基于DRL的巨型星座星地测控链路规划算法
2023-11-18席超杨博王记荣李公朱睿杰杨肖
席超,杨博,王记荣,*,李公,朱睿杰,杨肖
1.航天恒星科技有限公司,西安 710000 2.郑州大学,郑州 450001
1 引言
卫星通信系统正朝着低轨道、大规模、星座组网和多载荷多功能一体化趋势发展。以美国SpaceX公司为代表的技术先驱已率先全面启动天基互联网建设。全球计划部署巨型低轨星座数量多达18个以上。全球范围聚焦、聚力、抢占低轨星座市场。中国也正在规划、部署和建设相应的低轨巨型星座系统。航天测控技术是一种对航天飞行任务目标跟踪测量和控制的综合技术,通过网络通信技术完成运载火箭和卫星等航天器的跟踪测轨、遥测信号接收处理、遥控信号发送等任务,巨型星座测控属于航天测控范畴,面向的航天器是低轨巨型星座中的卫星,是实现低轨星座系统可靠运转和有序工作的关键。巨型星座测控涉及卫星全生命周期管控,管控节点多,周期长,对象广,阶段多,过程频繁复杂,同时管控效率要求高,现有的测控模式和设施无法满足供需平衡。要实现对低轨巨型星座系统高效运维管控,必须要摆脱对传统人工运维的高依赖,深化人工智能等新技术与测控技术多点融合,突破巨型星座系统测运控主要环节的高效运维管控技术。低轨星座卫星和地面测控站相对高动态运动,星地测控窗口动态多变,且存在单星多站和单站多星测控窗口规划选择问题。星地测控链路规划是执行对卫星跟踪测轨、遥测信号接收和遥控信号发送的关键和前提[1-3]。国内外对低轨巨型星座测运控相关研究较少。文献[4]构建了上行注入任务调度问题的多目标混合整数规划模型,并设计了基于规则的启发式算法进行求解;文献[5]提出了基于改进蚁群算法设计的敏捷卫星调度方法;文献[6]面向具有星间链路的卫星导航系统设计了启发式规划调度方法;文献[7]设计了基于遗传算法的规划方法,考虑了最大任务数和最小切换次数;文献[8]基于拉格朗日启发式方法设计了规划算法;文献[9]提出了改进的遗传算法。
上述方法大多采用传统的启发式方法,并且面向的是小规模的卫星系统,对测控站的资源也考虑有限。当应用在更为复杂的巨型星座系统中时,这些方法的性能和鲁棒性等都面临挑战。对于复杂的序列决策型问题,深度强化学习(deep reinforcement learning,DRL)展示出了强大的决策优化能力。通过智能体对系统环境进行“探索与评价”,利用深度学习的强大感知能力,构建深度神经网络模型对复杂环境进行特征提取,并结合强化学习的决策能力做出动作选择,并根据奖惩机制进行策略优化,现已成为解决复杂系统的感知-决策问题的重要手段[10]。本文结合卫星测运控工程经验和对低轨星座系统深入研究,将深度Q学习网络(deep Q-network,DQN)强化学习算法[11-15]技术与测控技术进行了融合,提出了一种面向未来巨型星座的高效星地测控链路组网规划算法,可为中国星座系统的建设提供相应的技术解决方案。
2 问题建模
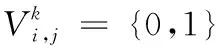

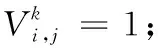


3 基于DRL的星地测控链路规划算法
DQN算法的网络框架如图1所示,采用了双神经网络架构,一个为评估网络,用来计算Q值,另一个为目标网络,用来计算目标Q值。两个神经网络的结构和初始权重值都是一样的,区别在于每次迭代训练中,评估网络每次都更新参数,而目标网络则隔一段时间才会更新参数。由于模型参数的频繁更新,容易出现震荡发散、难以收敛的现象,而目标神经网络的引入可以辅助稳定目标值,降低当前Q值和目标Q值的相关性,加快模型收敛,提升算法的稳定性。DQN的损失函数表示为目标Q值和当前Q值的均方差,智能体会使用梯度下降的方法来更新参数,损失函数的定义如下:

图1 DQN算法框架Fig.1 Framework diagram of DQN algorithm
Loss(θ)=E[(QTarget-Q(s,a;θ))2]
(1)
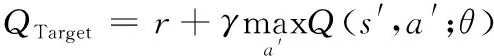
(2)
式中:θ为网络参数;γ为折扣因子;r为奖励值;s为当前环境状态;a为状态s下所采取的动作;s′为智能体做出动作更新后的环境状态;a′为状态s′下所采取的动作。
同时,DQN还引入了经验池的概念,用来存放环境、状态和奖励的相关数据,即(s,a,r,s′),在智能体学习过程中会从中抽取批次数据训练评估网络。这一机制可以有效地切断输入样本之间的相关性,同时也提升样本数据的利用率。
3.1 环境状态设计
为了更好地解决大规模星座星地传输规划问题,将问题解耦到每个离散时间片内的星地规划问题。在每个时间片内,每个测控站的初始状态都是一致的,都有相同的天线资源,但在不同的时间片内,测控站的可见卫星序列是不一致的,因此,在进行环境状态设计中,重点考虑卫星的状态。对于同一时间片内,如果一颗卫星被多个测控站可见,该卫星记为竞争卫星,对于某个测控站,卫星的状态情况如表1所示。

表1 环境状态描述Table 1 Environment status description
State={F(s1),F(s2),…,F(sl),F(s1′),
F(s2′),…,F(sL-l′)}
(3)
式中:F(s1)表示可视卫星s1的状态,F(s1)∈[0,5],可视卫星序列长度为l;F(s1′)表示填充卫星s1′的状态,F(s1′)=0,填充卫星序列长度为L-l。
3.2 动作空间选择
DQN智能体在进行动作选择时,采用了“探索与利用”的思想,即ε-贪心策略。传统的贪婪策略只会采用具有最大Q值的动作a=argmaxaiQ(s,ai),这种策略会导致智能体无法对环境信息进行更多的探索,容易陷入局部最优解。而ε-贪心策略是以ε的概率随机选取动作,以1-ε的概率选择具有最大Q值的动作,这样就增加了智能体对环境信息有更为全面的认知与掌握,不易局限于已知的局部信息之中,从而可以积累更多的经验,并逐步优化策略以获得最大化的奖励值。
在时间片tk,测控站gi∈G的动作空间大小与环境状态空间一致,定义如下:
Action={s1,s2,…,sl,s1′,s2′,…,sL-l′}
(4)
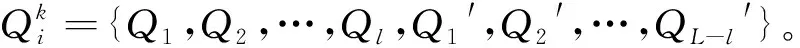
3.3 奖励函数定义
奖励函数的设计影响着智能体的动作选择和策略优化。从提升资源利用率和减少天线切换方面考虑,智能体应当尽可能地多选择非竞争卫星和在上一个时间片就连接到该测控站的卫星。因此,选中状态5到状态2的卫星对应的策略优级依次下降,而选中状态0和状态1的卫星均属于最差策略,因为这两种状态下的卫星都是无法建立星地链路。
基于上述分析,奖励函数的定义如下:
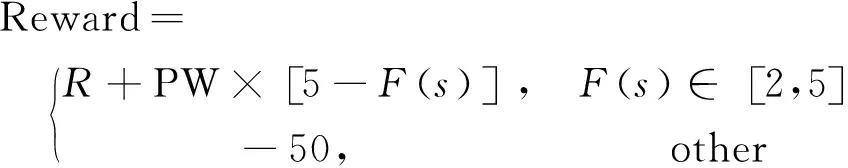
(5)
式中:R为基本奖励,设为20;PW为惩罚权重,设为-5;F(s)表示选择的卫星s的状态。选择的卫星状态级别越低时,所获得的奖励也越低,但对于选择状态0和状态1的卫星则直接给予负奖励值,因为这两种状态下的卫星是无法建立连接的。
3.4 算法流程
本算法流程如下,对于每个时间片,智能体依次为各个测控站进行卫星分配。
1 初始化评估网络和目标网络权重参数
2 while iter≤最大迭代次数:
3 fortkin iter≤:
4 forgiinG={g1,g2,…,gM}:
6 根据s,评估网络生成动作空间对应Q值序列;
7 forbwinBi={b1,b2,…,bW}:
8 根据Q值序列和ε-贪心策略选择动作a,为天线bw分配卫星;
9 计算奖励值r,环境状态更新为s′;
10 将(s,a,r,s′)存进经验池,记录分配方案;
11 learn_count += 1;
12 if learn_count % 学习步长 == 0:
13 从经验池中抽取批次样本进行网络训练;
14 if update_count % 更新步长 == 0:
15 将评估网络参数复制给目标网络;
16 目标网络计算出目标Q值;
17 计算损失函数,采用梯度下降更新网络;
18 update_count += 1;
19 计算资源利用率、天线切换次数;
20 end while;
21 输出最优分配方案;
4 仿真及结果分析
在本文的仿真场景中,空间段是由768颗卫星构成的大规模星座网络,采用极轨星座构型,共有16个轨道平面,每个轨道分布48颗卫星节点,轨道高度为1200km,轨道倾角为86°,轨道偏心率为0。地面段由23个测控站组成,随机分布在全球的各个大洲,每个测控站配有8根天线,天线的最低仰角为10°。规划周期时长设为24h,划分成1440个时间片,每个时间片为60s。
DQN算法所使用的评估网络和目标网络的神经网络架构一致,均设置3层隐藏层,各层的神经单元数量依次为1024、512和256,采用sigmoid激活函数。智能体的学习率设为0.01,学习步长为10,参数更新步长为200,经验池大小设为500,采样大小设为100,奖励折扣因子设为0.9,总的训练迭代次数为10000,采用24h的历史TLE数据计算出的可视时间窗口进行训练。
图2~4展示了DQN算法在训练过程中的测控站天线的平均利用率、平均切换次数和智能体获取的累计奖励值的变化情况。可以看出智能体通过不断学习与优化策略,获得的奖励值不断提高,可以将测控站的天线利用率提升到98%以上,并有效降低天线的切换次数。
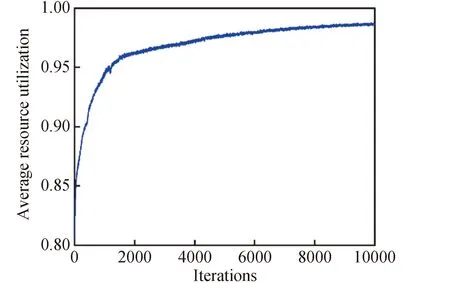
图2 测控站天线的平均资源利用率Fig.2 The average resource utilization of the antenna in TT&C station

图3 测控站天线的平均切换次数Fig.3 The average switching times of the antenna in TT&C station
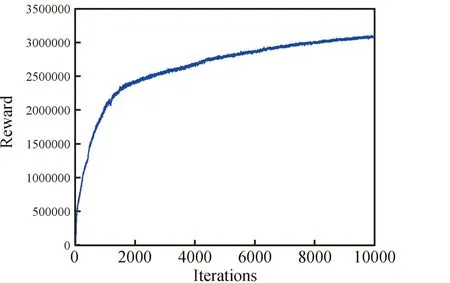
图4 DQN智能体获取的奖励值Fig.4 Reward values obtained by the DQN agent
图5和图6为训练好的DQN算法模型和遗传算法、随机算法对未来5天内的星地链路规划方案的性能比较结果,表2为DQN算法和遗传算法方案生成的耗时对比。从结果中可以看出DQN算法具有很好的鲁棒性和高效性。
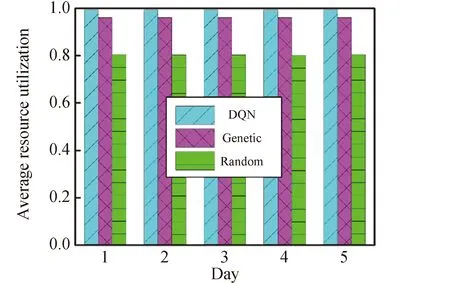
图5 DQN算法、遗传算法和随机算法的测控站平均资源利用率对比结果Fig.5 Comparison results of average resource utilization of TT&C stations by DQN algorithm,genetic algorithm and random algorithm
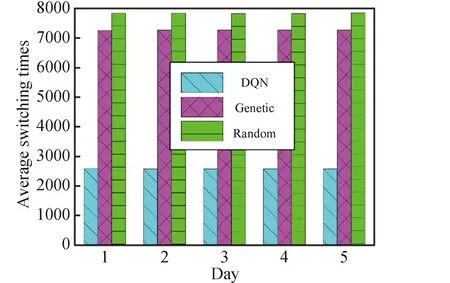
图6 DQN算法、遗传算法和随机算法的测控站平均切换次数对比结果Fig.6 Comparison results of average switching times of TT&C stations of DQN algorithm,genetic algorithm and random algorithm

表2 DQN、遗传算法和随机算法方案生成耗时对比Table 2 Comparison of generation time of DQN algorithm,genetic algorithm and random algorithm
5 结论
本文针对巨型星座系统中星地测控链路规划这一关键性问题,引入深度强化学习方法DQN进行策略优化。相比于传统的启发式算法,本文设计的算法对巨型星座有很强的适应性,利用智能体与环境进行信息交互,结合奖惩机制自动优化卫星选择策略。仿真实验表明,该算法可以将测控站天线资源率提升到98%以上,同时有效减少天线的切换次数。此外,训练好的模型可以根据未来时刻的星地可视窗口,在30s内快速生成规划方案,效率远远高于传统的蚁群算法。
