基于半监督学习的运动员姿态提取技术
2023-11-21陈丽萍
王 凯,陈丽萍
(1.厦门医学院,福建 厦门 361000;2.包头医学院 卫生健康学院,内蒙古 包头 014030)
全监督学习的快速发展为深度学习的可靠性奠定了基础,然而全监督学习方法面临着数据需求量过大的挑战。具体来说,对于密集预测任务,如目标检测和语义分割需要大量的标记数据,同样,人体姿势估计任务也需要很昂贵的标注成本。给定大量的标注训练数据对于训练姿势估计以及各种识别深度学习模型(例如,对象识别[1]和人脸识别[2])极其关键。尽管用于人体姿势估计的数据集的规模一直在增加(如图像解析数据集中有305 张图像[3],LSP 数据集中有2 000 张图像[4],MPII 人体姿势数据集中有25 000 张图像[5]),但是与目标识别任务相比,人体姿势估计的大型数据集仍然远远不足(如ISVRC[6]中超过1 430 000 张图像)。这是因为人体姿势标注比目标识别以及语义分割任务的窗口标注和区域标注复杂得多[7]。为了解决标注数据不足的问题,在结合半监督学习(SSL)的姿态估计方法中,通过使用未标记数据得到了较好的姿态估计效果。
最初的半监督学习工作主要集中在分类任务上[8]。一般来说,通过伪标签的方法来探索未标记的图像,首先使用有监督学习方式仅在已标注的图像上学习初始模型。然后,对于未标记的数据,应用初始模型来获得表示其类别的硬或软伪标签。最后,在混合标记数据和伪标记数据的组合数据集上学习最终模型。其中尤为经典的是自学习半监督模型[9]。
半监督学习方法虽然在部分研究任务中取得了较好的效果,但是仍然存在问题,伪标签的选择对后续模型的持续性训练影响很大,选择置信度低的伪标签将降低模型的效果。基于这一问题,该文提出了一种将真实标签与伪标签进行混合自学习的方法,称之为基于半监督学习的运动员姿态提取技术(Athlete Pose extraction technology based on Semi-Supervised Learning,AP-SSL),并进行了一系列实验验证,实验结果表明,该方法能够达到最佳的半监督姿态估计效果。
1 方法与处理
1.1 自监督姿态估计网络模型
该文提出的自监督姿态估计网络使用了两个不同的训练集。自监督姿态估计网络模型如图1(a)所示,首先基于真实标签数据集进行姿态估计训练网络模型的初始化训练,其姿态估计网络结构如图1(b)所示。模型构建过程中为了增强模型对有效区域特征的获取能力,在编解码主干姿态估计网络结构中使用了该文提出的硬注意力机制(Hard Attention Mechanism,HAM),其整体结构如图2所示。

图1 自监督姿态估计网络结构图
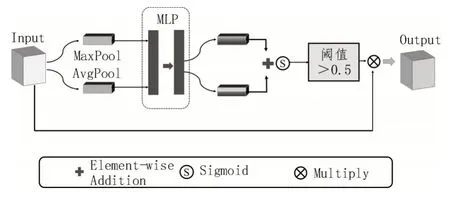
图2 硬注意力机制流程图
硬注意力机制的构建可以对有效特征进行筛选,从而能够准确获取有效特征的激活权重。
该文提出的硬注意机制的实现策略如下:
式中,Ws表示输出权重大小。其具体实现流程如下:对于输入数据,首先基于全局最大池化MaxPool和全局平均池化AvgPool 进行全局通道归一化,再通过双隐层的MLP 将数据缩放为描述符,并通过Sigmoid 进行激活,最后设定阈值为0.5 对特征权重进行深度筛选。获取的权重与原输入数据相乘后即可获取硬注意力特征数据。
在编解码网络结构中,添加硬注意力机制能够促使网络不断关注有效特征,进而提升整体模型的姿态提取效果。对添加了硬注意力机制的姿态估计训练网络结构在训练过程中的部分特征进行了可视化展示,如图3 所示。图3 中自左向右是随着网络层次的加深,硬注意力机制的输出特征图。亮度值高的区域代表网络的关注区域。

图3 硬注意力机热力图
从图3 可以看出,随着网络层次的加深,硬注意力机制能够促进网络逐渐关注人体姿态的关键节点部位。
1.2 自适应损失拟合策略
损失函数的构建能够提升网络结构的性能,使得网络模型在训练过程中快速收敛。文中构建了联合损失函数,并且在训练过程中创新性的提出了自适应损失拟合策略(Adaptive Loss Fitting strategy,ALF)来充分挖掘伪标签数据的信息。基于真实标签的损失函数Lloss如下:
式中,Ll1[10]和Ll2[11]损失函数定义如下:
式中,Yi为真实目标值,f(Xi)为估计值。当伪标签数据与真实标签数据进行混合时,由于伪标签的存在,无法有效评估损失函数的与实际损失的差距。为了解决这个问题,首先构建了联合损失函数Ltotal,其定义如下:
式中,Lloss为真实标签的损失函数,Uloss为伪标签损失函数,λ为伪标签权重。自适应损失拟合策略的实现方式如下:在训练过程中,Uloss是非可靠因子,因此,将Lloss设置为标准损失,当Lloss不断降低时,认为当前的训练迭代是向着正确的方向拟合,此时λ设置为1;当Lloss增加时,将λ设置为0。
2 实验验证
实验验证部分在装有NVIDIA 2080TI 显卡的服务器上进行,其学习率设置为0.000 1。为了快速收敛,该文还使用Adam 优化器[12]来训练模型,损失函数的设置将很大程度上影响模型的性能,该文选择提出的Ltotal作为损失函数,训练迭代次数为100,并且选择姿态估计精度AP(Average Precision)为评价指标对所提方法进行评估。
实验过程中使用公共可用的LSP 扩展数据集并对所提方法进行了训练。LSP 数据集中的图像使用了八个动作标签(即与每个图像相关的文本标签),包含田径、羽毛球、棒球、体操、跑酷、足球、网球和排球等八个不同的运动姿态。LSP 的训练集共计1 200张图像,其中,500 张作为真实标签数据进行有监督训练获取初始化姿态估计网络模型,另500 张无标签图像获取伪标签后,与真实标签数据进行混合训练,选剩余200 张图像作为测试集。
选择不同的网络结构包括ResNet50[13]、ResNet 101[14]、ResNet152[15]和HRNetW48[16]作为主干网络,基于LSP 数据集对比全监督姿态估计方法与该文提出的半监督姿态估计方法,实验结果如表1 所示。此外,对部分实验结果进行了可视化,如图4 所示。其中,图4(a)代表单独使用真实标签的全监督运动员姿态估计方法的实验结果,图4(b)代表基于半监督学习的运动员姿态估计方法的实验结果。

表1 姿态估计结果数据对比

图4 实验结果可视化展示图
对表1 以及图4 中的数据进行分析可以得出,基于伪标签与真实标签相结合的半监督学习方式,能够有效使用伪标签数据,与单独使用真实标签数据的全监督学习方式相比较,在不同主干网络结构下,姿态提取精度最高提升了3.2%,充分验证了该文提出的基于半监督学习的运动员姿态提取方法的有效性。
为了进一步验证该文提出的硬注意力机制的有效性,以ResNet50 为主干网络结构,在跳跃连接层分别添加硬注意力机制和不添加硬注意力机制,作为一组对比实验,并基于LSP 数据集进行了半监督姿态估计效果验证。其实验结果如表2 所示。

表2 硬注意力机制的有效性验证结果
表2 实验结果表明,硬注意力机制的添加能够增加1.4%的姿态估计精度,充分验证了硬注意力机制的有效性。
文中还分别对比了单独的L1、L2损失函数和该文提出的联合损失函数对网络模型的影响,将不同损失函数应用于该文提出的半监督学习的运动员姿态提取网络中,随着网络训练次数增加,相应的姿态估计精度和损失函数如图5 所示。对图5 中的折线图进行对比分析可以看出,该文提出的联合损失函数能够加快模型收敛,进一步验证了联合损失函数的有效性。
3 结束语
该文提出了一种基于半监督学习的运动员姿态提取方法,该方法通过混合学习的方式有效利用了未标注数据。与传统半监督学习方式相比较,该方法构建了自适应损失拟合策略,能够更加合理地对伪标签数据的训练损失权重进行调整。并且还提出了硬注意力机制,以更加有效地提取上下文语义信息。最后,基于公开的LSP 数据集,对该方法进行了一系列实验验证。
基于半监督学习的运动员姿态提取方法虽然取得了较好的运动员姿态估计效果,但是其模型计算量较大,接下来的研究工作将致力于构建轻量级的半监督学习模型,以更好地应用于实际任务中。
