基于Petri网的区块链图书馆隐私保护模型分析*
2023-11-27张纪方欢
张纪,方欢,2
(1.安徽理工大学数学与大数据学院, 安徽 淮南 232001;2.安徽省煤矿安全大数据分析与预警技术工程实验室, 安徽 淮南 232001)
0 前言
图书馆作为一个收集、整理、保存、传播知识并利用的科学、文化、教育机构,在我国每个城市以及各个高校一直都占据着重要的地位.随着2015年以来大数据的迅猛发展,智能化以数据深度挖掘和融合应用为主要特征,再加上云计算、人工智能、5G技术的全面兴起,各行各业都在推进数据化转型、开展智慧建设.从2017年起,我国图书馆开始了智慧图书馆建设的历程[2].伴随着智慧图书馆的发展,用户的隐私问题也逐渐显现.大数据技术的应用需要采集读者的个人信息和数据,并通过分析以提供相应的服务内容.如果出现不当的大数据处理或者应用方式不正确,则会导致读者的个人隐私数据发生泄漏,对用户造成不利影响,致使用户的满意度下降[3].当前图书馆的服务模式决定了读者个人隐私泄露的风险主要存在于数据信息的储存和传播中[4].
文献[5]提出了一种基于云背景的图书馆隐私保护模型,其从图书馆模块、用户模块、云端模块等四个模块进行图书馆隐私保护技术模型的构建.文献[6]基于一种图聚类k匿名得到了一种隐私保护方法.该方法利用用户节点的属性以及结构进行聚类并对聚类后的数据进行匿名化的处理从而保护了用户的数据隐私.文献[7]提出了一种IDP k-means算法,该方法通过验证满足ε异构隐私保护.文献[8]提出了一种基于区块链技术的智慧图书馆数字资源管理框架,深入讨论了图书数字资源管理学中要解决的重点问题,但其并未涉及图书馆用户的相关信息的隐私保护.文献[9]利用Petri网对数字图书馆书刊流通系统进行建模,但是没有考虑到大数据背景下的用户信息以及图书馆所收集分析的数据的隐私.
基于Petri网的相关背景知识,根据文献[1]中所提出的基于区块链的智慧图书馆隐私保护模型对用户信息的收集、加密、传输、存储等流程进行分析并建立了智慧图书馆用户信息存储的Petri网模型,最后使用PIPE软件对模型进行模拟运行分析,表明模型具有安全性以及有界性.
1 基本概念
定义1[10](网)满足以下条件的三元组N=(S,T;F)称作一个网:
1)S∪T≠φ
2)S∩T=φ
3)F⊆(S×T)∪(T×S)
4)dom(F)∪cod(F)=S∪T
其中
dom(F)={x∈S∪T|∃y∈S∪T:(x,y)∈F}
cod(F)={x∈S∪T|∃y∈S∪T:(y,x)∈F}
定义2[10](可达性)设Σ=(S,T;F,M)为一个Petri网.如果存在t∈T,使M[t>M′,则称M′为从M直接可达的.
定义3[11](区块链技术)区块链是采取分布式技术与共识算法来构造出一个全新的信任机制,利用密码学的方法相互关联形成一串串的数据块,一次网络交易的数据就保存在一个对应的数据块里面,起到验证其数据的真实性并且产生一个新的区块.
定义4[12](Merkle trees)在计算机科学与密码学中,Merkle trees是一种树形数据结构.每个叶子节点均以数据块的哈希值作为标签, 而除了叶子节点之外的节点,则以其子节点标签的加密哈希值作为标签Merkle trees,可以实现快捷的数据验证, 因此能够高效地验证大型数据结构的内容.
定义5[13](智能合约)智能合约是区块链中每一笔交易之间重要的“合同”,这份合同包含了众多对交易双方的约束规则,交易前只需预置好合同内容,就可保证交易的安全性和不可逆性.
2 基于区块链的图书馆隐私保护模型
智能图书馆中储存有大量的资源以及用户信息.目前,图书馆网络建设和应用大多采用中心化架构,在这种网络结构体系中分布式或联盟链上的节点之间的数据传输需由核心服务器控制、分配来完成,此种方式在通信过程中容易出现非法获取、篡改、欺骗等数据安全问题.因中心化故障引发连锁反应,造成整个系统崩溃,中心化作用和地位已成为整个网络系统的潜在安全威胁[14].区块链作为一项新兴的技术,恰恰具有去中心化、多节点、可追溯、自动化等特点,其可以保护图书馆用户数据传输的可靠性与完整性,对用户信息使用非对称加密技术,有效降低了用户的个人信息被获取修改的风险.
图1是基于区块链的图书馆用户隐私保护模型[1],其分为四个模块:利益相关者模块、信息生命周期模块、隐私风险识别模块、区块链基础架构模块.基于区块链的图书馆用户隐私保护模型共分为四个步骤[1],流程图如图 2所示.
1)信息采集以及组织加工.该阶段将图书馆用户再注册时提交的基本信息以及用户在使用图书馆服务时产生的行为信息采集起来.其中包含了用户的敏感信息以及非敏感信息.在采集了此类信息后使用哈希函数对所有信息进行加密处理.接着用户可以自行决定信息是否公开以及公开的内容,用户此时可以对自己的信息进行增、删、改、查等一系列操作.
2)信息传输存储.在图书馆服务模式下,每天有相当多的用户信息需要图书馆对其传输存储,而传统的数据存储模式采用的是中心化的存储模式,而中心化存储存在诸多问题,例如,其成本较高,还容易受到非法攻击.因此,去基于分布式存储的区块链满足了对用户信息存储方面的需求.在经过前一步的操作之后,用户的加密信息被存入到联盟链的图书馆用户节点上,通过检测用户的信用等级判断是否进行下一步操作.若用户信用等级较高,则可以继续存储,下一步进行数据完整性的检查,若某一用户节点遭受非法攻击或者存在完整性缺失,则我们会用其他节点的数据对其进行恢复并返回再次检查完整性以及全网广播.
3)信息评价与储存.当数据完整性被确认过后,系统会根据广播内容评价用户的信用等级并打包同用户信息一同加密存储到用户节点上,并传输到区块链中与其他图书馆所掌握的用户信息进行传播共享.
4)信息传播共享.用户节点以及图书馆自身所存储的数据信息会被打上数字水印,接着信息会被加盖时间戳,也就是对信息生命周期中各阶段的用户信息加盖时间证明,以方便通过Merkle trees对其进行真实性验证.当验证通过时,数据将会被发布到区块链上以便共享;若未通过则说明数据信息受到污染,利用区块链的可追溯性结合时间戳以及数字水印,对用户隐私失真的问题进行解决并将用户信息以及失真原因在全网登记广播.
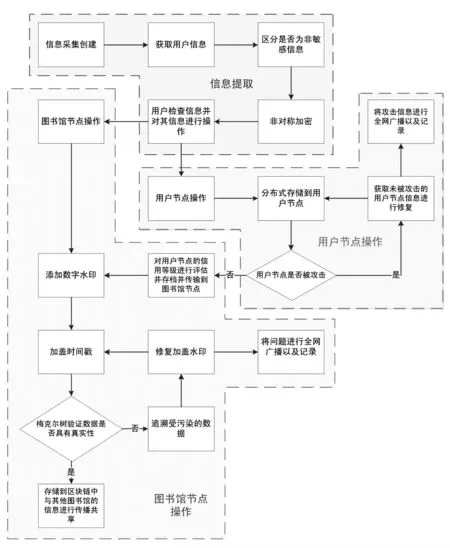
图2 基于区块链的图书馆用户隐私保护流程图
3 基于Petri网的区块链图书馆隐私保护模型
根据前面给出的流程,构建基于区块链的图书馆隐私保护Petri网模型,如图3所示.该模型包括的主体有用户节点和图书馆节点,应用到的技术有非对称加密、Merkle trees、智能合约、分布式数据库等.我们将用户隐私数据保护模型的四个步骤中所发生的活动用Petri网中的变迁T来表示,共计有37个变迁.每个变迁所表示的含义如表 1所示.变迁t1节点创建后,首先对数据进行收集并对收集的数据应用做初步的加密,从变迁t18处开始,数据分别进入用户节点和图书馆节点做进一步的处理,变迁t28发生时会将数据存储到用户节点上,这种去中心化的存储方式大大降低了图书馆的物理存储空间成本,同时提高了用户信息的安全性以及可靠性,变迁t36发生时,用户信息将会被在加入区块链的图书馆之间相互传播共享,提高了知识服务传播的效率.

表1 各变迁代表的活动
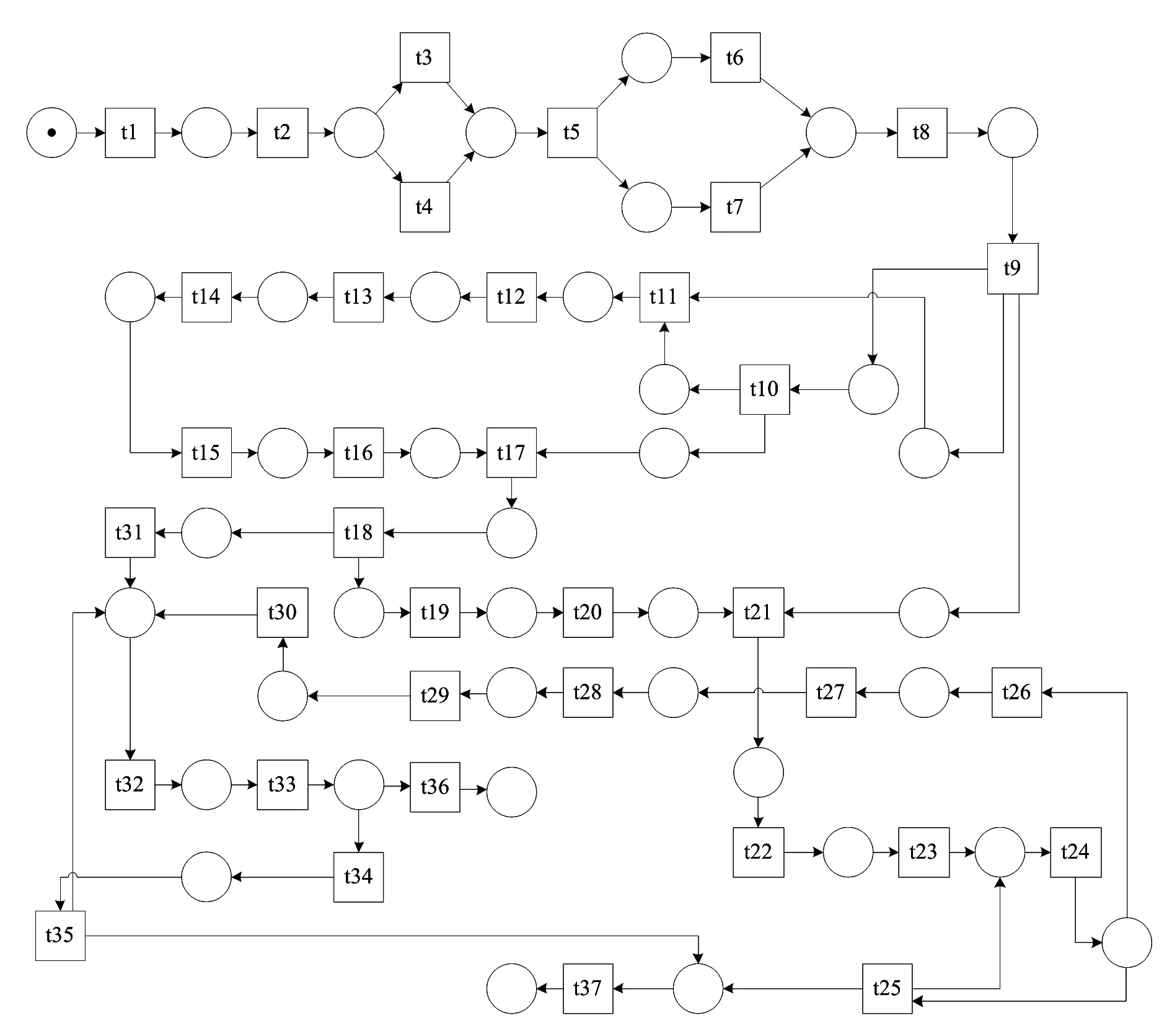
图3 基于区块链的图书馆用户隐私保护Petri网模型
通过利用区块链技术可以很好的保护图书馆用户的隐私信息不被攻击泄露,具体体现在如下方面.
1) 将用户信息通过区块包装永久记录到区块链的数据区块上.
2) 利用数字签名技术产生时间戳,以此证明图书馆用户信息产生的时间.
3) 通过哈希算法将任意长度的二进制值映射为固定长度的二进制值以实现区块链上的用户信息不被篡改.
4) 通过Merkle trees对比验证处理用户信息真实性.
5) 通过设计公私钥的形式实现非对称加密,只有用相应的私钥才能解密用公钥加密的用户信息.
在保证图书馆用户隐私信息安全的前提下,基于区块链的网络层可以实现各利益相关者之间的信息交流.用户信息在被打包成区块信息后会通过广播的形式传递到其他节点上去,而经过51%的用户节点验证过的信息将被写入到区块链主链上去.这些信息的交换构成了一个没有中心服务器的互联网体系,达到了用户信息共享的目的.通过对区块链上用户信息的分析,图书馆能将更符合用户喜好的服务推荐给每个图书馆用户.
4 仿真实验及结果分析
4.1 仿真实验
PIPE是一个开源、独立于平台的工具,用于创建和分析包括GSPN在内的Petri网.它的功能完全由Java实现,以确保平台独立性,并提供优雅、易于使用的图形用户界面,允许创建、保存和加载符合PNML交换格式的Petri网.PIPE还提供了一套完整的分析模块,用于检查行为属性、生成性能统计数据以及一些不太常见的功能,如PN比较和分类.利用PIPE对上述Petri网模型进行仿真运行以及分析,结果如图 4所示.从图 4可以得出,基于区块链的图书馆用户隐私保护Petri网模型具有有界性和安全性.

图4 模型分析结果
4.2 结果分析
传统图书馆用户隐私保护模型大多采用中心化存储架构,在这种网络结构体系中分布式或联盟链上的节点之间的数据传输需由中心服务器控制、分配来完成,在数据存储成本上花费较高,存储效率往往偏低.对于基于区块链的图书馆用户隐私保护模型,由于采用了去中心化的方式将数据信息存储到用户节点上,发挥了信任机制的最大效果,使得用户数据以及信息在网络中完整有效安全且可靠的传递,图 5展示了用户信息的两种储存方式.
模型的去中心化主要体现在用户的信息传输储存阶段.在用户信息被加密之后将会存储在用户的各个节点上.当某个数据节点收到非法攻击从而导致该节点数据损毁时,其他节点依旧保持数据的稳定以及安全性.被攻击的用户节点通过使用其他节点的数据便可对自身数据进行恢复.
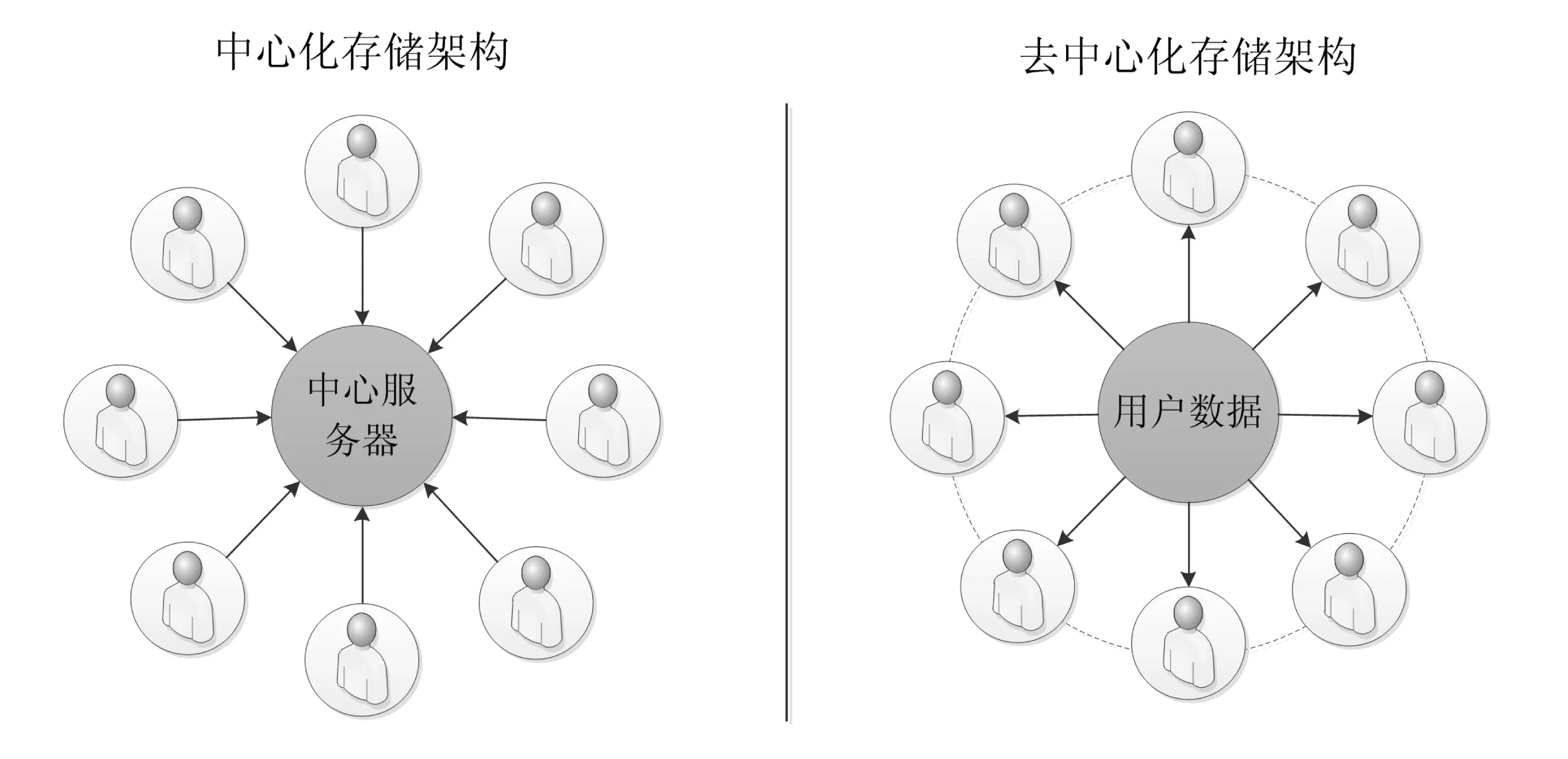
图5 用户信息中心化存储方式与去中心化存储方式
表2是传统图书馆用户隐私保护模型与基于区块链的图书馆用户隐私保护模型的详细对比情况.借助PIPE对模型作进一步分析,得出基于区块链的图书馆用户隐私保护模型有着较好的稳定性,且是有界、安全、无死锁的,证明了模型的安全性以及可靠性.

表2 传统图书馆用户隐私保护模型与基于区块链的图书馆用户隐私保护模型对比
5 结束语
介绍了图书馆隐私保护的背景知识并列举了几种常用的隐私保护模型.针对新兴的智慧图书馆,结合Petri网的相关知识对文中提出的一种基于区块链的图书馆用户隐私保护模型,进一步建模从而生成了基于Petri网的区块链图书馆用户隐私保护模型.使用PIPE软件模拟运行分析,结果表明该模型具有安全性和有界性.未来的工作中,会注重于将模型与应用场景实践结合起来以验证其可操作性,同时对比实际应用场景对目前模型存在的不足作进一步的改进与完善.
