一种融合注意力机制的跨模态图文检索算法
2023-11-22吴春明
杨 迪,吴春明
(西南大学 计算机与信息科学学院,重庆 400700)
0 引 言
随着移动设备智能化,社交软件的普及,人们可以更加便捷地生成各种不同模态的多媒体数据(图像、文本、视频、音频等)。面对这些海量数据,人们的检索需求从传统的单模态检索转变为跨模态检索。跨模态检索是指给定一种模态的查询样本,得到与查询样本语义相似的其他模态的样本[1],如文本/视频检索图像,图像/视频检索文本,该技术的关键在于如何有效提取不同模态数据的特征,并将这些特征以适宜的方法进行相似性度量。以图文检索为例,图像由像素构成,文本由单词序列组成,它们之间的相似度不能直接比较,这种底层特征异构所带来的“语义鸿沟”是跨模态检索首先要解决的重要问题。
传统的跨模态检索主要采用典型相关性分析(Canonical Correlation Analysis,CCA)方法,如Yan等人[2]利用该方法来寻找图像和句子的最大相关性。随着深度学习技术的发展,跨模态检索普遍解决方案变为从不同模态提取特征,再将这些特征映射到深度空间中,在该空间进行距离计算,经过学习之后,该空间鼓励相似样本对互相靠近,不相似样本对互相远离。Wang等人[3]利用CNN和WCNN分别提取图像和文本特征,证明这种基于深度神经网络提取的特征能有效提高检索精度。Dong等人[4]提出图卷积网络(Graph Convolutional Network,GCN),利用样本的邻接关系重构样本表示并基于局部图重构节点特征,从而获取隐藏的高级语义信息,但节点更新较为复杂,计算代价巨大。Peng等人[5]提出了一种跨模态生成对抗网络(Cross-Modal Generative Adversarial Networks,CM-GAN),利用生成模型和判别模型互相博弈来生成更具细粒度的多模态特征表示。Bahdanau[6]首次将注意力机制应用到机器翻译领域,该机制能聚焦重要部分而忽略不重要部分的特性,使得其在计算机视觉和自然语言处理领域取得了一系列成绩,学者们也开始将注意力机制应用到跨模态检索领域。Nam等人[7]提出双重注意力网络(Dual Attention Networks,DANs),利用视觉和文本注意力机制来捕获图像区域和单词之间的相互关系;Lee等人[8]提出堆叠交叉注意力方法来捕捉图像区域和单词的潜在对齐;Li等人[9]提出DMASA方法,利用多种自注意力机制从不同角度提取图像文本细粒度特征。
上述工作都在一定程度上提升了检索效果,但也存在两个主要问题:一是仅考虑了局部特征或者全局特征的一种,导致特征关键语义不够全面,信息表征不够完善;二是忽略了模态间有效交互,由于不同模态所含信息量不等,这会导致特征语义表达不够充分。针对这些问题,该文提出了一种融合注意力机制的图文检索算法。首先,利用ViT和Bert模型得到包含上下文信息的图像和文本特征;其次,利用注意力机制融合不同模态信息即用文本信息来表示图像,用图像信息表示文本;再次,将注意力机制引进到特征提取过程,利用融合不同模态信息的特征向量来获得新的全局特征表示和局部特征表示;最后,融合新的全局特征向量、局部特征向量和原始特征向量来表征数据。由于该方法更好地融合了全局和局部特征,因而取得了更好的检索精度,通过在Wikipedia数据集上与6种经典方法的对比实验,证明了该方法的有效性。
1 网络结构
整个模型结构如图1所示,包含图像编码模块、文本编码模块、交互模块3个部分。其中,图像编码模块负责图像特征提取,首先将图像分成块并加入位置信息编码,通过输入ViT模型得到全局特征和局部特征,作为图像的基础特征表示;文本编码模块负责文本特征提取,首先将文本数据通过词嵌入方式转为词向量,输入Bert模型得到文本的全局表示和单体表示,作为文本的基础特征表示;交互模块又分为模态内注意模块和模态间注意模块,为了挖掘语义相似不同模态数据间的内在联系,该文利用两个模块分别获取图像和文本新的局部特征和新的全局特征。最后,将这些特征与基础特征拼接,作为图像和文本的最终特征表示。

图1 模型结构
1.1 图像编码模块
Transformer模型的自注意力机制能对长距离依赖问题建模,能充分利用上下文信息从而获得有效的全局信息,因此,文中图像特征提取过程使用基于Transformer编码器的ViT模型。ViT[10]是Google团队提出的基于Transformer的一种图像分类模型,该模型将二维的图像数据转换成一维块序列使得Transformer能处理图像。具体来说,将输入图像的像素调整为224×224,把图像分割成大小为16×16、数量为196的patch块,加入位置信息编码并将其按顺序展平转化为向量,输入预训练好的ViT模型,得到输入图像的特征表示V={vcls,v1,…,vi,…,vn},其中vcls表示图像的整体信息,n为图像块的数量,vi为第i个图像块的特征向量。特征提取整体过程如图2所示。
1.2 文本编码模块
在图文检索中,文本通常以句子或长段落形式存在,而Bert模型的双向编码结构使得其在提取长文本数据特征方面有着突出优势。Bert[11]模型也是基于Transformer的自然语言处理模型,该模型使用Transformer Encoder 作为特征提取器,具有强大的语义信息提取能力。因此,该文利用Bert模型进行文本特征的提取。如图3所示,首先,将文本数据通过word2vec模型转化为词向量,然后,输入到预训练好的Bert模型得到文本特征表示T={tcls,t1,…,tj,…,tl},其中,tcls为文本的全局表示,l为文本长度,tj为第j个词的特征向量。

图2 图像特征提取

图3 文本特征提取
1.3 交互模块
注意力机制能选择性地关注重要信息,能为其赋予更高的权重,因而能有效提取关键特征。在图像和文本编码模块,利用注意力机制对图像和文本的基础特征进行了提取,但这种注意计算仅局限在同一模态内,即图像块到图像块的注意和单词到单词的注意,然而语义相似的图像和文本数据所包含的信息量不等,不同模态所关注的内容也不尽相同,因此在进行注意计算的时候应充分考虑不同模态间的相互影响,即图像块到单词的注意和单词到图像块的注意。因此,为了融合不同模态的特征并挖掘不同模态的内在联系,在本模块中,结合注意力机制分别设计了模态内注意模块和模态间注意模块,用来寻找新的局部特征映射和全局特征映射。
图像数据相比于文本数据具有更多的细节信息,文本数据比图像数据有更多的语义描述,为了凸显它们的内在关系,该文用文本信息来表征图像,用图像信息来表征文本。首先计算每个图像块和每个单词的相似性:
(1)
每个图像块的文本表示为:
(2)
同理,每个单词的图像表示为:
(3)
其中,exp是以自然数e为底的指数函数。在Transformer中,通过点乘的方式来计算两个向量的相似性,而这里的图像和单词相似性矩阵乘与该方式本质上一致。
1.3.1 模态内注意模块

(4)

(5)
(6)
(7)
以相同的方法计算融合图像信息的文本局部特征向量Tp。
1.3.2 模态间注意模块
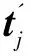
(8)
βj的计算过程与公式(6)(7)相同。同理可以得到融合图像信息的文本全局特征向量Tw。
最后,融合新的局部特征向量Vp、Tp,新的全局特征向量Vw、Tw及基础全局特征向量vcls、tcls作为图像文本的最终特征表示VF、TF,分别见公式(9)和(10),其中[;]表示向量的拼接。
VF=Ffusion[Vp;Vw;vcls]
(9)
TF=Ffusion[Tp;Tw;tcls]
(10)
1.4 损失函数
为了保证共享空间中语义相似的图像-文本对距离足够近,不相似图像-文本对的距离足够远,该文采用三元组排序损失函数[12]。对于图像数据集,构建三元组{VF,TF+,TF-},其中(VF,TF+)表示锚点VF的正样本对,(VF,TF-)表示负样本对,即与图像样本语义不相似的文本对,以相同的方式构建文本三元组{TF,VF+,VF-}。通过最小化相似样本对之间的距离,同时最大化不相似样本对的距离,保证图像文本模态的一致性。由于跨模态检索任务是双向检索,因此损失函数定义为:
L=[S(VF,TF-)-S(VF,TF+)+λ]++
S(TF,VF-)-S(VF,TF+)+λ]+
(11)
其中,λ是一个常量,用来保证相似样本对得分比不相似样本对得分大于一个固定值,[x]+≡max(0,x)。S函数表示图像文本对的相似性得分,以S(VF,TF-)为例,具体的计算公式为:
(12)
算法流程如表1所示。

表1 跨模态检索算法
2 实验结果与分析
2.1 数据集
Wikipedia[13]是跨模态检索研究普遍使用的数据集,来源于维基百科中的代表文章,并基于对应文章补充相关图像,整个数据集共有2 866个图像文本对,这些文本以短段落(至少70个字)描述图像,包含10个语义类。
2.2 评价指标
该文采用跨模态检索研究中通常采用的精确率-召回率(Precision-recall)曲线和平均精度均值mAP(Mean Average Precision)作为评价指标。
PR曲线横坐标为召回率,纵坐标为精确率,纵坐标值越大表示该方法性能越好。精确率P、召回率R计算公式如下:

(13)

(14)
其中,a表示检索返回中的正样本数量,b表示检索返回中的负样本数量,c表示数据集中没有返回的正样本数量。
mAP是AP的平均值,该指标综合考虑了排序信息和精确率[14]。取值越接近1代表方法性能越好。给出查询数据和n个检索结果,AP计算公式如下:
(15)
其中,R是测试集中的正样本数量,P(i)表示前i个检索结果的精确率,若检索结果为正样本,则δ(i)=1,否则为0。Q代表查询次数,最终mAP值公式为:
(16)
2.3 模型对比分析
基于验证文中算法有效性的目的,选取了KCCA[15]、DCCA[16]、SCM[17]、ACMR[18]、DSCMR[19]、DMTL[20]共6种方法进行对比实验。其中,KCCA利用核函数改变特征维度再进行关联分析,解决了CCA不能处理非线性关系的不足;DCCA将深度神经网络与CCA相结合,从两个视图学习非线性投影,比KCCA模型更为简洁;SCM是在CCA基础上将无监督相关和有监督语义结合的匹配算法;ACMR将对抗机制引入到语义融合层面,丰富了特征空间内容,并利用三元组约束保证语义相同的不同模态表示差异最小;DSCMR充分利用标签信息有效学习了不同模态公共表示,并通过最小化标签空间和公共表示空间的判别损失,以监督模型学习判别特征;DMTL由两个多模态特定的神经网络和一个联合学习模块组成,是一种迁移已标记类别的知识,以提高在未标记的新类别上检索性能的学习方法。
实验结果如表2所示。
由表2可知,文中方法的平均mAP达到了0.699,不管是图像模态检索文本还是文本模态检索图像,均高于其他方法。对比DMTL方法,文中方法图像检索文本的mAP值从0.633提高到0.687,文本检索图像的mAP值从0.652提高到0.711,平均mAP值从0.642提高到0.699。整体来看,基于深层结构方法在检索效果上大于浅层结构方法,这得益于深度学习强大的特征学习能力,可以有效捕捉样本间非线性关系,从而获取更能代表数据的关键特征。现用的跨模态检索方法大多将不同模态的数据映射到公共空间,这些方法只是简单将图像文本全局特征或局部特征对齐,而文中方法利用注意力机制充分挖掘同一模态内细粒度局部信息和不同模态间交互全局信息,全面考虑两种信息从而提高了模型的检索准确率。

表2 跨模态检索方法mAP(Wikipedia数据集)
为了进一步验证文中方法的有效性,在数据集上绘制所有对比方法的PR曲线,如图4所示。

图4 图像检索文本PR曲线
由图4可知,文中方法明显优于其他对比方法,当召回率值为0.4时,仅DMTL方法的精确率与文中方法基本持平,当召回率为其他值时,文中方法的精确率均高于其他方法。
2.4 注意力可视化
为了更加直观地表现在交互模块中图像对文本和文本对图像的注意,该文进行了注意力可视化分析,结果如图5所示。

图5 注意力可视化
由图5可知,图像对文本的注意力主要集中在单词“football”“World”“Cup”和“FIFA”上,即图中文字描述划线部分。文本对图像的注意力权重主要集中在球员、球迷和场地等部分,即图中标注区域。
2.5 对照实验
考虑到特征提取器及注意力机制对整个检索模型性能的影响,该文通过改变特征提取器类型和是否添加注意力机制等方式进行了一系列对照实验。为公平起见,对于图像特征提取器为CNN类的实验,该文均采用预训练好的VGG16的最后一个池化层作为图像特征向量。
实验结果如表3所示,由方法二四六和方法一三五对比得知,添加了注意力机制的方法在检索效果上显著优于没有添加注意力机制的方法。这是因为融合注意力的方法能选择性地关注不同模态数据间的重要信息部分,进而提取到更完善的语义特征。通过方法一和三、二和四比较得知,图像特征提取器为ViT模型类的方法与为CNN类的方法效果存在差异,但差距并不明显。通过方法六和四、五和三对比得知,文本特征提取器为Bert类模型的方法比为LSTM类方法的效果更好,一是因为Bert模型是双向编码模型,能同时考虑上下文信息,具有更强大的语义提取能力,二是因为Wikipedia数据集中多以长文本为主,在处理长距离依赖问题上,Bert模型有着更为优秀的表现。

表3 对照实验mAP结果对比(Wikipedia数据集)
3 结束语
针对图文检索研究,该文提出了一种融合注意力机制的跨模态检索算法。为了综合考虑全局特征和局部特征对检索效果的影响,基于注意力机制提取语义表达更充分的全局特征和局部特征,并将这些特征有机融合,使得模态数据特征信息表达更完善;同时,为了挖掘语义相似但模态不同的数据内在关系,通过注意力机制融合不同模态信息,从而提取更好的特征表示。实验证明,提出的算法优于目前已知方法,未来将针对文本描述为中文的图文检索做进一步研究。
