融合情境信息的非支配排序多目标进化推荐算法
2023-11-22金友振夏小云
朱 鑫,金友振,夏小云
(1.浙江师范大学 数学与计算机科学学院,浙江金华 321004;2.嘉兴学院 信息科学与工程学院,浙江嘉兴 314001)
随着移动设备的普及,推荐系统可以很容易通过手机、手环、平板等感知设备获取情境信息.情境信息又称为上下文信息,是指在用户产生行为数据过程中与情境相关的信息,如时间、地点和心情等,具有实时性和时间多样性的优点.[1]因此,在推荐算法中融入情境信息,有助于提高算法的性能.情境信息在推荐算法中发挥着越来越重要的作用.旅游软件可以利用地理位置信息为用户推荐旅游景点和住宿信息,[2]餐饮软件可以利用时间信息为用户推荐菜品,[3]音乐软件则是通过心情标签为用户推荐歌曲.[4]本研究将融合情境信息降低系统对历史行为数据的依赖,提升推荐精确度,并结合多目标进化算法对推荐列表进行优化.
1 相关研究
1.1 聚类技术
聚类方法属于分类思想或者分簇思想,指把要分类的用户按照用户间的相似性进行划分.划分后,同一类内两两用户的相似度最大,不同类间的用户相似性最低.聚类方法包含划分式聚类和计算密度聚类以及划归层次聚类.[5]本文采用的K-means++聚类方法是K-means算法的改进,优化了选择初始质心的方法,属于划分式聚类方法.[6]该方法初始化簇中心时,逐个选取各簇中心,且距离其他簇中心越远的样本越有可能被选为下个簇中心.
1.2 协同过滤推荐算法
协同过滤推荐是在基于内容过滤推荐技术之后发展起来的,已逐渐成为业界推荐系统中主流的种类,其应用范围广泛、影响效果深远.按照“物以类聚,人以群分”的思想,协同过滤推荐主要分为两大类:基于物品的协同过滤推荐和基于用户的协同过滤推荐(User Collaborative Filterting,User CF).[7-8]前者考虑的是在推荐过程中,推荐的内容或者项目之间存在着一定的相似性,根据物品相似性来判断用户喜好进行推荐;后者则是通过计算用户之间的相似性来推荐,两个用户之间相似性越大,则他们喜好的内容也越相似,根据用户对物品的已评分项来为其相似用户推荐评分较高的物品项.[8]
1.3 多目标优化
多目标优化即在问题求解过程中,需要同时优化多个目标函数.通常情况下,求得一个目标函数的最优解时往往是以损失其他目标函数为代价的,但多目标优化模型可以很好地解决这类问题.[9]多目标优化问题的数学描述如下:
(1)
其中,x∈D表示解向量空间,x=(x1,x2,…,xi),xi表示第i个解向量;F(x)为目标函数集;gi(x)和hj(x)为等式或者不等式约束条件集合,p和q分别表示等式与不等式个数.[10]
2 融合情境信息的聚类推荐
2.1 划分簇类
利用K-means++算法对数据集进行一次聚类,使得算法的收敛情况不再严重依赖于簇中心的初始化状况,相较于K-means算法求得K个聚类中心再做聚类,K-means++算法的可解释性更强.[11]算法过程如下:
(i)从数据集X中无序地挑选某个数据点即某个用户对所有物品评分来作为第一个划分簇类的簇心点ci;
(ii)求出其余数据点与上一步选择的簇心点之间的路径长度,用D(x)表示,并求出簇中心之外剩余数据点被挑选为下一个簇中心的概率P(x),依概率赌盘选择最大概率值所对应的样本点作为下一个簇中心:
(2)
(iii)重复第(ii)步,直到选择出k个聚类中心.
基于选取的k个聚类中心,将数据集进行聚类,使聚类后类内数据相似性最大,而类间数据差异性最大.算法步骤如下:
(I)挑选出的簇心点当作每一簇的簇心;
(II)求出所有数据点与挑选出的簇中心之间的差异性,再把这些数据点划分到与之差异性最小即相似性最大的簇中心所对应的簇中;
(III)通过上一步的划分再次求出相应的中心点;
(IV)将上述第(II)步和第(III)步重复运行,直至满足设置的退出条件.
2.2 改进的余弦相似度计算
相似度的计算影响了聚类效果的好坏.基于改进多目标进化推荐算法[12]中采用余弦相似性度量算法计算用户之间的相似度,尚未将客户的不同喜好程度融入到计算中.通俗来说,余弦相似度没有将用户的打分尺度考虑进去,如有的用户打分范围在1~5之间,而有的用户在2~4之间(即不太愿意给最高分和最低分).例如,有两个用户对两个item打分,item的向量分别为(10,2)、(10,3).但用户1习惯打高分,他认为最差的item也能得到6分,而用户2较严格,4分在他看来已经足够高.因此,通过用户对项目的评分减去各个用户的评分均值来消除不同用户评分标准不同的问题,公式如下:
(3)
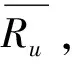
由式(1)可以看出,减去用户的评分项平均值解决了余弦相似度仅考虑向量维度方向上相似的问题,在相似度计算中考虑到了用户对评分项存在评分程度偏好的问题.
2.3 融入时间衰减系数的预测评分
用户的兴趣会随着时间的增加而降低,即推荐过程中存在时效性较强的因素时,忽略时间会降低推荐的准确度从而导致推荐效果差.例如:在影视推荐环境下,用户对最新好评电影以及往年好评电影的选择会更倾向于前者.在实际中,用户的兴趣偏好是处于动态变化的.相对于早期的用户行为,近期的用户行为对于推荐更有时效性,能提升推荐性能.本文将时间情境信息融入对影视项的预测评分中来追踪用户兴趣偏移.用户u对项目i的预测评分公式如下:
(4)
其中,wuv表示簇内用户u和v之间的相似度,S(u,M)表示与评分用户爱好最为相似的一组用户集合,集合包含M个其他的用户.若用户v对某类型影视项有过观看行为,令rvi=1;否则,令rvi=0.
融入时间衰减函数后,计算用户对影视项的相似度时则需要进行改进,加入时间情境信息后的函数如下:
(5)
其中,t0表示当前时间,tvi表示评分用户v对评分项i的历史行为时间.
3 非支配进化的情境推荐
本节将介绍通过非支配排序的多目标进化算法对推荐项求均衡解,旨在平衡推荐列表的精确度和多样性.
3.1 推荐列表优化评测指标
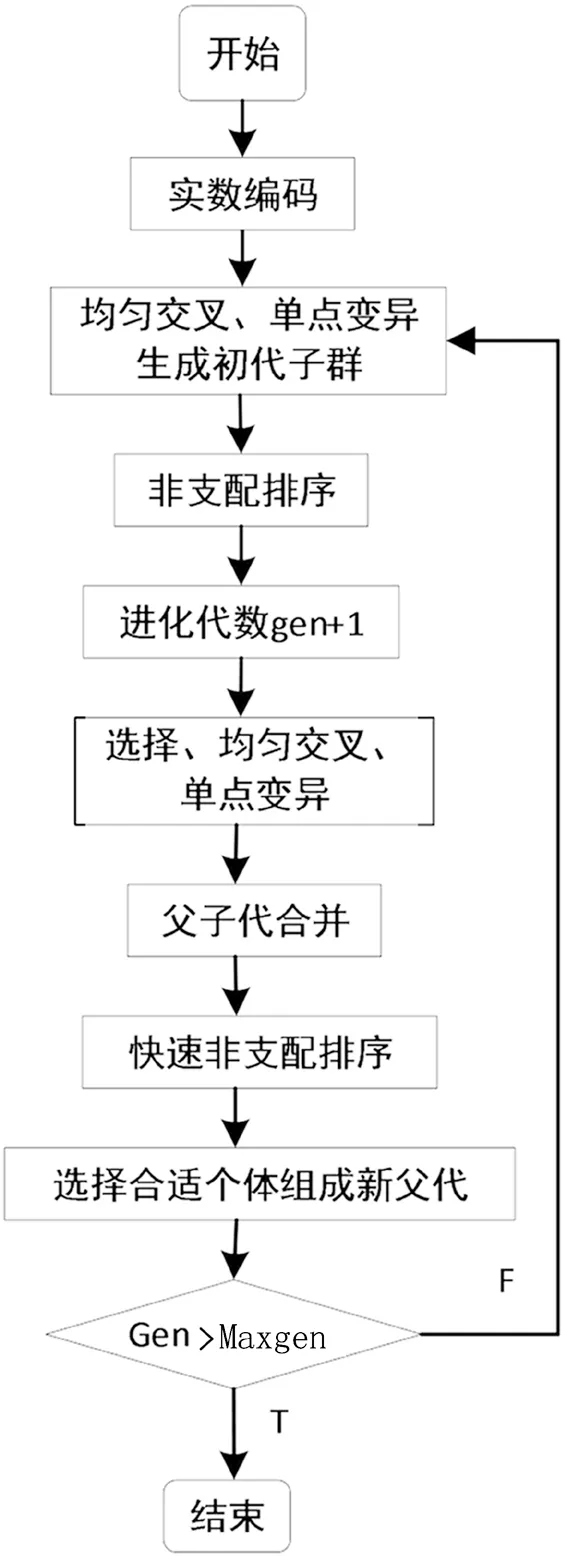
图1 基于非支配排序的多目标进化算法流程
针对推荐列表的优劣问题,有两个冲突的评价指标需要通过多目标进化算法进行平衡.第一个平衡指标是推荐列表的精确度.关于精确度计算是无法通过具体的参数计算用户真实偏好的,因此,采用项目的预测评分进行衡量.[15]用户α对项目c的预测评分用Prαc表示,用户簇群大小用M表示,公式定义如下:
(6)
其中|M|表示簇群M中的用户数量,C表示推荐列表的长度.
第二个指标是评价推荐列表的多样性.多样性指标可分为用户间多样性、用户内多样性和覆盖率.[16]为了降低计算复杂度,本文选用覆盖率进行评价,覆盖率越大表示推荐列表的多样性越好.具体公式如下:
(7)
其中,Ldif表示相同簇群中对于推荐用户推荐列表的不同推荐项,L表示推荐用户的所有推荐项目.
基于非支配排序多目标进化优化利用了进化思想,并对多个目标函数同时求取最优解.[17]本文中,将使用多目标优化来最大化以上两个评测指标.最终的目标函数如下:
(8)
3.2 基于非支配排序的多目标进化
结合具体多目标进化算法中的编码策略、交叉策略和遗传策略以及变异算子对相同簇群中的推荐列表求得均衡解,具体算法流程如图1所示.
在算法输入端,将观影用户对影视项的分数进行实数向量编码,每个观影用户关于全部影视项的评分则表示为种群中的个体.将所有用户进行矩阵排列.假设簇群大小即用户数量为n,评分项目数量为m,则矩阵的规模为n×m,如表1所示.

表1 用户评分表

图2 均匀交叉
其中,scoren,m记为用户n对项目m的评分.种群中个体的等位基因不会重复,因此,将编码后的染色体进行均匀交叉操作.交叉算子的过程表述如下:挑选两条父代染色体,对同一项目具有相同评分项的等位基因识别并遗传给子代;剩余的等位基因通过[0,1]随机数进行选择;若产生的随机数大于0.5,则从第一条父代染色体处获得相同的等位基因;否则,从第二条父代染色体处获得等位基因.交叉操作如图2所示.
关于变异算子的选择,本文与其他多目标优化算法一样,使用同样的标准单点变异.单点变异是通过随机选择一个基因并生成一个随机数:若随机数大于0.5,则从推荐项目中随机挑选一个未被评分的项目;否则,基因保持不变,从而保证了变异基因与推荐列表中基因的差异性.
4 实验与分析
采用开源的Movielens-1M影视数据集进行验证,该数据集采集自20世纪90年代末到21世纪初,是由用户提供的电影评分数据.数据集含有6000名用户对4000部电影的100万条评分数据,分为用户电影评分表、用户信息表和电影信息表.
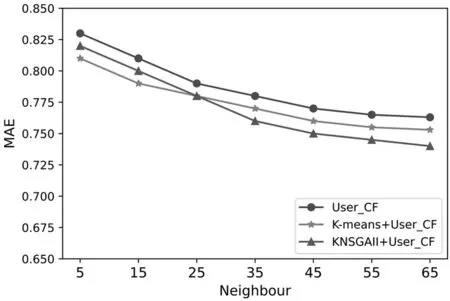
图3 MAE实验图
为了评估本文提出的KNSGAII-UserCF算法的性能和有效性,考虑从两个方面验证推荐结果的有效性.
第一个是评分预测,预测指标通常采用平均绝对误差MAE预测用户看到未评分的项目时对项目进行多少评分.平均绝对误差定义如下:
(9)

由图3的实验结果可知,将邻居用户划分范围,当邻居用户数目变大时,提出的模
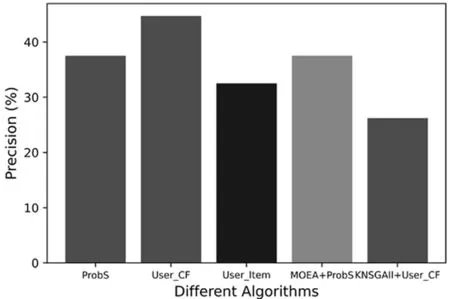
图4 精确度指标评价
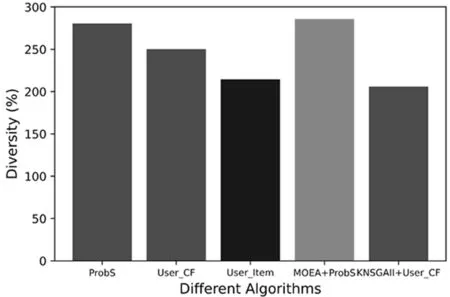
图5 多样性指标评价
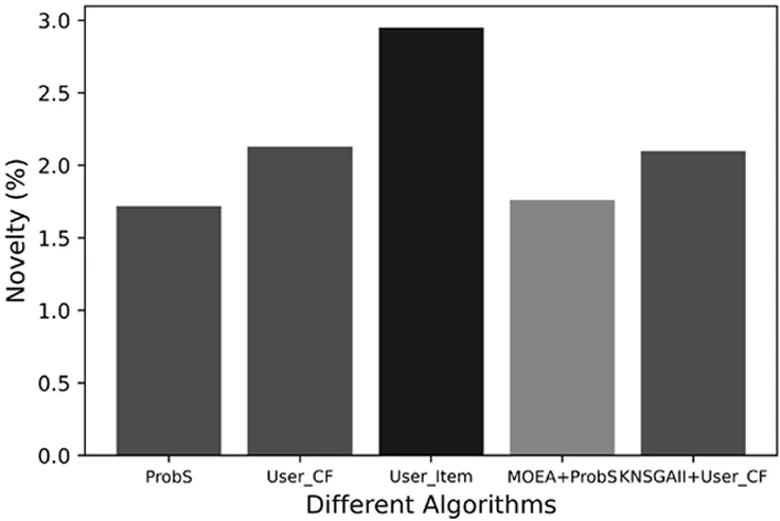
图6 新颖度指标评价
型平均绝对误差慢慢地趋于稳定值.若近邻用户数量为5时,绝对误差最大.而本文提出的算法在近邻用户大于25时,相较于对比算法的性能略好.
第二个评测指标是Top-N推荐.[20]预测评分项目的精确度、多样性以及新颖度,实验数据仍采用同一个数据集.新颖度是指推荐列表中推荐项的流行度,如果推荐列表中的项目越受欢迎,则表示推荐列表的新颖度越高.新颖度定义公式如下:[21]
(10)
其中,U表示推荐系统中所有用户的数量,L表示推荐列表的长度,Ni表示对项目i的已评分数量.从精确度、多样性、新颖度等方面与其他算法比较,如基于二部图网络的推荐、[15]基于内容和用户的协同过滤推荐[14]和基于进化算法的推荐[21].关于评价指标精确度、多样性和新颖度的实验结果如图4、图5、图6所示.
从图4中可以看出,本文算法在评价推荐列表的精确度方面略低于基于二部图网络的推荐、基于协同过滤的推荐和基于改进的多目标进化推荐.图5中则展示了在评价推荐列表多样时,多样性的指标与对比算法基本持平.新颖度作为推荐列表的评价指标也变得越来越重要,一个新颖度高的推荐列表会给用户带来惊喜,从图6可以看出,本文算法比对比算法在新颖度方面略好.总的来说,本文通过非支配排序的多目标进化算法在平衡推荐列表精确度、多样性、新颖度时,牺牲了一定程度的精确度来实现推荐列表更高的多样性和新颖度.
表2是对比算法与本文算法在三个评价指标方面的具体数值.
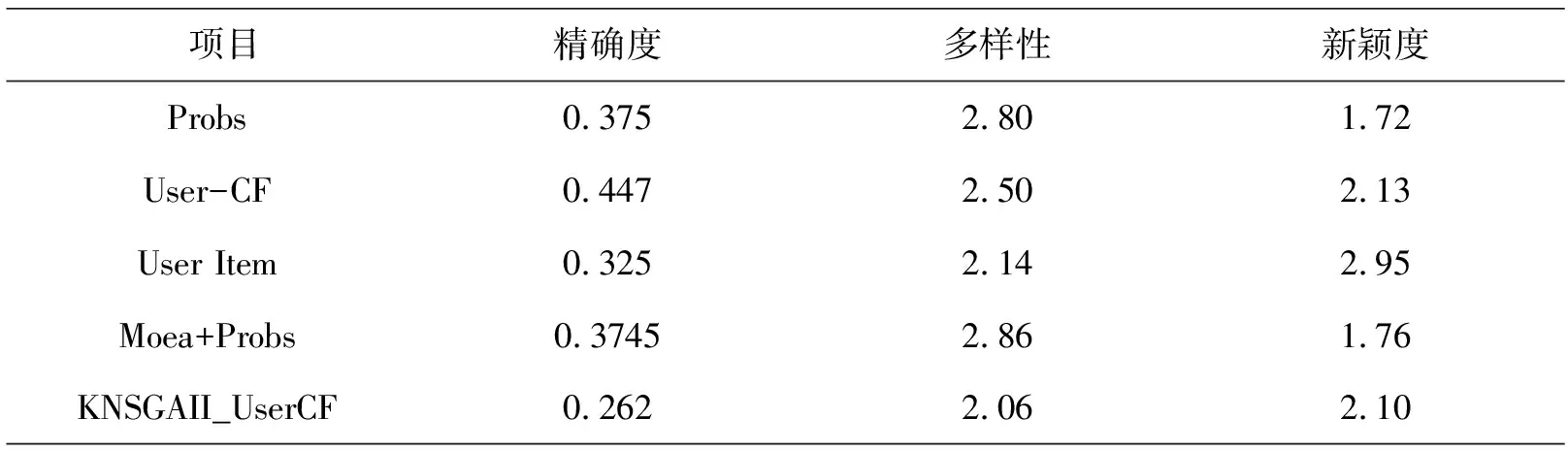
表2 评价指标
由表2可知,本文提出的方法在精确度方面略微低于对比算法,在多样性方面效果与基于用户的协同过滤推荐相同,而新颖度仅低于基于用户的协同过滤,相较于基于项目的推荐和二分网络的推荐新颖度数值都高出15%左右,故本文所提算法给出的推荐列表新颖度高.
5 结语
本文提出了一种基于非支配排序多目标进化的情境推荐算法,通过构建k-means++融合情境时间推荐模型,减少计算时间复杂度和提高簇类用户间相似性,最大化用户对推荐列表的满意度,并将推荐列表通过进化算法特性同时优化精确度和多样性目标.实验结果表明,融合了情境信息的多目标进化推荐,在做评分预测时能够降低预测的误差,给出TopN推荐时,一定程度上提高了推荐项的精确度、多样性和新颖度.由于本文提供的数据集稀疏程度较高,未做处理的数据会使实验存在不稳定性,表明提出的算法鲁棒性、稳定性还有待提高.应进一步处理数据稀疏问题,以提升算法的效果,提高推荐效率.
