云环境下Web服务的自动化分类方法
2023-11-16李玉聪
李玉聪
吉林大学第一医院,吉林长春,130022
0 引言
云计算主要分为IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务),Web服务是SaaS的主要部署模式。自云计算推出以来,如何提高云中资源的利用率就是云计算研究的热点之一。国内外的诸多学者都对该问题进行了研究,MultiJava语言中,开放类是一种可以动态添加属性和方法的类,而且可以在运行时进行修改[1]。继承应该被看作是一种增量修改机制,而不是一种面向对象设计的基本原则[2]。邓晓衡[3]在iVCE的可信模式与体系的基础上给出了可信优化资源调度算子,在信任度效果、最早结束时刻、请求无效率、资源效率等几个方面较好地综合优化了网络系统的特性;田冠华[4]给出了一种根据资源需求量和故障规则确定动态进行的节点资源可靠性的策略,经过剖析DAG图活动的并行与同时进行特点,运用从后向前方式将活动逆向分级;苑迎春[5]将工作流结束期转换为层截止时间,为减少平均耗费而给出了截止期约束的逆向分级费用优化算子;异构分布式系统的一个负载均衡的容错调度算法[6]给定了一个主/从版本的具备控制能力的过程调度算法:HDALF与HDLDF,并经过实验得到,当系统发生故障前后的负载均衡性权值相同时,在负载均衡和处理机资金效率层面,HDLDF技术都要高于HDALF技术;根据网格信赖模式与信赖效果参数,对于业务网格资源管理中存在的信赖机制与调节机制相互分离的问题,张伟哲[7]共同探讨了利用信任QoS扩展的计算服务调节技术,并研究了常规调节技术的不足,最后得到了一个信任关系的服务网格业务调节技术。在集群中运用分布式算法处理大量的Web日志文件,可以明显提高Web数据挖掘的效率[8]。
不同云服务对于资源可靠性的需求不同,计算密集型服务对于计算资源的要求较高,交互密集型服务对于网络带宽和内存资源要求较高,在同一台物理机上分配互补型服务可以有效地提高资源的利用率。但在当前的云环境下,云中心无法自动化地判断服务对于各种资源的需求。为弥补这一不足,本文提出了一种云环境下Web服务的自动化分类方法,利用Web服务的WSDL自动化判断服务的需求。实验表明,本文的方法是有效的,可以自动化地预测服务的资源需求。
1 WSDL介绍
作为云服务的一个关键部署模型,WSDL文件能够更准确地描述有关Web服务的文档,能够把Web服务定义为用户的站点或客户端之间的集成。一个WSDL文档通常包含Types、PortType、Import、Message、Operation、Binding、Service 7种重要元素。Definitions是WSDL文档的根元素,把这些内容都嵌套进去,这些内容的作用如下。
(1)Types:以数据类型定义的系统容器,通常采用XML或Schema中的数据类型。
(2)Message:通信消息的数据结构形式的抽象类型化概念。利用Types中所规定的信息类别来确定一个信号的数据结构。
(3)Operation:对服务中所提供的功能的抽象说明,通常指每个Operation提供了一组使用入口的邀请/应答消息比对。
(4)PortType:指定了与协议/信息形式所绑定的具体Web浏览网址组成的抽象集合,由某个业务访问入口点所支持。
(5)Binding:根据所规定连接类别的具体协定和数据格式标准协商的绑定。
(6)Import:关于对某个访问的点类型所提供的功能的抽象集合,通常这种集合由一个或众多的访问点类型所提供。
(7)Service:若干服务访问点的集合。
除了以上7个重要元素,一个完整的WSDL文档通常还包含Input、Output元素,用来描述服务的输入和输出操作,这两个元素通常被包含在Operation元素中。通过以上这些元素,WSDL文档能完整地对Web服务进行刻画。
2 Web服务的资源需求分析
由于Web服务所需的资源和服务的过程和类型密切相关,即与使用什么操作有关,因而可以忽略标签之间的嵌套关系,只考察服务所需的各种操作和操作的次数。在此基础上,我们可以将一个WSDL文档抽象成一个形如(Nimp,Nty, Nme, Np, Nbd, Nse, Nop, Nipt, Nopt)的元组。其中Nimp、Nty、Nme、Npt、Nbd、Nse、Nop、Nipt、Nopt分别表示文档中Import、Types、Message、PortType、Binding、Service、Operation、Input、Output标签数量。
通过分析大量的WSDL文档,我们发现,通常情况下服务的Import、Types、PoetType、Binding、Service标签数量都是固定的,为0、1、3、6、1,可见它们对判别服务资源需求的影响不大,因而可以将服务进一步抽象为一个4元组(Nme, Nop, Nipt, Nopt),元组中的元素分别表示Message、Operation、Input、Output标签的数量。
根据服务对于资源的需求可以简单地将服务划分成4种类型,分别是计算密集型服务、下载类服务、交互密集型服务和其他类型服务。一般来说,计算密集型服务对CPU资源要求较高,下载类服务对网络带宽要求较高,而交互密集型服务则对带宽和内存均有较高要求,还有部分服务的资源需求类型不属于这三种中的任何一种,划出作为单独一类。
本文用一个三元组(RCPU, RMem, RNet)表示云服务S的资源需求,并且总和为单位1,即其中RCPU表示S对于固定CPU的占用时间比例,RMem表示S对于内存的需求比例,RNet表示S对于带宽资源的需求比例,他们都是抽象度量。通过对大量服务的总结,我们发现计算密集型服务的资源需求大约为(0.60,0.20,0.20),下载类服务的资源需求约为(0.20,0.20,0.60),交互密集型服务的资源需求约为(0.15,0.35,0.50),其他类型服务的资源需求约为(0.33,0.33,0.34)。本文假设上述的资源需求为不同类型服务的标准资源需求。
3 资源需求的自动化预测
本文采用BP神经网络算法对服务的资源需求进行预测,该方法的具体流程如图1所示。
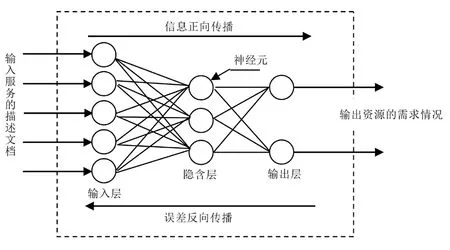
图1 方法的具体流程图
(1)输入模型,服务于从入口层经隐含层向出口层的“模式正向传递”流程。
(2)网络实际的传输信息和所需要传递的错误信息,在输出层与隐含层向信号层逐级调节的权和阈值之间的“错误正反向传递”流程。
(3)将“模式正向传播”过程与“误差反向传播”过程之间的重复交互完成的网络学习训练方法。
(4)网络在全局误差趋向极小的最后一个收敛阶段。
(5)神经网络训练完成后即可根据服务的描述文档,对任意服务进行分类。
(6)该算法进行试验的训练集源于一个互联网网站,该网站提供了大量的web服务实例,包括天气预报服务、实时股票行情数据服务、中英双向翻译服务等。
4 方法实现
本文方法的总体流程如图2所示,首先利用训练好的神经网络获得资源需求向量,之后利用向量余弦相似度计算该向量与四种资源需求标准向量的相似程度,根据计算结果确定任务的类型。
(1)预处理是为使用神经网络算法做准备。从web服务的WSDL文件中提取数据,抽取出可以用于该功能的主要元素,再根据给定的内容描述元组的形式,把文档抽象为可以用于后续实验应用的主要元组。
(2)神经网络分为训练和使用两部分。进行神经网络的训练操作时,将已知资源需求的web服务的资源需求元组和对应的描述元组作为训练集,对神经网络进行多次训练,以达到使用标准。进行神经网络的使用操作时,即将待分类服务的描述元组作为输入,即可获得对应资源需求的预期值。
(3)通过实验获取各类资源占有型服务的典型服务实例作为特性实例,并测出特征实例的资源需求元组。定义一种分类方法(GF)如下:求神经网络算法求得的待分类服务的资源需求元组与特征实例元组向量夹角的余弦值,定义得出的结果为类型评分,由于余弦值越大则证明两个向量越接近,因此,比较这几种类型评分的大小,待分类服务的类型即为得出的类型评分值最大的那一种类型。
(4)最终上述方法将测得服务对应的类型,实现任意web服务的自动化分类。
5 结语
为了对本文提出的方法进行验证,首先对Web服务网站上的3组Web服务的实际资源需求进行了监测,基于监测结果对服务进行了分类,并将分类结果作为标准结果;之后利用本文的方法对这组服务资源需求和分类结果进行预测,利用预测结果和标准结果的对比来对本文方法的有效性进行分析。实验结果显示,本文提出的自动化服务分类算法的分类效果较好,分类的准确度较高。当服务的WSDL描述相似时,个别服务有可能会出现类型判断偏差问题,比如:当其他类型中CPU资源占用预期失误时,会导致其他类型的服务被误判断成交互类型服务;而当计算类型服务的CPU占用资源预期出现偏小的情况时,总体的资源需求预期将会变得与其他类型服务接近。这是由于其他类型与这三种类型服务的划分分界线标准量过少,几种类型的资源需求量是按照占总单位1的比例来表示,而导致当某一种资源需求预期出现偏差时,引起其余资源需求预期值变化,服务的类型判断也会出现相应的失误。
