基于GA-BP神经网络的尾煤水灰分视觉检测方法研究
2023-11-18岳耀辉王昱晨曹英华鹿新建秦录芳
岳耀辉 ,孙 涛 ,王昱晨 ,曹英华 ,鹿新建 ,秦录芳
1.盐城工学院 机械工程学院,江苏 盐城 224051;2.徐州工程学院 机电工程学院,江苏 徐州 221018;3.江苏仕能工业技术有限公司,江苏 徐州 221000
浮选工艺是提升精煤产率,增加经济效益的有效手段。浮选过程中,煤泥灰分是反应浮选系统效果优劣的重要指标。目前,煤泥灰分检测手段主要包括人工快灰试验、光电式测灰法、射线检测法和机器视觉方法[1]。
由于机器视觉具有稳定、即时、高效等优点,可在工业检测和控制过程中普遍使用,因此采用机器视觉辅助检测尾煤水灰分已成为相关研究的热门方向。文献[2-4]以煤浆图像的灰度特征作为输入值建立了煤浆灰分的软测量模型,忽略了煤浆图像的彩色特征。包玉奇等[5-6]将灰度区间离散变量、光源光强和反射光作为输入变量构建BP 神经网络预测模型,但模型存在较大误差。阳春华等[7]将泡沫颜色、泡沫速度作为输入值,利用最小二乘支持向量机建立了浮选产率的预测模型。综上所述,煤泥浮选回归模型大多采用灰度图像,特征值少且预测模型缺少优化,使得模型精度难以进一步提高。
鉴于此,本文对尾煤图像的灰度特征和彩色特征等多特征值进行提取,基于GA-BP 神经网络算法对提取的特征值进行回归预测,以提高尾煤水灰分预测模型的精度。
1 图像的预处理与特征提取
1.1 图像预处理
由于拍摄过程中尾煤水图像会受到光源反射和气泡喷溅的污染,因此,为了使图像的灰度特征和颜色特征能够被更加准确地提取出来,需要对其进行分割处理[8]。原图像预处理后的图像为
式中:x、y分别表示像素点的横坐标与纵坐标;med{...}表示对括号内的像素值集合进行中值操作;h(x-5,y-5)表示坐标点(x,y)在水平方向和垂直方向上分别向左和向上平移了5 个单位;intercept(300,300)为截取的300×300图像。分割处理后的图像如图1所示。

图1 分割后的尾煤水图像Fig. 1 Image of tail coal water after segmentation
1.2 特征提取
对原始图像进行去噪和阈值分割操作确定目标区域后,需要对所得的目标区域进行特征提取[9]。本文主要提取图像的灰度统计特征和颜色特征。
彩色图像的灰度值计算公式为
式中:f为灰度值;R为红色分量值;G为绿色分量值;B为蓝色分量值。
灰度均值的计算公式为
式中:He为灰度均值;f(i,j)为图像第i行j列的灰度值。
浮选过程中尾煤水不仅含有灰度特征,还含有彩色特征。这种彩色特征含有丰富的信息,可以较好的模拟灰分的变化[10]。
当前的颜色空间包括RGB 空间特征、YUV 空间特征和HSI 空间特征[11]。RGB 颜色空间的R、G、B分量可以直接提取。YUV 颜色空间是一种用于视频信号传输的编码方案。根据亮度原理,每个像素分为3 个特征:明亮度Y、色度U和浓度V。YUV的转换公式为
式中:Y为明亮度值;U为色度值;V为浓度值。
HSI 颜色空间的色调H、饱和度S、亮度I分量可以根据RGB 或YUV 的特征值转换而来。像素特征变换公式为
式中:H为色调值;S为饱和度值;I为亮度值;θ为RGB颜色空间转换成的角度值。
提取特征后的部分输入输出样本数据如表1所示。
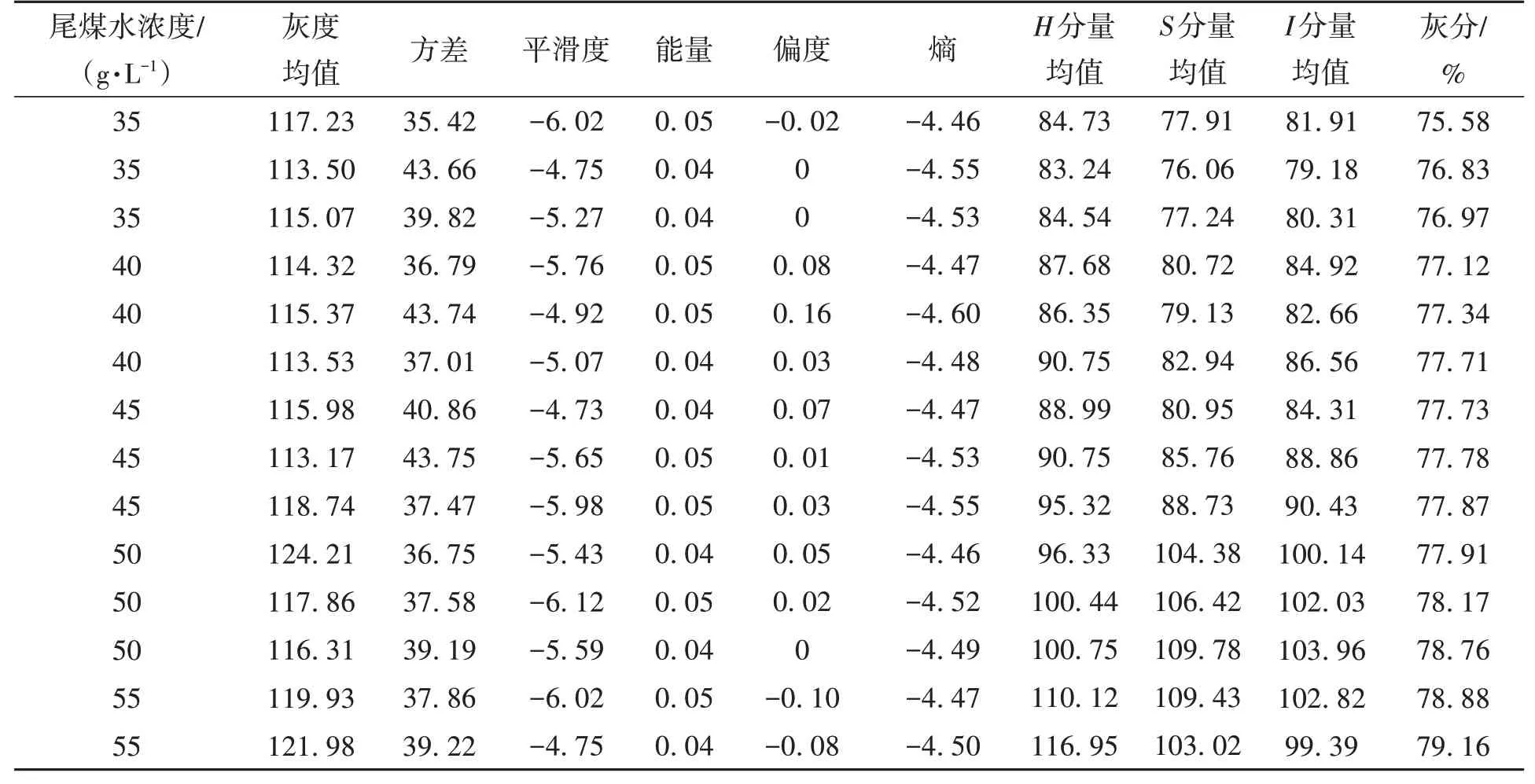
表1 部分输入输出样本数据Table 1 Partial input and output sample data
2 建立基于遗传算法的BP 神经网络灰分预测模型
2.1 BP神经网络算法
BP(back propagation)神经网络是一种广泛使用的人工神经网络,由输入层、隐藏层和输出层组成[12]。BP 神经网络的训练过程通常采用反向传播算法,通过调整神经元之间的权值,使预测值更接近真实值,从而逐步提高预测精度。
输入层、隐藏层、输出层的神经元数量分别为m、n、l。输入层输入记为(x1,x2,...,xm);隐藏层输出记为(h1,h2,...,hn);输出层记为(y1,y2,...,yl)。
(1)隐藏层的输出计算公式
式中:hj表示隐藏层神经元j的输出值;wij表示连接神经元i到神经元j的权重;θj表示神经元j的偏置。
(2)输出层计算公式
式中:yk表示输出层神经元k的输出值;wjk表示连接神经元j到神经元k的权重;θk表示神经元k的偏置。
(3)反向误差计算公式
隐藏层和输出层之间的误差为
式中:δk表示隐藏层神经元k与输出层的神经元k误差;dk表示隐藏层神经元k的输出值。
输入层与隐藏层的误差为
式中:δj表示隐藏层神经元j的误差;f′表示激活函数的导数。
2.2 遗传算法
BP 神经网络在训练过程中,需要调整大量的权值参数来拟合数据[13]。因此,可采用遗传算法(genetic algorithm,GA)帮助BP 神经网络进行全局寻优。遗传算法是一类受自然进化过程启发的进化算法,可用于复杂的优化问题[14]。遗传算法模拟自然选择和进化的过程,使得有价值的特征被保留和改进,从而进化出更好的解决方案。
使用遗传算法优化BP 神经网络的基本过程如下:
(1)初始化种群:生成一组初始解,每一个解都是一组权重参数。
(2)对种群进行评价:利用BP 神经网络对每个解进行评价,得到每个解的适应度。
(3)选择最适合的个体:根据他们的适应度值选择最适合的解决方案的子集。
(4)再现所选个体:使用交叉和变异等遗传算子从所选个体生成一组新的解决方案。
重复步骤(2)~(4),直到找到满意的解决方案或达到一定的迭代次数。
使用遗传算法优化BP 神经网络可以在全局范围内搜索最优解,而不是像传统优化算法那样陷入局部最优[15]。此外,遗传算法能够处理大型复杂数据集,且易于并行化,可用于高维优化问题。
2.3 GA-BP神经网络尾煤水灰分预测模型
在BP神经网络中,至关重要的两个参数为连接权值和阈值,极其容易使模型陷入局部最小化,导致模型的预测精度不高[16]。因此本文基于遗传算法对BP 神经网络加以改进,使BP 神经网络模型获得最理想的权重和阈值,更加有效地实现网络训练与预测[17]。遗传算法优化BP 神经网络流程如图2所示。
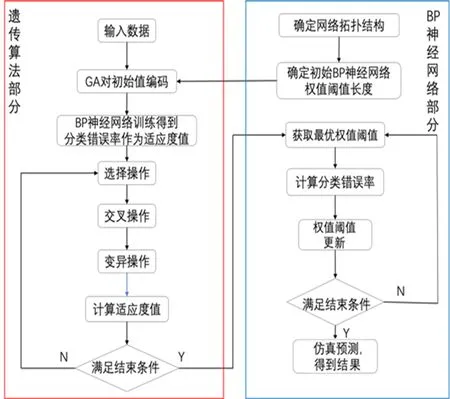
图2 遗传算法优化BP神经网络流程Fig. 2 Optimization of BP neural network process by genetic algorithm
3 试验及结果分析
3.1 研究路线
首先对尾煤水图像原图进行分割,去除尾煤水图像中特有的光斑等噪声干扰;然后对输出图像进行特征提取,提取灰度特征和颜色特征的统计量;最后,将得到的统计特征作为输入训练BP神经网络,通过遗传算法优化得到训练好的神经网络模型。该模型用于预测尾煤水图像的灰分含量。
3.2 试验条件
选择0~0.25 mm 的浮选尾煤干粉、浮选精煤干粉和矸石作为试验样本,灰分分别为23.87%、41.35%和69.18%。
本文研究对象为是浮选尾煤水,除灰度特征外还有其他颜色特征,排放过程中存在泡沫飞溅、光线暗淡等情况,导致相机识别检测的尾煤水图片受到污染,从而降低取相质量。为解决上述问题,本文的图像采集装置包括:MV-EM510C彩色CCD 工业相机、LED 灯、泡沫过滤器、液位传感器和样本容器等,具体如图3所示。

图3 图像采集装置Fig.3 Image acquisition device
3.3 试验结果分析
测试过程在MATLAB R2021a 平台上进行。测试过程中,输入特征主要选取不同维数特征与本方案的浓度、灰度特征和彩色特征进行对比测试;预测模型主要选取支持向量回归、ELM 极限学习机与遗传算法优化的BP 神经网络进行对比测试。
BP 神经网络和GA-BP 神经网络在不同特征维数下的预测精度如表2、表3 所示。表中7 维特征包括煤浆浓度、灰度特征(灰度均值、熵、方差、平滑度、能量、偏度)的7个统计量,10维特征是在7 维特征的基础上增加了彩色特征(H分量、S分量、I分量),共计10 个统计量。由表2~3 可以看出,BP 神经网络、GA-BP 神经网络均在具有10 维特征和4 个神经元时预测精度最高,然后由于过拟合问题使其预测精度随着神经元数量的增加而下降;灰度特征加彩色特征的预测组合精度高于只采用灰度特征,即神经元数为4 时10 维特征的预测精度高于7 维特征的预测精度,说明加入反映局部色差的特征可以提高BP 神经网络的预测性能。

表2 不同特征维数下BP神经网络预测精度Table 2 Prediction accuracy of BP neural network under different feature dimensions
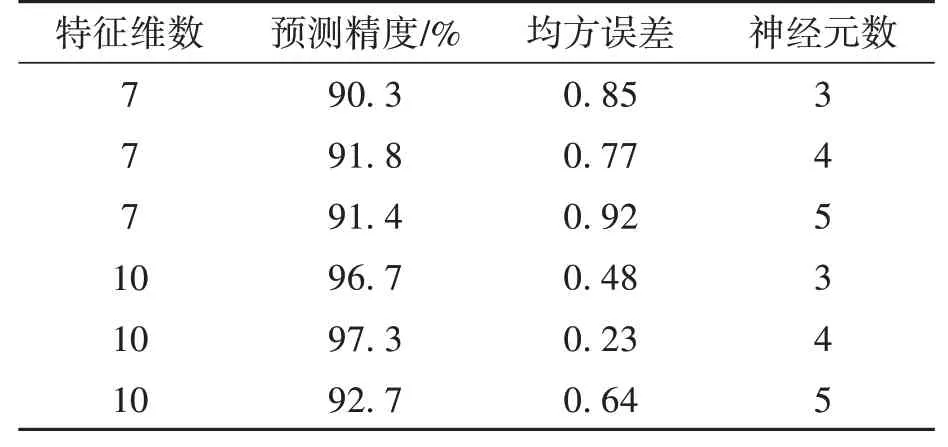
表3 不同特征维数下GA-BP神经网络预测精度Table 3 Prediction accuracy of GA-BP neural network under different feature dimensions
ELM 极限学习机算法、支持向量回归的预测精度如表4~5 所示。表中的7 维特征为煤浆浓度、灰度均值、方差、平滑度、偏度、能量、熵等7个统计量;10 维特征为煤浆浓度、灰度均值、能量、熵、Y分量、U分量、V分量、H分量、S分量、I分量等10 个统计量。由表4~5 可以看出,ELM 极限学习机在特征维数为10、隐藏层节点数为3 时预测精度最高;当支持向量机回归使用Sigmoid核函数时,7 个特征维度的预测精度最高。但总体预测精度低于GA-BP 神经网络和ELM 极限学习机算法。
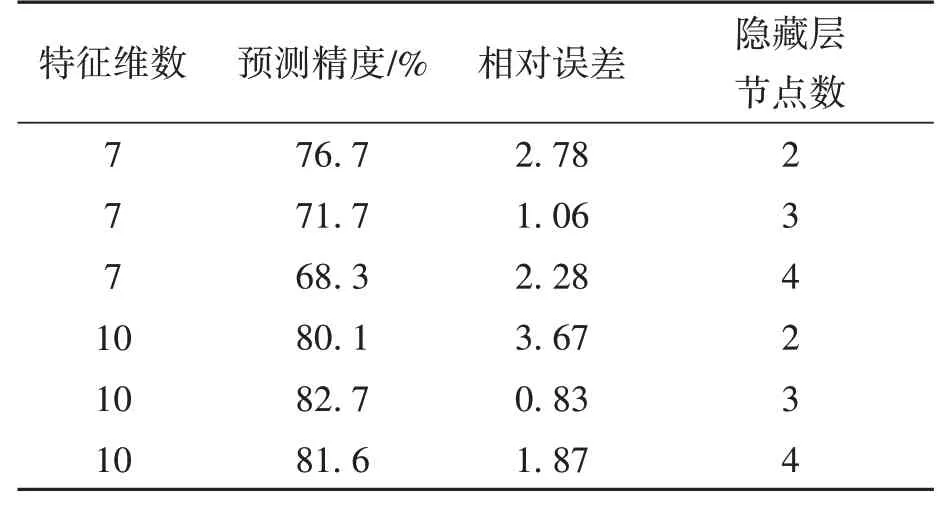
表4 不同特征维数下ELM极限学习机模型预测精度Table 4 Prediction accuracy of ELM extreme learning machine model under different feature dimensions

表5 不同特征维数下支持向量回归预测精度Table 5 Support vector regression prediction accuracy under different feature dimensions
上述实验结果表明,与支持向量回归相比,GA-BP 神经网络和ELM 极限学习机等通过多层参数的深度训练逼近正确类别的预测模型更有效,且使用10维特征统计的预测精度更高。
10维特征、4神经元时,GA-BP神经网络训练集和测试集的预测结果对比如图4~5所示。训练集的均方根误差RMSE=0.158 47,测试集的均方根误差RMSE=0.234 81。
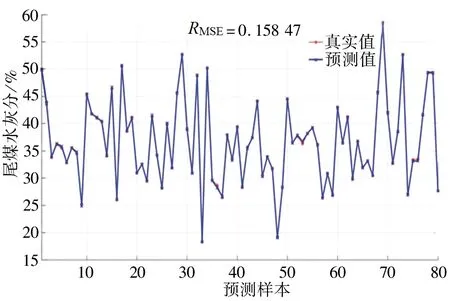
图4 训练集预测结果对比Fig. 4 Comparison of training set prediction results

图5 测试集预测结果对比Fig. 5 Comparison of test set prediction results
4 结语
提出了一种基于遗传算法优化BP 神经网络的尾煤水灰分视觉检测方法,对采集到的尾煤水灰分数据进行训练并测试,具体结论如下:
(1)BP 神经网络加入遗传算法优化后,预测精度可达97.3%,均方误差降低到0.23,对比BP神经网络预测精度提高了4%。
(2)相对于未引入彩色图像特征建立的特征维数为7、神经元数为4 的回归模型,引入彩色图像特征建立的特征维数为10、神经元数为4 的GA-BP 神经网络预测模型的预测精度提高了5.5%。
(3)经过试验对比分析,基于GA-BP 神经网络的尾煤水灰分预测模型在误差允许的范围内可以较好地实现对浮选尾煤水灰分的在线检测,有助于提高精煤产率和经济效益。
