基于D- S 的特高压换流站设备故障诊断模型的建立与运用
2023-11-27白彦
白 彦
(中国电建集团北京勘测设计研究院有限公司,北京)
引言
随着社会经济的发展,对电力的需求日益增长,大量的电力设备需要进行监测,以确保电网的正常运行和及时维护。由于电网设备类型众多,在日常运行维护过程中会产生庞大的数据,这些数据构成十分复杂,给电网企业运维管理带来极大挑战。随着电网数字化和智能化的发展,对电力设备的运维也提出了更高的要求,但是目前的信息化管理与运维业务之间的融合度普遍不高,各项运维业务之间的缺乏足够有效的沟通大,导致运维工作变得十分法中,大大降低了电力设备的管理效率,因而有必要通过智能化改造来实现设备的精细化管理,从而提升电力设备运行维护的效率[1-3]。
换流站是特高压直流输电工程的关键设备,对于我国西电东送战略的实施具有重要意义,如何保证换流站在运行过程中的稳定与安全,成为当下的一个热门研究话题[4]。本文基于数据融合和D-S 证据技术,提出针对换流站设备的故障诊断模型,以期能为换流站设备的故障诊断提供可靠手段。
1 换流站简介
换流站主要高压直流输点系统中交流电和直流电之间的相互转换,充分确保电力系统安全和电能质量要求,是±500、±800 千伏特高压输电工程的重要中转站,有利于像西电东输这种长距离输电工程的电能保障。换流站内按照设备功能的不同,可将其划分为一次设备、二次设备以及辅助设备。一次设备主要用于电能的发输配电,包括换流阀、换流变、直流场设备、交流滤波器、GIS 设备等,二次设备主要包括监控和保护设备,如控制开关、测量仪器等,辅助设备主要包括水冷系统和消防设施。在换流站运行过程中,依靠监测系统可实现对油色谱、电气量、过程量等多个指标的监测,通过监测数据,可对换流站的运行状态进行诊断。
2 故障诊断模型
2.1 信息融合技术
信息融合是通过多个传感器对信息源进行监测,然后利用相关软件算法对监测信息数据进行联合、相关或者组合的技术手段,有效避免了单一信息源造成的误差影响,从而得到更加准确的目标估计,实现对故障的精确检测和排除,并为决策者提供最佳的处置方案。
信息融合的基础是多传感器,在数据处理方式上也呈现多层次的特点,一般而言将数据融合划分为三层结构:数据层融合、特征层融合以及决策层融合。数据层融合是指直接在传感器原始监测数据上进行处理和融合,并对其进行特征提取然后提供决策的方法,包含的信息更细微,数据量损失相对较少;特征层融合是指先对监测数据进行特征(如油色谱、电气量、过程量等)提取,然后再进行特征级别的融合处理,这种方法可以降低数据的冗余性,提高计算速度;决策层融合是指在进行特征提取后,对各个特征提取结果进行独立的决策分析,然后再对各个特征属性的决策结果进行融合处理得到最终的决策结果,该方法可以保证决策结果具有一致性,对传感器和网络传输通道的依赖性小,具有较好的容错性和时效性。
2.2 D-S 证据理论
D-S 证据理论由Dempster 及其他的学生Shafer提出并发展起来的一种不精确推理理论,该理论有两大特点:一是可以满足比贝叶斯概率论更弱的条件,二是具有能够表达“不确定”和“不知道”的能力,基于D-S 证据理论的合成诊断模型见图1。首先将故障初步诊断结果转换为证据体;其次定义各证据体的BPA分配原则;再次计算识别框架上的信任函数和似然函数,并确定信任函数的下限和似然函数的上限;最后对证据体进行融合,并输出诊断结论。
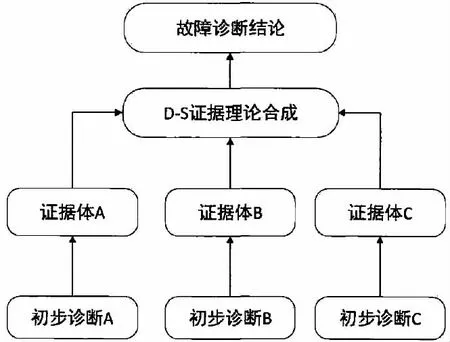
图1 D-S 合成诊断模型
2.3 D-S 故障诊断流程
基于数据融合三层结构,构建特高压换流站设备的故障诊断模型。诊断模型整体流程为:(1) 对换流站中的设备进行数据采集,然后对采集到的数据进行缺失值填充、异常值处理、标准化处理等预处理措施(统称为数据清洗)之后,将处理过后的数据传输给数据级融合模块;(2) 对预处理之后的数据进行关联融合,关联融合分为两类:一是同类数据之间的关联分析,二是异类数据之间的关联分析,然后将融合之后的数据传输给特征级融合模块;(3) 对关联融合之后的数据进行特征降维,然后利用设备特征库对换流站各个设备的故障进行初步诊断,并利用多分类逻辑回归将诊断出的故障按类型分别输出到决策级融合模块;(4) 将不同故障特征子集转换为证据体,并将其输入到D-S 证据理论中,按照D-S 证据理论相应原则进行融合,得到最终的故障诊断结果。
3 案列应用
3.1 换流站概况
某换流站换流总容量为9 000 MVA,该换流站包括28 台换流变压器、6 台高压电抗器、4 个直流双极阀厅和16 组交流滤波器。对该换流站内的换流变设备进行了为期6 个月的监测,监测数据类型包括电压、电流、甲烷、温度、压力等20 种。经计算统计,监测数据标记的故障样本共有2 805 条,将这些这些数据样本作为实例进行分析。
根据换流变的历史故障类型,可将其划分为绕组故障、铁芯故障、放电故障、过热故障以及绝缘油故障五类。造成绕组故障的主要因素包括电压、电流、温度、甲烷等,造成铁芯故障的主要因素包括电压、铁芯接地电流、温度等,造成放电故障的主要因素包括氢气、甲烷、乙烷、温度等,造成过热故障的主要因素包括乙烯、甲烷、铁芯接地电流等,造成缘油故障的主要因素包括徽水、氢气、甲烷、二氧化碳等。
3.2 数据预处理
按照D-S 故障诊断流程,首先需要对监测数据进行预处理,在本次监测数据中,共对123 条数据缺失值进行了填充处理,对12 条异常值数据(传感器漂移或者通讯异常所导致)进行了剔除,然后对数据进行标准化处理,目的是消除不同类型数据量纲的差异性,使不同数据之间可以得到标准化数据。以氢气、总的溶解可燃气体含量、乙烯、铁芯接地电流、分接开关油位、一氧化碳等种个数据为例,得到标准化处理之后数据频率分布直方图见图2。
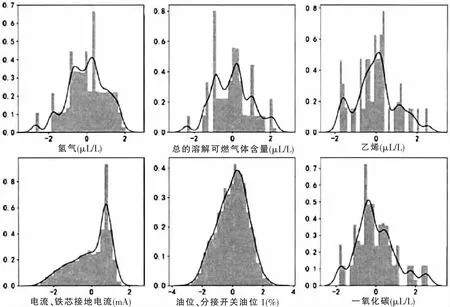
图2 标准化数据频率分布直方图
3.3 数据融合与降维处理
经数据预处理之后,剩余有效故障样本数为2 793 条,然后利用这些故障样本进行数据关联融合。在原始数据中,电气量的维度为2,油色谱的维度为12,过程量的维度为6,经同类数据融合和异类数据融合之后,数据维度由20 升至52,见表1。
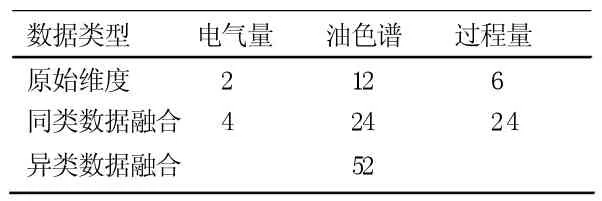
表1 数据关联融合维度变化
在如此高维度数据状态下,对故障特征进行提取和诊断会耗费大量的时间,因此有必要对数据进行降维处理,不同维度下信息保留率情况见图3。从图3 中可以看到:当维度值≥35 时,数据的信息保留率可以达到99%以上,因此,将维度从52 降至35 后,再将其作为初步诊断模型的输入特征维度值。
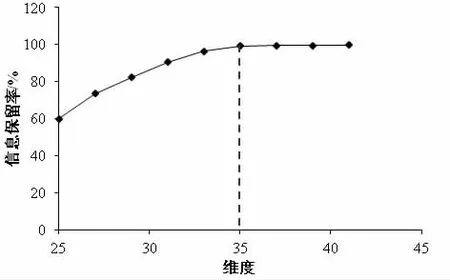
图3 信息保留率与维度关系
3.4 多分类逻辑回归初步诊断
当完成数据融合和降维处理之后,需要对数据进行多分类逻辑回归初步诊断,见图4。常用的多分类输出使用softmax 函数,该函数仅适用于输出类别为互斥的情况,但实际上电力设备的故障通常存在多个交叉输出,因而本文采用多分类逻辑回归(OvR LRs)来进行故障分类处理。首先,将某一类故障看作是正样本,将其余四种故障数据看作是负样本;其次,利用LR 二分类计算得到该类型故障的概率Pn;再次,按照上述步骤依次得到物中故障的概率;最后根据故障概率,当概率值大于该类故障的阈值时,将其列为诊断故障类型。
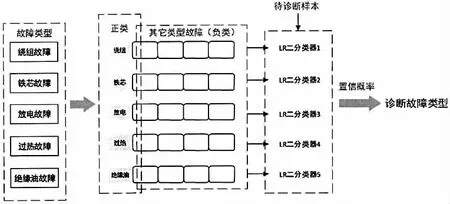
图4 多分类逻辑回归初步诊断流程
3.5 故障诊断结果
将2 793 条故障样本的80%作为训练样本,剩余20%作为测试样本,对D-S、逻辑回归以及集成树三种分类方法下的故障诊断召回率进行了统计,结果见图5。从图5 中可知:经过多分类逻辑回归初步诊断和D-S 证据融合之后,每一类故障的召回率均较传统逻辑回归和集成树算法有一定程度提升,采用D-S 证据合成算法的故障诊断平均召回率为87.75%,采用逻辑回归法的故障诊断平均召回率为85.6%,采用集成树算法的故障诊断平均召回率为86.58%;当采用单一的逻辑回归分类算法时,由于只能处理线性可分数据,因而对于非线性数据问题会存在欠拟合情况,因而故障召回率较低;当采用集成树分类算法时,对非线性问题处理比较好,但会存在过拟合情况,因而也会造成故障诊断召回率降低;当采用D-S 数据融合算法时,不仅考虑了非线性问题,而且还考虑了不确定性因素的影响,在进行融合时考虑了多个证据体的概率分配,因而可以得出更符合实际情况的综合决策结果。
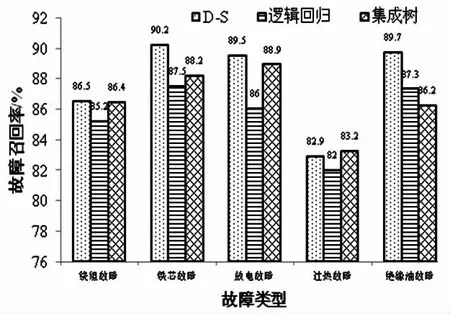
图5 故障诊断召回率
4 结论
以特高压换流站设备为例,提出基于数据融合和D-S 证据理论的故障诊断模型,构建了包括数据层融合、特征层融合以及决策层融合的故障诊断模型,并将其应用到实际工程中,分析结果表明:该方法较传统逻辑回归分类算法和集成树分类算法的故障诊断平均召回率分别提升2.15%和1.17%,故障诊断率有明显提升,可用于换流站设备的故障诊断。
