基于关键翻转集合的极化码Fast-SSC-Flip译码算法
2023-11-18郭锐孙荷杨沛
郭 锐 孙 荷 杨 沛
(杭州电子科技大学通信工程学院 杭州 310018)
1 引言
极化码是目前唯一一种通过理论证明能够达到香农极限的信道编码方案[1]。由于极化码具有低复杂度的编译码结构和优良的纠错性能,其已成为5G增强移动宽带场景(Enhance M ob ile B road Band,EM BB)中控制信道的编码方案。当极化码的码长趋近于无穷大时,串行抵消译码算法(Successive Cancellation,SC)被证明是一种可使极化码的纠错性能达到信道容量的译码算法。但SC译码算法在有限码长情况下的译码性能并不理想,并且具有较高的译码时延。
为此,研究者提出了串行抵消翻转(Successive Cancellation Flip,SC-Flip)译码算法[2]。该算法在首次SC译码失败后,继续尝试多次SC译码,选择易错的候选比特(Candidate B it,CB)进行翻转。Chandesris等人[3]提出了一种动态SC-Flip(Dynam ic-SC-Flip,D-SC-Flip)译码算法。该算法通过一种新的度量准则来权衡候选比特的译码顺序和决策对数似然比(Log-Likelihood Ratio,LLR)对候选比特可靠性的影响,动态构建及更新候选翻转比特集合,同时翻转多位错误比特。文献[4]通过比较LLR计算得到的错误概率与高斯近似(Gaussian Approximation,GA)计算得到的错误概率,以此来缩小D-SC-Flip译码算法的候选翻转比特集合。文献[5]通过优化候选翻转集合的构造,减少D-SC-Flip译码算法的搜索复杂度。文献[6]提出了基于门限的候选翻转集合构造算法,进一步提升了译码性能。文献[7]提出了一种新型的SC-Flip译码算法,同时利用奇偶校验(Parity Check,PC)和循环冗余校验(Cyclic Redundancy Check,CRC)的校验作用,相比于CRC辅助的SC-Flip译码算法,获得了更好的性能和复杂度的折中。
为了降低SC算法的译码时延,文献[8]提出了简化的SC(Sim p lified SC,SSC)译码算法。SSC译码算法能够在Rate0节点以及Rate1节点直接进行硬判决译码,有效地降低了译码时延。随后,Sarkis等人[9]进一步提出了单奇偶校验(Sing le Parity Check,SPC)以及重复(REPetition,REP)节点,并提供了这两种特殊节点的直接译码方法,使得改进后的快速简化串行抵消(Fast-Sim p lified Successive Cancellation,Fast-SSC)译码算法相较于SC译码算法在不损失纠错性能的前提下极大地降低译码时延。进一步地,文献[10]对Fast-SSC译码算法中的各种特殊节点做了归纳总结,提出了更具一般性的Type-I,Type-II,Type-III,Type-IV以及Type-V节点,通过对这5种节点直接译码,从而极大地改善SC译码算法的译码时延。
Giard等人[11]将Fast-SSC译码算法与SC-Flip译码算法相结合,提出了Fast-SSC-F lip译码算法。Fast-SSC-Flip译码算法允许在初始Fast-SSC译码失败之后,继续尝试执行最多Tmax次Fast-SSC译码算法,且每次执行Fast-SSC译码时选择候选翻转比特集合中的某个比特进行翻转。然而传统Fast-SSC-Flip译码算法在对SPC节点进行翻转译码时会有轻微的性能损失,为此研究者提出了一种新的Fast-SSC-Flip[12](New-Fast-SSC-Flip,N-Fast-SSCF lip)译码算法,能取得优异的译码性能。同一作者在文献[13]中提出了一种适用于衡量Fast-SSC译码过程中候选比特可靠性的度量准则,该度量准则能够更精确地定位到首位译码错误比特。文献[14]提出了基于易错比特列表和分段CRC校验的Fast-SSC-F lip译码算法,进一步提升译码性能。文献[15,16]提出了两种增强型的多比特翻转Fast-SSC译码算法来纠正Fast-SSC译码过程中的多位译码错误比特。
候选翻转比特集合是影响Fast-SSC-Flip算法译码复杂度以及译码性能的关键因素之一,集合大小影响候选比特的搜索效率以及复杂度。当前Fast-SSC-Flip译码算法搜索候选翻转比特的范围与全部信息比特构成的集合的维度一致。因此,本文在CS的基础上提出了关键翻转集合(Critical Flip Set,CFS),将Fast-SSC-Flip译码中候选比特搜索范围定位到CFS中,并提出了基于CFS的Fast-SSCFlip译码算法,从而降低传统Fast-SSC-Flip译码算法的候选翻转比特集合大小,减小搜索复杂度。
2 Fast-SSC-Flip译码算法
2.1 Fast-SSC译码算法

图1 所示的极化码S C 译码树利用R a t e 0,Rate1,REP以及SPC节点进行剪枝之后,可以得到如图2所示的Fast-SSC译码树。Fast-SSC译码树相较于最初的SC译码树而言,其高度已经大大降低,因此深度优先遍历的效率可以得到提升,相应的译码时延也会降低。

图1(N,K)=(8,4)的极化码SC译码树
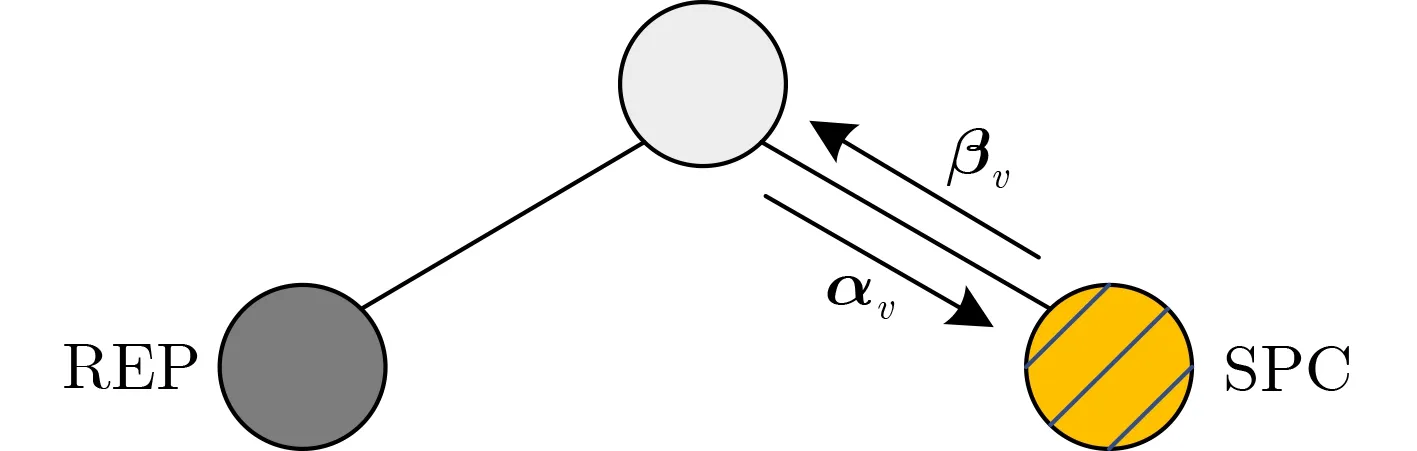
图2(N,K)=(8,4)的极化码Fast-SSC译码树
Rate0节点表示该节点有连续 2S个比特为冻结比特,因此将该节点的所有码字比特硬判决为全0比特;Rate1节点表示该节点有连续 2S个比特为信息比特,在该节点直接利用硬判决方法进行译码。REP节点仅仅只有最右侧的叶节点是信息比特,而其余的叶节点全是冻结比特。Fast-SSC译码算法在REP节点直接利用最大似然译码算法进行译码。SPC节点是指在以该节点为根节点的译码子树中,只有最左侧的叶节点是冻结比特,其余的叶节点全是信息比特。同理,Fast-SSC可以直接在SPC节点进行硬判决(Hard Decision,HD),译码输出结果为
其中,HD[i]表 示根据SPC节点内的第i个比特的LLR值进行硬判决,判决方式如式(2)所示;p表示SPC节点内所有比特的译码估计值的总和,计算方式如式(3)所示;iε表示SPC节点内最不可靠的一位信息位的索引位置,选择方法如式(4)所示
2.2 Fast-SSC-Flip译码算法
Fast-SSC-Flip算法通过找到Fast-SSC译码中不可靠的比特加入到候选翻转比特集合中,并在额外译码中尝试逐次翻转不可靠的比特,直至译码输出正确结果或者达到设置的最大额外尝试译码次数Tmax。
在衡量Fast-SSC译码过程中候选比特可靠性时,需要根据不同节点类型分别计算各个节点内候选比特的可靠性。由于Rate0节点内包含的所有比特全是冻结比特,这些冻结比特在接收端和发送端也被假设是已知的。因此本文在构建候选翻转比特集合时,仅考虑Rate1,REP以及SPC 3种节点内的信息比特。
Rate1节点内的任意第i个CB的可靠性度量计算方式为
当需要翻转的比特位于该节点内时,相应位置的比特进行翻转。
REP节点内仅含有一个信息比特,即在该节点内有且仅有1个CB,且该CB位于末尾位置。该CB的可靠性度量计算方式为
其中,N v表示该节点的长度,即包含冻结比特以及信息比特的总数量。当需要翻转的比特位于REP节点内时,该节点内的末尾比特进行翻转。
SPC节点内CB的可靠性度量计算及其无损翻转译码方法为
其中,p以及iε计 算方式参见式(3)和式(4),ε表示节点内最不可靠的比特的决策LLR值,可用式(8)计算
在Fast-SSC-F lip译码算法中,无论是计算候选比特的度量值,还是选择不可靠的候选比特执行翻转译码,都与候选翻转比特集合的大小相关。然而大部分现存文献中的Fast-SSC-Flip算法的候选翻转比特集合的大小都等于信息比特集合的大小,因此若能有效缩小候选翻转比特集合的大小,则可以有效减少度量值计算以及排序复杂度,并且可以提升候选比特的搜索效率。为此,本文利用极化码的生成矩阵得到与CS中信息比特相应的码字比特,并用这些码字比特构建关键翻转集合CFS作为候选翻转比特集合。从而降低Fast-SSC-F lip译码算法的候选翻转比特集合大小,减小搜索复杂度。
3 Fast-SSC译码算法中CS构造及其有效性
为了降低Fast-SSC-F lip译码算法搜索候选翻转比特的复杂度,一种直接的思想是缩小译码过程中首位错误比特的搜索范围,文献[16]提出的关键集合CS能够将SC译码算法中首位错误比特定位到CS中,CS在SC译码算法中有极大概率包含首位错误比特。然而由于Fast-SSC并不是在SC译码树的叶节点得到译码信息比特值,而是在Fast-SSC译码树的各种特殊节点得到相应的码字比特序列。故本节首先研究了CS在Fast-SSC译码算法中的有效性。
3.1 CS构造方法
构建CS的方法简述为:首先将SC译码树裁剪为SSC译码树,裁剪后的译码树中编码速率为1的叶节点(等效于Rate1节点)被称为极化子块,每个子块都是一个仅包含信息比特序列的极化码。将所有子块中的首位比特依次放入到初始化为空集的CS中完成CS的构建。CS详细的构建方法如算法1所示。
3.2 CS有效性
本节主要验证CS集合在Fast-SSC译码算法下是否能够有效地包含Fast-SSC译码算法的首位错误比特。本节的仿真参数如下:极化码编码方式为非系统编码,接收端采用Fast-SSC译码算法。设置极化码码长N=1 024,信息比特长度K=512,码率R=0.5,蒙特卡罗仿真次数为Tsim=106。
仿真结果见表1,“译码错误帧数”表示采用Fast-SSC译码得到的错误译码总帧数;“首错在CS中”表示Fast-SSC译码中的首位错误信息比特在由算法1构造的CS中的总帧数;“准确性”由两者的比值得到;“CS的维度”表示CS集合的大小。
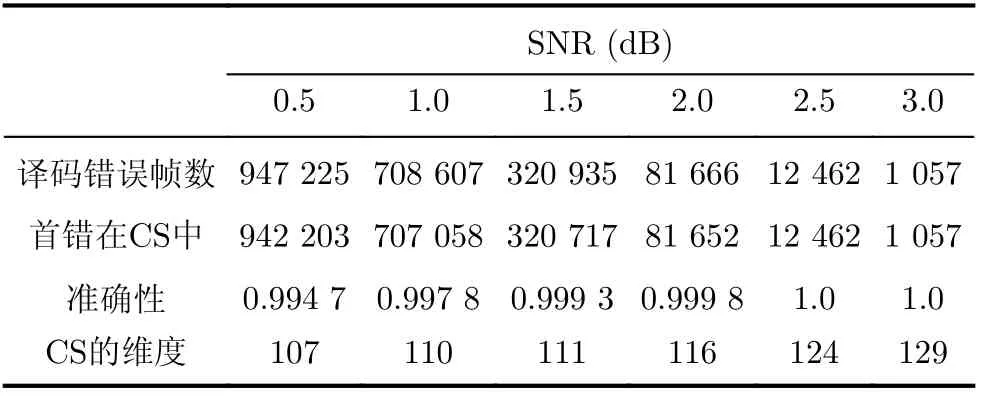
表1 N =1 024, K =512 T sim =106, 时CS的有效性验证
仿真结果验证了CS在Fast-SSC译码过程中仍然有效,即CS有接近100%的概率能够包含Fast-SSC译码过程中的首位译码错误比特,且CS的维度小于信息比特集合的大小。
4 关键翻转集合CFS的构造
4.1 基础理论及结论证明
图3给出了SC译码树转换成Fast-SSC译码树的过程。{u1,u2,u3,u5}表 示冻结序列,{u4,u6,u7,u8}表示信息序列。右边的译码树表示该极化码的Fast-SSC译码树。其中左边叶节点为REP节点,该节点可以描述成一个长度为4,包含{u1,u2,u3,u4}的子极化码。同理,右边叶节点为SPC节点,可以描述为一个长度为4,包含{u5,u6,u7,u8}的子极化码。

图3 极化码SC译码树以及Fast-SSC译码树
当进行Fast-SSC译码时,利用硬判决方法对REP以及SPC节点直接译码得到的结果称为码字序列。在Fast-SSC译码过程中,只有翻转首位错误码字比特才能避免错误传播对Fast-SSC译码过程的影响。然而CS是相对于信息比特序列而言的,因此对于Fast-SSC译码,需要寻找与CS中的信息比特相应的候选比特(码字比特)才能构建候选翻转比特集合。
对于一个码长为N=2n的极化码,其生成矩阵G N=(g1,g2,...,g N)=F⊗n,其中GN的列向量gi中元素1的位置构成的集合为Ωi。若叶节点l长 度为L,当前子极化码对应于极化码的索引为(τ+1,τ+2,...,τ+L),l由包含的信息比特序列经过极化编码构成,在节点l处可得到码字序列为
其中,G L为 该子极化码的生成矩阵。当译码树的叶节点l为Rate1或者REP节点时,在2元域下,本文给出如下命题:
命题1若Fast-SSC译码中首位错误信息比特uτ+i在 译码树的叶节点l内,且是由l译码得到的部分码字比特xˆΦ错误导致的,则必然有Φ⊆Ωi且有极大概率|Φ|=1,其中Φ表示为候选翻转比特集合。
证明 若节点l得到的译码码字序列为,则该节点包含的信息序列为
其中,第2步等式是根据文献[1]中给出的G N=,故可以得到首位错误比特uτ+i的估计值为
因此对于Rate1及REP节点而言,若确定首位错误信息比特uτ+i,则其相应的候选比特集合Φ可由命题1得到。当译码树的叶节点l为SPC节点时,若首位错误信息比特uτ+i在该节点内,则根据文献[17]可知,SPC节点有极大概率仅存在两位错误比特,一位为固定翻转码字比特(由于该比特是固定翻转比特,因此并没有被包含于该文献中的节点内错误比特数量统计结果),另一位为待确定的由信道噪声导致译码错误的某个候选码字比特e。由于命题1是在2元域讨论下得到的结论,则两位错误比特必然不可能同时在xΩi中,否则根据式(11)可知,两位错误比特将导致uτ+i正确译码。将uτ+i相应的固定翻转位记作µε,且计算为
综上所述,对于Rate1,REP以及SPC 3种特殊节点,若确定首位错误信息比特uτ+i,则都能够利用命题1来构建uτ+i相应的候选比特集合。
为了便于理解命题1,本文以图2中的SPC节点为例。该SPC节点为一个码长N=4的子极化码,包含信息比特序列(u6,u7,u8),u5为冻结比特且设置为0,该子极化码对应的子树结构如图4所示,其中蓝色节点表示SPC节点,白色叶节点表示冻结比特,黑色叶节点表示信息比特。当利用Fast-SSC算法进行译码时,在SPC节点得到的正确译码码字为
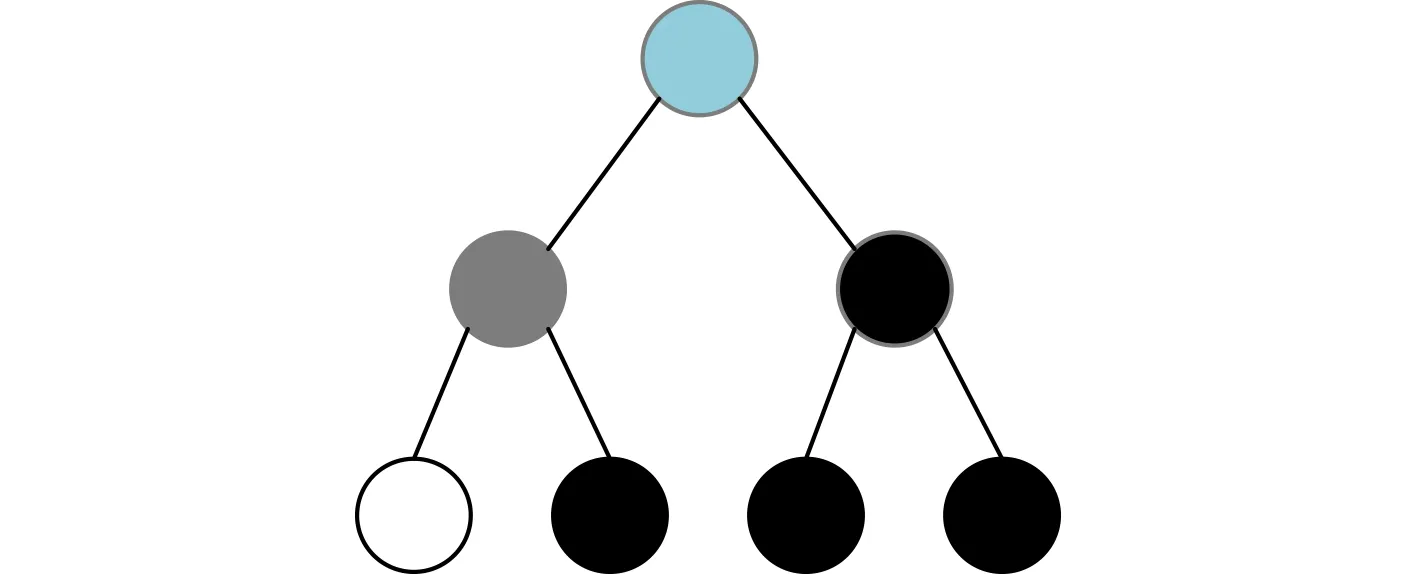
图4 译码树SPC节点对应子树结构
其中,G4为该子极化码的生成矩阵。假设上述的极化码在Fast-SSC译码中首位错误比特为u6,则根据式(13)有
根据式(14)可知,导致u6译码错误的原因是x2或x4译码错误,即有Φ={2}或Φ={4};显然Ω2={2,4},故Φ⊆Ωi成立。证毕
4.2 CFS构造算法
基于上述的命题1,在Fast-SSC译码过程中,首位错误信息比特一般都是由其所在的子极化码的某位码字比特xΦ译码错误导致的;同时根据Fast-SSC译码中首位错误信息比特有接近100%的概率在CS中的结论,本文将CS中的每个信息比特对应的xΦ收集起来构成一个关键翻转集合CFS。不同于CS的构建方法,CFS在CS的基础上,需要利用LLR以及生成矩阵完成,其不仅与极化码的结构有关还与译码过程有关。
CFS构建方法如算法2所示:注意到算法2所述算法的第1行利用的是算法1所述的CS构造函数;第3行根据Fast-SSC译码树结构确定CS(i)相应的Ω,先确定C S(i)所 在的子极化码生成矩阵GN以及其相对节点内的首位信息比特的位置i,根据GN以及i确定相应的Ω;第4行描述的衡量码字比特可靠性的度量准则,所使用的度量准则为码字比特的决策LLR。表示码字比特序列相应的决策LLR向量。

算法2 CFS构造算法
CFS构造算法一个直观的解释是,Fast-SSC译码过程中首位错误比特一般是由于该比特所在的子极化码某位译码错误导致的,且该比特必然属于因此本文选择xΩ中最不可靠的码字比特作为CFS集合中的一员。同时,由于CS集合有极大概率包括Fast-SSC译码的首位错误比特,故为了减少复杂度,本文仅考虑在CS基础上构建相应的CFS。
5 CFS-Fast-SSC-Flip译码算法及性能
5.1 CFS-Fast-SSC-Flip译码算法
本文基于提出的CFS设计了一种单比特翻转Fast-SSC译码算法,命名为CFS-Fast-SSC-Flip译码算法。CFS-Fast-SSC-Flip译码算法详细的描述见算法3。所提算法与传统的Fast-SSC-Flip译码算法的主要区别为:所提算法选择候选比特进行翻转译码时仅从CFS中选择,相较于传统的Fast-SSCFlip使用整个信息比特集合的搜索范围而言,减小了搜索复杂度,有效提升候选比特的搜索效率。
5.2 CFS-Fast-SSC-Flip译码器性能分析
为了研究提出的CFS-Fast-SSC-Flip译码算法译码性能,本节将算法3中第4行的度量准则设置为根据候选比特的决策LLR升序排序,并与Fast-SSC-Flip(s=0.5,算法补偿系数),N-Fast-SSCFlip,Fast-SSC以及SSC-Oracle译码算法进行性能比较。由于本文所提的CFS-Fast-SSC-Flip译码算法的CFS是基于CS构建的,因此本文同时比较了基于CS的Fast-SSC-Flip(Fast-SSC-Flip-CS)译码算法的性能。SSC-O racle译码算法是一种理想的Fast-SSC译码算法,该算法能够完美纠正Fast-SSC译码过程中由信道噪声导致的单个错误比特,即该算法的性能代表单比特翻转Fast-SSC算法的译码性能上限。

算法3 CFS-Fast-SSC-Flip译码算法
当设置极化码的参数N=512,R=0.5时,上述各个译码算法的BER性能曲线如图5(a)所示。从图5(a)可以看出所提的CFS-Fast-SSC-F lip译码算法与N-Fast-SSC-Flip译码算法的BER性能曲线几乎保持一致,相较于传统的Fast-SSC-Flip译码算法以及Fast-SSC-Flip-CS译码算法,所提的CFSFast-SSC-F lip译码算法并没有明显的BER性能损失。相较SC,Fast-SSC译码算法在BER=10-3条件下有0.78 dB的性能增益。

图5 CFS-Fast-SSC-Flip译码算法与各种译码算法在R =0.5时BER性能比较图
类似地,图5(b)表示N=1 024,R=0.5时上述的各个译码算法的BER性能数值仿真图。综合图5(a)与图5(b)可得,所提的CFS-Fast-SSC-Flip译码算法与N-Fast-SSC-Flip译码算法的BER性能曲线几乎保持一致,相较于传统的Fast-SSC-Flip译码算法以及Fast-SSC-F lip-CS译码算法,所提的CFSFast-SSC-Flip译码算法并没有明显的BER性能损失。

类似地,图6(b)表示在极化码参数N=1 024,R=0.5时上述的各个译码算法的FER性能数值仿真图。通过观察两图可以发现,提出的CFS-Fast-SSC-Flip算法的译码性能略优于传统的Fast-SSCFlip译码算法以及Fast-SSC-Flip-CS译码算法,且与N-Fast-SSC-Flip译码算法的性能几乎相同。
为了研究CFS-Fast-SSC-Flip译码算法的性能开销以及译码延迟,本节利用翻转译码算法的平均迭代次数Iave来表示每一帧需要进行译码的次数,其最小和最大的迭代次数分别为1和Tmax+1。Iave的计算方法为
为了更好地分析所提算法的译码延迟[18],对各种算法的时钟周期(C lock Cycles,CC)进行比较。为了便于表述每个译码阶段所消耗的CC数,其中Fast-SSC译码算法消耗的CC数、排序操作消耗的CC数、CRC校验消耗的CC数以及一轮额外迭代的CC数分别用CFast-SSC,CSort,CCRC以及CExtra进行表示。假设在第1次译码过程中,首先进行Fast-SSC译码操作,然后执行排序操作,其中CRC校验和排序操作同时执行。因此在第1次译码过程中消耗的C1=CFast-SSC+CSort。在额外的迭代译码过程中仍然先执行Fast-SSC译码操作,与第1次译码不同的是,后续的迭代译码过程不需要进行排序操作。因此,每一轮额外的迭代译码消耗的CExtra=CFast-SSC+CCRC。综上,译码一帧所需CC数量的计算表达如式(16)所示
由于所对比的几种不同算法均基于Fast-SSC,在保持参数一致的情况下,译码过程中消耗的CFast-SSC,CCRC一致。因此,译码一帧中消耗的CC数量取决于CSort。传统的Fast-SSC-Flip译码算法对K个信息比特的LLR值进行排序,而CFS-Fast-SSC-Flip仅对CFS中η个信息比特的LLR值进行排序。在排序过程中消耗的时钟周期CSort(η)<CSort(K)。由表2可以得到,本文所提的CFS-Fast-SSC-Flip译码算法的平均迭代次数Iave要小于等于目前现存的Fast-SSC-Flip译码算法。综上,本文所提算法的译码延迟要优于Fast-SSC-Flip算法、且与N-Fast-SSC-Flip译码算法的译码延迟接近。
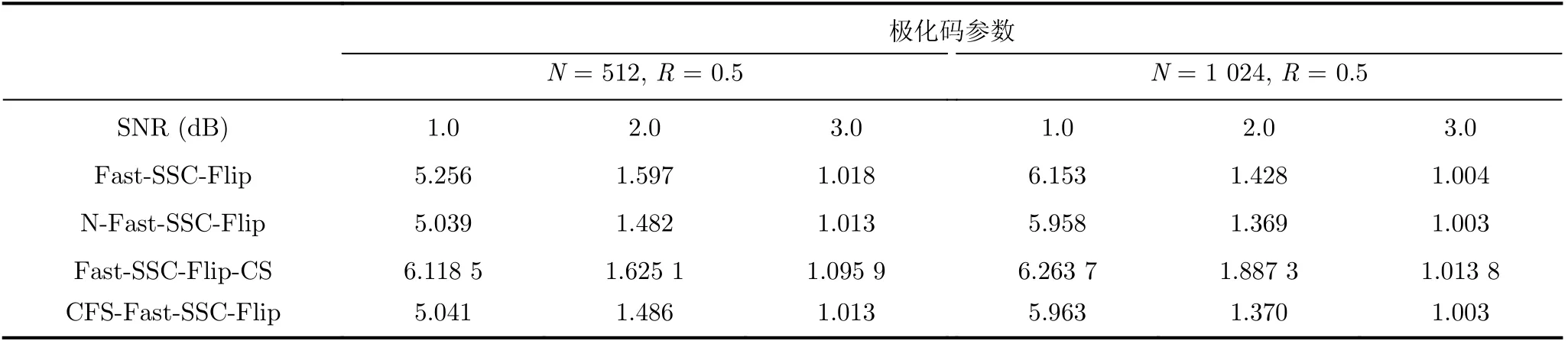
表2 各种译码算法的平均迭代次数
本文所提的CFS-Fast-SSC-F lip译码算法相较于传统Fast-SSC-Flip以及N-Fast-SSC-Flip译码算法的一个直观优势是在候选比特的搜索效率。传统的Fast-SSC-Flip译码算法在搜索候选比特方面的复杂度为O(Klog2K),而CFS-Fast-SSC-F lip译码算法的搜索复杂度为O(ηlog2η)。其中K表示信息比特集合大小,η表示CFS集合的大小。
表3比较了本节所提的CFS相较于传统的Fast-SSC-Flip所使用的候选翻转比特集合大小。从表3可以得到本文所提的CFS集合的大小在不同极化码编码参数以及信噪比的情况下都要小于传统的Fast-SSC-Flip译码算法所使用的候选翻转比特集合大小。在极化码的码长N=1 024,码率R=0.5,本文所提的CFS-Fast-SSC-Flip译码算法相较于传统Fast-SSC-Flip(N-Fast-SSC-F lip与传统Fast-SSC-Flip两种译码算法的候选翻转比特集合大小相同),至少能缩小77.93%的候选翻转比特集合大小。
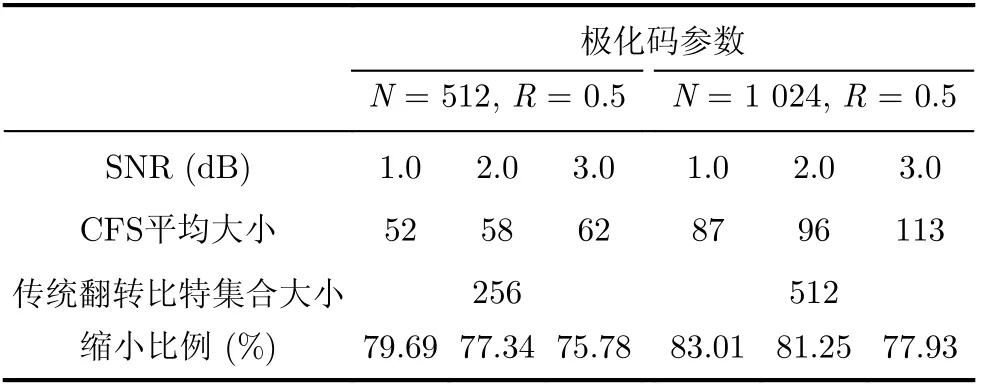
表3 CFS与传统Fast-SSC-Flip译码算法的候选翻转比特集合大小比较
6 结论
本文从缩小Fast-SSC-Flip译码算法中的候选翻转比特集合大小出发来提升Fast-SSC-Flip的候选比特搜索效率,由此提出了CFS-Fast-SSCFlip。本文所提的CFS能够有效地包含候选翻转比特,但集合大小远小于全部信息比特集合大小,从而减小搜索复杂度。实验结果表明,本文提出的基于CFS的Fast-SSC-F lip算法在和N-Fast-SSCF lip取得相近的译码性能和平均迭代次数的情况下,显著地缩小了候选翻转比特集合的大小,减小了搜索复杂度,提升了候选比特的搜索效率。
