面向高冲突事务处理的架构设计和优化
2023-11-29连薛超王清帅
连薛超,刘 维,王清帅,张 蓉
(1.华东师范大学 数据科学与工程学院,上海 200062;2.工业和信息化部电子第五研究所,广州 511300)
0 引 言
从NoSQL到NewSQL[1],分布式数据库虽然取得了长足的进展,在解决事务一致性和可扩展性上都有很大的进步,但是还存在着一些尚未解决的问题,当前分布式数据库的吞吐主要被3 个因素限制:①消息传递的额外开支;② 网络的带宽;③资源竞争[2].
远程直接数据存取(remote direct memory access,RDMA)技术可以缓解消息传递的额外开支和网络的带宽[3].但是,RDMA 技术尚未被大规模运用.在一般的分布式场景下,消息延迟比单机场景的延迟要长得多,进一步增大了冲突的概率.例如,以太网中单次小消息传递的延迟约为 35 μs,不考虑磁盘和网络延迟的情况下,事务的延迟为 10~ 60 μs[4-5],网络延迟已经成了短事务延迟的主要瓶颈,而短事务又是联机事务处理(online transactional processing,OLTP)的主要类型之一.长消息延迟恶化了分布式数据库的冲突,已经有研究指出,事务的冲突概率和访问单个记录的延迟成指数级关系[2].一方面,当负载的冲突很大的时候,系统中大量的事务最终都会回滚,在无效的操作上浪费了大量的资源.另一方面,由于大量事务都在竞争同一数据项,花费在等待资源上的时间也会变长.两个因素共同作用,导致整个系统在高冲突负载下较差的性能.
对于目前流行的无共享架构而言,在逻辑上,往往有一个无状态的事务组件层用于计算,另一个数据组件层用于存储数据和事务状态[6],如TiDB[7],CockroachDB[8],Spanner[9],FoundationDB[10]等.这样的架构,在高冲突的场景下,可能由于检测冲突的时间太长导致高冲突,进而导致低吞吐.例如,对于乐观的并发控制协议Percolator[11]来说,事务在提交和读取数据时需要在存储层检测冲突,而在那之前事务可能已经进行了多次网络 I/O(input/output),这样就造成,实际发生冲突的时间和检测到冲突的时间被拉长.
为了解决这个问题,本文基于 FoundationDB 的事务处理架构,设计了一套面向高冲突的事务处理系统原型,通过定期从存储事务状态的节点获取冲突信息,在发生高冲突现象时,收集高冲突数据集.监视节点会根据高冲突数据集改变整个集群的事务策略,同时选定一个计算节点作为后续处理高冲突事务的计算节点,实现了对冲突的有效检测.在高冲突的事务策略中,采用了类似MOCC(mostly-optimistic concurrency control)[12]的乐观事务模型结合悲观事务模型的方式进行处理,可以提前检测到事务的冲突,缩短了浪费在消息延迟上的时间.同时由于高冲突事务都被放在了一个节点,本文采用了更激进的缓存策略来改善读操作的延迟.实验证明,本文所提出的这套框架可以有效缓解计算节点无状态的分布式数据库系统在高冲突情况下的性能问题.
1 相关工作
FoundationDB[10]是一款开源的事务键值存储系统,它采用了乐观的并发控制协议,是 Apple,Snowflake 等公司云基础架构的重要组成部分.和很多无共享架构的数据库一样,因为计算节点无状态,所以在高冲突的情况下,吞吐和延迟会受到更多的影响.事务模型分为乐观的事务模型和悲观的事务模型:乐观的事务模型在获取资源前无需获取锁,通过事务提交之前的验证来保证事务隔离级别的正确性;悲观的事务模型在获取资源前需要获取锁,一般通过二阶段锁(two-phase locking,2PL)等并发控制协议来保证事务隔离级别的正确性.其他无共享架构的数据库,有些采用了乐观的事务模型,如v3.08 之前的TiDB[7](TiDB 在v3.08 之后也支持了悲观的事务模型)、CockroachDB[8];有些则采用了悲观的事务模型,如 Spanner[9]等.这些架构的数据库都有着类似的问题,面对高冲突负载,无状态的计算节点,导致冲突检测的链路过长,从而造成更差的性能.
在单机数据库中,已经有很多的方法尝试解决高冲突的问题.对于乐观的事务处理来说,MOCC[12]针对热点键值采用预先加锁的方式避免一些不必要的回滚,为了解决加锁时可能导致的死锁问题,使用了一种非2PL 的加锁方式来按照键值大小获取锁,不符合加锁顺序的锁就释放掉.对于悲观的事务处理,Bamboo[13]通过提前释放锁来缩短持有锁的时间,为了解决读取脏数据可能会导致的级联回滚问题,Bamboo 记录了读脏数据时的依赖信息.IC3[14]也是一种悲观事务处理的协议,它对事务进行静态分析,将事务分割为原子的子事务,每一个子事务完成后,子事务的更新就变得可见,通过这种方式让事务获得了更多的并发度.
在分布式数据库的事务处理中,也有不少试图解决高冲突问题的方法.Calvin[15]采用了确定性并发控制的方式从源头上消除了冲突,为锁请求进行了一个全局的定序.DLV(distributed lock violation)[16]对二阶段锁加二阶段提交(2PL+two-phase commit,2PC)的分布式事务,采用了类似于 Bamboo的提前释放锁的做法,将这一点应用在了分布式的环境下,并对释放锁的时机进行了更细的区分.Chiller[3]则是一个以事务分区的方式来解决2PL+2PC 的高冲突问题的架构,对事务日志进行静态分析后,对事务内的一部分操作进行重排序,通过这样的分区工具来重新分区,让涉及高冲突记录的锁被放在同一个分区内,从而使之可以提前释放.
2 高冲突情况下无共享架构数据库面临的问题
本章以TiDB[7]为例介绍当前无共享架构数据库在高冲突情况下普遍面临的问题.TiDB 的架构分为计算节点 TiDB 和存储节点 TiKV,其并发控制协议是基于 Percolator[11]的.Percolator 的事务分为执行和提交两个阶段: 在执行阶段,所有的写入都保存在本地;在提交阶段,先进行预写入,将之前本地写入的记录所对应的锁写入存储,并选择一个写入操作作为主键,用来保证原子性,所有的预写入都完成以后,再对主键进行提交.冲突的检测仅发生在事务执行阶段中的读取操作和事务提交阶段的预写入操作,s是事务的开始时间戳,c是事务的结束时间戳.
当进行读取操作时,事务会检查 TiKV 上是否已经写入了[0,s]的锁,如果存在这样的锁,就会尝试清除这个锁;如果清除失败,事务就会回滚.
当进行预写入操作时,事务会检查 TiKV 上是否已经存在c[s,+∞)的提交数据以及是否已经存在任意时间戳写入,即c或者s属于[0,+∞)的锁.
然而在发生冲突之前可能已经发生了多次远程过程调用(remote procedure call,RPC)(每访问一次 TiKV 都是一次 RPC),而这么多 RPC 的时延是不可忽略的,也就是说,事务从执行到检测冲突的链路是很长的.
如图1 所示,假设有两个事务分别为事务1 和事务2,它们可能在同一个TiDB 节点,也可能不在同一个 TiDB 节点,这两个事务均会读取和写入一个相同的记录x.事务1 已经完成了执行阶段和预写入操作,正在执行提交操作;事务2 已经完成了执行阶段,正在进行预写入操作,但是在预写入时,它会发现x这个记录已经被事务1 上锁,由于发生了冲突,事务2 就会回滚.事务2 在回滚之前,该事务已经进行了两轮 RPC,一轮是读取x这个记录,一轮是预写入.
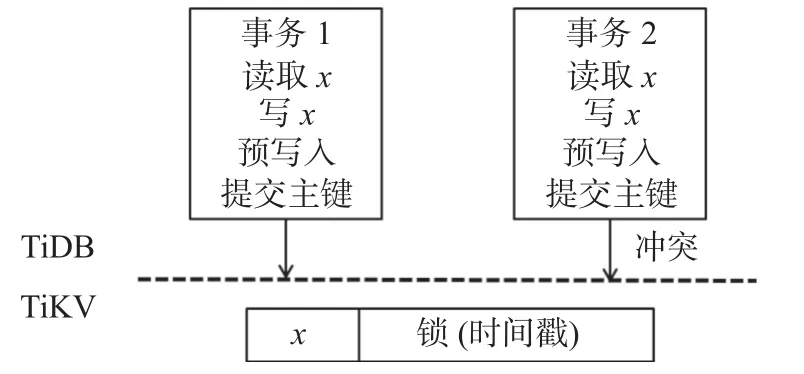
图1 TiDB 的事务冲突示例Fig.1 Example of TiDB transaction conflict
每个事务读取的记录数量有限,可以预料到的是,在高冲突和读取更多记录的情况下,会有更多的事务受到影响,更多的资源被浪费.如果有办法能够提前在计算层就检测到冲突,根据检测到的冲突,提前对会回滚的事务进行回滚,就可以有效降低时延并提高系统的吞吐.
3 高冲突处理架构
本文设计的高冲突处理架构由两部分组成: 第一部分是高冲突检测,负责检测高冲突并启动高冲突处理;第二部分是高冲突处理,负责对高冲突事务的处理.这个架构在本文开发的原型系统中进行验证,下面按照原型系统的架构、高冲突检测、高冲突处理策略3 个小节来介绍本文的工作.
3.1 原型系统的架构
本文基于 FoundationDB[10]实现了一个高冲突处理架构的原型系统.FoundationDB 在属于无共享架构的前提下有着更小的代码量,模块复杂度低,便于进行技术验证和原型系统开发.在实现上,使用了FoundationDB 的协程框架flow 和网络通信框架fdbrpc,参考了 FoundationDB 的并发控制协议和整体架构,因为本文主要关注的是分布式数据库的高冲突问题,所以去掉了其中的持久化和高可用部分,这一点和文献[17]类似.原型系统架构如图2 所示.整体架构分为两层: 第一层是计算层,其中的事务处理节点负责与客户端交互.冲突检测节点按照访问的键范围进行分区,负责检测事务的冲突.第二层是存储层,其中的存储节点也按照访问的键范围进行分区,负责处理读请求.控制节点负责时间戳的分发,集群的初始化,控制事务处理策略等任务.本文的主要贡献在图2 中红色区域的两个模块,其余部分主要是参考FoundationDB 而来,为了减少不必要的工作量,对FoundationDB 的设计进行了一定的简化.
当客户端发起一个请求以后,客户端会从控制节点或者本地缓存里获取集群信息,选择一个事务处理节点作为交互的节点,发送事务 ID 和参数.事务处理节点收到事务 ID 和参数以后,就启动一个协程服务这个事务,这样一个事务的生命周期就开始了,每个事务从开始到提交的生命周期如下所示,并与图2 对应.
(1)事务处理节点从控制节点处获取读时间戳.
(2)执行事务: ①读操作根据读时间戳从所对应的存储节点读取数据;② 写操作暂时先保存在本地的缓冲区中.
(3)提交事务: ①事务处理节点从控制节点处获取写时间戳;② 将事务的读写集发送到冲突检测节点处检测冲突,如果有其他事务修改了本事务读取的值,那么就会回滚,如果没有回滚,就会更新冲突检测节点处键值的写时间戳为当前事务的写时间戳;③确认所有的冲突检测节点均已提交以后,发送当前事务的日志给对应存储节点,等待存储节点完成日志的应用后,事务提交.
FoundationDB 的并发控制协议还要求,存储节点和日志节点严格按照时间戳顺序处理事务,前一个事务没有完成,后一个事务就不能启动,因此 FoundationDB 只有读写冲突而没有写写冲突.本文也参照 FoundationDB 实现了类似的机制.
3.2 高冲突检测
冲突检测节点使用跳表来保存键范围到写时间戳的映射.用跳表的上层节点会保存下层节点写时间戳的最大值,用这样的方式,可以更快地检测冲突.同时,为了减少不必要的网络 I/O,每次的事务冲突检测都是用批的方式完成.
高冲突检测包含了两个问题: 第一个问题是检测并发现系统当前处于高冲突状态;第二个问题是收集高冲突的数据项集合.对于第一个问题,检测事务的回滚率即可,事务的回滚率可以直接从事务处理节点得到,但是事务处理节点无法得到高冲突的数据项集合,因而需要从冲突检测节点处检测高冲突并在一小段时间内收集高冲突的数据项集合.对于冲突检测节点来说,时刻维护一个高冲突的数据项集合,对内存和中央处理器(central processing unit,CPU)资源的消耗无疑都比较高,因此,本文选择了和 E-Store[17]类似的做法,只在回滚率达到一定阈值时,才会启动记录高冲突的数据项.为了防止假阳性(即实际上只有很少的事务),本文也同时限制了事务负载载荷的下限阈值.
在启动高冲突检测以后,冲突检测节点内的跳表就会在进行检测冲突时发送当前产生冲突的键给后台协程,后台协程在收集完毕以后,取占据访问热度一定比例的键作为高冲突数据项集合,即
式中:Ak表示采样时间内某个键的访问频数;K表示采样时间内所有键的集合;H表示高冲突数据项的集合.本文在根据采样时间内访问频数排序的键中选择排序靠前的键,使得H的访问频数占数据库总访问频数的比例超过阈值λ.确定H的方式为: 先将所有的键按照采样时间内访问频数从高到低进行排序,再从高到低依次选择键加入H,直到H中键的访问频数之和占所有键访问频数之和的比例大于或等于λ.本文设置λ为采样时间内的回滚率P与触发收集高冲突数据项回滚率的阈值θ的差值,即λP-θ.这样设置λ的原因是: 第一,随着P的增大,λ也会增大,这样在冲突更高时,可以确保将高冲突数据项都收集到H中;第二,P减去θ以后,可以避免H中包含一些较低冲突的键,减少对非高冲突负载的影响.通过设置θ,系统可以在有效处理高冲突负载和避免对非高冲突负载影响之间取得一个平衡,经过测试,本文将θ设置为0.05.
冲突检测节点会每隔一段时间发送一个高冲突状态请求给控制节点,里面包含了当前的高冲突数据项集合,直到高冲突现象被消除.为了避免不必要的重复发送,本文设计了一个简单的机制,比较每次高冲突数据项集合的数量变化,如果数量变化大于一定的阈值,该机制就会发送新的高冲突数据项集合给控制节点;否则,就不发送.
3.3 高冲突处理策略
整个系统的并发控制会有两种策略: 一个是高冲突处理策略;一个是正常策略.当使用高冲突处理策略时,控制节点会随机选取一个事务处理节点,作为高冲突处理节点,控制节点随后将所有的高冲突事务都交给这个高冲突处理节点处理,这样就可以在这个事务处理节点进行预先加锁和本地缓存等操作.
如图3 所示,控制节点在收到冲突检测节点发来的高冲突状态请求以后,会对内部的全局变量S加 1,系统通过S来识别当前的并发控制是高冲突处理策略还是正常策略.在对内部的S加1 以后,控制节点会向所有的事务处理节点请求更新事务处理节点处的S,控制节点完成这个过程以后,本次的状态就改变完毕.客户端也会维护一个S,当客户端向事务处理节点发送请求时,客户端的S可能已经过期,这时就需要从控制节点处更新S并获取可能需要的高冲突数据项集合.从高冲突状态变回低冲突状态也是类似的,操作变为从事务处理节点发送请求,因为事务处理节点可以知道当前有多少个事务命中了高冲突数据项集合,当事务命中高冲突数据项集合的数量低于一定阈值以后,就可以向控制节点发送请求,改变系统的并发控制策略.
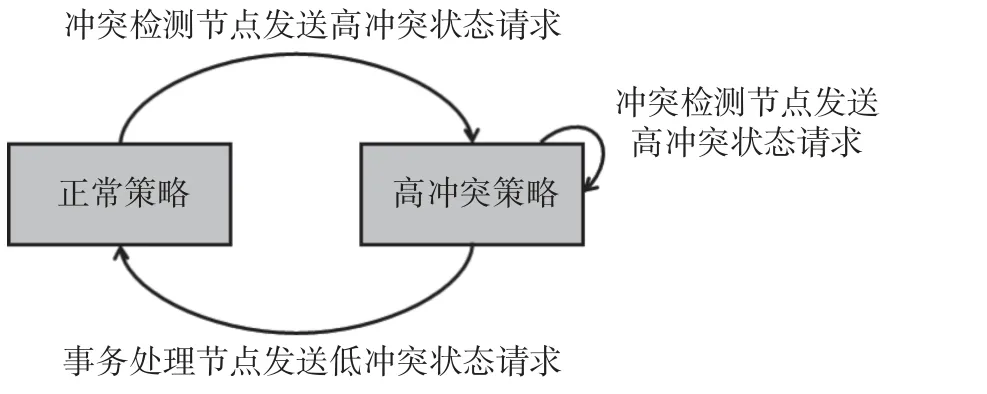
图3 状态变化Fig.3 State transition diagram
3.3.1 预先加锁
事务处理节点会区分高冲突事务和普通事务,对于高冲突事务,在正常的执行流程之外,还额外增加了预处理的流程.预处理的流程和 MOCC[12]类似,都是提前加锁,读锁在事务执行阶段就获取,而写锁要等到提交阶段才会获取.第一个不同之处是,本文的设计,只允许写者等待读者,而不允许读者等待写者.这一点是因为,当事务1 读到了事务2 正在获取写锁的记录时,事务1 的读时间戳一定比事务2 的写时间戳要小,那么事务1 在后续冲突检测节点验证时就一定会回滚,因此无须等待事务1 完成.第二个不同之处是,本文的设计还限制了同一时间允许获取同一记录读锁的数量,以免产生锁颠簸的现象,这一点和 MySQL 里的批最大依赖集优先算法[18]类似,如算法1 所示.

第三个不同之处是,MOCC[12]为了解决死锁的问题,会在加锁时,直接释放掉不符合加锁顺序的锁.在本文的设计里,仅仅在获取写锁时才会触发这个机制,读和读之间是不会发生冲突的,读和写会发生的冲突,如算法2 所示.由于加锁机制不允许读者等待写者,冲突的依赖只可能是写指向读的.获取新的读锁不会引发死锁,可以在获取读锁时,保留不符合加锁顺序的锁.

3.3.2 本地缓存
除了预先加锁之外,高冲突处理节点还可以维护一个本地缓存,在事务处理节点缓存所有高冲突数据项.为了便于实现,本文采用了写穿透策略,即同步写入远程存储和本地缓存,当事务提交时,不仅需要提交到远程存储,而且需要写入本地缓存.并发控制策略变换前后可能会导致最近的更新写入了旧的本地缓存中,为了保证写入和读取本地缓存在并发控制策略变换前后的缓存一致性,本文还在本地缓存和事务的数据结构中也维护了S,分别用于标记本地缓存创建时的S和每个事务在开始执行前记录当前事务处理节点的S.当高冲突处理节点的事务在尝试读取本地缓存时,可能会发现自己的S和本地缓存的S不一致,那么就不会读取本地缓存中的数据.同时,对于已经读取了之前本地缓存,但尚未完成执行或提交的事务,高冲突处理节点会在提交时检查该事务读取本地缓存的S,如果和本地缓存记录的S不一致,事务就会回滚.
3.3.3 客户端路由策略
客户端在将事务路由到不同的处理节点时,会使用两种不同的路由策略.第一种路由策略是非高冲突的路由策略,在这种路由策略下,客户端在发送事务时按照均匀分布随机将事务发送给一个事务处理节点.第二种路由策略是高冲突路由策略,当客户端使用高冲突路由策略时,会根据事务 ID 和事务的输入来确定事务是否可能访问高冲突数据项,如果有可能访问到,那么客户端就发送一个高冲突事务请求给所对应的高冲突处理节点,非高冲突事务则会随机均匀发送到事务处理节点中.为了负载均衡,客户端还会减少发送到高冲突事务处理节点的非高冲突事务.需要注意的是,当前客户端确定一个事务是否为高冲突事务的方法是较为简单的,即根据事务的参数来计算访问集,判断这些键是否属于高冲突的数据项集合,进而判断该事务是否属于高冲突事务.对于一些无法通过计算来得到访问集的事务,目前还无法处理,未来可以考虑通过对事务日志进行机器学习等方式来计算事务的访问集.
4 实验分析
4.1 集群环境及测试负载
(1)集群环境.本系统部署在 6 个节点上,其中 3 个节点的配置为 4vCPU 16 GB 的内存,CPU型号为 Intel Xeon Platinum(Cooper Lake)8369;另外 3 个节点的配置为 4vCPU 8 GB,CPU 型号为Intel Xeon(Ice Lake)Platinum 8369B.3 个存储节点分别部署在 3个4vCPU 16 GB 节点上,3 个冲突检测节点均部署在 1个4vCPU 8 GB 的节点上,3 个事务处理节点和 1 个控制节点均部署在 1 个4vCPU 8 GB 的节点上,客户端部署在 1个4vCPU 8 GB 节点上.集群环境将存储节点和事务处理节点分开,以模拟无共享架构数据库里计算节点到存储节点的网络开销.为了模拟无共享架构分布式数据库冲突检测链路过长的问题,将事务处理节点和冲突检测节点也部署在不同的机器上.为了避免客户端对系统造成影响,客户端被单独部署在一个机器上.
(2)测试负载.本实验的测试负载为The Yahoo! Cloud Serving Benchmark(YCSB)[19],YCSB 是一套由互联网公司开发的模拟大规模服务的负载,本文采用YCSB 的理由是YCSB 事务结构简单,可以更直接地观测高冲突事务对系统的影响,其他事务负载,如TPC-C,可能会有更多复杂因素(如算子的执行效率等)影响实验的结果,给解释实验现象与冲突处理方案的关系造成困难.本文实现了YCSB 的评测标准,为了满足测试高冲突负载的需求,本文对负载进行了改造,在实验里所使用的事务负载包含10 条结构化查询语句(structured query language,SQL),每条SQL 语句有均等的概率成为一个简单的读操作或者更新操作,更新操作会更新对应键的值为相同长度的新值,所有 SQL 语句访问的记录均按照相同的分布产生.实验加载了 50 万条数据,每条数据包含 10 个列,每个列的长度为1 000 个字节.冲突检测节点和存储节点均按照键范围均匀分割所有的键.本文通过改变负载的偏斜来模拟高冲突负载,采用Zipf 分布来模拟数据的偏斜,Zipf 参数越大,负载的冲突强度就越大.
4.2 高冲突处理策略的有效性
本节通过实验检验高冲突处理策略的有效性,YCSB 负载的Zipf 参数从0.50 到1.05 之间变化,实验结果如图4 所示,所有的实验数据为负载稳定后1 min 的平均值.一般来说,Zipf 参数大于0.70 就可以被认为是高冲突的负载.Zipf 参数大于0.70 的实验结果显示本文设计的高冲突处理策略对吞吐率都有一定的提升,当Zipf 参数为1.05 时,吞吐相对基线的比例最多提升了84%;当Zipf 参数小于等于0.70 时,启用了高冲突处理策略的实验组和基线的实验组相比则几乎没有差别.

图4 高冲突处理策略的有效性Fig.4 High-contention-strategy effectiveness
对实验结果进一步分析,可以发现,预先加锁对吞吐的提升有一个先升后降的趋势,大约当Zipf 参数为0.90 时,达到峰值,这一现象是由于目前将所有的高冲突事务都交给一个事务处理节点处理,随着冲突的升高,高冲突事务的量也随之增大.可能由于冲突的不断增强,导致高冲突事务处理节点成为新的瓶颈.本地缓存对吞吐的提升则是在Zipf 参数为 0.90 时达到低谷,随后又随着冲突的升高而增大.这个低谷的出现可能是由于预先加锁会提前回滚掉一些事务,这些提前被回滚的事务就会执行更少的读操作,随着预先加锁效果的提升,提前回滚的事务的量也会增大,这些提前被回滚的事务会执行更少的读操作,那么由于本地缓存带来的性能提升就会逐渐降低.当Zipf 参数大于0.90 时,随着 Zipf 参数的增大,高冲突事务的量也不断增大,尽管预先加锁回滚了一些事务,仍然有更多事务的读操作需要经过本地缓存读取,促进本地缓存的性能也随之提升.
4.3 高冲突检测的有效性
为了检验高冲突检测的有效性,本文设计了本节实验来验证高冲突检测模块的有效性.首先在0 至20 s 执行的均匀分布负载,然后在20 至40 s 执行 Zipf 参数为0.99 的高冲突负载,最后在40 至60 s 执行均匀分布负载,实验结果如图5 所示.
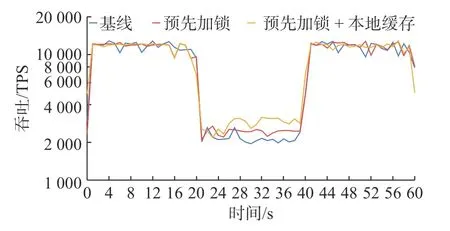
图5 高冲突检测的有效性Fig.5 High-contention-detection effectiveness
对实验结果进行分析,可以发现,在第20 秒加入了高冲突负载以后,如果不考虑第27 秒出现的异常(这一异常应该是由正常的网络抖动和协程的不确定性导致的,3 种对比方法都会出现类似的抖动),对于预先加锁来说,在第23 秒时就已经获得了比基线更好的吞吐,在第26 秒左右达到约为2 400 TPS的稳定吞吐,比基线高约20%.如果额外开启了本地缓存,在第24 秒时取得了比基线更好的吞吐,同时在第 27 秒左右达到了约为2 900 TPS 的稳定吞吐,比基线高约45%.因此,高冲突策略从检测冲突到生效的时延为3~ 4 s,而达到稳定吞吐所需的时间为6~ 7 s.这说明,本文设计的高冲突检测模块,可以在较短的时间内检测出冲突,并启动高冲突策略.
4.4 预先加锁对回滚事务延迟的影响
在4.3 节中,预先加锁的原理是提前回滚掉一些可能会产生冲突的事务,进而达到提高吞吐的效果.本节通过实验验证这一结论,YCSB的Zipf 参数在 0.50到1.05 之间变化,统计回滚事务从开始到执行失败的平均延迟,实验结果如图6 所示.
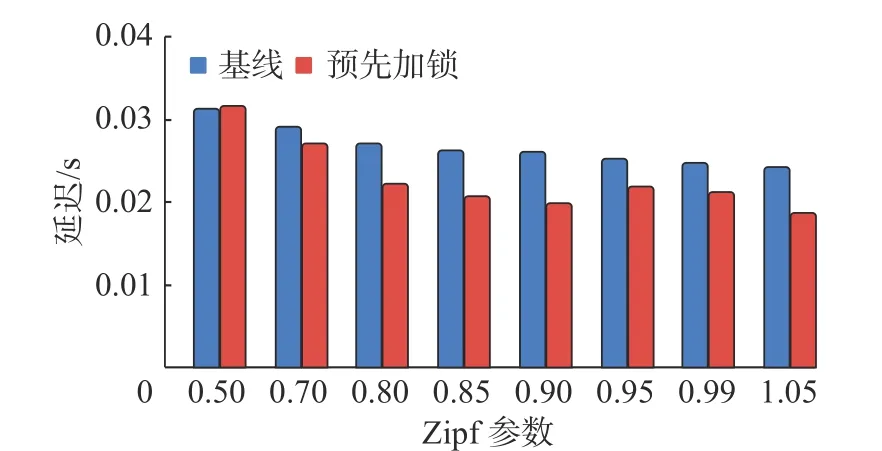
图6 预先加锁对回滚事务延迟的影响Fig.6 Effects of pre-locking on abort transaction latency
可以发现当Zipf 参数大于等于0.80 时,回滚事务的延迟都有一定的下降,延迟降低最大的值是24%,预先加锁的吞吐相比基线的吞吐更好,这说明了预先加锁策略可以有效缩短回滚事务的延迟,进而增大系统整体的吞吐.
4.5 本地缓存对读操作延迟的影响
本节实验在 Zipf 参数为 0.70 到1.05 的条件下进行,分别统计稳定以后单个读操作通过 RPC 返回的延迟和通过本地缓存返回的延迟,实验结果如图7 所示.当Zipf 参数大于等于0.85 时,本地缓存读的延迟均在通过RPC 返回延迟的12%以内,这一点说明了本地缓存可以有效缩短读操作的延迟.同时,如图4 所示,和单纯的预先加锁相比,本地缓存对于系统的吞吐有一定提升,这说明了本地缓存可以缩短高冲突数据项的延迟,进而提升系统的吞吐.当Zipf 参数为0.70 和0.80 时,出现了一些延迟很高的异常点,使得本地缓存读的延迟相较于远程读并无明显优势,这一现象应该是由于当Zipf 参数较小时,冲突强度不大,大量算力用于执行非高冲突事务,导致对本地缓存的更新操作无法及时同步,进而导致本地缓存的读操作被阻塞.
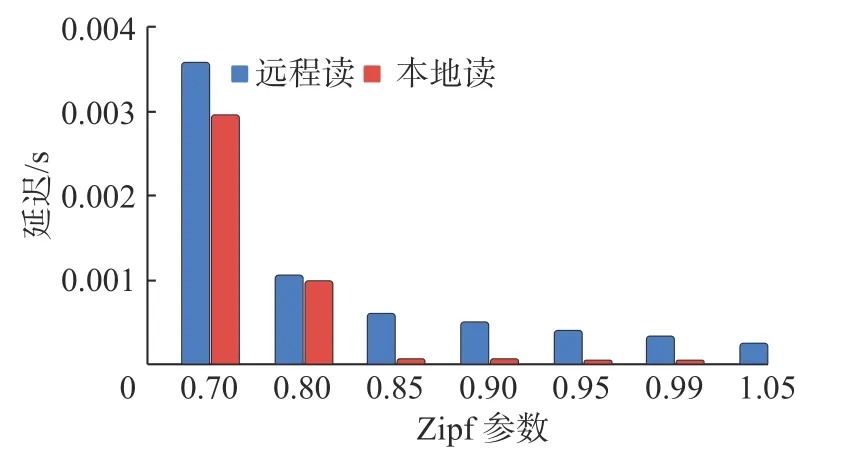
图7 本地缓存对读操作延迟的影响Fig.7 Local cache effect on read operation latency
5 结 语
本文提出了无共享架构数据库由于冲突检测链路过长在高冲突负载下可能会成为系统瓶颈的问题,针对这一问题,设计并实现了一套冲突检测与高冲突处理的框架,针对分布式数据库在高冲突负载下可能出现的性能瓶颈,本文提出了包含两个高冲突处理的策略: 一是用预先加锁来提前对一些高冲突事务进行回滚,从而缩短了冲突检测链路的长度;二是用本地缓存来缩短高冲突数据项的读操作延迟,避免了高冲突数据项频繁RPC 对性能的影响.为了检测冲突,本文设计了高冲突检测模块,可以快速发现冲突并应用高冲突处理策略.在策略上的主要创新在于,首次将MOCC 的这一套预先加锁方案应用于分布式数据库领域,适配了原型系统的并发控制协议,并加入了本地缓存等策略.通过实验证明,本文所提出的高冲突处理原型系统架构,可以有效改善高冲突负载下系统的性能.
本文工作还存在一些尚未探讨的问题,如选取事务处理节点时是否可以考虑负载均衡以达到更好的效果.在分布式数据库领域,负载均衡一直是一个很热的研究话题,大量研究工作试图在系统运行过程中完成实时调度.本文的处理方法可以和现有的负载均衡技术相结合,达到更好的效果.又如当选择高冲突处理节点时,仅选择了一个事务处理节点,该节点可能就会成为新的瓶颈.将高冲突数据项分散到多个事务处理节点,可以改善系统的可扩展性,随之而来的分布式事务开销也是不可忽略的,这就需要在分布式事务和负载均衡之间取得一个平衡,很多工作都是针对这一问题展开的,本文的处理方法可以和现有的相关工作结合,以达到更好的效果.
