基于多注意力融合的抗遮挡目标跟踪
2023-11-25张天晴刘明华邵洪波
张天晴,刘明华,何 博,邵洪波
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
在计算机视觉任务中,目标跟踪定义为给定视频初始帧的目标位置,预测后续视频序列的目标状态[1]。它被广泛地应用于智能视频监控、无人机、机器人等[2],是计算机视觉的一个重要研究方向。如何在光照变化、遮挡形变、相似目标、尺度变化、运动突变等复杂场景中,准确、快速地跟踪目标是亟待解决的问题[3],其中遮挡是导致目标跟踪失败最普遍的问题。
为应对局部遮挡问题,陈勇等[4]使用提出的注意网络融合浅层和深层特征,进而引导模型更多关注被遮挡目标可视区域。王蓓等[5]判断目标是否被遮挡的方法是平均峰值相关能量遮挡判据,目标出现遮挡时,该算法依据目标的历史运动轨迹使用滤波修正目标位置。姜文涛等[6]提出异常分析机制来判断目标是否被遮挡,设计响应模型和响应图做对比,二者差距大即说明目标存在遮挡或形变等异常。分块算法能有效地应对遮挡问题。刘明华等[7]利用超像素分块的模式不变性,得到能很好地保持目标边界和空间结构特征的自适应目标子块;遮挡处理方面,使用目标相似性度量和超像素判别处理每个目标子块。考虑到局部模型和全局模型的联系,张卫峰等[8]使用局部滤波器粗略估计目标位置,再由全局滤波器准确定位目标。王任华等[9]利用局部分块应对遮挡,联合全局模型应对目标的大幅度形变。局部和全局模型的联合实现了鲁棒的目标跟踪。以上方法从遮挡识别机制的设计到分块算法,再到联合全局模型处理遮挡,一定程度提升模型在遮挡场景中跟踪的性能,然而遮挡图片数据集有限限制了上述算法性能的提升,遮挡数据集有限导致模型很难学习到丰富的遮挡图像特征,导致其识别能力在面对不同类型的遮挡场景时难以得到较好的体现。同时,遮挡情况的多样性和复杂性也会导致模型的泛化能力下降,遮挡场景下,模型往往会出现漏检或误检的情况。此外,由于过度拟合的情况常常在较小的数据集中出现,遮挡图片数据集有限也会引发此类问题,使模型难以泛化到新的场景并保持高精度跟踪的效果。为了解决这些问题,需要引入更多的具有丰富变化的遮挡样本数据,或者采用更为先进的数据增强技术或网络优化算法以提高模型在遮挡场景下的抗干扰能力,因此本工作通过生成随机遮挡块,扩充负样本数据集,提升模型在遮挡情况下对判别性特征的提取能力,进而提升模型在遮挡场景下的抗干扰能力。
注意力机制利用特征增强模块筛选特征,为目标特征赋予高权重,从而引导跟踪器关注重要信息,忽略干扰信息。HU 等[10]提出挤压激励模块(squeeze and excitation module,SE),通过给通道加权显式地建模特征通道间的依赖关系。PARK等[11]提出瓶颈注意模块(bottleneck attention module,BAM),增加卷积模块操作的空间注意力机制,与通道注意力机制并行,进一步优化目标特征。鉴于SE 模型忽略了目标在特征图中的位置信息,HOU 等[12]提出协调注意力(coordinate attention,CA)模块,该模块使用平均池化获取并拼接特征图的纵向和横向上的信息,最后重标定特征图。对比SE模型,精度提升的同时,参数和计算量更少。吕振虎等[13]在DiceNet[14]使用的卷积方法基础之上提出了基于挤压激励的轻量化注意力机制模块,获取到特征图在高度维度上的有用信息,证明了特征图中仍存在着可利用的信息。从SE的通道注意力到BAM 的空间注意力,以及后来的协调注意力,都未能充分挖掘和融合特征图中的信息,导致跟踪器难以准确提取目标的特征造成跟踪失败,另外在处理部分遮挡、形变、旋转或尺度变化等情况时表现较差,导致鲁棒性下降,从而降低跟踪模型的可靠性和稳定性。因此,在目标跟踪中,必须充分挖掘特征图中的信息,以提高跟踪模型的效果,因此本工作从特征图的三个维度去捕获有用信息,联合空间注意力模块,充分挖掘并融合特征图信息,提升模型应用精度。
本工作提出一种基于多注意力融合的抗遮挡目标跟踪方法(anti-occlusion target tracking based on multi-attention fusion,AOTMAF)。并在GOT-10k等多个公开数据集上验证了模型的有效性。
1 基于多注意力融合的抗遮挡目标跟踪算法
基于多注意力融合的抗遮挡跟踪方法总体框架如图1所示,网络由骨干网络、特征融合网络和预测头三个部分组成。主干网络首先,提取模板和搜索区域的特征;然后,利用特征融合网络对特征融合,最后,预测头对增强的特征进行二值分类和边界盒回归,生成跟踪结果。

图1 基于多注意力融合的抗遮挡目标跟踪框架Fig.1 Anti-occlusion target tracking framework based on multi-attention fusion
1.1 孪生网络目标跟踪框架
1.1.1 特征抽取
与基于Siam 框架的跟踪器类似,提议的网络使用成对的图像块(即模板和搜索区域)作为输入。模板是视频序列第一帧中目标中心边长的2倍放大图,包含了目标的外观及其邻近环境的信息。前一帧图像中目标中心坐标的边长被放大4倍,形成搜索区域,该区域覆盖了目标可能的运动范围。搜索区域和模板都被转换为正方形。紧接着,搜索图像经过渐进式随机遮挡模块(progressive random occlusion module,PRO)处理,得到遮挡图像,将遮挡图像和模板图像送入主干网络处理。随机遮挡模块具体实现细节见1.2节。
本工作调整Res Net50用于特征提取。更具体地说,Res Net50的最后一个阶段被删除,第四阶段的输出被用作动态输出。第四阶段的卷积步幅从2降到1,以达到更好的特征分辨率。为增加感受野,第四阶段的3×3卷积也被改为2步幅。骨干网对遮挡搜索区域和模板进行处理,以获得其特征映射
1.1.2 特征融合网络
本工作设计了一种特征融合网络,有效地增强并融合特征f z和f x。首先将特征表达送入多注意力融合模块,获得重要通道和目标所在空间的信息;再送入特征融合模块,融合多层卷积后输出的特征,特征的多样性得到提升,进而提升模型性能。
多注意力融合模块由三维度通道注意力和空间注意力组成。利用三维度通道注意力机制可以从三个维度捕获特征图有用信息,利用空间注意力机制可以引导模型关注特征图空间信息,将基于三维度的通道注意力机制和空间注意力机制融合,在保持特征通道间关联性的同时保留了特征图的空间信息。多注意力融合模块的具体实现细节见1.3。
1.1.3 预测头网络
分类和回归分支组成预测头,每个分支包含一个三层感知器和一个Re Lu激活函数,感知器的隐藏维度为d。经由特征融合网络输出特征图(f∈Rd×H x Wx),预测头对该特征图中每个向量预测,分别得到H x W x个前/背景分类结果以及H x W x对搜索区域大小的归一化坐标。算法直接预测归一化的坐标,根据先验知识完全消除了锚点和锚盒,这使得框架更加简单。
1.2 渐进式随机遮挡模块
图像裁剪和遮挡等数据增强方法可以提高模型的鲁棒性和通用性,但对于困难的训练样本,这种方法对性能提高是有限的。为了更好地模拟遮挡图像,本算法嵌入渐进式遮挡模块PRO。随着学习次数的增加,网络学习能力提升,PRO 渐进式地对一些图像区域进行随机遮挡,提升模型在遮挡情况下对判别性特征的提取能力。
给定一个图像X∈R3×H×W,PRO 在X中随机生成i个遮挡区域的块P i。每个块P i的面积为S i,块P i的总面积为S,其中H和W是图像的长度和宽度。i是区块的数量,P i是区块的数量。遮挡块的生成过程如下:
1)图像的面积为S o=H×W,随机初始化生成S0,其中S0∈[s l×S,s h×S],s l、s h分别为最小和最大面积遮挡系数。
4)区域P i=(x i,y i,x i+h i,y i+w i)为遮挡区域。生成一个[0,255]的随机值填充区域P i的像素点,最终得到一个人工遮挡特征张量模拟遭受遮挡的图像Xobscure。
如图2 所示,每5 个训练轮次,遮挡块数量翻倍,S随着轮次的增加而增大。

图2 基于批次的渐进式随机遮挡块Fig.2 Batch-based progressive random occlusion block
遮挡图像Xobscure通过主干网得到特征图F_obscure,F_obscure经过多注意力融合模块 进一步提取精炼特征与通过二值降维的mask按照元素级的操作乘法得到Fmask,Fmask与作为MSELoss 的输入,Fmask通过计算MSELoss对F_obscure进 行监督。该损失函数使遮挡的区域对应于特征尽可能为0,使模型在反向传播中忽略生成的遮挡区域O i。该损失函数如下:
然后F'_obscure通 过3×3卷积层、批次归一化层以及ReLU 层,最终得到特征图Fobscure∈R32×24×8。该分支起到了提取局部非显著性特征的作用。
其中:W O和b O分别为卷积层的权重和偏置。
1.3 多注意力融合模型
通过融合三维度通道注意力和空间注意力机制,能有效抑制背景噪声,强调目标区域,充分挖掘并融合目标特征,算法的跟踪性能得到提升。本节介绍多注意力融合模型(muti-attention fusion,MAF)的细节,如图3所示。
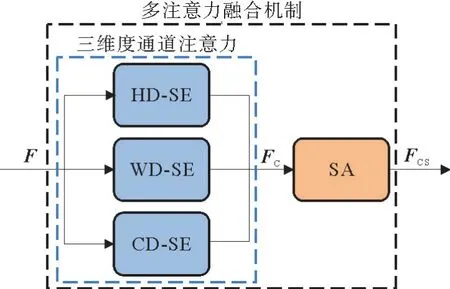
图3 多注意力融合机制Fig.3 Multi-attention fusion mechanism
1.3.1 HD-SE模块和WD-SE模块
对于一个三维特征图张量F∈RC×H×W,不同于挤压激励操作在深度维度上加权特征图的通道信息,HD-SE是在高度维度处理特征图。具体地,首先将特征图按高度维度转置,得到F1∈RH×C×W输入到HD-SE中,接着对F1进行挤压激励操作,得到基于高度维度的道道权重系数,基于此对输入特征图F1重标定,应用惩罚系数b,最后将特征图转置回来。惩罚系数是为了降低由于转置操作带来的干扰信息对特征的影响。
图4为HD-SE 结构图。其中Fsq(·) 为挤压操作,Fex(·,W)为激励操作,Fscale(·,·)为特征重标定操作,β为惩罚系数。WD-SE 则是在宽度维度上对特征图转置,后续操作相同,该模块实现从特征图的高度维度去捕获有用信息。

图4 HD-SE结构Fig.4 HD-SE structure
分别得到从三个维度通道增强的特征,将这三个特征图Concat在一起,即得通道数为3×256,大小为7×7的特征图;最后,用Conv Transpose2d操作,得到大小为7×7×256的特征图F c,该特征图具备三个维度通道增强信息,接着将增强特征图送入空间注意力模块。
1.3.2 空间注意力机制
空间注意力机制可以对目标中的特征聚焦,通过赋予特征图不同位置的重要性,增强重要区域,抑制不重要区域,增加了特征间的判别性,进而将跟踪目标从复杂的背景下区分出来。
在本工作的模型中,将三维度通道注意力模型输出的特征图作为空间注意力机制模块的输入特征图。如图5 所示,首先分别使用最大池化(maxpooling)和平均池化(meanpooling)操作压缩输入特征图通道域特征,接着为消除通道间信息分布对空间注意力机制的影响,使用卷积操作压缩多通道特征为单通道特征,然后应用激活函数归一化权重,最后进行特征重标定,得到具有空间权重信息的特征图。

图5 空间注意力机制Fig.5 Spatial attention mechanism
空间注意力模块的运算过程:
其中,Fc为输入特征图,δ是sigmoid激活函数,f3×3是卷积核大小为3 的卷积层,AvgPool(·)和Max Pool(·)分别表示平均池化和最大池化操作。
1.4 跟踪流程
训练完成后保存网络参数,在跟踪时使用。跟踪流程如下:
1) 从第一帧图片中,以跟踪目标的中心点截取127×127的区域,作为template。
2) 在随后的图片中,以上一帧跟踪目标的中心点截取255×255的区域,作为search region。
3) 将template,search送入RPN 网络预测出目标的box和score。
4) 对score进行window penalty,即采用窗函数(汉宁窗,余弦窗等)对距离中心点较远的边缘区域分数进行惩罚。
5) 取分数最高的box中心点作为新的中心点,上一帧目标的宽高和box的宽高进行平滑加权作为新的宽高。
6) 采用新的中心点和宽高作为当前帧的box。
2 实验结果分析
本章在OTB100、VOT2018 和GOT-10k 3 个标准数据集上测试了算法的性能,并与几种先进的目标跟踪算法进行了比较。实验结果表明,本章提出的算法具有良好的跟踪性能。进行了消融实验以验证提出的模块组件对性能的提升。
2.1 实验设置
本工作采用ResNet-50作为主干网络的预训练模型。采用批量随机梯度下降对模型进行训练,批次大小为32。本工作使用权重衰减改变学习率,前5个迭代过程利用热身训练,其中初始学习率为0.001,随后每个迭代过程增加0.001,热身结束后采用学习率梯度下降对网络进行训练。共计20轮迭代过程,网络总体训练时间为50 h,实验中使用的深度学习框架pytorch为1.11.0版本,python为3.8 版 本,GPU 为NVIDIA GeForce RTX2070,CUDA 为11.3.1版本,Cudnn为8.2.1。
2.2 在OTB100上的评估
OTB100数据集由100个人工标注的跟踪视频组成,这些视频包含背景混合、光照、遮挡等目标跟踪任务中常见的困难和挑战。该数据集的两个评价指标为准确率(precision)和成功率(success rate)。计算预测框和人工标注框中心点的距离,该距离小于一定阈值时的视频帧数占总帧数的比率定义为准确率。计算预测框与真实框重叠的数值,该数值大于设定阈值即判定当前帧为跟踪成功,成功率即成功帧数与所有帧数的比值。通过在OTB100 数据集上利用一次通过测试OPE对本算法与Siam RPN++、DeepSRDCF、DaSiam RPN、CFNet、Siam FC、Siam FC++等6种算法进行比较,图6左图为准确率曲线图,右图为成功率曲线图。本章算法的准确率超过基于Transformer的Trans T[16]1.3个百分点,排名第一,成功率为68.8%,性能表现良好。

图6 在OTB100上的精确率图和成功率图Fig.6 Accuracy and success rates on OTB100
2.3 在VOT2018上的评估
VOT2018包含60个人工精确标注的短时跟踪视频序列,该数据集包括3个性能分析指标,分别是鲁棒性(robustness,R)、准确率(accuracy,A)及期望平均重叠率(expected average overlap,EAO)。鲁棒性用来衡量跟踪失败次数;计算预测框和真实框重叠率,取平均值计为准确率;期望平均重叠率是通过计算跟踪器在大量的具有相同视觉特性的短期序列上所期望得到的平均重叠率。表1给出了AOTMAF算法与其他跟踪算法的测试结果。AOTMAF的EAO 指标达到0.489,排名第一,超过基于Transformer的Tr Di MP[17]2.7个百分点。

表1 VOT2018上与多个跟踪器对比Table 1 Comparison with multiple trackers on VOT2018
2.4 在GOT-10K 上的评估
GOT-10k是一个包含了超过10 000条视频序列的大型多场景数据集,共包含560多个类别。该数据集的两个评价指标为平均重合率(average overlap,AO)和成功率(success rate,SR)。预测框与和真实框交并比取平均值计为AO,重叠率超过一定阈值下帧数的百分比计为成功率,阈值取0.5和0.75。从表2可以看出AOTMAF算法的AO 指标值为64.4,超过ATOM[21]8.8个百分点,超过基于时空记忆网络的无模板视觉跟踪器STMTracker[22]0.2个百分点。实验结果表明AOTMAF算法在不同类别目标跟踪任务中有着良好的性能。

表2 GOT-10k上与多个跟踪器对比Table 2 Comparison with multiple trackers on GOT-10k
2.5 速度、参数量及计算量
如表3中所示,本算法可以以超过86帧·s-1的速度实时运行,该算法速度超过基于Transformer的STARK,而计算量和参数量与之持平,主要因为HD-SE与WD-SE模块是轻量级结构,对网络增加的参数量和计算量可以忽略不计。
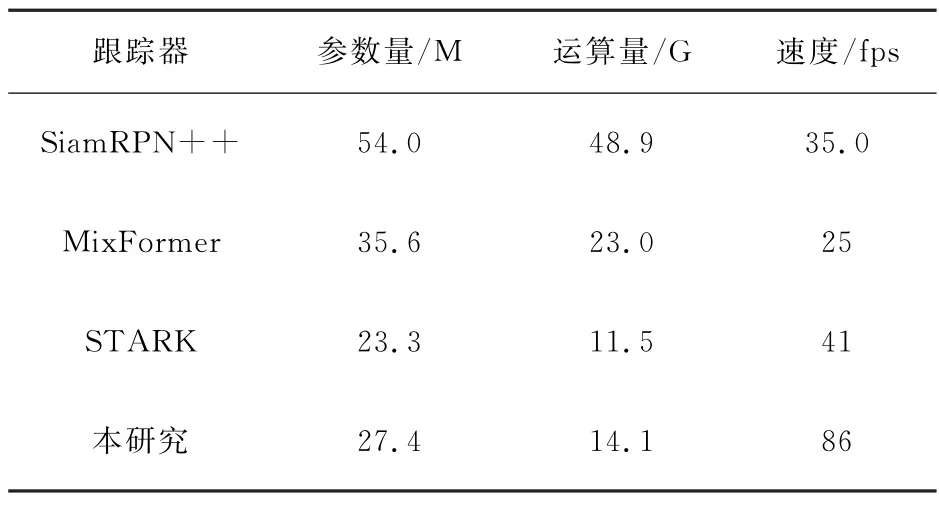
表3 参数量、运算量和速度对比Table 3 Comparison about the speed,FLOPs and Params
2.6 消融实验
为了进一步验证本章跟踪方法中渐进式随机遮挡模块(PRO)、多注意力融合模块(MAF)的有效性,本小节在OTB100、VOT2018 和GOT-10K 数据集上开展消融实验。如图7 所示,算法在OTB100数据集上进行消融实验,其中Base是指除去PRO 和MAF模块的算法。对比Siam FC 算法,PRO 和MAF 在跟踪精度上分别比Siam FC 提高7.4%和5.1%,验证了本研究所提模块的有效性。

图7 OTB100上消融实验Fig.7 Ablation study on OTB100
表4 展示了不同的模块设计在VOT2018 和GOT-10K 上进行消融实验所得到的跟踪模型的性能对比。由表4中可以看出,当算法仅引入PRO 模块时,跟踪器在VOT2018上3项指标上均有提升,在准确度上达到了64.0%,在鲁棒性和EAO 上分别提升了0.8%、0.5%;跟踪器在GOT-10K 的平均重叠提升了1.4%。

表4 VOT2018与GOT-10K 上消融研究Table 4 Ablation study on VOT2018 and GOT-10K
当仅采用MAF模块时,算法在VOT2018上的跟踪结果保持了准确度的同时,在鲁棒性和EAO上表现较好,分别达到了18.9%、48.4%;在GOT-10K 的平均重叠提升了1.6%。而当算法同时采用RPO 模块和MAF 模块时,算法的跟踪效果最好,在VOT2018数据集的精确度、鲁棒性和EAO 指标上分别达到了64.0%、18.1%、48.9%,在鲁棒性和EAO 上提升明显;在GOT-10K 的平均重叠提升2.2%。各性能指标的提升是因为PRO 模块能够由易到难地训练模型识别遮挡图像,提升了模型在遮挡情况下对判别性特征的提取能力,有效减少背景的干扰,使网络更具有鲁棒性。另外HD-SE 模块及WD-SE模块在特征图的高度维度与宽度维度进行挤压激励捕获特征图中信息,充分挖掘和融合特征图中的有用信息,提升模型跟踪性能。结合以上两点分析以及消融实验结果,说明充分利用特征图信息以及随机遮挡块的生成,使得本算法能很好的适应目标表观变化和遮挡影响,有效提高复杂环境下跟踪的精确性和鲁棒性。
3 结语
本研究提出了一种基于多注意力融合的抗遮挡目标跟踪算法,主要解决特征挖掘不充分以及模型在遮挡情况下判别性特征的提取能力较弱两类问题。本研究从特征图的三个维度去捕获有用信息,融合了特征三个维度的通道注意力及空间注意力,进一步挖掘了特征图通道信息,并对特征图中每个位置的空间依赖性进行聚合,模型应用精度得到提升。使用PRO 模块,更好地模拟遮挡图片,使网络在遮挡情况下,能够对具有较少显著特征的图片有更好的识别率。下一步工作将探索如何更好地生成遮挡区域,进行精准化遮挡,进而更加有效地将背景信息和前景信息区分开,以生成更有价值的遮挡图像,从而进一步提高模型的准确率。
