐因子分布为概率分布则可扩展为概率矩阵分解模型.之后,Koren 等[13]为用户和物品的隐因子引入偏差项,进一步优化了MF 方法.尽管这些协同过滤算法能取得较优的表现,但是仍然受到评分矩阵数据稀疏问题的困扰.
随着用户和物品交互产生的大量诸如评论文本的隐性反馈数据,研究者们尝试通过将评论作为辅助信息来缓解数据稀疏问题并提升推荐性能.与自然语言处理的语义理解研究线路一致,早期的引入评论的推荐方法是基于主题模型的,即将从评论中挖掘的主题特征替代为MF 模型的隐因子,比如,Macauley 等[1]使用隐含狄利克雷分布(latent Dirichlet allocation,LDA)模型提取用户和物品评论中的主题语义,并将其作为用户和物品的表示;RBLT(rating-boosted latent topics)[14]模型假设高分评论包含更多信息,因此先基于评分复制多份高分评论,而后再挖掘主题;Yang 等[15]先使用主题模型从评论中提取语义特征,然后将这些提取出的特征和从MF 模型提取的评分特征进行融合,并作为用户和物品的隐表示;Diao 等[16]同时使用评论的主题词、评分和情感建模用户和物品的兴趣分布;CDL(collaborative deep learning)[17]模型使用去噪自编码器建模物品内容,并整合到概率矩阵分解框架.以上这些方法都超过了仅依赖评分矩阵的方法;但是,主题模型依赖词袋机制忽视了词序和局部语境信息,故损失了大量评论文本的上下文语境特征.
近年来,受益于深度神经网络(deep neural network,DNN)的强大表征能力,越来越多的研究使用神经网络去提取评论上下文信息.CNN 和循环神经网络(recurrent neural network,RNN)通常用于组合上下文语义信息到一个连续的向量表示,以提升推荐性能.ConvMF[18]使用CNN 从物品描述中提取物品特征.DeepCoNN[3]使用2 个平行的CNN 从用户和物品评论文档中提取语义特征,建模用户和物品的隐表示,然后将其拼接之后输入因子分解机模型去预测评分.TransNets[19]通过增加额外的转换层去推断目标用户–物品对的评论表示,扩展了DeepCoNN.由于神经网络可提取语义的优越性,这些模型获得了比传统主题模型更好的性能;但是,朴素的神经网络忽视了不同的单词或评论的有用性.因此,许多研究专注于引入注意力机制,比如,D-Attn[4]考虑不同单词的重要性,分别使用局部注意力和全局注意力去捕捉评论文档中的重要单词;NARRE[5]考虑评论集合中的不同评论有用性不同,引入评论级别的注意力来计算不同评论对用户或物品的重要性;RPRM(review properties-based recommendation model)[20]认为不同的评论属性会影响用户的信息采用过程,基于用户处理评论信息的框架学习相应评论的有用性;HUITA[11]分别在单词、句子和评论级别分别应用注意力机制,整合出了一个3 层的层级注意力框架.这些方法都是将用户和物品建模看作双塔,学习静态的用户和物品表示,没有考虑用户和物品之间文本级别的交互.为了增强评论交互,DAML[6]在文档层级,基于用户和物品评论表示的欧氏距离,添加交互注意力层学习物品和用户的相关性;ANR[8]提出了基于方面词的协同注意力网络,端到端地计算评论中不同方面的重要性;MPCN[10]采用基于指针的协同注意力网络,在上下文感知的模式下,利用指针选择机制,选择用户和物品评论最相关的评论并抽取出来;AHN(asymmetrical hierarchical network)[21]认为物品评论是围绕单一主题的同质数据,相关用户评论是关于多个主题的异构数据,可采用非对称的注意力学习用户表示和物品表示;CARL[7]使用上下文感知注意力机制,同时从评分和评论这两种信息源学习特定用户–物品对的表示;CARP(capsule network based model for rating prediction)[22]基于胶囊网络分别从评论文档提取多个用户视图和多个物品方面的不同信息;进一步地,MRCP(multi-aspect neural recommendation model with context-aware personalized)[23]基于多头网络学习多个方面的用户偏好.
文本作为辅助信号引入协同过滤框架,一些研究[24]还尝试建模文字、图网络和图片描述等特征表示,并专注于使用协同注意力建模多种模态之间的交互,优化异构特征融合,形成最终的用户表示和物品表示.此外,因为评论中包含大量的特定空间和时间的表达,研究者们也尝试抽取评论中的地理属性用于地点推荐,以及抽取评论中的时间属性增强序列推荐[16].
2 描述感知的个性化推荐系统
本章首先介绍推荐任务,然后描述本文提出的DAPR 模型.DAPR 模型结构如图1 所示,其中MLP(multi-layer perception)表示多层感知器,Cat(catenate)表示连接.框架大体结构: 对用户网络和物品网络采用分层的注意力,选择信息量大的单词和评论建模用户评论表示和物品评论表示;基于协同注意力网络,从评论描述中捕捉动态的用户偏好和物品属性,并分别用uSum 和gSum 表示.
2.1 问题定义
推荐系统的目的是根据用户的偏好去识别并推荐物品.将系统中的用户集合表示为U{u1,u2,···,uN},物品集合表示为G{g1,g2,···,gM},评分矩阵表示为RRM×N,用户对物品g的评分表示为Ru,g,其中,N、M分别表示用户和物品的数量.每一个用户u有历史评论集合du{du,1,du,2,···,du,n},每一个物品g有多个用户为它写下的评论集合dg{dg,1,dg,2,···,dg,m},其中n、m分别表示用户评论集合的数量和物品评论集合的数量.探究根据用户写下的评论准确地预测用户对未曾交互过的物品的评分,帮助用户找到最感兴趣的物品.
2.2 单词层级的个性特征选择
用户ID(identity)(uID)和物品ID(gID)是用户和物品的唯一标志,其作为一种强特征信息在推荐系统中被广泛使用.首先,映射每一个用户ID 和物品ID 到一个低维的向量表示,且作为ID 嵌入向量.用户和物品的ID 嵌入向量分别表示为
式(1)―(2)中:xu、xg分别为用户和物品的one-hot 编码向量;QRd×N、PRd×M分别是用户ID 和物品ID 的向量矩阵,其中d表示Q、P的维度.然后,将矩阵随机初始化作为用户/物品的初始表示,且在训练的过程中不断地更新ID 向量表示,以表征它们个性化的内在属性.最后,引入ID 向量到单词级别的特征选择中.
给定一条包含T个单词序列的用户文本评论du,1{w1,w2,···,wT},通过查找词向量矩阵Rd×|V|获得每个单词的词向量,得到向量序列X{e1,e2,···,eT},其中,eiRd为第i个单词的词向量,|V| 为单词表的大小,d为各自对应矩阵的维度.矩阵E可以通过Word2Vec 和Glove 等预训练词向量初始化.TextCNN[25]通过一维卷积抽取文本N-gram 的特征表示,获得语义信息,并使用CNN 从评论单词序列提取语义特征.相比于RNN 和Transformer[26]结构的模型,CNN 计算更加高效.因此,本文选用CNN 作为评论编码器.对于每个卷积核fj,第j个卷积核在第i个窗口的计算结果是
式(3)中:Wj是第j个卷积核;Xi:i+h-1表示相邻的h个单词; R eLU 表示激活函数;bj为偏差项.经过K个卷积核的计算,可以获得特征H{c1,c2,···,cK},HRT×K,其中T表示单词的长度.因为H的每一行表示单词的特征,H还可表示为H{c1,c2,···,cT}. 正如前面所述,一方面,不是所有的单词对推断评分都有用;另一方面,相同的单词对于不同的用户也有着不同的信息量.考虑用户ID 向量作为独一无二的标志携带着个性化信息,基于ID 向量可选择重要的单词预测用户偏好,本文设计了2 种捕捉特定用户特征的神经网络: 基于普通注意力机制和基于门控机制.
1)基于普通注意力机制
首先,将用户ID 向量经过一层线性变换层得到注意力的向量qwu;然后,经过普通注意力方法计算单词的注意力权重.相应公式为
式(4)―(6)中:ai和αi分别代表每条评论中第i个单词的注意力得分和注意力权重;ci代表评论中第i个单词的经过卷积后的向量表示;⊕表示拼接操作.经过权重聚合评论的单词,获得用户的第1 条评论的表示,具体为
2)基于门控机制
受门控单元在语言模型上成功应用的启发[27],本文引入用户ID 设计特定用户感知的门控单元.特别地,将用户ID 向量经过线性层变换之后的表示与词向量卷积之后的表示进行组合,通过sigmoid 函数形成门控去控制信息的传递.计算过程为
式(8)―(9)中:gj代表门控单元;bg为偏差项;cj代表卷积后的表示(H矩阵第j列);zj代表经过门控之后的表示,经过门控计算之后可获得特征矩阵H′[z1,z2,···,zK],H′RT×K;⊙表示按位相乘.经过在单词序列长度维度执行最大池化之后得到用户第1 条评论的表示,具体为
其中 m axpool 为最大池化操作.
2.3 评论层级的动态交互
当获得所有用户和物品的评论表示后,将探索怎样聚合它们去表示用户或者物品.如上所述,不同的评论对用户表示的建模贡献是不同的.同时,当用户面对不同的目标物品时,每一条评论信息的有用性也是不同的,基于不同的物品特征可能激发用户不同的兴趣.普通的池化或者平均聚合不但忽视了不同评论的重要性,还不能动态地捕捉用户的偏好.因此,本文设计了一个目标物品感知的注意力模块去学习当前用户历史评论中不同评论的重要性,以便更好地建模用户偏好表示.
式(11)―(12)中:w2和W1代表可训练的权重系数;⊕表示拼接操作;b为偏差项.将权重βi和评论向量ru,i相乘可得到权重后的评论表示du[du,1,du,2,···,du,n],最终的用户表示Xu通过聚合评论表示得到.相应公式为
其中 s um 为评论表示的加和操作.
对称地,通过将输入的评论集合替换为物品评论集合,物品描述替换为用户描述,可以获得物品的最终评论表示Xg.
2.4 基于协同注意力的用户和物品描述交互
评论摘要通常以小贴士或者吸睛标题的形式帮助用户快速做出购买决定.在深度学习中,一些研究尝试从相应的评论文档中抽取摘要形成物品描述[28].评论的摘要文本很短,含有较少的噪声,并且对物品总结的评论摘要都是围绕物品的属性写下的,话题更单一,信息密度更高.本文专注于将用户摘要拼接为长度为l1文档序列,然后查询词向量矩阵得到用户描述表示PuRh×l1,其中h表示可学习矩阵的维度.同理可得物品描述表示QgRh×l2,其中,l2为物品摘要拼接后的文档序列长度.通过计算得到关联矩阵S.相应公式为
式(14)中:WsRh×h表示可学习的权重参数;φ(·)表示激活函数.关联矩阵的每一个单元表示对应的用户描述和物品描述的相似性遵循视觉问答模型[29].将关联矩阵看作特征去计算用户描述和物品描述的单词的重要性.相应公式为
式(15)―(16)中:Mu、Mg分别表示用户描述和物品描述的单词的重要性;Wx,WyRh1×h和vx,vyRh1都是可学习的参数;wu、wg分别是用户描述中和物品描述中单词的权重系数.通过聚合计算,可得用户评论描述表示su和物品评论描述表示sg. 相应公式为
式(17)中:pj和qj分别表示用户和物品描述的第j个单词的词向量.
2.5 融合预测层
将用户的ID 向量eu和物品ID 向量eg分别看作从用户和物品评分矩阵学习的隐表示,将Xu和Xg分别看作用户和物品的评论语义特征表示,将su和sg分别看作用户和物品评论描述语义特征表示.融合这3 种不同信息源的表示可实现信息互补.因此,本文将融合这3 种特征的表示作为用户和物品的最终表示,具体为
式(18)中:Uu和Gg为最终的用户偏好和物品属性的表示向量.
本文采用隐因子模型预测评分,首先将物品表示和用户表示融合,然后输入线性转换层得到预测评分. 相应公式为
式(19)中:WfRf为预测层的权重系数;bu、bg、bo分别表示用户偏差、物品偏差和全局偏差;⊙表示按位相乘.在训练阶段,最小化标准评分和预测评分之间的均方误差为
式(20)中: |T| 表示训练的数据集大小;Ru,g表示用户对物品的真实评分.
3 实 验
3.1 数据集和实验设置
本文从Amazon 5 分数据集上选择Digital Music、Office Product、Grocery and Gourmet Food、Toys and Games 和Video Games 等5 个来自不同领域且大小规模不同的数据集.数据集包含用户从1 分到5 分的评分,并且每个用户–物品对都有相应的评分.本文对所有的数据集执行如下的操作: 删除评论中文档频率高于0.90 的单词,为每一个单词计算TF-IDF(term frequency–inverse document frequency)得分,并选择4 万个不同的单词构建词汇表;删除每条评论中所有不在词汇表中的单词;为了避免评论的长度和数量造成的长尾效应,设置评论的长度和数量能覆盖到70%的用户评论和物品评论;对于拼接的评论文档,设置固定长度为500,对于拼接的评论摘要文档设置长度为30.表1 总结了预处理后数据集的统计信息和评论设置,其中评分密度表示评分矩阵的稀疏程度.随机划分每一个数据集合的80%作为训练集,10%作为验证集,10%作为测试集,并且训练集上保证每个用户至少与物品交互过一次.

表1 5 个亚马逊数据集的信息统计Tab.1 Statistical details for five Amazon datasets
1)评估指标
为了验证本文提出的DAPR 模型的有效性,本文使用均方误差MSE(mean square error)作为评估方法,并用EMS表示.给定真实评分Ru,g和预测评分,EMS的计算公式为
其中 |Ω| 表示测试集的数量.
为了评估本文DAPR 模型的性能,本文将DAPR 与6 个常用的基于评论的推荐模型(基线模型)进行了比较.这6 个常用的基于评论的推荐模型如下.
(1)MF[9]: 是基础的矩阵分解模型,仅依赖评分矩阵学习物品和用户表示,通过点积预测评分.
(2)DeepCoNN[3]: 将用户和物品评论集合拼接成文档,使用2 个平行的CNN 从评论文档提取语义信息,采用因子分解机预测评分.
(3)D-Attn(dual attention)[4]: 整合全局注意力和局部注意力网络,同时考虑评论文档的全局和局部的信息量大的单词,捕捉更准确的语义特征.
(4)DAML[6]: 基于局部注意力捕捉局部语义信息,然后计算用户表示和物品表示之间相关性得到交互注意力权重去选择信息量大的单词,实现用户与物品之间的动态交互.
(5)MPCN[18]: 结合协同注意力技术和Gumbel-Softmax 指针技术选择相关性高的评论,并进一步采用单词级别的指针选择评论中重要的单词用作评分.
(6)NARRE[5]: 利用历史交互的ID 信息设计单词层级注意力网络学习评论的有用性.
2)超参设置
为了公平比较,本文对所有模型执行相同的预处理过程: 设定词向量的维度为300,并且选择Glove 作为预训练词向量;ID 的嵌入向量维度设置为32;卷积核的个数设置为32,在[16,32,64]的范围内调节,卷积的窗口设置为3;注意力网络的隐藏层维度设置为32;最终用户和物品的表示维度设置为32,在[16,32,64]的范围内调节.对于D-Attn 和DAML,设置批量大小为32;对于MPCN,设置指针数量为4,其他所有模型批量大小设置为128.采用dropout 缓解过拟合问题,设置dropout 的丢失率为0.3.采用Adam 优化策略优化模型,学习率设为0.001,权重衰减设为0.000 1.设置模型的最大训练周期(epoch)为20,当连续6 个epoch 模型性能没有提升时,停止训练.
3.2 实验结果比较
表2 展现了本文提出的DAPR 模型和基线模型的MSE 比较结果,可以发现: 基于评论文本的模型DeepCoNN 和NARRE 等都显著好于仅依赖于评分数据的模型MF,这说明评论包含的语义特征有助于预测评分;并且使用注意力网络的模型D-Attn 和NARRE 比没有注意力的DeepCoNN 表现更好,表明注意力机制可以关注到信息量大的单词和评论;MPCN 在所有的数据集上的表现都很不稳定,可能是因为使用每次选择特定数量评论过滤了太多评论信息,并且动态选择给模型增加l 了不确定性;DAML 获得比DeepCoNN 和D-Attn 更大的提升,证明动态注意力网络捕捉动态的用户偏好和物品属性有助于推荐性能提升;使用评论文档的方法DeepCoNN、D-Attn 和DAML 在较大的数据集Toys and Games 和Video Games 上的表现相对较差,表明在大的数据集上,采用基于文档的方法会引入较多噪声和不相关信息.
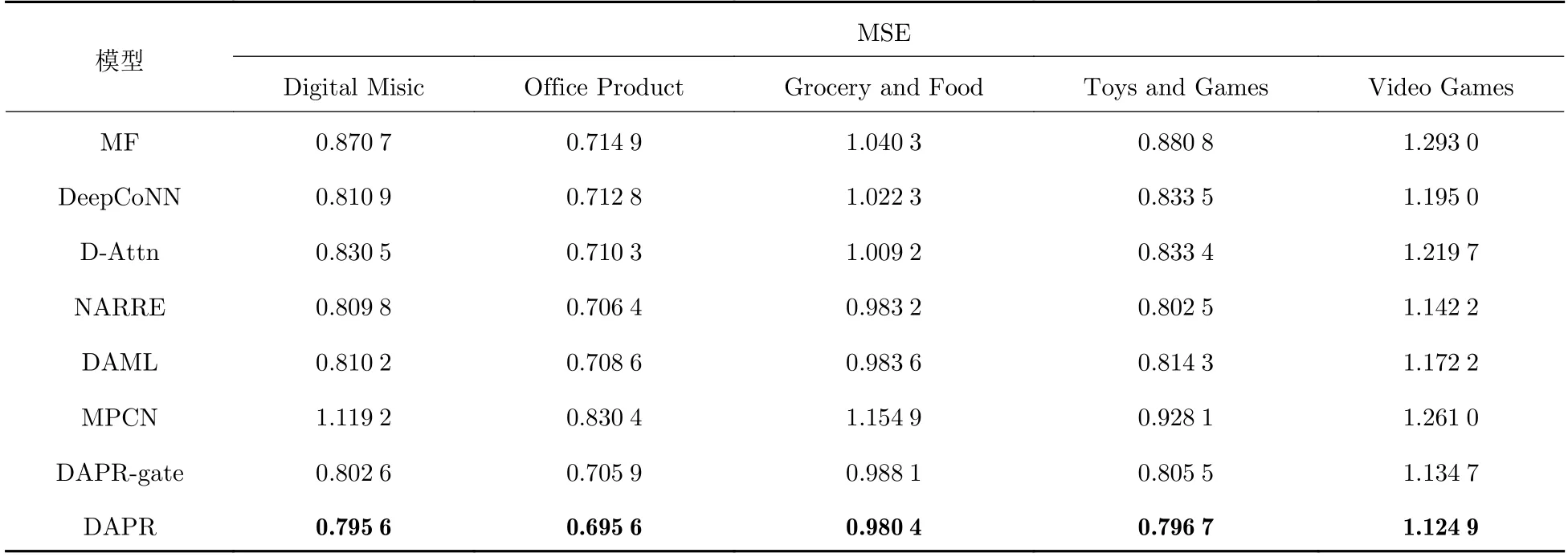
表2 DAPR 模型和基线模型的MSE 比较Tab.2 MSE comparison of DAPR and baseline models
本文提出的DAPR 模型在5 个数据集上取得了最好的结果,与当下最优的基线模型NARRE 相比,取得了0.29%(Grocery and Food)到1.75%(Video Games)范围的提升.尽管NARRE 采用了注意力机制关注于重要的评论,但DAPR 采用分层的注意力网络,能更详细建模用户和物品.DAPR 显著好于动态建模的DAML 和MPCN,说明本文在评论上采用交叉注意力模块、在评论摘要上的协同注意力模块能更好获得用户和物品的表示.DAPR-gate 为在单词级别使用门控选择重要信息的模型,同样取得了小幅度的提升,证明引入ID 控制单词层级的信息流动可以提取更丰富的语义信息.
3.3 有效性实验分析
3.3.1 DAPR 模型不同模块的有效性
DAPR 模型主要由单词级别注意力、评论级别注意力和基于描述的协同注意力这3 部分组成.为了验证模型方法的有效性,本文分别将模块消除或者换为可替代模型方法探究相应模块的有效性.消融结果如表3 所示,其中,Base 模型在单词和评论的聚合中均采用maxpool 方式;Base+Ave 模型对单词和评论采用平均聚合;DAPR-WA 表示DAPR 模型不使用单词级别注意力,将卷积之后的隐藏表示平均聚合得到用户评论;DAPR-RA 表示模式不使用评论级别注意力,平均聚合评论获得用户表示;DAPR-Co 表示不使用评论描述的交互注意力.
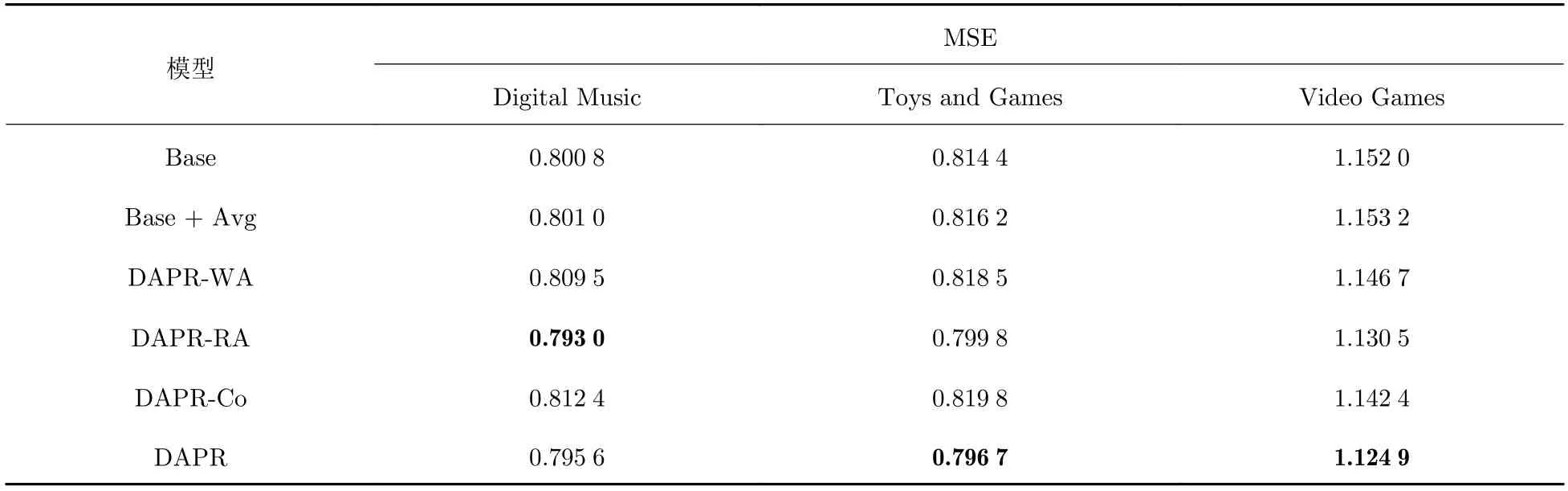
表3 DAPR 模型消融实验的MSE 结果Tab.3 MSE results of ablation experiments with DAPR model
实验结果表明,采用平均聚合和最大池化聚合,结果没有显著区别.DAPR-WA 和DAPR-RA 消除个性化机制之后,模型性能下降,表明引入单词注意力和评论注意力模块均能一定程度提升模型性能,其中,在数据集Digital Music 上,DAPR 性能差于DAPR-RA,这可能是应用于评论的交叉注意力在小数据集上不稳定所导致的.当移除描述的协同注意力网络时,模型性能显著下降,表明整合上下文感知的动态偏好可帮助更好的建模用户偏好和物品属性.
3.3.2 不同预测模块的有效性
在之前的研究中,不同的模型使用不同的方法进行预测,其中,DeepCoNN 和MPCN 采用FM 作为预测层,DAML 和NARRE 使用修改的LFM(latent factor model)作为预测层,MF 和D-Attn 采用点积预测评分.分别修改DAPR 的预测层模型为点乘和FM,探究不同预测层对实验结果的影响,结果如表4 所示.

表4 DAPR 采用不同预测层的MSE 结果Tab.4 MSE results of different prediction layers of DAPR
表4 结果表明,不同的预测层对模型的影响差异非常大,点乘的方法(Dot)显著低于FM 和LFM 的表现;注意到FM 建模二阶的特征交互,在数据集Digital Music 和数据集Toys and Games 上均表现不好,DAPR 在文本阶段已经完成交互,高层的特征交互增加了模型的复杂度,不能进一步提升性能,甚至损害模型性能;DAPR-LFM 为本文采用了预测层,表现性能最好.
4 总结
本文提出了一种分层级描述感知的推荐算法DAPR,在捕捉特定的个性化特征的同时,兼顾捕捉动态的用户偏好和物品属性.在单词层级,因为不同的单词有不同的重要性,设计了ID 引导的注意力网络选择信息量大且具有个性化的单词;在评论层级,注意到用户对不同物品展示出不同的兴趣,设计了交叉注意力网络动态地学习物品表示和用户表示;此外,引入评论摘要作为客观描述信息,设计了协同注意力网络以捕捉用户和物品描述之间的相关性,进一步捕捉用户动态的偏好;最后,将评分特征、动态的评论特征和动态的描述特征融合,预测评分.在5 个数据集上的实验结果证明了本文所提方法可以提升推荐性能.
