基于tesseract.js Web图片文字搜索定位浏览器扩展
2023-11-25张斌和
张斌和
(美丰农业科技(上海)有限公司,上海 200000)
0 引言
随着互联网的迅速发展和数字化内容的日益增加,图片中所包含的文字信息对于网页搜索、文本分析和信息抽取等任务变得越来越重要。然而,传统的文本搜索方法无法直接从图片中检索关键信息,这给利用图像进行准确的文字搜索和定位带来了挑战。
为了解决这一问题,光学字符识别(OCR)技术被广泛应用于将图像中的文字提取为可供计算机处理的文本形式。然而,传统的OCR方法在应用上存在一些限制,如需要专门的硬件设备和繁重的前期处理。为了提供更方便和高效的图像文字搜索定位工具,近年来在Web 浏览器中进行图像识别和OCR 的研究引起了广泛关注。
将[0,xm]区间等分为m1个子区间,并设每一个小区间为[xri-1,xri],(i=1,2,…,m1).因此,每个小区间端点xri=i·2-N/m1,(i=0,1,…,m1).设幅度修正因子函数Kc在区间[xri-1,xri],(i=1,2,…,m1)上的最佳一致逼近一阶多项式为
本研究旨在设计和开发一种基于tesseract.js的浏览器扩展,旨在为用户提供一种在Web浏览器中准确搜索和定位图片中的文字的便捷工具[1-3]。该扩展利用tesseract.js 作为OCR 引擎,结合浏览器扩展的功能,实现了直接在浏览器中识别图片中的文字、提供搜索定位功能的能力。
与传统的OCR 方法相比,基于tesseract.js 的浏览器扩展具有以下优势。首先,通过借助现有的浏览器平台,消除了对专门硬件设备和前期处理的依赖,提供了一种轻量级的图像文字搜索与定位解决方案。其次,扩展程序运行在用户的浏览器环境中,可以在保护用户隐私的同时提供本地化的图像文字处理。同时,基于tesseract.js 引擎的高性能和可靠性可以保证文字识别的准确性和效率。
在本研究中,将详细介绍基于tesseract.js 的浏览器扩展的设计与实现,并进行实验评估。将讨论扩展程序的功能、准确性和性能,并与相关方法进行比较。最后,探讨该扩展程序在实际应用领域的潜在价值,并提出改进的建议和未来的研究方向。
1 方法
本节将详细介绍基于tesseract.js的Web图片文字搜索定位的浏览器扩展的设计和实现方法。首先介绍系统架构,包括背景脚本、内容脚本和相关的JavaScript 文件。接着解释tesseract.js 的作用和OCR 引擎的组成。最后详细描述浏览器扩展的关键功能和实现细节。
1.1 系统架构
基于tesseract.js的Web图片文字搜索定位的浏览器扩展的系统架构包括背景脚本(background.js) 、内容脚本(content.js) 和相关的JavaScript 文件(tesseract.js、worker.js、tesseract-core-simd.wasm.js) 。背景脚本负责处理扩展程序的安装、右键菜单的创建和消息传递,而内容脚本则负责与当前网页进行交互和执行图像文字搜索定位的实际操作。
然而,需要认识到基于tesseract.js 的Web 图片文字搜索定位的浏览器扩展存在一些局限性。首先,扩展程序可能受到图像质量和复杂度的影响,对于低质量或含有干扰元素的图像,识别和定位准确性可能会降低。其次,扩展程序仍然依赖于tesseract.js 作为OCR引擎,其性能和准确性受到引擎本身的限制。进一步的改进和优化可能需要考虑更先进的OCR 技术和算法。
1.2 tesseract.js和OCR引擎
tesseract.js 是基于JavaScript 的OCR 库,利用Web-Assembly技术加载和运行一个OCR引擎的二进制文件(tesseract-core-simd.wasm.js)。该OCR 引擎是基于tesseract 项目的开源引擎,经过优化以便在浏览器中进行高性能的文字识别。
1.3 浏览器扩展功能
利用采集到的数据,当相关参数发生变化时,研究系统的EER是如何变化的,并且在分析测试结果的工作中,将相邻时间段内波动比较大的数据剔除掉。为了尽量避免其他条件的影响,选择机组运行正常2017年6月27日的数据进行分析。
普通本科院校的建设归根结底是应用型本科专业的建设。旅游管理专业的特点要求在教学环节及人才培养过程中加大实践教学力度,增加实践教学内容,构建系统的实践教学体系。
右键菜单创建:在图像上右键点击时,通过背景脚本创建一个右键菜单项,使用户能够触发图像文字搜索定位功能。
图像文字搜索触发:当用户选择右键菜单中的搜索图片选项时,内容脚本将发送消息给背景脚本,请求显示一个输入框以接收用户输入的搜索内容。
1.冬奥会的成功申办为冰雪产业带来了广阔的发展前景。北京冬奥会助推了冰雪运动在中国的推广与普及,同时也带动了冰雪旅游、冰雪文化、冰雪装备制造业等产业的发展。预计到2025年,我国冰雪产业总规模将达到万亿元,直接参加冰雪运动的人数可达5000万人,并带动3亿人参与冰雪运动。冰雪产业无疑有着广阔的发展前景。
图像处理与OCR实现:当用户在输入框中输入搜索内容并点击搜索按钮时,内容脚本将获取所选图像的URL,并利用tesseract.js 库和OCR 引擎对图像进行文字识别。识别的结果将与搜索内容进行匹配和定位,以便进行进一步操作。
搜索定位结果展示:搜索定位结果将以标注的方式展示在页面上,例如在识别出的文本区域周围绘制边框或标记搜索关键词。此外,还可以提供关闭按钮,供用户随时关闭搜索定位结果的显示。
基于tesseract.js的Web图片文字搜索定位的浏览器扩展具有以下关键功能:
2 实验和实现
背景脚本(background.js) :负责处理扩展程序的安装和更新以及监听消息传递。通过与内容脚本进行通信,接收来自内容脚本的搜索请求,并与图片文本识别模块进行交互。
1997年,丹麦外科教授Henrik Kehlet首先提出加速康复外科(Fast Track surgery)的理念,目前,学术界对加速康复外科普遍采用的名称为ERAS(Enhanced Recovery After Surgery)。2005年,欧洲临床营养与代谢学会(ESPEN)首先提出围术期ERAS整体管理方案。2007年,在黎介寿院士指导下,南京军区总医院全军普通外科研究所首先开展ERAS的研究应用,并发表世界首篇有关胃切除术后加速康复外科的临床结果。
2.1 实现细节
基于tesseract.js的Web图片文字搜索定位的浏览器扩展包括以下关键部分:
本节将详细介绍基于tesseract.js的Web图片文字搜索定位的浏览器扩展的具体实现和实验过程。首先介绍实现细节,包括代码中的各个部分的作用和互动。然后描述实验设置,包括实验环境、测试网页和相关的图像和文本数据集。最后展示实验结果,并对系统功能和性能进行评估。
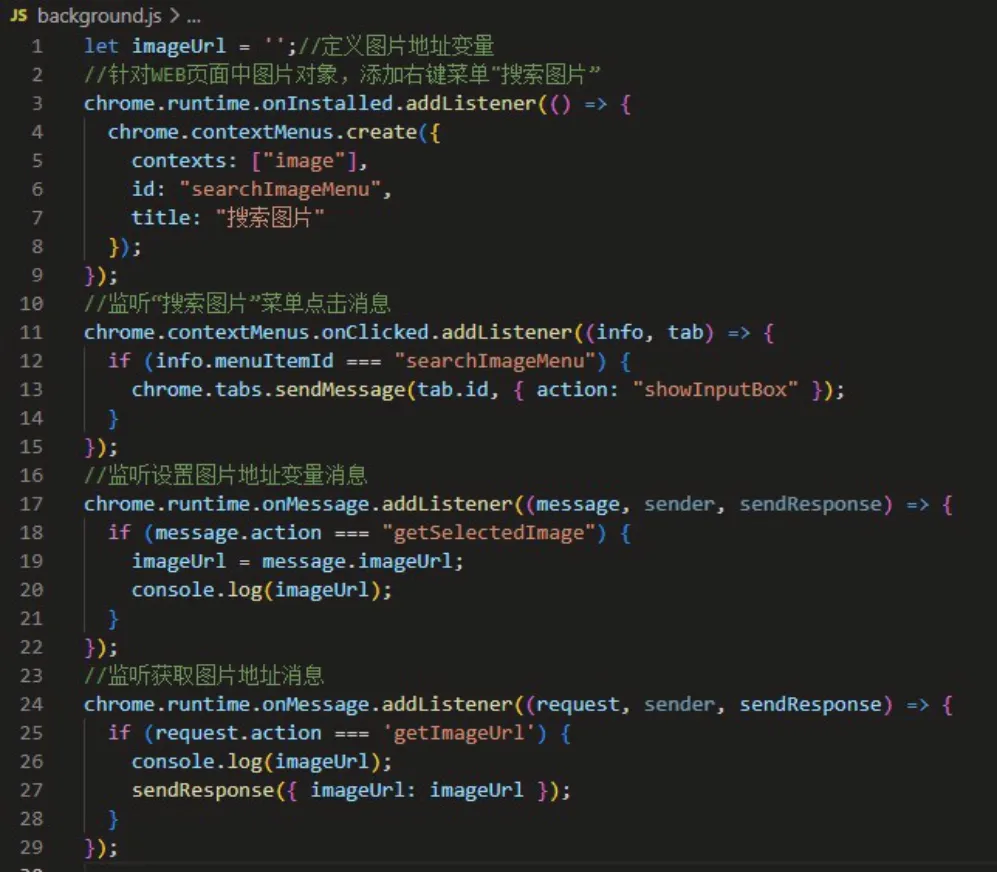
图1 background.js核心代码
内容脚本(content.js):在当前网页加载时注入,负责与网页进行交互和执行OCR 搜索定位操作。通过与背景脚本通信,触发搜索请求并接收识别结果,并将结果展示到网页上。
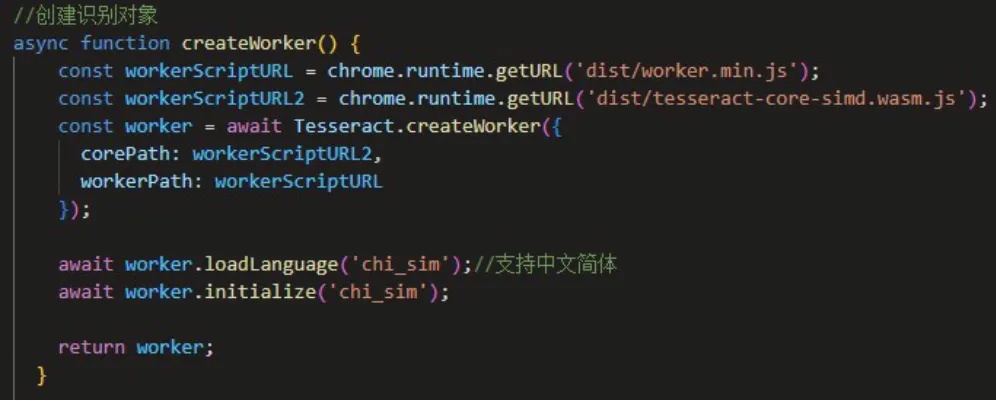
图2 content.js核心代码创建OCR识别对象

图3 content.js根据关键字搜索图片并定位
tesseract.js:作为核心库文件,负责加载和运行OCR 引擎。它与worker.js 和tesseract-core-simd.wasm.js进行交互,并提供文字识别的功能。
tesseract-core-simd.wasm.js:包含了基于WebAssembly的高性能OCR引擎。它与tesseract.js和worker.js协同工作,提供准确和高效的文字识别功能。
worker.js:作为后台工作器,运行在浏览器后台,通过与tesseract-core-simd.wasm.js文件的交互执行实际的图像处理和OCR操作。
2.2 实验设置
图像和文本数据集:从网络上获取不同类型的图片,并给这些图片添加文字,构建用于实验的图像和文本数据集。这些数据集被用来模拟真实的网页环境,以检验扩展程序对不同类型图像的识别和搜索能力。
实验环境:使用了一台配备现代Web浏览器的计算机作为实验平台。运行Google Chrome 浏览器,并确保所使用的扩展程序在该环境下正常运行。
测试网页:选择了一组包含图片中包含文字的网页作为测试对象。这些网页包括新闻文章、购物页面和博客等不同类型的内容,以保证实验的多样性。
为了评估基于tesseract.js的Web图片文字搜索定位的浏览器扩展的性能和功能,本文进行了以下实验设置:
2.3 实验结果
对基于tesseract.js的Web图片文字搜索定位的浏览器扩展进行了一系列实验,并评估了其功能和性能。实验结果表明,该扩展程序在不同类型的网页环境下能够准确地识别图片中的文字,并根据用户的搜索内容进行定位和框选。
在功能方面,扩展程序能够成功创建右键菜单,并将搜索请求和识别结果传递给后台处理。对于搜索功能,扩展程序能够根据用户的输入快速搜索并定位感兴趣的文本区域,并进行标注展示。在性能方面,扩展程序能够在合理的时间内完成图像处理和文字识别,并以可接受的速度呈现搜索定位结果。
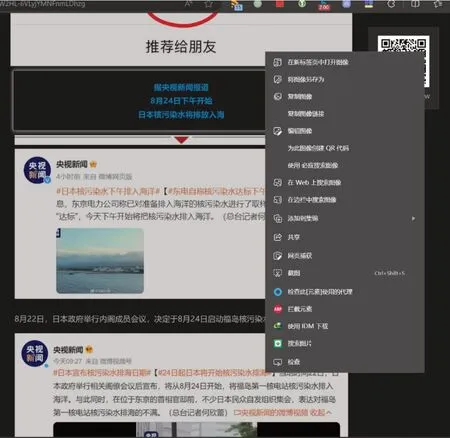
图4 浏览器扩展程序创建“搜索图片”右键菜单
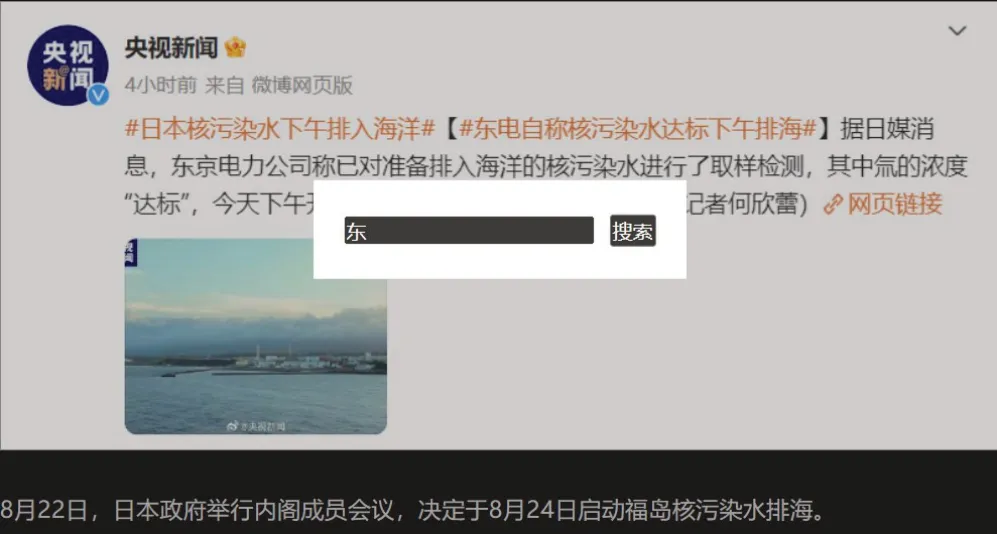
图5 响应菜单创建搜索框

图6 根据关键字完成图片文字搜索并弹出显示
3 讨论
本节将对基于tesseract.js的Web图片文字搜索定位的浏览器扩展进行讨论,包括功能评估和局限性、实际应用场景以及与相关工作的比较。
3.1 功能评估和局限性
针对扩展程序的功能,进行了评估。扩展程序在准确性方面表现出色,能够有效识别和定位图像中的文字。在搜索功能上也取得了良好的效果,能够根据用户的搜索内容快速定位感兴趣的文本区域。此外,扩展程序提供了用户友好的界面和交互方式,例如标记搜索关键词,提升了用户体验。
在投入资金、治理标准、政策法规、建设模式、运行管理等方面,北京市明显走在最前列,其将生态清洁小流域作为生态建设的重要抓手,大规模实施并取得了显著成效。而津冀两地停留在传统的小流域综合治理,生态清洁小流域建设仍处在摸索阶段,投入资金和治理标准也远低于北京市。
3.2 实际应用场景
基于tesseract.js的Web图片文字搜索定位的浏览器扩展在实际应用中具有广泛的潜在价值。首先,它可以为用户提供网页图像中文字的直接搜索和定位能力,方便用户从图片中获取所需的信息。其次,它还可以用于图像文档的搜索和整理,提高文档管理的效率和准确性[4]。
还有一些国际组织也在制定相关的标准,以推动绿色节能数据中心的建设,其中最成功的是绿色网格组织(GreenGrid)。该组织是致力于降低全球数据中心能源消耗的非营利性组织,由IBM、微软等几家知名IT公司联合建立。而创立了全球最权威的绿色建筑LEED认证体系的美国绿色建筑委员会(USGBC),也针对数据中心建筑增加了绿色认证标准。绿色网格组织已成功开发出一套提高数据中心能效的指标,包括PUE、DCiE等,这些指标都在世界范围内被广泛使用,成功地为大量数据中心的建设和运营提供能源效率比对标准[4]。
3.3 与相关工作的比较
基于tesseract.js的Web图片文字搜索定位的浏览器扩展与其他类似的图像文字搜索和定位工具相比具有一些独特的优势。首先,与传统的OCR 技术相比,它不需要额外的硬件设备和复杂的前期处理,用户可以直接在浏览器中完成图片文字识别和搜索。其次,基于tesseract.js的引擎和WebAssembly技术,扩展程序提供了高性能的文字识别功能,能够快速和准确地处理图像中的文字。
然而,与其他类似扩展和工具相比,基于tesseract.js的浏览器扩展仍然存在一些局限性。例如,某些专用的OCR 软件和服务可能提供更高级的文字识别和定位功能,但它们通常需要付费或在计算能力方面更为要求严格。此外,一些商业化的图像处理和OCR解决方案可能在扩展程序中尚未完全覆盖的领域中具有一定的竞争力。
在WIFI热点较少的地方,定位精度较低,笔者用高德地图开启WIFI定位,精度只有74m。但是现在城市每个地方都充斥着WIFI热点信号,尤其是各大商场、高层建筑等WIFI热点充分的地方,像室内位置服务商WIFI SLAM能够通过重力感应和指南针功能,同步脚步的移动,可定位的精确度在10m以内。
4 结束语
设计和实现基于tesseract.js的Web图片文字搜索定位的浏览器扩展,旨在为用户提供在Web浏览器中准确搜索和定位图片中文字的便捷工具。该扩展利用tesseract.js 作为OCR 引擎,并通过借助WebAssembly 技术实现了高准确性的文字识别和搜索定位功能,提供了直接从图像中获取所需信息的方式。
Optimization of Aeroengine Shop Visit Cost in its Service Life Cycle
本研究的主要贡献如下:
首先,提出了基于tesseract.js 的Web 图片文字搜索定位的浏览器扩展的概念和设计。通过结合现有的OCR 技术和Web 浏览器技术,实现了一个轻量级、方便和高效的图像文字搜索定位工具,使用户能够在浏览器中直接操作图像并提取其中的文字信息。
其次,详细介绍了扩展程序的架构和关键功能。通过背景脚本、内容脚本和相关的JavaScript 文件的协同工作,扩展程序能够与浏览器平台和OCR引擎进行交互,实现图像处理、文字识别和搜索定位等功能。
实验结果展示了基于tesseract.js的Web图片文字搜索定位的浏览器扩展在不同类型的网页环境下的准确性和性能。实验评估表明,该扩展程序能够快速识别图片中的文字,并提供准确的搜索定位结果,为用户提供了一个方便和高效的图像文字搜索定位工具。
尽管基于tesseract.js的Web图片文字搜索定位的浏览器扩展在实验中展现出了良好的功能和性能,但也存在一些局限性和改进空间。改进方向可以包括优化图像处理算法、提高识别准确性,以及扩展更多实际应用场景的适用性。
SHT11的初始化时序如下:当时钟SCK高电平时信号DATA翻转为低电平,紧接着 SCK 变为低电平,随后是在SCK时钟高电平时DATA翻转为高电平,如图3所示。后续命令包括3个地址位和5个命令位,主要命令包括温度测量命令(03H),湿度测量命令(05H),读状态寄存器指令(07H),和写状态寄存器指令(06H)。
其中,2010-2016年郑州、开封、洛阳、新乡和焦作5个城市的接近中心度均高于平均值,这些城市因经济实力强、基础设施完善、交通网络完善,与其他节点城市的旅游经济距离较近,旅游经济交流阻碍较少,联系较为紧密。在2010年漯河、信阳、驻马店3个城市的接近中心度全省最低为51.51,但在2013-2016年漯河、信阳和驻马店与网络中其他节点城市的旅游经济距离不断缩短,逐渐摆脱中心城市的控制。而商丘和济源因旅游发展动力不足等原因,与其他节点城市间的旅游经济距离增大,逐渐被郑州、开封、洛阳等中心城市所控制,在2013-2016年接近中心度达全省最低值。
未来工作可以进一步探索基于深度学习的OCR技术和算法,以提高文字识别的准确性和效率[5]。此外,可以考虑进一步优化扩展程序的用户界面和交互体验,使其更加友好和易用。
基于tesseract.js的Web图片文字搜索定位的浏览器扩展在图像文字处理领域具有广泛的应用潜力,可以在网页搜索、文本分析和信息抽取等任务中发挥重要作用。未来的研究可以进一步拓展应用场景,并深入探索该领域的技术创新和改进方向。
