大数据环境下典型文献资源发现系统评测与建议
2023-11-17李雪原张洁
李雪原,张洁
研究论文
大数据环境下典型文献资源发现系统评测与建议
李雪原1,张洁2 *
1.中国农业大学图书馆,北京 100193,中国;2.中国农业科学院农业信息研究所,北京 100081,中国
以Primo、Summon、EDS、百度学术、超星发现5种较为常用的发现系统为样本,梳理归纳发现系统的功能特点,研发、测试文献资源发现系统的评测指标体系并进行具体评测,调研分析用户在使用发现系统中获取信息的影响因素、系统易用性的影响因素、以及用户忠诚度的影响因素,同时结合大数据的发展与影响,提出6点发展建议:加强元数据的规范建设、提升文献信息的揭示度与获取途径、优化相关性排序、提升个性化服务、利用衍生数据推动精准服务、加强顶层规划,建立协同合作机制。
资源发现系统;知识发现系统;Primo;Summon;EDS;百度学术;超星发现系统
1 引言
随着文献资源总量的持续快速增加,文献发现在规模体量和技术体系上已进入大数据时代,在海量资源中准确且高效地发现、定位用户需求的文献资源,已经成为文献管理与服务的核心挑战。用户的需求从简单的搜索转变为知识发现,文献发现技术的范式也从数据库资源导航、联邦搜索演进至资源发现阶段。文献发现系统是在元数据的发展基础之上,不断地与爬虫采集技术、预处理技术、存储挖掘技术、可视化展示技术等大数据技术相结合的产物,是一种新的信息资源整合系统,可以理解为图书馆的Google[1]。它具有很强的颠覆性,不仅可以整合图书馆各种类型的文献资源,包括商家电子资源、自建数据库、馆藏纸本资源、以及网络开放获取资源,实现统一检索,还可以满足用户筛选、排序、多渠道获取全文、以及评论与交流的需求,是一个集资源与服务于一体的搜索平台[2]。截至2022年1月,国内市场上仅Summon一家发现系统就已经达到70家图书馆以上,国内39所“985”院校的图书馆已全部配置资源发现系统,有的图书馆甚至配置了中外文两套发现系统[3]。
国外发现系统的起步与发展比国内早很多,发现系统的类型也较多:商业研发的主要有AquaBrowser、BiblioCore、EDS、Encore、Enterprise、Primo、Summon、WorldCat Local;使用开源技术的主要有Blacklight、eXtensible Catalog、VuFind这三种[4-6]。国内的发现系统以商业研发为主,主要有超星发现系统、中国学术搜索、智立方发现系统、学知搜索,百度学术搜索等,自主研发的有国家图书馆的“文津”搜索系统[7]。国外发现系统不仅数量较多,在功能上也起到了引领作用。如AquaBrowser提供的是一种基于主题词云图的分面导航检索方式。它可以将图书馆的MARC数据自动转成XML记录,系统对每个XML记录进行特征抽取和共线性分析,从而将每个信息对象与关键词进行可视化链接,形成云图。用户的检索行为由图示引导,可以视为一种可视化搜索方式。BiblioCore在2014年时推出了馆员荐读功能,这一新功能可以帮助图书馆员在书目页面上发表推荐评论,可以导入来自任何第三方的博客内容,并可以优先标识或标注这些内容。Blacklight具有添加社会化标签的功能,以实现用户信息的共享。与Blacklight类似,VuFind允许用户给书目记录添加Tag,让用户建立自己的分类模式,使用户在一定程度上免去传统受控词表带来的困扰[4-6]。
以Primo、Summon、EDS、超星发现、百度学术等为主体的国内外文献发现系统,已经成为用户发现、定位文献资源的主要工具。目前学者对发现系统的研究大多集中在发现系统的检索功能和使用性能方面,是基于系统自身的总结性梳理和比较,缺少与用户体验的结合。在此意义上,笔者以用户调查为手段,以Primo、Summon、EDS、超星发现、百度学术为样本,研发、测试了文献资源发现系统的评测指标体系并进行了具体评测,这对文献发现技术与系统的研发与持续改进具有积极意义。
2 数据和方法
外文发现系统在中国推广较好的有Primo、Summon、EDS和OCLC的WorldCat四大发现系统,为更好地分析比较发现系统的功能与特点,在这四大外文发现系统中选取Primo、Summon、EDS三个作为典型案例;中文发现系统选取百度学术搜索与超星发现系统作为典型案例。为了深入了解各个发现系统平台的特点,对选取的五家发现系统进行了检索测试,测试的版本选取:Summon选取了北京大学的未名学术搜索、Primo选取了清华大学的水木学术搜索、EDS选取了武汉大学的珞珈学术搜索、超星发现系统选取了中国农业大学的试用版本;考察内容主要围绕以下四方面:1)系统质量;2)信息质量与获取方式;3)服务与反馈;4)整合的外部数据源。分析结果如表1所示。为了更好地了解用户对这五家发现系统的使用感受,以问卷的方式进行用户使用测试。
2.1 问卷设计
资源发现系统是一种典型的信息系统,参考陈颖[8]、赵钊[9]、Sabeh[10]、DeLone[11]等人的信息系统评价模型,同时考虑资源发现系统的特点,将信息质量、系统质量、服务质量、用户满意度、用户使用意愿作为主要测评方向;结合Lundrigan[12]、Stubley[13]、Kronenfeld[14]等人的研究,共设置了17个测评指标,见表2。与图情专业人员、教师、研究生进行商榷与访谈后,增加了三道排序题,最后形成问卷。问卷主要包括三部分:第一部分主要收集样本的人口统计学特征以及查找信息的入口习惯;第二部分采用Likert5分制考察用户在体验资源发现系统时对信息质量、系统质量、服务质量、用户满意度、用户使用意愿的感受;第三部分则是略带开放性的排序题,询问用户在检索时最看重哪一部分因素,并进行优先排序[15]。
2.2 数据收集
问卷先是采用了在线问卷的形式,进行一周预测试后,效果反响不佳,预测试问卷回收结果显示,不少用户对资源发现系统不很了解,这与平时对资源发现系统的推广不够有关。为了保证用户在测试时遇到的问题能够得到及时解答,后采取了线下问卷调研的形式,分别选取了中国农业大学、青岛大学、北京师范大学三所高校进行调研,主要调研对象为本科生、研究生与教师,最终回收问卷379份,剔除作答不完整与无效问卷后,实际统计分析问卷数量为338份,详见表3。
3 五家典型资源发现系统评测分析
3.1 数据统计与分析
问卷调查样本的性别、身份及查找文献优先选择的检索入口特征,如表4所示。从被调查者的人口数据可看出:男女比例较均衡,占比分别为46.45%与53.55%。样本身份主要以研究生为主,占比为 58.28%,其次是本科生,占比为33.43%,最后是教师,仅占8.28%,说明在该调查中研究生与本科生的参与积极性较高,教师的参与度欠缺。当询问查找资料优先使用哪个检索入口时,占比最高的是“知网、SCI等数据库”,占比为50.59%,其次是“百度学术”,占比为20.12%,而“图书馆书目查询系统”的占比为15.09%,“图书馆提供的发现平台”的占比为14.20%。由此可以看出,大部分研究人员在选择文献查找渠道时,并没有选择图书馆提供的检索入口,而是直接选择经常使用的数据库或百度学术。
数据收集整理后,利用Spssau数据处理平台,对数据的信度、效度进行检验,得到表5。总量表Cronbach’a系数为0.915,17个潜变量的Cronbach’a系数均大于0.8,KMO值为0.731,P<0.001。根据统计学研究观点,Cronbach’a系数在0.8 以上说明样本数据信度良好,KMO值大于0.7说明效度良好。此外,因子载荷与CR值均大于0.7,AVE 值大于0.5,说明聚合效度良好。
3.2 结果分析
3.2.1 各指标平均值比较
从图1平均值对比图可以看出,SERQ1、SERQ2、SERQ3、USQ1、USQ2项分值较低,在4分以下,其他分值均在4分以上。最低的分值是3.48,对应的指标是“个性化功能(检索历史自动保存/订阅推送服务/可视化分析、社交分享等)”,倒数第二分值为3.81,对应指标是“实时咨询服务”,第三低的分值为3.98,对应指标是“人工智能服务(拼写检查、检索词智能修正等)”。三项最低分值的指标均是“服务质量”指标,在测评的五家发现系统内,用户对系统提供的服务满意度都比较低。但对于五家发现系统的信息质量、系统质量的打分均在4分以上,用户的使用意愿均值也在4分以上,这说明基于信息质量、系统质量,用户的使用意愿还是蛮强烈的,只是服务质量的欠缺,造成用户的满意度稍低。
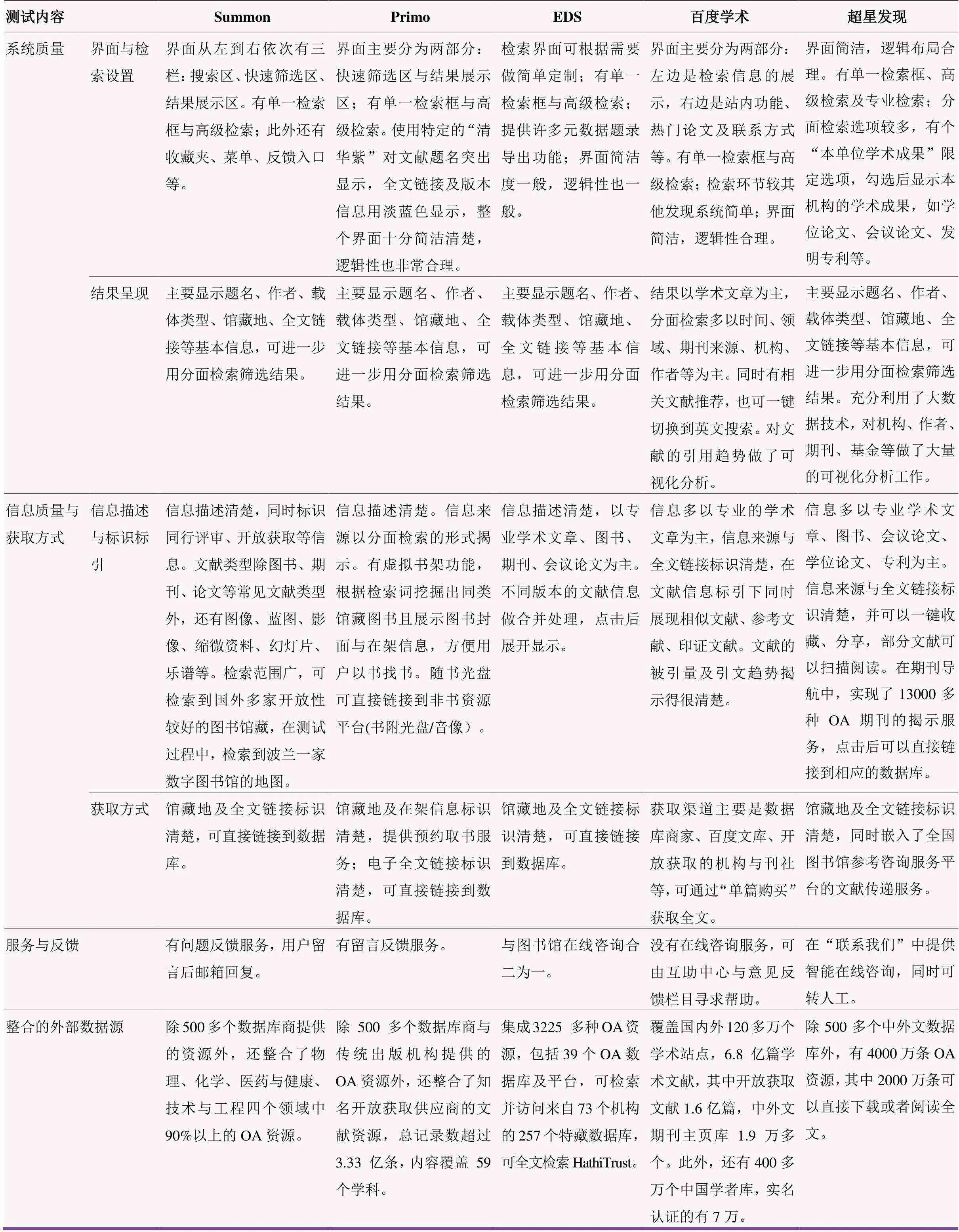
表1 五家中外文发现系统功能特点梳理归纳
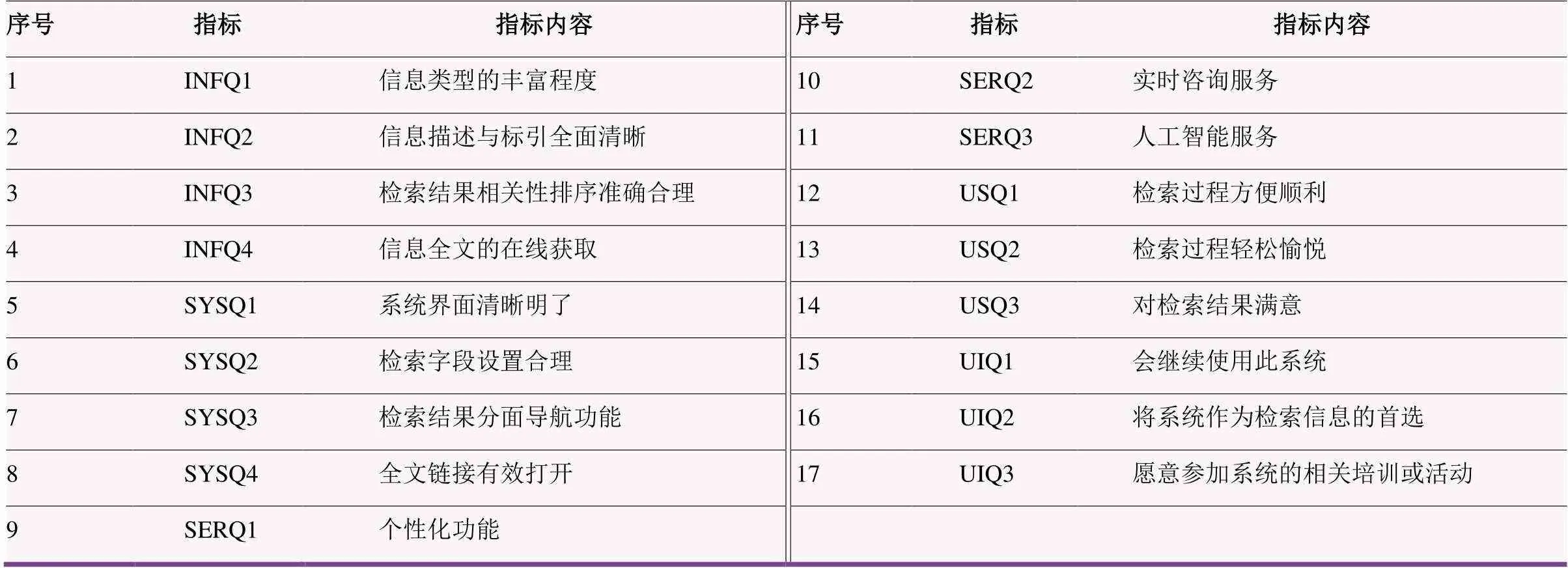
表2 17项测评指标与指标内容描述

表3 测评问卷回收情况
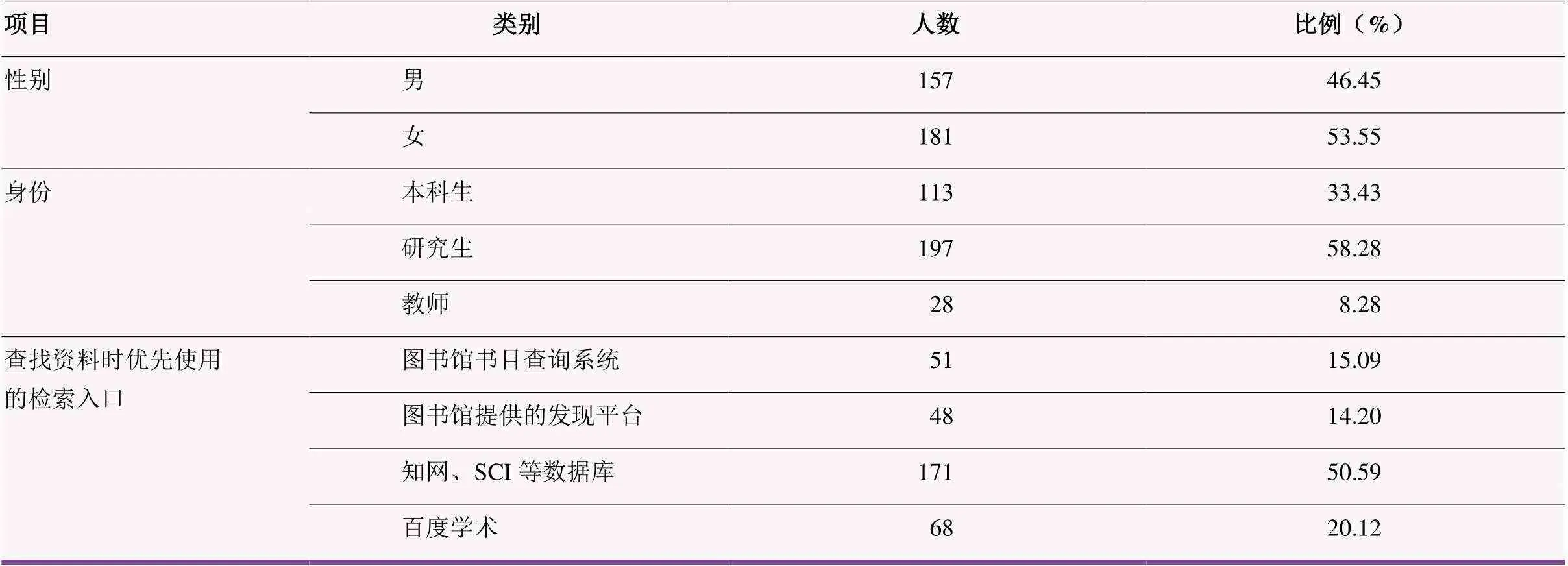
表4 样本人口学统计分析
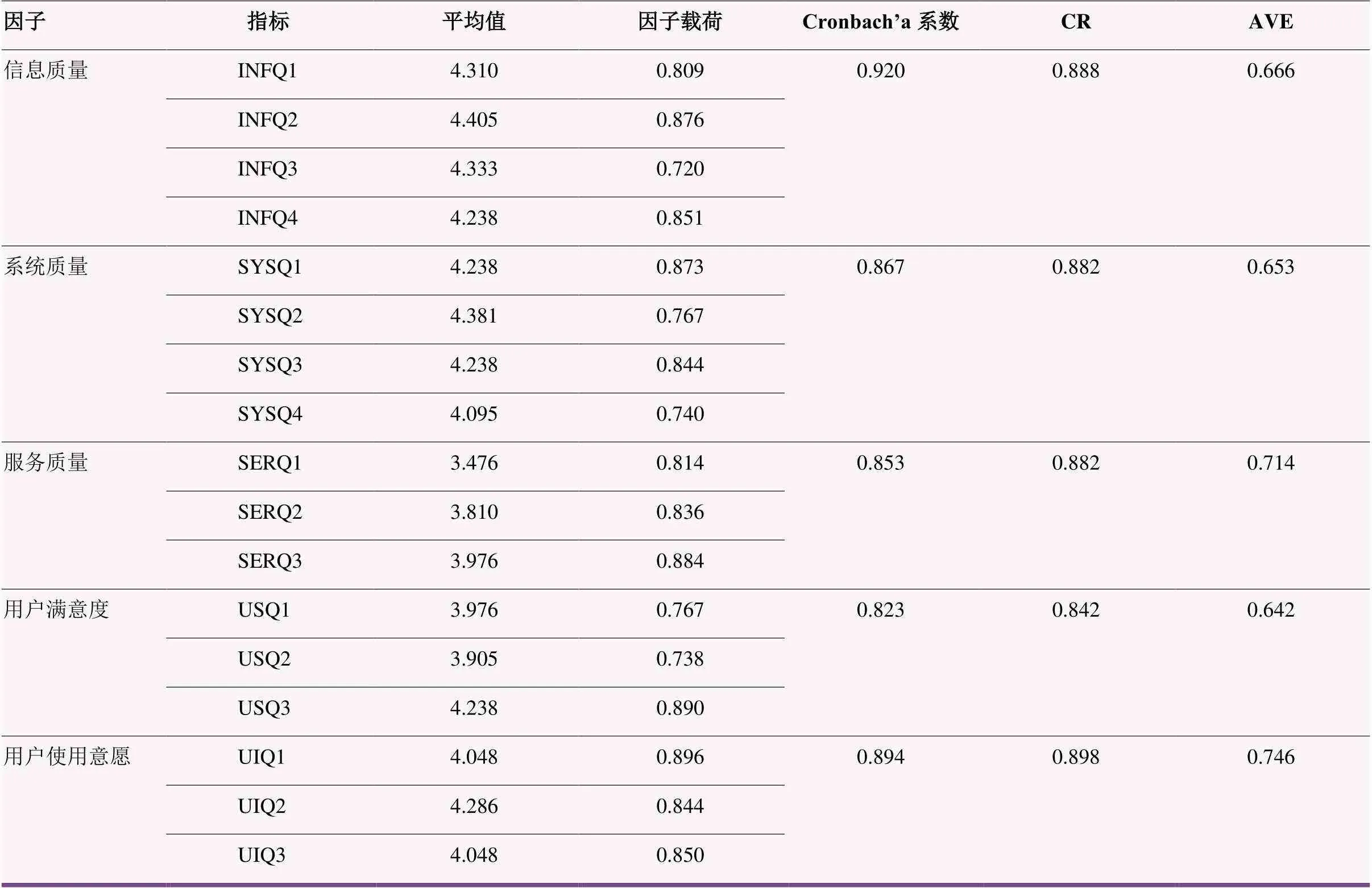
表5 因子平均值、因子载荷、Cronbach’α系数、CR、AVE 值
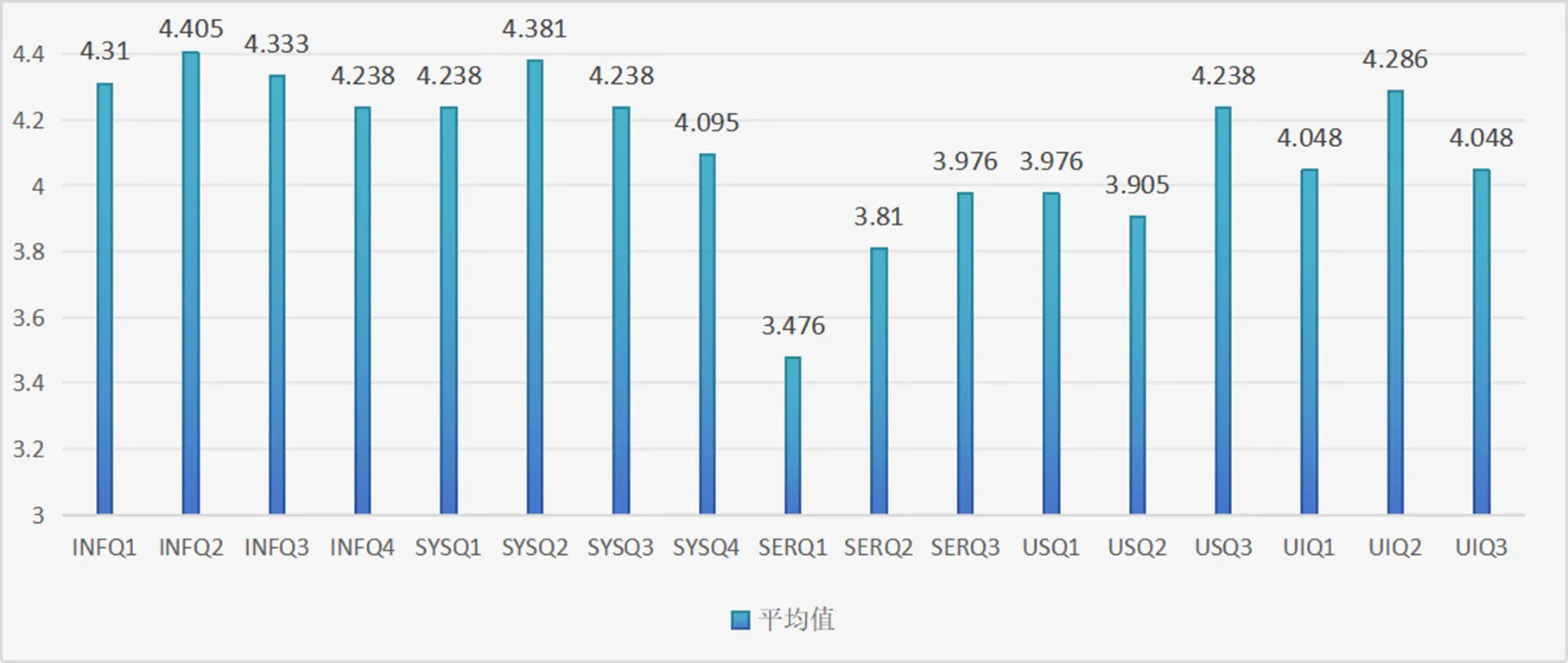
图1 各指标平均值比较
3.2.2 获取信息的影响因素分析
在询问“获取信息过程中哪个因素比较重要”时,调查对象给出的答案排在前三位最多的分别是:全文获取容易、相关性排序合理、信息足够丰富。由此可见,大部分科研用户很看重最后的全文获取这一步,如果最终不能获得全文,用户的前期检索工作很大程度上将失去意义。所以,怎样最大限度地实现这一功能,发挥平台效益,是平台未来发展的重点。信息的丰富程度和检索结果的相关性也是用户比较在意的,也有研究显示,人们在检索过程中往往只查看前20条检索内容[16],一些资源发现系统在文献结果排序过程中,会侧重于自己拥有的与商业有合作的资源,Boram[17]曾指出,同一条文献在不同的发现平台检索结果中其排序位置差异很大,这种有倾向的排序难免造成用户错过一些资源。资源发现系统如何利用大数据技术提升排序的合理性、科学性是未来突破的重点。
3.2.3 系统易用性的影响因素分析
在询问“最影响发现系统易用性的因素有哪些”时,排在前三的选项是:界面干净明了,导航清晰;全文获取链接设置明显;有实时在线的参考咨询服务。对于“界面干净明了,导航清晰”的要求五家发现系统都做得较好。对于“全文链接设置明显”,在测评的五家发现系统中,超星发现整合了全国高校馆藏信息,并可以直接链接到BALIS参考服务平台;艾利贝斯也已将旗下的Primo发现系统与馆际互借系统RapidILL进行技术上的对接整合,同样的馆际互借系统还有Borrow Direct,也是图书馆可以考虑嵌入的文献传递系统[18-20];百度则是链接各大数据库商,如果不在商家服务IP内,则需付费获取全文。对于排序第三的“有实时在线的参考咨询服务”这一项,有用户反映发现系统的宣传推广做得太少,用户对发现系统的使用、认知、熟练程度都很欠缺,在检索过程中也确实遇到过“检索失败”“检索到x条结果但并未显示结果”“检索方式不习惯”“系统无纠错能力”等问题,这些问题的解决有赖于服务的加强,如“在平台中嵌入检索技巧讲解视频”“平台本身具备一定的智能纠错(如拼写检查、检索词智能提示、修正、扩展等)”以及设置“人工在线咨询服务”等。在测试过程中,超星发现在这一项上做得较好,提供的“人工在线咨询服务”可随时解答问题。
3.2.4 忠诚度的影响因素分析
在询问“五家资源发现系统中您优先推荐哪个”时,排序前三的是:Summon发现系统、超星发现系统、百度学术搜索。从表6可以看出,在五家发现系统中,每家发现系统的侧重点与优势各不相同。Summon发现系统在信息丰富度、相关性排序两方面分值最高。Primo发现系统在信息描述与标引、全文在线揭示度分值最高,学者武丽娜[21]在2018年“大学出版社学术资源在发现系统中的索引深度调查”中也曾指出,相同的学术文献资源在Primo和Summmon两种发现系统中的索引深度不一致,相比较而言,Primo的索引深度略高于Summon。超星发现系统在个性化功能上分值最高,是中文发现系统中的佼佼者,深受用户好评。百度学术因为入口便捷,简单易用,在“会继续使用此系统”与“将系统作为检索信息的首选”两项上分值最高。
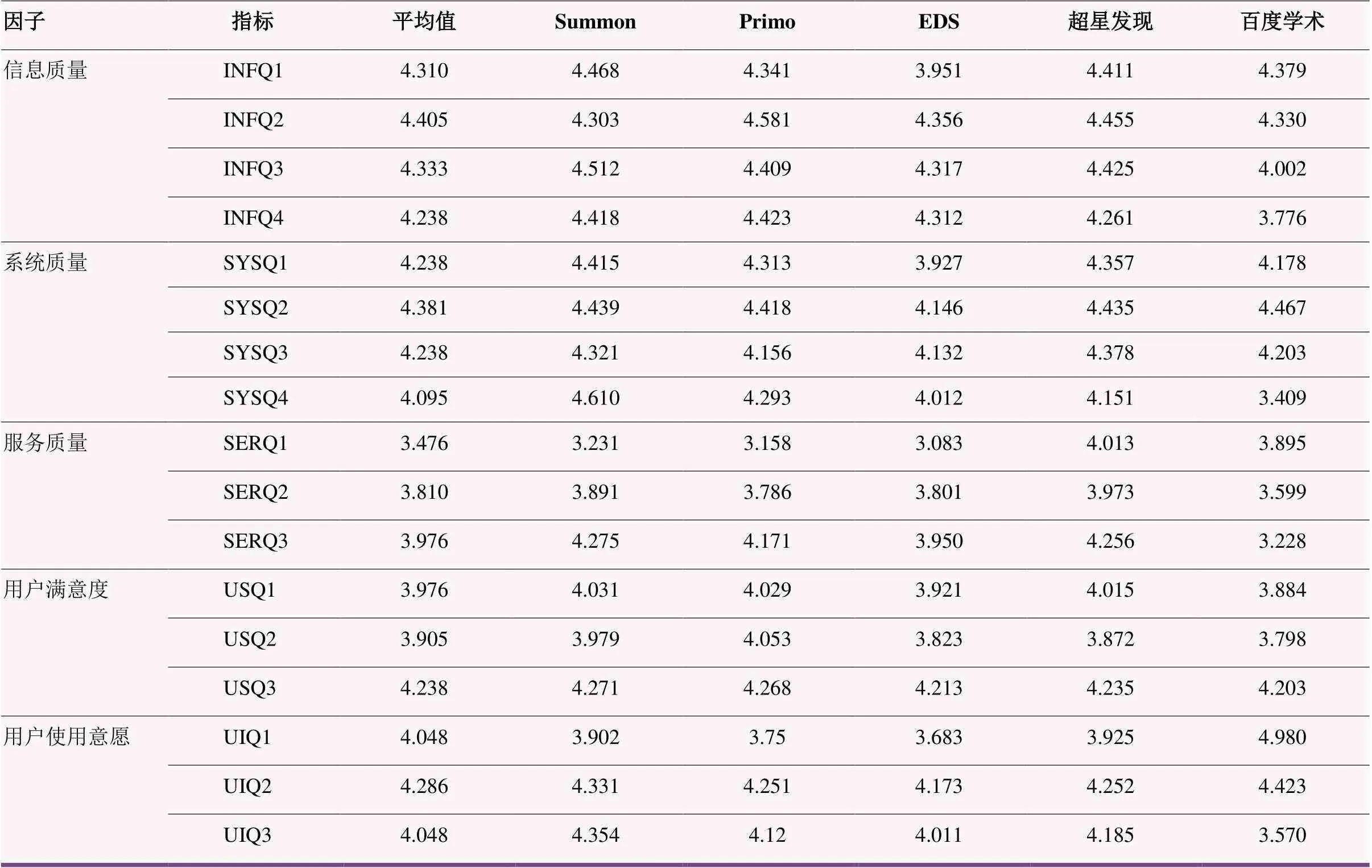
表6 五家发现系统测评指标分值比较
3.2.5 国内外发现系统比较
国外的发现系统发展较早,在数据资源与应用技术上都略领先国内的发现系统。Summon、Primo、EDS三家发现系统在信息的丰富程度、结果的相关性排序、以及全文获取上发展得非常成熟;国内以超星发现、百度学术为代表的发现系统由于受数据库商的限制,在全文获取方面有待提升,同时此次调研显示,超星发现系统在可视化展示、在线服务、和个性化服务方面表现十分突出。学者覃燕梅[22]、王新才[23]、宋姗姗[24]都对超星发现与百度学术进行过比较分析,认为超星发现在元数据质量、检索结果排序以及数据挖掘服务上优于百度学术。无论国内还是国外的发现系统,都有待开拓学术社区功能、用户标签分类功能、可视化搜索功能、用户与馆员的交互功能,学者袁玉英也曾选取Summon、Primo、EDS和WorldCatLocal为案例进行比较分析,分析结果显示,这四大外文发现系统同样缺少个性化和社群功能,需进一步全面提升更智能化、可视化的检索服务[25]。
4 建议
4.1 加强元数据规范建设
在大数据时代,多渠道的文献数据难免缺乏一致性、规范性,数据种类繁多、数据结构混杂,对大数据的预处理技术(清洗、集成、转换及数据规约)都提出了新的挑战,发现系统如何结合使用新技术使庞杂的数据更有序可查仍然是首要任务。在对五家发现系统的测评过程中深刻体会到,有些商家过于追求大而全,而忽略了元数据的规范与厚度,使得宽泛的资源得不到深层聚类,原本简单的发现变得复杂,反而给用户带来了信息冗杂的困扰。在Primo资源发现系统中有一个用户反馈机制,该机制允许用户在检索过程中对元数据进行纠错与反馈,是对元数据维护工作的一个补充,值得推广与借鉴。
4.2 利用大数据技术,提升文献信息的揭示度与获取途径
测评的五家发现系统多是以数据库全文链接的形式来补充全文内容。需要注意的是,全文获取途径的链接一定要醒目、维护要及时、确保能够有效打开,在测试时出现过全文链接打不开、失效的情况。同时,图书馆还应积极开拓其他全文获取渠道,如在书目信息栏目下嵌入读者荐购模块,增加文献获取的途径;或积极开展联盟合作,嵌入类似RapidILL、Borrow Direct的馆际互借文献传递系统。图书馆应积极促进各方信息服务机构在资源、技术、服务上进行智能合作,将文献传递的“内容供应链”打造好,为用户提供更完整便捷的“发现—获取”全程服务[26]。
4.3 利用算法工具优化相关性排序
检索结果的相关性排序是非常复杂的内容,算法很多且不好平衡。同时,相关性排序的算法是发现系统的核心竞争力,大多不对外公布,因此,资源发现系统一直在结果排序上无法取得阶段性的进步。在测评的五家发现系统中,百度学术在检索结果上是按照文献引文量进行排序并呈现文献的引文脉络,同时推介一些热点文章。Primo系统是通过数据的引用和使用情况及用户的个性需求情况来提升文献的相关性排序,并申请了名为“ScholarRank”的技术专利。EDS系统的相关性排序是对主题、篇名、刊名、关键词等索引数据赋予不同的权重,并以全文和摘要内容为基础进行更深层的排序优化,以此来提高检索结果的相关性。Summon系统主要是依靠对元数据或全文词频的权重学习的方式计算相关性排序,该方法受不同资源类型的元数据分布影响,因此该系统比较偏向于优先发现报纸类资源[27-29]。如何智能地识别出用户的检索初衷,需要计算机的深度学习。有向搜索的用户在检索过程中明确知道自己要查找的文献内容,即目标清晰明确;而无向搜索的用户在检索过程中是查找某一主题或学科的文献,并无清晰的题录信息,对无向搜索的用户来说,资源发现系统的结果排序就起到至关重要的作用[17]。因此,资源发现系统怎样从用户角度出发,提升排序算法的合理性、科学性,是值得思考的问题。研究者丁梦晓、汪滢提出基于用户日志分析和用户兴趣进行相关性排序算法,即根据用户的日志检索数据与学术交流数据,分析出用户的学科、兴趣、信息需求等信息,再根据该“数据”进行信息推介与排序[30-31]。
4.4 提升个性化服务水平
在测评的五家发现系统中,超星发现可以将文献分享到QQ、新浪微博、微信,百度学术除了分享到QQ、新浪微博、微信外,还可以链接到印象笔记与有道云笔记。像BiblioCore一样,打造一个馆员推荐与评论功能模块的几乎没有,像Blacklight与VuFind那样,允许用户给书目添加Tag,建立用户自己的分类体系更是少见。这样的个性化功能有利于提升发现系统的服务功能,增强发现系统的作用与效益。BiblioCommons联合创始人Beth Jefferson曾说:“随着图书零售渠道的逐渐减少,为读者推荐有用而他们可能不知道的图书变得越来越重要。图书馆员可以在书目中根据他们的专业知识做一些推荐,这样能够帮助读者注意到更多他们可能感兴趣但自己又可能发现不了的图书”[32]。发现系统应注重用户的参与,利用大数据技术打造用户对文献分类及评论的社区模块,实现用户间的交流与分享,建立一个集文献资源、用户群体、专业馆员共同范在的数字场域。
4.5 利用衍生数据推动精准服务
目前,中外文发现系统的聚合功能更多的是在同一载体、同一著者、同一概念间的聚合,在数据编织和知识发现上还远远不够。百度学术是通过引文共引共现以及高被引文章向用户进行推送,而超星则是通过可视化图谱聚合文献。外文发现系统的文献聚合功能对元数据过分依赖,使得分面检索的聚合功能也大同小异,主要有学科、作者、主题词等。发现系统应挖掘利用在检索过程中的衍生数据,诸如用户身份数据、检索行为数据、文献的聚合与传播数据,文献被点评与使用的数据,通过分析这些数据来带动服务,从而形成“用户产生数据、数据推动服务”的良性迭代。
4.6 加强顶层规划,建立协同合作机制
资源发现系统具有很强的颠覆性,它通过创新资源组织方式,提升异构海量资源的揭示效果,通过整合服务模块提升用户服务,这种集成开放的思维给出版商、内容商、图书馆带来开放协作的机会,在这样的机遇与趋势下,图书馆应该加强顶层规划,建立协同合作机制,促进馆内和馆外资源的整合流通。从数字出版数据到有足够厚度的元数据,再到全文获取数据,一系列的环节都需要图书馆跨界链接,与出版商、数据商、发行商、及可提供内容的第三方进行广泛的合作,创新跨机构资源的全文服务方式,发挥跨机构服务协作的效益。同时,还需要树立系统即服务的理念,在系统中嵌入各项服务功能,形成基于资源发现系统的综合服务体系,这样用户才更愿意使用该系统,依赖该系统,从而提升图书馆在大数据环境下的服务能力与竞争能力。
[1] Bowen J. Metadata to Support Next-Generation Library Resource Discovery: Lessons from the eXtensible Catalog, Phase 1[J]. Information Technology and Libraries, 2008(27):6-19. https://doi.org/ 10.6017/ital.v27i2.3253
[2] 曾建勋.资源发现系统的颠覆性[J/OL].数字图书馆论坛,2016(2):1.
[3] 刘洋.我国高校图书馆资源发现系统现状调查——以“985工程”院校为例[J].河北科技图苑,2016,29(4):86-90+96. DOI:10.13897/j. cnki.hbkjty.2016.0113.
[4] Chickering F W, Yang S Q. Evaluation and Comparison of Discovery Tools: An Update[J]. Information Technology and Libraries, 2014, 33(2): 5-30. https://doi.org/10.6017/ital.v33i2.3471.
[5] Yang S Q, Wagner K. Evaluating and comparing discovery tools: how close are we towards next generation catalog[J]. Library Hi Tech, 2010,28(4): 90-709. https://doi.org/10.1108/07378831011096312.
[6] Marshall. The Future of Library Resource Discovery.2015t NISO White Papers[R/OL]. [2022-09-20].http://tefkos.comminfo.rutgers.edu/Courses/e553/Articles/Articles%20Sp15/NISO%20report%20future_library_resource_discovery%202015.pdf.
[7] 申晓娟,李丹,王秀香.略论图书馆资源整合与检索系统的发展——以国家图书馆“文津”搜索系统为例[J].图书情报工作,2013, 57(18):39-43+60.
[8] 成颖.基于相关性判据的学术信息检索系统成功模型建构[J].现代图书情报技术,2011(9):46-53.
[9] 赵钊,孙伟新,赵珊珊.基于D&M模型的信息系统成功评价研究[C]//国际信息系统协会中国分会.国际信息系统协会中国分会,2015.
[10] Hala Najwan Sabeh , Mohd Heikal Husin, Daisy Mui Hung Kee, et sl. A Systematic Review of the DeLone and McLean Model of Information Systems Success in an E-Learning Context (2010–2020) [J/OL]. IEEE Access, 2021: 81210-81235.DOI:10.1109/ACCESS. 2021.3084815.
[11] Petter S, DeLone W, McLean E. Measuring information systems success: models, dimensions, measures, and interrelationships[J]. European Journal of Information Systems,2008,17:236-263. https://doi. org/10.1057/ejis.2008.15.
[12] Lundrigan C, Manuel K, Yan M.“Pretty Rad”: Explorations in User Satisfaction with a Discovery Layer at Ryerson University[J]. College & Research Libraries, 2015, 76(1):43-62. https://doi.org/ 10.5860/ crl.76.1.43.
[13] Stubley P, Kidd T. Questionnaire surveys to discover academic staff and library staff perceptions of a National Union catalogue[J]. Journal of Documentation, 2002,58(6):611-648. https://doi.org/10.1108/ 00220410210448183.
[14] Kronenfeld M. Library resource discovery[J]. Journal of the Medical Library Association, 2015,103(4):210-213. https://doi.org/10.3163/ 1536-5050.103.4.011.
[15] Clough P, Goodale P. Selecting Success Criteria: Experiences with an Academic Library Catalogue. Information Access Evaluation. Conference and Labs of the Evaluation Forum,2013. https://doi.org/ 10.1007/978-3-642-40802-1_7.
[16] 邓小昭.网络用户信息行为研究[M].北京:科学出版社,2010:148-177.
[17] Boram L, EunKyung Chung. An Analysis of Web-scale Discovery Services From the Perspective of User's Relevance Judgment[J]. The Journal of Academic Librarianship,2016, 42(5):529-534. https://doi. org/10.1016/j.acalib.2016.06.016.
[18] 杨薇,曾丽军.从“快传”(RapidILL)和“立借”(Borrow Direct)看馆际互借与文献传递服务体系的发展[J].大学图书馆学报,2018,36(4):18-23+44. https://doi.org/10.16603/j.issn1002-1027.2018.04.003.
[19] Delaney T G, Richins M. RapidILL: an enhanced, low cost and low impact solution to interlending[J]. Interlending & Document Supply, 2012, 40(1):12-18. https://doi.org/10.1108/02641611211214233.
[20] 黄静.变革中的文献传递服务:案例剖析与路向管窥[J].图书情报工作,2013,57(7):55-59.
[21] 武丽娜,左阳,窦天芳.基于发现系统的大学出版社开放学术资源现状调研及分析[J].知识管理论坛,2018,3(1):12-18. DOI:10.13266/ j.issn.2095-5472.2018.002.
[22] 覃燕梅.百度学术搜索与超星发现系统比较分析及评价[J].现代情报,2016,36(3):48-52+60.
[23] 王新才,谢宇君.知识发现系统与通用学术搜索引擎文献资源比较研究——以超星发现和百度学术为例[J].福建论坛(人文社会科学版),2018(4):164-172.
[24] 宋姗姗.发现系统在高校图书馆的应用研究——以超星发现为例[J].产业与科技论坛,2020,19(12):69-71.
[25] 袁玉英.常用几种资源发现系统对比分析研究[J].图书馆工作与研究,2015(9):38-41. DOI:10.16384/j.cnki.lwas.2015.09.009.
[26] 曾建勋.基于发现系统的资源调度知识库研究[J].图书情报知识,2019(6):12-18. DOI:10.13366/j.dik.2019.06.012.
[27] 王连喜.知识发现系统的相关性排序与主题聚类功能问题探析[J].图书馆工作与研究,2015(12):56- 60.https://doi.org/10.16384/j.cnki.lwas.2015.12.013.
[28] 相关性排序:为研究人员提供最需要的信息[EB/OL].[2022-11-08]. https://www.exlibris.com.cn/products/summon-library-discovery/relevance-ranking/.
[29] 相关性排序:提供最相关的检索结果[EB/OL].[2022-11-08]. https://www.exlibris.com.cn/products/primo-discovery-service/relevance-ranking/.
[30] 丁梦晓,毕强,许鹏程,等.基于用户兴趣度量的知识发现服务精准推荐[J].图书情报工作,2019,63(3):21-29. DOI:10.13266/j.issn. 0252- 3116.2019.03.003.
[31] 汪滢.基于用户日志分析的搜索引擎相关排序算法优化[J].电脑知识与技术,2020,16(18):99-101.https://doi.org/10.14004/j.cnki.ckt.2020.1878.
[32] Brandi Scardilli. Biblio Commons catalog-centric library operations[J]. Information Today, 2014, 31(7): 23.
Evaluation and Suggestion on Typical Literature Resource Discovery Systems in Big Data Environment
LI XueYuan1, ZHANG Jie2 *
1. China Agricultural University Library, Beijing 100193, China; 2. Agricultural Information Institute, Chinese Academy of Agricultural Sciences, Beijing 100081, China
Five commonly used discovery systems, Primo, Summon, EDS, Baidu Scholar and Chaoxing Discovery, are taken as samples to sort out and summarize the functional characteristics of the discovery system, develop and test the evaluation index system of the literature resource discovery system and conduct specific evaluation. The study investigates and analyzes the influencing factors of users' access to information in the use of the discovery system, the system usability, and user loyalty. Moreover, combined with the development and influence of big data, the study proposed six development suggestions: strengthen the normative construction of metadata, improve the disclosure and access of literature information, optimize the relevance ranking, improve personalized services, promote accurate services using derivative data, strengthen top-level planning and establish a mechanism for coordination and cooperation.
resource discovery system; knowledge discovery system; Primo; Summon; EDS; Baidu Scholar; Chaoxing Discovery
李雪原,张杰. 大数据环境下典型文献资源发现系统评测与建议[J]. 农业大数据学报, 2023, 5(3): 83-92.
LI XueYuan1, ZHANG Jie. Evaluation and Suggestion on Typical Literature Resource Discovery Systems in Big Data Environment[J]. Journal of Agricultural Big Data, 2023, 5(3): 83-92.
2023-06-01;
2023-09-04
国家新闻出版署农业融合出版知识挖掘与知识服务重点实验室开放基金项目“资源发现系统比较分析与评价”(项目编号:2021KMKS04)
李雪原,E-mail:lixueyuan @sina.com;通信作者张洁,E-mail:zhangjie07@caas.cn。
