基于属性组权重的分类数据离群检测
2023-11-22张凯棋宋亦静
张凯棋,宋亦静,陈 鑫
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
离群数据(outlier)是指明显偏离其他数据对象,可能是由于一种不同于其他数据对象的机理而产生的数据对象[1]。由于离群数据蕴含着大量丰富的、有价值的潜在的信息,已广泛地应用在无线传感器网络[2]、肿瘤检测[3]、入侵检测[4]、欺诈检测[5]、网络安全[6]、数据清理[7]、工业系统[8]、地球科学[9]等领域。针对高维数据,由于出现了“维度灾难”,严重影响了离群检测效果。属性分组是指根据属性之间的相关性实现属性分组,并降低了离群检测维度,可有效地缓解“维度灾难”干扰。
属性分组离群数据检测作为一类高维离群检测方法,将依据属性之间的关联关系,将属性划分为若干子集,并利用各属性子集,识别或度量离群数据对象,从而可挖掘出全局和局部离群数据[10-12]。但现有的属性分组离群检测未能体现属性组之间的差异性与属性组的偏离程度,影响了高维离群检测效果。该文利用信息熵累加和刻画属性组权重,提出了一种基于属性组权重的分类离群数据检测方法,有效地体现了属性组之间的差异性,进一步改善了高维离群检测效果,并缓解了“维度灾难”干扰。其主要贡献:
·依据数据模式频率和编码长度,定义了属性组偏离因子及计算公式;
·提出了一种基于信息熵的属性组权重计算方法;
·提出了一种基于属性组权重的分类离群数据检测算法。
1 相关工作
分类数据作为一类广泛出现在多种应用领域中的重要数据类型,具有取值无序与不可比等特点。目前,分类数据离群检测主要包括:基于距离的方法[13-15]、基于密度的方法[16-17]、基于统计的方法[18-19]、基于聚类的方法[20-22]、基于频繁项集的方法[10-11,23]、基于子空间的方法[24-26]等。针对高维分类数据,由于“维度灾难”,严重影响了分类数据离群检测性能;而子空间方法是将数据对象从高维空间投影到低维空间,可有效缓解“维度灾难”干扰,是高维分类离群检测的有效途径之一。
基于子空间的离群检测是将数据对象从高维空间投影到低维子空间,并在低维子空间中,度量与检测离群数据对象,主要包括相关子空间和稀疏子空间两类子空间方法。其典型研究成果:文献[27]采用遗传算法搜索稀疏子空间,但该算法受初始种群影响,离群挖掘结果的完备性和准确性等无法得到保证;文献[28]采用概念格作为子空间的描述工具,通过引入稠密度系数,在概念格内涵中确定稀疏子空间;文献[29]在概念格的基础上提出了约束概念格的方法,提高了概念格的构造效率,进一步提高了挖掘的效率;文献[30]提出了一种基于稀疏子空间并行搜索技术的类星体光谱异常数据并行检测算法,实现了对天体光谱中异常光谱的挖掘。稀疏子空间的方法的稀疏系数阈值需要人为设置,无法保证稀疏子空间划分的准确性;文献[31]利用局部稀疏差异因子得到相关子空间,解决了检测相关子空间时间复杂度较高的问题,但是维度的数据分布会使得到的相关子空间产生一定的误差;文献[24]提出一种轴平行子空间离群挖掘方法,该方法通过共享最近邻居,为数据对象寻找似子集以确定子空间,但该方法采用的欧氏距离的维平均方法度量离群具有明显不足;文献[32]提出一种在相关子空间进行离群检测的算法,算法使用KNN方法确定数据对象的局部数据集,然后生成稀疏因子矩阵和局部稀疏因子矩阵,再确定数据对象对应的子空间定义向量,计算数据对象的离群程度,但该方法的局部稀疏差异因子阈值的选取会影响子空间定义向量的确定和挖掘的精度。相关子空间的方法不能有效地在高维数据集中挖掘离群数据,因此离群挖掘的效率和准确性无法保证。
作为一种子空间离群检测,属性分组是将高维属性划分为若干不同属性组,将相关性强的属性划分在同一个组中,相关性弱的属性划分在不同组中。其典型工作有:文献[10]提出了一种利用特征分组的加权离群检测的方法,该算法利用特征关系的概念对特征(即属性)进行分组,可以实现对分类数据中的全局和局部离群数据的挖掘,但是该算法组间离群数据的合并缺乏合理的解释性;文献[11]提出了一种基于压缩数据的离群检测算法,该算法根据最小描述长度定律最小化压缩长度实现属性的分组,但是由于建立代码表的开销过大,所以该算法的时间复杂度较高;文献[12]采用基于二叉搜索树的隔离算法实现属性分组,在属性组内实现数据对象的聚类过程,以实现对离群数据的挖掘。属性分组的方法对于分组组数的选取和分组时属性分配存在一定的难度,同时,对于全局离群数据的挖掘的组间合并缺乏合理的解释性。
综上所述,子空间离群检测可以有效地发现隐藏在子空间中的局部离群数据,但会丢失部分有用信息,影响了离群检测性能;属性分组离群检测将高维属性分为不同的属性组,有效地利用了全部离群信息,但现在的属性分组存在着组数选取敏感,离群检测未能有效体现属性组间的差异性等,从而影响离群检测效果。
2 属性分组与离群检测
在高维离群检测中,属性分组是缓解“维度灾难”的有效途径之一。所谓属性分组是依据属性之间的关联程度,将相关性强的属性划分在同一个组中,相关性弱的属性划分在不同组中。参照文献[10-11],相关概念描述如下:

信息增益描述了随机变量的概率分布的差异性,属性分组通过标准化信息增益(Normal Information Gain,NIG)来描述属性组间概率分布的差异性,可以有效地刻画属性组之间的相关性。对于任意2个属性组(Fu和Fv),其标准化信息增益的计算公式如下:
(1)
其中,H(Fu),H(Fv)分别为第u属性组的信息熵、第v属性组的信息熵,H(Fu,Fv)为Fu和Fv之间的互信息,|Fu|和|Fv|分别表示第u属性组和第v属性组的属性个数。
在公式(1)中,NIG(Fu,Fv)刻画了Fu和Fv之间的相关程度,其值越大,表明两组的相关性越强,合并为同一组的概率就越大,反之亦然。
数据模式是指数据对象(xi)在属性组(Fj)中,属性的一个取值项集。在Fj中,xi由若干个互不相同的数据模式组成。代码表是为描述属性组中的数据模式和数据模式编码构建的一种模型结构。数据模式编码体现了数据模式在代码表中数据模式频率分布的差异性。在Fj中,设p为xi的任一数据模式,CT为描述数据模式和数据模式编码的代码表,则p的数据模式编码定义如下:
(2)

在公式(2)中,L(code(p)|CT)刻画了数据模式在CT下的频率分布,其值越大,表明该数据模式在代码表中出现的频率越大,反之亦然。
数据编码是数据集(D)中所有数据对象(xi)在CT中所有数据模式编码的总和,数据编码有效地刻画了D在Fj中的压缩效果,是评估CT模型质量的依据。设CT为代码表,A为xi在Fj中所有数据模式的集合,则利用公式(2),D的数据编码描述如下:
(3)
在公式(3)中,L(D|CT)刻画了数据集(D)在CT模型中的压缩效果,其值越大,表明压缩效果越差,无法适用于D,反之亦然。
为了有效地度量构建代码表模型(CT)的代价,利用公式(2),CT的代价定义如下:
(4)

在公式(4)中,L(CT)反映了构建代码表的代价,其值越大,表明构建该代码表所需的编码长度越长,代价成本就越高,反之亦然。
为了刻画属性分组(P)的压缩效果与体现属性分组的分组效果,利用P中的各个属性组对应的数据编码和代码表代价总和作为其度量依据。利用公式(3)和(4),在D中,CT和P的压缩消耗函数定义如下:
(5)
其中,L(P)表示描述分组情况所需要的编码长度。
在公式(5)中,L(P,CT,D)有效地刻画了属性分组的质量,其值越大,表明总的压缩效果越差,表明属性分组的效果越差,反之亦然。
依据上述定义,属性分组的基本步骤如下:
(1)将每个属性视为单独的一组,根据公式(2),计算数据模式编码,构建对应的代码表;
(2)根据公式(1)计算两两属性组的NIG,按照NIG降序的方式对属性组排序;
(3)根据公式(3)~(5)计算压缩消耗函数,根据压缩消耗函数的大小实现组间合并,更新属性组及代码表,若属性组全部遍历后,压缩消耗函数值仍未减小,分组结束,否则返回步骤2,继续组间合并。
在上述属性分组的基础上,为了度量数据对象在其数据集中的离群程度,利用公式(2)、公式(3),xi的离群得分计算公式定义如下:

(6)
在公式(6)中,score(xi)刻画了xi的离群程度,其值越大,表明数据对象的偏离程度越大,成为离群数据的概率越大,反之亦然。
3 属性组权重与分类离群检测
在上一章节的属性分组步骤中,NIG作为一种搜索策略,是属性组之间合并顺序依据。由公式(1)可知,计算NIG的值与初始属性分组(P)中的属性组个数(d)有关,即:需要计算d个属性组中的任意两组间NIG;依据公式(5)定义的压缩消耗函数,属性组迭代合并更新后,还需要重新计算属性组之间的NIG。因此,属性分组中的搜索策略效率低下。
在属性分组中,数据模式出现的频率体现了属性取值项集疏密程度,数据模式编码长度体现了数据模式频率分布。数据模式编码长度体现了属性组的不确定性,可以有效地衡量属性组的偏离程度。对于任意属性组(Fj),设CT为Fj对应的代码表,Fj的偏离因子定义如下:
GDF(CT)=log(1/p(r))-log(1/p(t))
(7)
其中,r,t分别为CT中的频次最小、频次最大数据模式,p(r),p(t)分别表示r,t数据模式在CT中出现的频率。
在公式(7)中,log(1/p(r))和log(1/p(t))分别刻画了r,t所含的信息量,数据模式出现的频次越小,包含的离群信息量越大,反之亦然。r是属性组(Fj)中含离群信息量最大的数据模式,而t是属性组(Fj)中含离群信息量最小的数据模式,因此,GDF(CT)刻画了Fj的偏离程度。在属性分组中,采用偏离因子(GDF)作为属性组之间合并顺序依据,只需要利用代码表中已有的数据模式编码,计算d个属性组的GDF。相较NIG而言,避免了NIG中任意两组间的互信息计算,因此有效地提高了搜索策略的效率。
在公式(6)中,离群得分计算仅体现了属性组(Fj)的数据模式编码长度,忽略了属性组之间所包含的离群信息量差异,影响离群检测效果。信息熵是根据系统内的分布差异,衡量系统所含信息量,信息熵越大表明该系统的不确定性或混乱程度越大[33]。因此,利用信息熵度量属性组,可以体现属性组内包含的离群信息量,信息熵越大表明所包含的离群信息越多,即:离群检测的重要程度也就越大,从而体现了属性组之间的差异性。设Fj={fk|1≤k≤h}为任意属性组,则Fj的权重定义如下:
(8)
其中,fk为Fj中的第k个属性,h为Fj中的属性个数,H(fk)表示第j属性组第k属性的信息熵。
在公式(8)中,属性组权重有效地度量了属性组的混乱程度,体现了属性组所包含的离群信息量,其值越大,所包含的离群信息量越大,反之亦然。属性组权重刻画了不同属性组对度量离群数据对象的重要程度,充分体现出属性组间的差异性。
由公式(7)和(8)可知,属性组偏离因子(GDF)利用数据模式编码频率分布,有效地刻画了属性组对度量离群数据的重要程度,改善了搜索策略的效率;属性组权重利用信息熵度量了属性组包含的离群信息重要程度,有效地刻画了属性组之间的差异。为了有效地度量数据对象(xi)在其数据集(D)中的离群程度,参照公式(6)、公式(8),xi的离群得分重新定义如下:
(9)
在公式(9)中,离群得分值刻画了xi的离群程度,其值越大,表明数据对象的偏离程度越大,成为离群数据的概率越大,反之亦然。由于该离群得分体现了属性组权重和数据模式编码长度,因而有效地刻画了属性组内和属性组间数据对象所包含的离群信息。
4 基于属性组权重的分类离群检测算法
依据上一章节描述,采用属性组权重,分类离群检测基本步骤描述如下:
(1)将每个属性视为单独的一组,根据公式(2),计算数据模式编码,构建对应代码表;
(2)根据公式(7)计算属性组偏离因子(GDF),按照GDF降序的方式对属性组排序;
(3)根据公式(3)~(5)计算压缩消耗函数,根据压缩消耗函数的大小实现组间合并,更新属性组及代码表,若属性组全部遍历后,压缩消耗函数值仍未减小,分组结束,否则返回步骤2,继续组间合并;
(4)根据公式(8)计算属性组权重,根据公式(9)计算数据对象的离群得分,从中选取离群得分最高的k个对象作为离群数据。
算法伪代码如下:
算法:AGWODC(Attribute Group Weight Outlier Detection for Categorical data)
输入:数据集(D)(n个数据对象×d个属性)
输出:k个离群数据对象
1.初始化分组:P={Fj|1≤j≤d},Fj={fj}, 1≤j≤d
2.根据公式(2)构建代码表:CT={CTj|1≤j≤d}
3.根据公式(7)计算每个组的偏离因子(GDF),构成集合(OD)
4.ForFuinP:
5. forFvinP:
6.降序排序OD
7.根据公式(5),计算最小消耗函数L(P,CT,OD)
cost=L(P,CT,OD)
8.根据公式(2)计算数据模式的编码长度,构建新的代码表(CTu|v)
9.P=P(Fu∪Fv)∪Fu|v
10.CT'=CT(CTu∪CTv)∪CTu|v
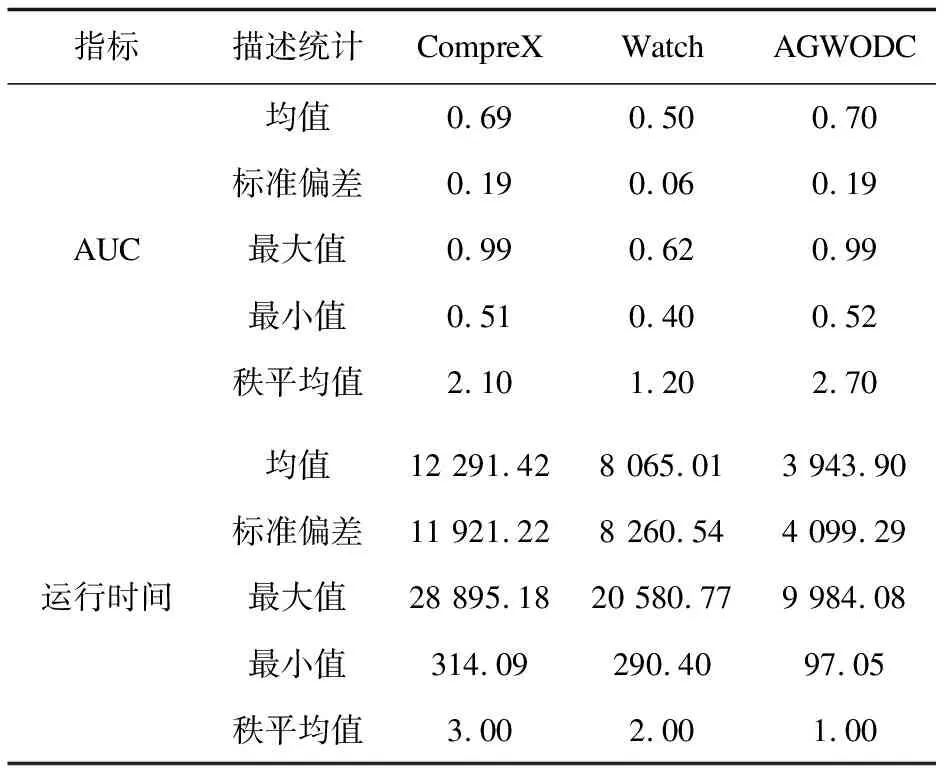
11. ifL(P',CT',OD) 12.P=P',CT=CT' 13. 根据公式(7)计算CT'的CDF,更新OD 14.返回步骤(4) 15. endif; 16. endfor; 17.Endfor; 18.For eachjinP: 19.根据公式(8)计算组权重ω(Fj) 20.For eachi∈(1,2,…,n) inD: 21.根据公式(9)计算数据对象的离群分数 22.Endfor; 23.选择离群分数最高的k个离群数据对象 24.End AGWODC 时间复杂性分析: 在上述AGWODC算法中,主要包括属性分组、属性组权重与离群得分两个阶段。在属性分组中,主要包括了组间合并时寻找新的数据模式,合并过程中插入新的数据模式时,更新其他数据模式的频次等。组间合并时寻找新的数据模式所需时间复杂度约为O(n),更新其他数据模式的频次所需时间复杂度约为O(n),在最坏情况下,组间合并时间复杂度为O(d2)。因此,属性分组的时间复杂度为O(d2n),其中n为数据对象的个数,d为属性的个数。在属性组权重与离群得分中,主要包括了属性组权重的计算和计算数据对象离群得分,属性组权重的计算时间复杂度约为O(d),计算数据对象离群得分的时间复杂度约为O(n),因此该过程的时间复杂度约为O(n)。总之,AGWODC算法的时间复杂度约为O(d2n+n)。 实验配置:Intel Core I5 6300HQ CPU,8G内存,并采用python语言在pycharm平台上,实现了AGWODC算法及实验对比算法Watch[10]和CompreX[11]。实验数据集包括UCI,Kaggle,UIUC公开数据集。另外,为了验证算法的可扩展性和伸缩性,采用GAClust toolkit软件[34]生成人工数据集,将随机数发生器种子的值设置为5,类别数设置为2,根据实验需要设置相应的数据量、属性个数,分别从两类中选取符合实验需求的正常数据与离群数据,构成人工数据集:其中,data1-data4为数据量相同,维数不同的人工数据集,用于验证算法的可扩展性;data5-data8为维数相同,数据量不同的人工数据集,用于验证算法的伸缩性。其数据集详情如表1所示。 表1 实验数据集 为了实验验证AGWODC算法的离群检测精度,采用了表1所示的UCI,Kaggle,UIUC等10个数据集,以及2个对比算法:Watch和CompreX,其AUC[35]指标的实验结果如表2所示。 由表2可知,AGWODC的AUC指标值优于其对比算法,仅在Cowsgame数据集上略低于CompreX算法,在diabetes数据集上略低于Watch算法;尽管AGWODC的ROC曲线基本高于其他对比算法,但在Cowsgame数据集上略低于CompreX算法,diabetes数据集上略低于Watch算法。因此,表明了AGWODC具有较高的离群检测精度。其主要原因:AGWODC利用了基于信息熵度量的属性组权重,并在离群得分中充分体现出了属性组间的差异。此外,由于Cowsgame是一种猜数字游戏的数据集,其属性由玩家若干次猜测数字构成,每次玩家猜测的数字形成一个属性组,从而形成有特定含义的属性分组,且与数据集分布无关,属性组权重会偏离了特定含义的属性分组;由于diabetes数据集的维数较低、属性的取值较少,信息熵无法体现出属性组之间的差异。 为了实验验证AGWODC算法的离群检测效率,采用了表1所示的UCI,Kaggle,UIUC等10个数据集,以及2个对比算法:Watch和CompreX,其实验结果如表3所示。 由表3可知,AGWODC算法的耗时明显低于其他对比算法,因而表明AGWODC具有较高的检测效率。其主要原因:由于Watch算法采用特征关系(FR)等,实现其属性分组及离群得分,需要频繁计算属性之间的互信息;CompreX算法在属性组之间合并过程中采用标准化信息增益(NIG)的搜索策略作为属性组间合并依据;AGWODC采用基于偏离因子(GDF)的搜索策略,避免了NIG中任意两组间的互信息计算。 弗里德曼检验是一种无参数检验方法,用于检测3组或者3组以上数据是否存在显著差异性。为了评价AGWODC与其他相关算法在AUC值和检测效率的优越性,采用统计检验中弗里德曼检验对3种算法在10个数据集上的AUC值和运行时间进行检验,比较3种算法是否存在差异性。根据表2和表3中的实验数据,弗里德曼检验统计结果如表4所示。 表4 AUC与运行时间的弗里德曼检验 由表4可知,在显著性水平α=0.05时,卡方值为12.000,渐近显著性为0.002,表明AUC值的秩平均值具有显著统计学差异,秩平均值越大,AUC值越大;在显著性水平α=0.05时,卡方值为20.000,渐近显著性为0.000 045,表明运行时间的秩平均值具有显著统计学差异,秩平均值越小,运行时间越短。由表4可知,AGWODC的AUC值算法秩平均值最大,运行时间秩平均值最小,因此,从统计检验的角度而言,AGWODC算法优于其他算法。 可扩展性与伸缩性是衡量离群检测算法的重要指标,可扩展性是当数据对象个数相同,维数变化对离群检测算法效率的影响;伸缩性是当维数相同,数据对象个数变化对算法效率的影响。为了验证AGWODC算法的可扩展性,采用了表1所示的4个人工数据集(data1~data4),以及2个对比算法:Watch和CompreX,其实验结果如图1所示。 图1 可扩展性 由图1可知,随着数据集的维数增加,3个算法的耗时呈现了非线性增长,且AGWODC明显优于其他2个对比算法,表明AGWODC具有良好的可扩展性。其主要原因:随着维数的增加,在属性分组过程中,属性组偏离因子(GDF)的计算随之增多,属性组代码表建立和属性组间合并随之增多,但避免了CompreX中NIG搜索策略与Watch中FR中属性之间的互信息计算,有效降低了算法的运行时间。 为了验证AGWODC算法的伸缩性,采用了表1所示的4个人工数据集(data5~data8),以及2个对比算法:Watch和CompreX,其实验结果如图2所示。 图2 伸缩性 由图2可知,随着数据集的数据对象增加,3个算法的耗时呈现了非线性增长,且AGWODC明显优于其他2个对比算法,表明AGWODC具有良好的伸缩性。其主要原因:随着数据对象的增加,属性组间合并时寻找新的数据模式、更新数据模式频次和数据对象离群得分的计算量也随之增加,但避免了CompreX中NIG搜索策略与Watch中特征关系(FR)中属性之间的互信息计算,大大缩短了算法的运行时间。 该文采用信息熵累加和刻画属性组权重,提出了一种基于属性组权重的分类离群数据检测方法,充分体现和刻画了属性组之间的差异性以及属性组的偏离程度,有效地改善了高维离群检测性能,并缓解了“维度灾难”干扰,可适用于海量高维分类数据离群检测任务。下一步研究工作是基于属性组权重的分类离群数据检测并行化,以及混合数据的高维离群检测等。5 实验结果

5.1 检测准确性
5.2 检测效率
5.3 弗里德曼检验
5.4 可扩展性与伸缩性


6 结束语
