RFNet: 用于三维点云分类的卷积神经网络
2023-11-28单铉洋孙战里曾志刚
单铉洋 孙战里 曾志刚
近年来,随着自动驾驶仪、高精度地图、智慧城市等新概念的出现,许多应用场景都需要基于点云的3D 环境感知和交互.三维扫描技术和深度摄像机的快速发展,使得点云的获取更加简单方便,在三维数据深度学习领域,点云逐渐成为一种流行的三维数据表达方式[1].但与二维图像不同,由于采样不均匀、传感器精度等因素,点云在空间上是高度稀疏无序的.因此,如何用深度学习的方式处理点云数据,成为一个关键的问题[2].
由于卷积神经网络(Convolutional neural network,CNN)方法在图片处理上有着广泛且成熟的应用,而点云并不是像图片一样规则排列的,因此许多工作都是先对点云进行预处理,将点云数据转化为规则的数据,然后再使用传统的CNN 方法[3].根据神经网络输入数据类型的不同,现有的点云分类方法可以分为多视图法、体素法和基于点的方法3 种[4].多视图法是将三维点云数据从不同角度投影到二维平面上,然后再对二维平面图做二维卷积[5-7].但由于存在遮挡问题,在三维向二维投影的过程中,会导致三维点云中固有信息的大量丢失.体素法是通过将点云转化为规则的三维网格,在三维网格上使用卷积神经网络[8-9].但这种方法受到分辨率的限制,低分辨率训练速度快,但会造成点云信息的大量丢失;高分辨率形状描述能力强,但同时也会让空间复杂度大幅度提高.
基于点的方法是将直接点云的三维坐标(x,y,z)作为输入,对坐标进行卷积.PointNet[3]是这条路线的先驱.为克服点云无序性而直接处理点云数据,PointNet 首先对输入点云使用多个共享的多层感知器(Multi-layer perceptron,MLP),从而将低维的坐标信息映射为高维特征,然后使用对称聚合函数来提取最终的全局特征,最后使用全连接层(Fully connected layer,FC)进行最终分类[3].然而在这种设计中,每个点的特征都是独立学习的,忽略了点与点之间的结构关系.为此,PointNet++[10]把点云划分为多个局部,在每个局部中使用Point-Net 提取局部特征,然后对提取到的局部特征进行局部划分并使用PointNet,通过多次叠加,最终获取全局特征.PointNet++在一定程度上解决了PointNet 缺少局部特征的问题,但这种方法只是简单地划分局部,并没有进一步说明局部点之间的关系.谱图卷积(Spectral graph convolution,Spec-GCN)[11]使用递归聚类和池化策略替换标准的最大池化过程,用于聚合来自其谱坐标中彼此接近的节点簇内信息,从而产生更丰富的整体特征描述符.但这种方法需要将三维点坐标转换到谱坐标中,增大了网络的复杂度.动态图卷积神经网络(Dynamic graph convolutional neural network,DGCNN)[12]是一种边缘卷积方法,通过与近邻点构建局部图结构,然后使用共享的MLP 层,对图的每一个边缘进行卷积获取邻边特征,最后使用最大池化方式对每一个邻边特征进行聚合,获取局部特征,并在网络的每一层后进行动态更新.这种方法增强了局部结构中点与点之间的关联,但由于点云并不是均匀分布的,近邻点对于中心点的影响也是不同的,而边缘卷积平等地处理每一个邻边,这种提取方式是不准确的.RSCNN (Relation-shape convolutional neural network)[13]通过从三维点云之间的几何关系,学习隐含的形状信息,从而构建局部.这种利用局部结构三维几何特征的方法可以方便地提取低维特征,但对高维特征的提取有局限性.
近年来,注意力网络在神经网络学习领域已成为一个重要概念,并在不同领域有着广泛应用.注意力机制通过加权方式来提高有用信息,抑制无用信息.在点云分析上注意力网络也有了一些应用.例如图注意力卷积网络可以根据动态学习的特征,有选择地关注其中最相关部分[14].基于点网络的图卷积[15]通过学习每个点的注意力特征,然后利用多头机制获取特征,最后利用注意力池化层来捕捉重要信号.点云变压器(Point cloud transformer,PCT)[16]网络的主要思想是通过使用Transformer固有的顺序不变性避免定义点云数据的顺序和通过注意力机制进行特征学习.但是,相较于卷积神经网络,注意力模块有更多的参数,大量使用注意力模块会使整体网络的训练难度增加.
为了更好地应对不规则点云带来的问题和现有网络存在的问题,本文提出基于特征关系的神经网络(Network based on relationships between features,RFNet).在构建点云局部结构上,RFNet 使用基于特征关系的卷积(Convolution based on relationships between features,RFConv)方法,来增强局部结构中近邻点特征与中心点特征之间的联系.首先,通过描述局部结构中近邻点与中心点之间的多种关系学习近邻点权重;然后,将加权后的近邻点与中心点进行组合构成局部;最后,再对组合后的局部进行学习聚合为高维的局部特征.另外,本文针对对称函数和联合损失函数(Joint loss function,JL)提出改进方法.在现有的网络中,对称函数多是使用最大池化和平均池化这样硬性的聚合高维特征方法,会导致信息的损失,为此,本文基于注意力思想,提出加权平均池化(Weighted average pooling,WAP).另外,本文利用交叉熵损失函数和中心损失函数的互补优势,组成联合损失函数,在增大类间距离的同时,减小类内距离,从而增强网络的分类性能[17].本文主要贡献如下:
1)提出一个全新的CNN 模块,可以有效聚合点云局部和全局特征;
2)引入联合损失函数,在减小点云类内距离的同时,增大点云类间距离,增强网络分类性能;
3)在合成数据集和真实世界数据集上的实验结果表明,本文网络与现有网络相比,有着更为明显的优势.
1 算法介绍
RFNet 是基于点的方法实现的.整体网络结构如图1 所示,其中C为物体的类别数.经典的基于点的方法的网络一般以MLP 网络和对称聚合函数为基础.MLP 网络的作用是将低维点特征映射到高维空间中来提取高维点特征.在此过程中,MLP网络首先对点特征进行1× 1 的卷积,然后进行批标准化,最后通过激活函数为网络增加非线性因素,增强网络表达能力.
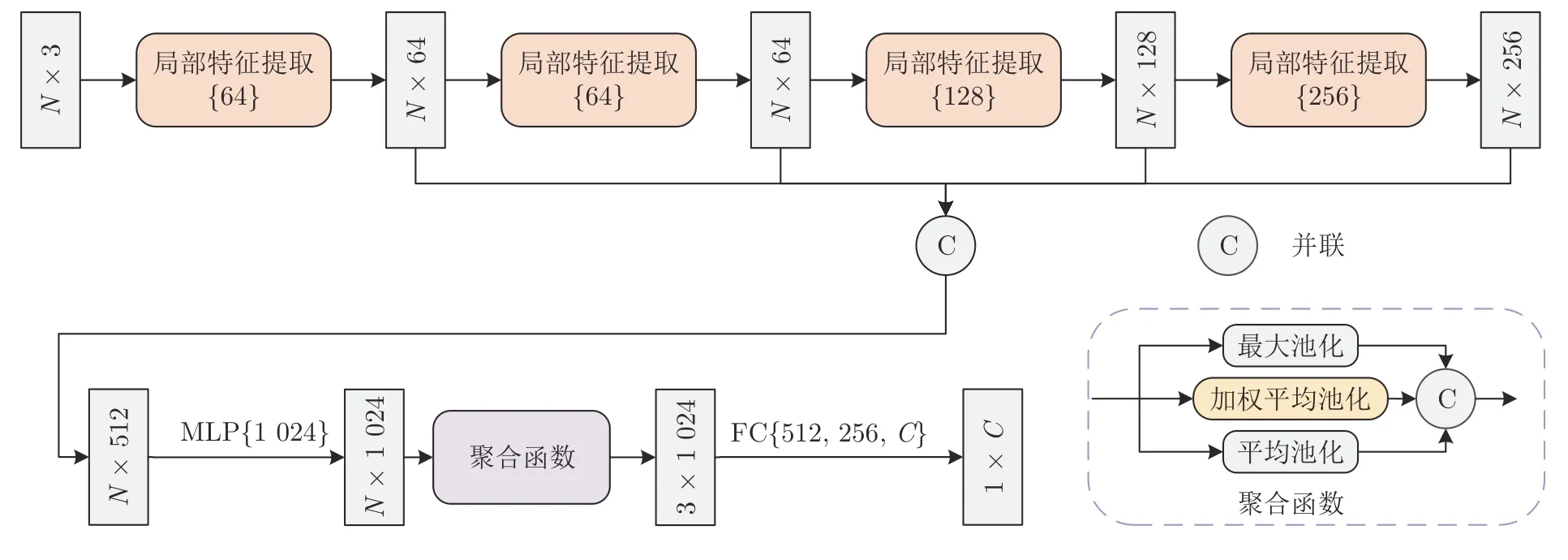
图1 整体网络结构图Fig.1 Diagram of overall network structure
式中,σ是激活函数,bn是批标准化,c1×1是1×1的卷积操作.对称聚合函数可以保证不论网络输入特征的顺序如何改变,都能使整体网络得到一个不变的全局特征,从而应对点云的无序性:
式中,A为对称聚合函数,Fo为全局特征,fl为第l层的高维点特征.在现有网络中,对称聚合函数一般选用最大池化和平均池化.
1.1 基于特征局部结构的卷积操作
现有的网络已经证明点云局部结构的构建对于点云高维特征的提取是至关重要的,为此本文提出基于特征关系的局部构建方法.
1)局部结构构建.对于输入的点云集合有P={Xi|i=1,2,3,···,N}∈RN×d,其中Xi表示第i个点的特征向量,N为点的个数,d为Xi的特征维度.对于第1 层特征向量来说,维度d=3 即每个点的三维坐标Xi=(xi,yi,zi),随着网络深度的增加,特征维度d会不断增大.中心点和近邻点的局部结构如图2 所示.首先,在本文网络中,对于输入的每一个点云特征Xi都视为点云的中心点;然后,利用K近邻(K-nearest neighbors,KNN)算法,通过计算中心点Xi到其余点之间的欧氏距离,选取距离最近的K个点作为中心的近邻点,Xij(j=1,2,3,···,K)∈Rd;最后,将中心点与近邻点组合构成一个局部.由于近邻点并不是均匀分布在中心点周围,因此对于不同位置的近邻点,其特征对中心点特征的影响也是不同的.所以,本文根据近邻点与中心点之间的不同特征关系,对近邻点进行权重分配:
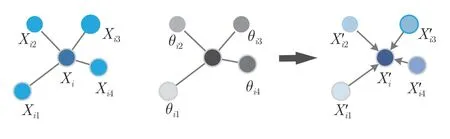
图2 中心点和近邻点的局部结构图Fig.2 Diagram of local structure between the central point and its neighbors
式中,θij ∈Rd是通过特征关系学习到的权重,⊙为点乘操作.
2)特征关系描述.本文通过对中心点特征与近邻点特征之间的关系进行描述,对不同的特征关系进行组合,获取近邻点对于中心点影响的权重.具体学习方法如下:
式中,⊕为并联操作,总体并联后的维度为Rd+2;eij ∈Rd为中心点与近邻点之间的向量信息;lij ∈R为中心点特征与近邻点特征的欧氏距离;sij ∈R为中心点与近邻点之间的余弦相似度,其中分别表示向量Xi、Xij的均值;θij ∈Rd为近邻特征的权重;M为式(1)的MLP 操作,用来提取权重信息并将权重的维度由d+2 调整为d.
3)局部特征提取.首先将中心点特征Xi分别与加权后的K个近邻点特征并联构建局部结构,然后对构建好的局部结构使用共享的MLP 提取K个高维的邻边特征,最后使用最大池化函数将提取的K个邻边特征聚合为Xi为中心的局部特征Li:
聚合后的局部特征Li即为下一层的特征输入,其中d′表示通过MLP升维后的维度.局部特征提取的网络结构如图3 所示,其中P={Xi|i=1,2,3,···,N}为 中心点特征Xi的集合,θ={θij|i=1,2,3,···,N,j=1,2,3,···,K}为权重θij的集合,L={Li|i=1,2,3,···,N}为局部特征Li的集合.
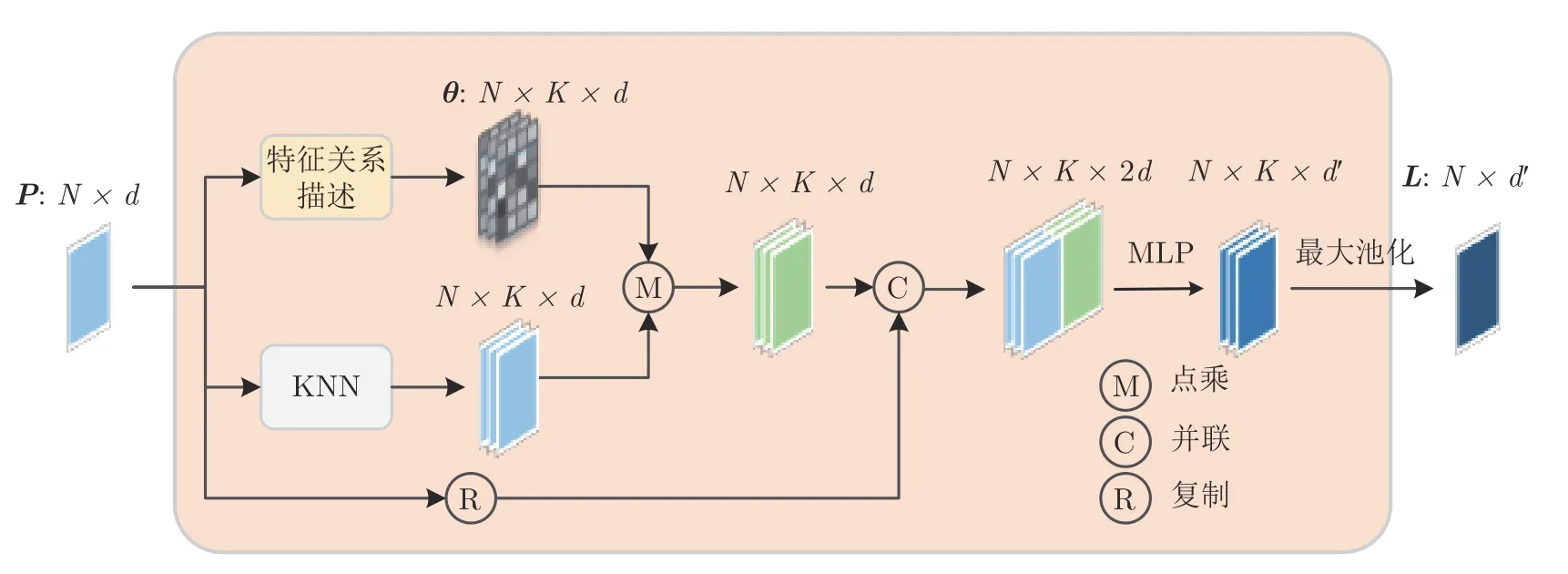
图3 局部特征提取结构图Fig.3 Diagram of local feature extraction structure
1.2 聚合函数
在全局特征的聚合过程中,现有的网络算法大多是以最大池化函数或平均池化函数硬性聚合高维特征,这样可以保持网络的对称性,但并不能准确地学习到有用信息,同时还造成信息的大量丢失.为了有选择地聚合高维特征,同时还要保持整体网络的对称性,本文基于注意力机制,提出加权平均池化,通过使用最大池化、平均池化和加权平均池化对特征进行聚合.
1)特征输入.如图1 所示,经过4 次局部特征提取,将每一层提取到的局部特征Li做并联操作,再经过MLP 网络提取特征并将维度升级到1 024维,得到最终的高维特征输入fi ∈R1024:
2)加权平均池化.如图4 所示,对于N个高维特征输入fi,首先经过MLP 学习特征分数,然后经过softmax 来将特征分数归一化:
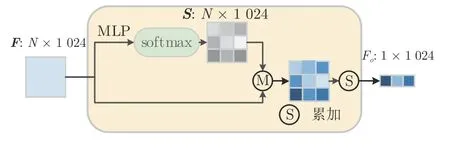
图4 加权平均池化结构图Fig.4 Diagram of weighted average pooling structure
最后,将学习到的特征分数与相对应的特征相乘并聚合,以获取加权池化后的全局特征:
式中,fi为第i个高维特征,其集合为F={fi|i=1,2,3,···,N};si为第i个高维特征的特征分数,其集合为S={si|i=1,2,3,···,N}.
1.3 联合损失函数
现有点云网络的损失函数大多是采用交叉熵损失函数.交叉熵损失函数可以使类间距离增大[17],但交叉熵损失函数对类内距离的影响较小,这样学习到的特征包含较大类内变化.为此,本文引用中心损失函数,采用交叉熵损失和中心损失联合监督的方法,进一步减小类内距离.
1)中心损失函数.中心损失函数通过对每一个类随机生成一个特征中心,然后在训练的过程中对每一个特征中心进行更新学习,使深层特征与其对应的类特征中心之间的距离最小化,具体的中心损失函数为:
式中,cyi表示深度特征yi类的特征中心,Fi ∈Rd表示深层次的特征,m表示输入批次的大小.因此,中心损失就是希望一个批次中的每个样本的特征离特征中心的距离的平方和越小越好,也就是类内距离越小越好.
2)联合损失函数.联合损失结构如图5 所示.通过将交叉熵损失与中心损失进行联合监督,在增大类间距离的同时,减小类内距离,使其获得的特征具有更强识别能力,具体表达式如下:
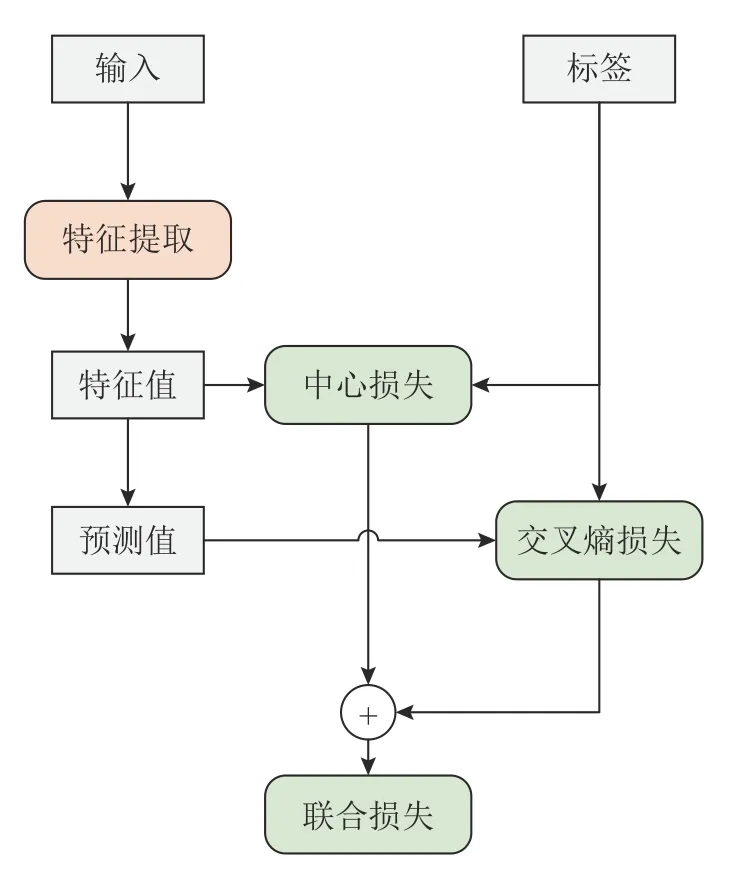
图5 联合损失结构图Fig.5 Diagram of joint loss structure
式中,LCE为交叉熵损失函数;n为分类的类别数;P(yij)代表yi类对应的真实标签,也就是n个类别的预测概率;Q(yij)代表yi类的预测值;LC为中心损失函数;λ参数用以调节两个损失的比重,当λ=0时,该函数表示为仅有交叉熵损失情况.
2 实验结果与分析
首先,介绍实验所使用的数据集以及网络的基本设置;然后,将本文网络与现有典型网络在不同数据集上进行对比,并对实验结果做进一步的分析;最后,为了说明本文网络模块的有效性和网络的抗干扰能力,进行了消融实验和鲁棒性实验.此外,为了说明网络的资源占用,还进行了复杂度实验.
2.1 数据集介绍
为了评估本文提出的点云分类算法的有效性,选用标准的合成数据集ModelNet40[18]、ShapeNet-Core[19]以及由真实世界对象点云组成的ScanObjectNN[20]进行实验结果对比.
1)ModelNet40 数据集.作为点云分析中应用最广泛的基准,ModelNet40 因其简洁的形状和构造良好等特点而广受欢迎.该数据集共有12 311 个物体,包括40 个类别,其中9 843 个模型用作训练数据集,其余2 468 个模型为测试数据集[18].
2)ShapeNetCore 数据集是一个丰富标注的大规模点云数据集,相较于ModelNet40,ShapeNet-Core 包含更为丰富的模型,其中包含55 种常见的物品类别和513 000 个三维模型.因此在训练时,也更具挑战性[19].
3)ScanObjectNN 数据集.为了进一步说明本文分类网络的有效性和鲁棒性,本文还在以真实世界对象为模型的数据集ScanObjectNN 上进行实验.该数据集有15 个类别,包含约15 000 个对象[20].由于复杂的背景、缺少的部件和各种变形,使得Scan-ObjectNN 在训练时,有更高的挑战性.
2.2 实验设置
本文实验使用的硬件配置和软件版本如表1所示.
表1 实验配置Table 1 Experimental configuration
网络参数的设置.网络的优化器选择了随机梯度下降法,将动量设置为0.9,并使用了余弦退火法,将学习速率从0.1 降低到0.001.训练批次设置为32,测试批次设置为16,并最终进行了500 次训练.激活函数使用负向斜率为0.2 的Leaky-ReLU 激活函数.在每个MLP 层后,都加入比例为0.5 的暂退率,以抑制过拟合.
2.3 分类实验
本文实验的输入数据为只含有1 024 个三维坐标的点云数据,在表2 中表示为1 k,2 k 表示输入的是含有2 048 个三维坐标的点云数据,5 k 表示输入的是含有5 120 个三维坐标的点云数据,nor 表示输入额外的法向量信息,voting 表示实验使用了多次投票验证策略.本文使用最常用的整体精度(Overall accuracy,OA)和平均精度(Mean accuracy,mAcc)性能标准,进行分类性能评价.其中,整体精度代表所有测试实例的平均精度,平均精度代表所有类别的平均精度.
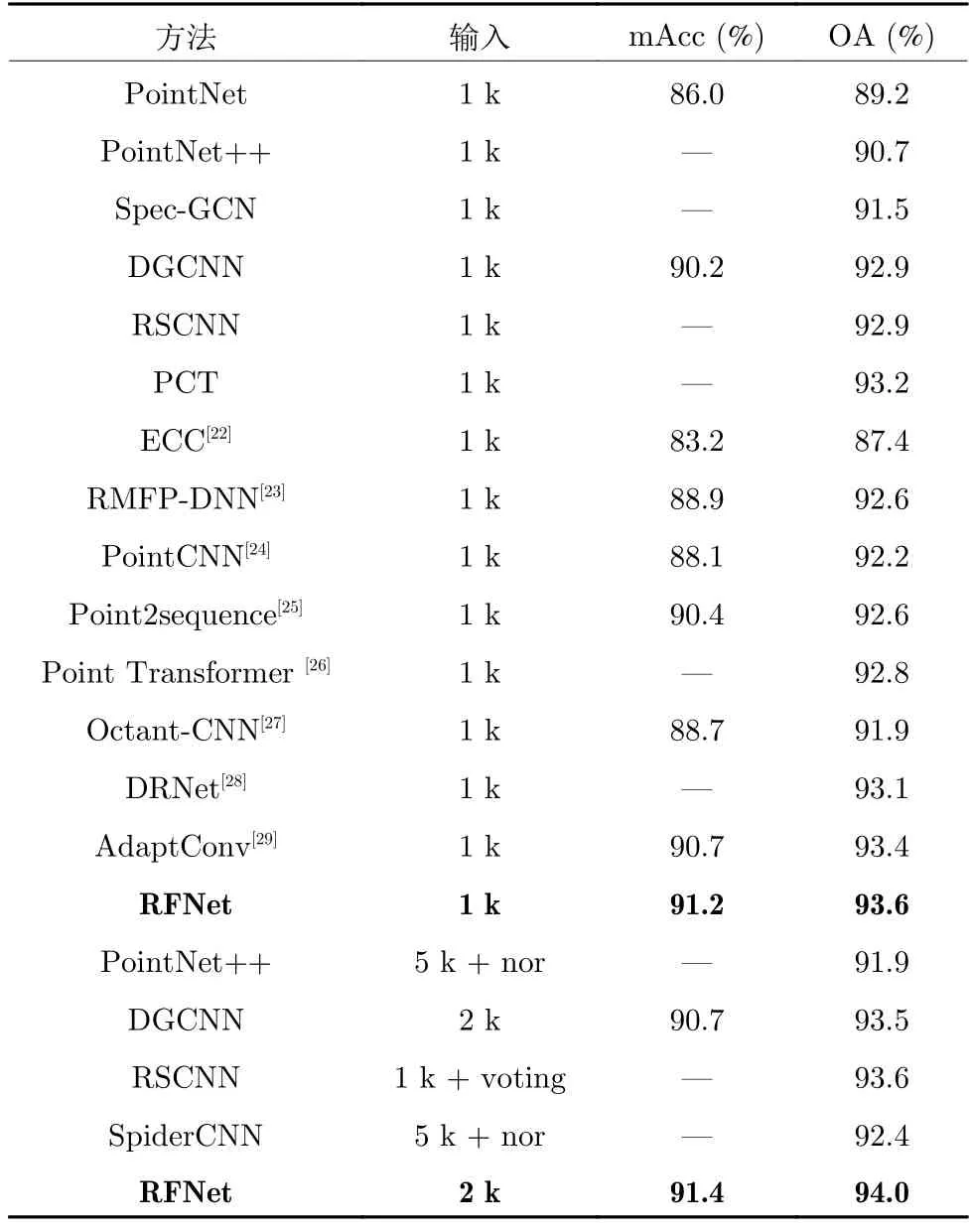
表2 在ModelNet40 数据集上的实验结果Table 2 Experimental results on ModelNet40
表2 给出了RFNet 与目前主流网络在Model-Net40 数据集上的实验结果.由表2 实验结果可以看出,RFNet 整体精度为93.6%,平均精度为91.2%,在与同样输入为1 k的网络情况下,取得了最优的结果.RFNet 甚至超过了一些输入额外信息的网络,例如PointNet++和SpiderCNN[21]在输入了5 k 个点和法向量信息后,整体精度仍低于本文中的FRNet.另外,RFNet 超越了输入同样是1 k 的RSCNN,与使用了10 次投票评估方法后的RSCNN 网络相同.本文在ModelNet40 数据集上进行输入为2 k 的实验,最终取得了整体精度94.0%和平均精度91.4%的好成绩,超越了所有输入额外信息的网络.
此外,本文在ModelNet40 数据集上进行了真实标签和预测标签的混淆实验,实验结果如图6 所示.由图6 可以看出,网络最易混淆的是标签为15的花盆类,这与数据集的标定有关.为了进一步探究预测结果,进行了易错模型的分类对比实验,实验结果如表3 所示.由表3 可以看出,RFNet 相较于PointNet 和DGCNN 有着更强的细节分辨能力,能较好地区分易混模型.由表3 也可以看出,ModelNet40 数据集中部分花盆类的标定有较大的歧义.
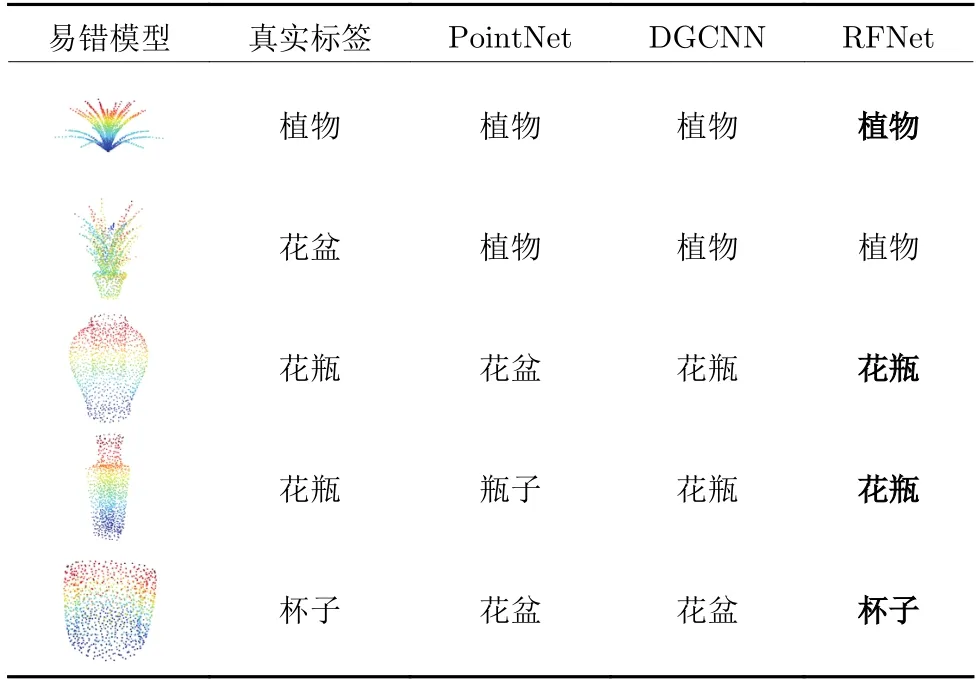
表3 不同网络的易错模型分类对比Table 3 Classification comparison of error-prone models for different networks
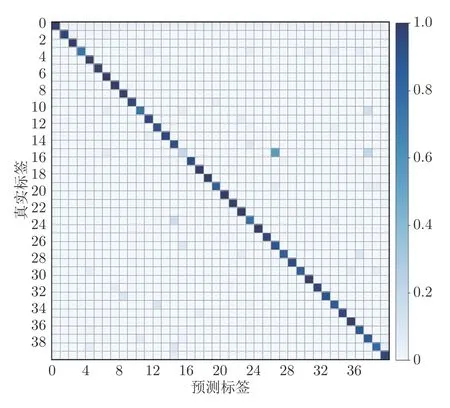
图6 混淆矩阵Fig.6 Confusion matrix
为了验证整体网络应对更丰富分类数据时的能力,本文在ShapeNetCore 数据集上进行实验,实验结果见表4.在输入点数1 k 情况下,RFNet 整体精度为88.3%.可以看出,ShapeNetCore 数据集更为丰富的分类确实给网络带来了不小的挑战.但对比其他网络,RFNet 依旧领先,甚至高于输入额外的法向量信息的SpiderCNN.

表4 在ShapeNetCore 数据集上的实验结果Table 4 Experimental results on ShapeNetCore
为了说明RFNet 在面对真实世界数据时的表现,本文在ScanObjectNN 数据集上进行实验,实验结果见表5.实验的输入依旧是1 k 点云坐标,最终取得了整体精度79.6%和平均精度76.3%的成绩.与其他网络对比可以看出,RFNet 无论是在整体精度还是平均精度上,都取得了最优异成绩;另外,表中还对ScanObjectNN 数据集中的15 个类别(Bag,Bin,Box,···)的分类精度进行了对比,其中有6 个分类都取得了最高精度,表明了RFNet的优越性.
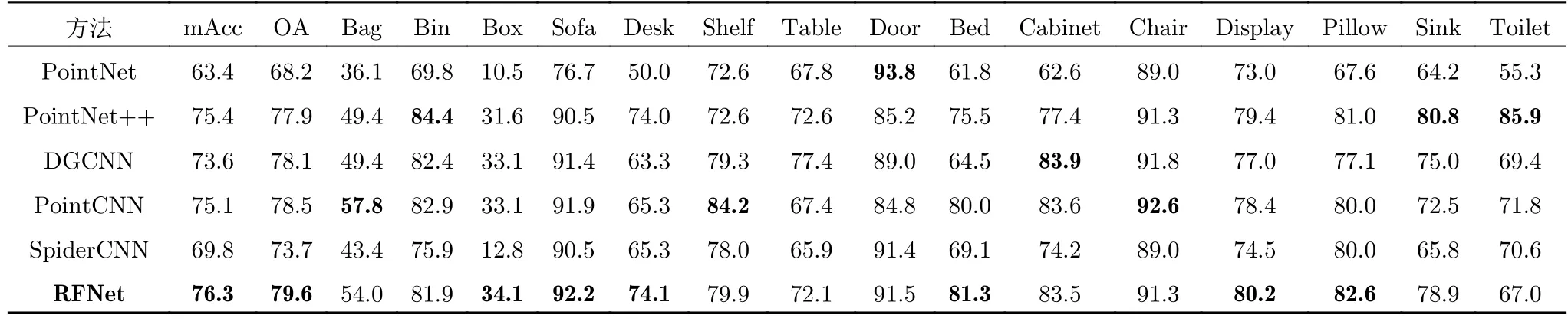
表5 在ScanObjectNN 数据集上的实验结果 (%)Table 5 Experimental results on ScanObjectNN (%)
2.4 不同模块的消融实验
为了验证网络中不同组件的功能和有效性,本文对RFNet 中的网络模块进行了消融实验.实验在数据集ModelNet40 上进行.表6 显示了不同模块的消融实验结果,表中“×”表示不使用对应模块,“√”表示使用对应模块.
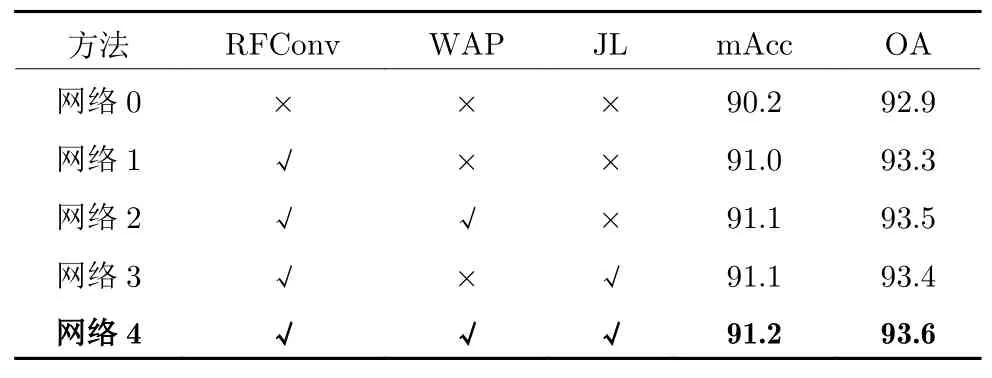
表6 不同模块的消融实验 (%)Table 6 Ablation experiment of different modules (%)
网络0 表示在只使用普通的动态图网络时的分类结果.在网络1 中,将图结构模块换成了RFConv模块,网络的整体分类精度也提高到了93.3%.这归因于RFConv 模块相较于图结构,可以通过特征加权的方式更有效地构建局部;同时可以看出,局部结构的构建对特征提取有着很大的影响.网络2在网络1 基础上,增加加权平均池化模块,其整体的分类精度提高了0.2%.加权平均池化模块可以通过自注意力方式,对不同层次的输入特征进行特征聚合,并且注意力机制也可以通过学习特征分数,在一定程度上弱化无效特征,增强有效特征.网络3 在网络2 基础上,增加了联合损失模块.联合损失模块可以在增大类间距离的基础上,通过迫使同类向特征中心靠近,将不同类进一步分离.可以看出,网络3 在网络2 基础上进一步提高.在网络4 中,同时使用了所有模块,其整体精度达到了93.6%,平均精度达到了91.2%,相较于网络0,整体精度提高了0.7%.
2.5 鲁棒性实验
本文在数据集ModelNet40 上进行了采样密度的鲁棒性实验和高斯噪声鲁棒性实验.
1)采样密度鲁棒性实验.实验中,分别将点云的采样数设置为1 024、512、256、128,然后将网络PointNet、PointNet++、PCNN、DGCNN 和RSCNN 作为对比,对比结果如图7 所示.由图7 可以看出,随着采样点数的降低,RFNet 有着更为稳健的结果.RSCNN 在使用投票机制后,有着很小的差距,但随着采样数降为128,差距进一步拉开,而RFNet 的准确率依旧保持在91%以上.表明本文网络具有较强的采样密度鲁棒性.
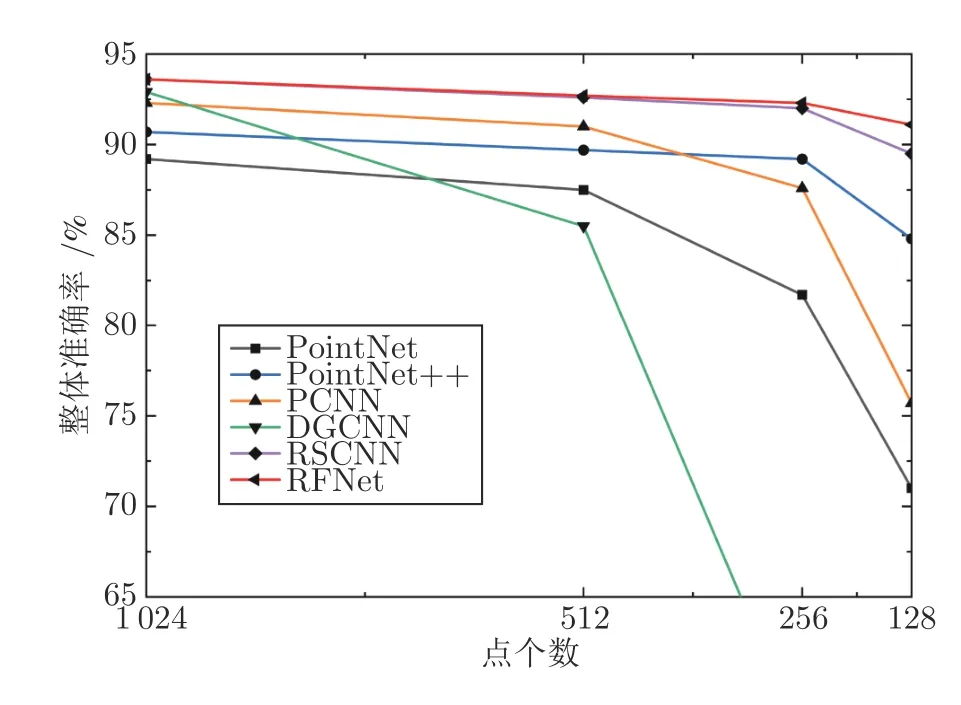
图7 采样密度实验结果对比Fig.7 Comparison of experiment results with different sampling densities
2)高斯噪声鲁棒性实验.本文在原始数据集上加入了高斯噪声,噪声均值设置为0.02,方差设置为0.01,可视化模型如图8 所示,实验结果见表7,其中PointNet++和RSCNN 的平均精度数据缺失,本文不做对比.由其余数据的对比结果可以看出,在加入高斯噪声后,各种分类网络的结果都有明显下降,但RFNet 影响较低.这是由于在构建局部结构时,RFNet 可以通过对不同近邻点分配不同权重来降低干扰点的影响,也使得RFNet 在面对高斯噪声的影响时,更具有鲁棒性.
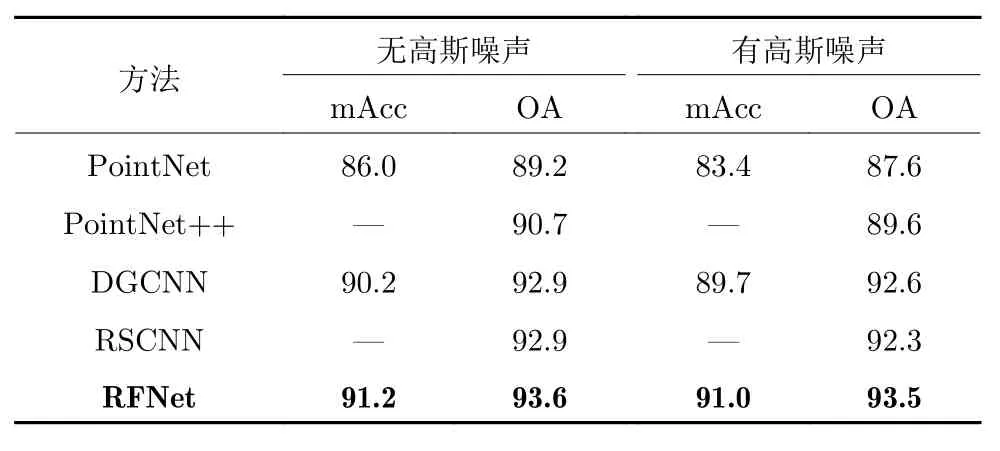
表7 高斯噪声鲁棒性实验 (%)Table 7 Robustness experiment of Gaussian noise (%)
图8 添加高斯噪声前/后点云样本的对照图Fig.8 Comparison of one sample with and without Gaussian noise
2.6 特征关系的消融实验
不同特征关系组合的选取对局部结构构造有很大影响,过少的特征关系无法准确描述近邻点对中心点的影响;而过多的特征关系则会给网络带来冗余信息,导致网络过拟合.本节对不同组合进行探讨.除式(5)提到的特征外,还加入了新的特征关系:
式中,disij ∈Rd为中心点与近邻点之间的方向信息.最终实验结果见表8,表中“×”表示不使用对应特征关系,“√”表示使用对应特征关系.
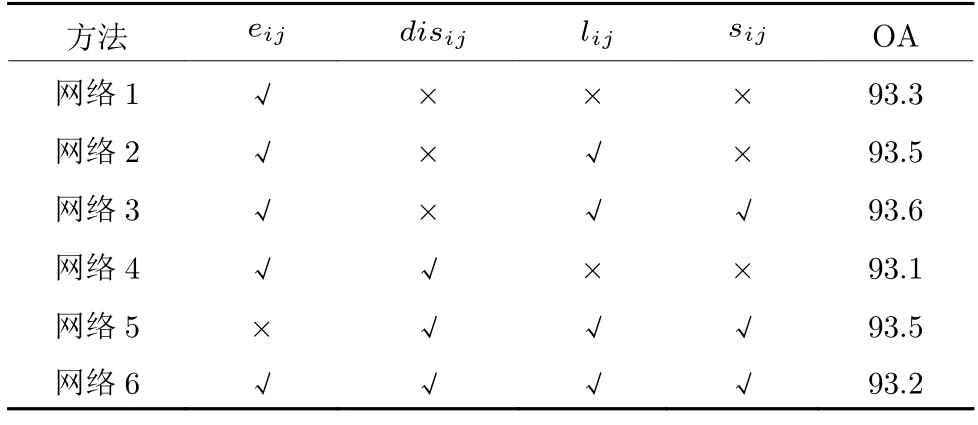
表8 不同特征关系的消融实验 (%)Table 8 Ablation studies about different relationships between features (%)
由表8 可知,网络1 在仅使用向量信息eij时,仍能取得93.3%的整体分类精度,可见eij中含有丰富的特征信息.网络2 和网络3 在网络1 的基础上增加了距离信息lij和余弦相似度信息sij后,整体分类精度也都有进一步的提高.需要注意的是,虽然eij中内在包含了lij,但从分类结果可以看出,一个准确的距离关系信息对局部特征的提取是很有必要的.网络4 在网络1 的基础上增加了方向信息disij,最终的整体分类精度却降低了0.2%,这是因为二者在相同的维度d下存在着冗余信息,而且冗余信息会随着维度d的增大而不断增加.这点通过网络3 与网络6、网络5 与网络6 的对比也可以看出.虽然二者有着相同的维度,但eij中却内在包含了disij,由网络3 与网络5 的对比也能看出,使用eij能够取得更好效果.
2.7 网络复杂度实验
本节通过对比网络的参数量和浮点运算数来说明网络的复杂度.网络的复杂度对比见表9.
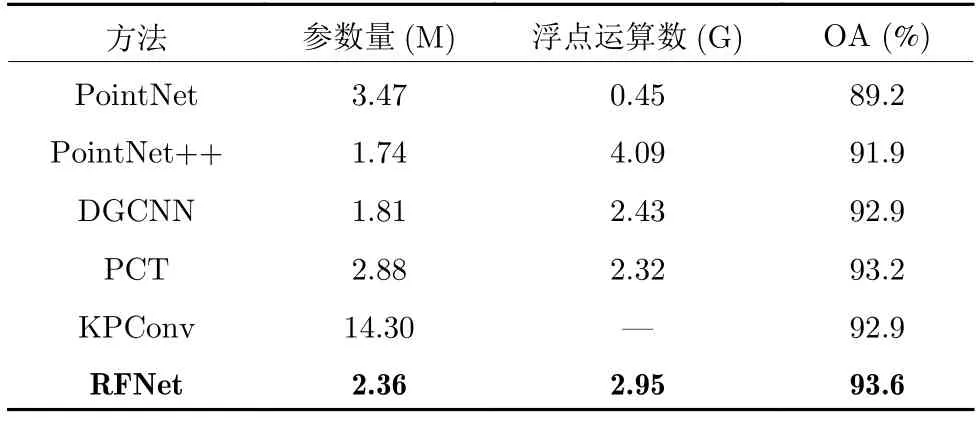
表9 网络的复杂度对比Table 9 Comparison of network complexity
对比DGCNN 可以看出,RFNet 在参数量和浮点运算数上都有一定提高;同时,在整体精度上也有很大程度的提高.这说明,网络中增添的模块对网络精度的提高具有正向意义.对比其他网络也可以看出,网络在参数量和浮点运算数上做了折中方案,但整体精度却最高.
3 结束语
本文提出一种用于点云分类的卷积神经网络.首先,该网络通过卷积模块提取近邻点与中心点之间的局部特征;然后,通过使用加权平均池化,从冗余的高维特征中聚合全局特征;最后,使用联合损失函数增强整体网络的分类能力.从合成数据集和真实世界数据集上的实验结果可以看出,该网络比现有网络更具优势.同时,本文还进行了消融实验、采样密度的鲁棒性实验、高斯噪声鲁棒性实验和网络复杂度实验,实验结果验证了本文网络模块的有效性和整体网络的稳定性.
