基于生成对抗和图卷积网络的含缺失值交通流预测模型
2023-11-15陈建忠吕泽凯蔺皓萌
陈建忠,吕泽凯,蔺皓萌
(西北工业大学 自动化学院,陕西 西安 710129)
0 引言
在科学技术日新月异的今天,人工智能的快速崛起和广泛应用为缓解交通拥堵提供了有效的方法[1]。交通流预测需要大量的历史交通数据,在实际数据收集过程中,由于交通基础设施、气象状况和数据采集技术的限制与人为失误等原因造成的数据缺失问题对交通流预测的准确性产生严重的负面影响[2]。因此,本研究基于深度学习方法建立交通流缺失数据补全方法和交通流预测模型,提高交通流缺失数据补全的准确性和交通流预测的精度。
常见的处理缺失数据的方法分为不做任何处理、删除缺失数据和填补缺失数据。填补缺失数据是应用最为广泛且效果最好的处理方法。随着人工智能的快速发展,神经网络、深度学习等方法逐步应用于交通流缺失数据的补全中,目前已经取得了一定的研究成果。Tian等[3]提出了一种基于长短时记忆网络的方法用于时间序列数据补全;Duan等[4]提出了一种基于去噪堆叠自动编码器的交通数据补全模型,讨论了时空因素对交通数据插补的影响,给出了分层训练的方法并建立模型,该方法可以有效获取大规模路网数据中包含的时空相关性信息;Tan等[5]将张量插补方法应用于高速公路多检测器缺失数据的插补中。
随着交通流数据采集技术的快速发展,依据交通流数据的特点,从数据驱动角度进行交通流预测,从20世纪70年代末开始就一直是该领域的基本研究方向。基于数据驱动的交通流预测方法大致分为以下4类,分别是统计模型、机器学习模型、深度学习模型和组合模型。
统计模型考虑了交通流的周期性,提取历史数据对未来交通流进行预测。经典的时间序列方法有历史平均模型和自回归积分滑动平均模型等。机器学习模型如支持向量机、贝叶斯网络和随机森林等在交通流预测中展现出了强大的能力。Dell’Acqua等[6]给出了最近邻回归方法,这是一种对于交通流预测有效且易于实现的数据驱动方法;祁伟等[7]引入季节性ARiMA模型并利用时序周期特征计算交通观测值的缺失,对稀疏交通流进行预测;吴晋武等[8]提出了一种改进的非参数回归交通流预测算法,融合主成分分析、模糊C均值聚类与支持向量机方法,对短时交通流进行预测。
深度学习是机器学习的细分领域。相对于机器学习模型,深度学习模型除了可以学习简单特征以外,还能从简单特征中提取更加复杂的特征,可以更有效地进行特征提取进而处理更为复杂的问题,提高模型准确性。Lü等[9]应用深层架构模型,使用自动编码器捕获交通流特征进行预测;为了预测交通流,Huang等[10]提出了一个由2部分组成的深层结构,即底层的深层信念网络(Deep Belief Network,DBN)和顶层的多任务学习回归层,DBN能以无监督的方式学习交通流的有效特征;Ma等[11]提出一种长短时记忆网络,有效地获取交通流非线性特征。为提高模型提取特征的能力,部分研究者提出了将多种模型组合用于交通流预测;Zhao等[12]和Yu等[13]提出了时空图卷积网络,设计了一种包含图卷积网络与门控循环单元的时空卷积模块,对流量、速度进行预测;唐智慧等[14]将神经网络模型与无迹卡尔曼组合构成预测模型,对短时交通流进行预测;杨春霞等[15]基于双向长短时记忆网络方法,构建了学习交通流上下关联性的模型;陈孟等[16]综合时空图卷积网络以及卡尔曼滤波对未来的交通流流量进行预测。
交通流预测的关键在于依据大量历史交通数据,针对交通流非线性、非平稳的特点,设计合适的模型,以达到尽可能低的预测误差。目前基于深度学习的交通流缺失数据补全方法研究较少,运用深度学习方法学习大规模路网交通流数据分布,可以更加有效地提取特征,与现有补全方法相比,提高了数据补全的准确性。本研究针对含缺失值的城市道路网络交通流,设计了基于生成对抗网络的交通生成对抗插补网络。现有交通流预测方法多数依赖完整交通流数据集实现预测,当数据集中有较多缺失值时使用这些方法的交通流预测精度会显著降低。为提高含缺失值的路网交通流预测的准确性,在文献[12]的基础上,设计了基于交通生成对抗插补网络、经验模态分解、图卷积网络和门控循环单元的交通流预测模型,显著降低了数据缺失和数据噪声对交通流预测的负面影响,捕获路网交通流的时空相关性进而提升城市道路网络交通流预测的精度。
1 数据集选用与缺失设计
城市道路交通系统是由人、车、路整合而成的巨大复杂系统,交通流参数的变化受到诸多因素的影响,体现在城市道路网络交通流的随机性、周期性、时间相关性和空间相关性等。为研究城市道路网络的交通流预测,本研究选用深圳市罗湖区出租车平均车速数据集[12],该数据集包括2015年1月1日至31日深圳市罗湖区156条主要道路的实测车速数据。试验数据主要包括2部分:一是156×156邻接矩阵,描述了道路之间的空间拓扑,每行表示一条道路,矩阵中的值表示道路之间的连通性,道路间有连通为1,不连通为0;二是特征矩阵,描述了每一条道路上的速度随时间的变化,每一行代表一个时间点不同路段的交通速度,每一列是同一道路不同时间段上的交通速度,速度选取的是每15 min该路段所有统计车辆的平均速度。
在本研究试验中模拟真实交通流数据缺失情形,设计2种缺失模式,分别为:(1)随机缺失:每个传感器完全随机丢失观测值;(2)非随机缺失:每个传感器在数天内失去观测值。这2种缺失情形在数据集上作数据处理,将被视为缺失值的数据点的值变为0,用于模拟实际缺失情形。考虑实际情形中数据缺失的比率不尽相同,设计含有不同缺失率的缺失数据用于补全方法验证,缺失率设置为10%,20%,30%,40%,50%,60%这6种情形。
2 补全方法与预测模型
2.1 交通流数据补全方法设计
生成对抗网络可以在不依赖完整数据集的情况下很好地进行数据的填补,其在图像增强领域大放异彩[17]。在研究补全问题时通常将图像作为矩阵进行操作,因交通流数据同样可以矩阵化,对于交通流数据的补全问题,生成对抗网络同样适用[18]。本研究将生成对抗网络引入交通流数据补全中,利用生成对抗网络的思想结合矩阵化的交通流数据结构,设计了用于交通流数据补全的交通生成对抗插补网络(Traffic Generative Adversarial Imputation Network,TGAIN)。为方便推导,做如下规定:
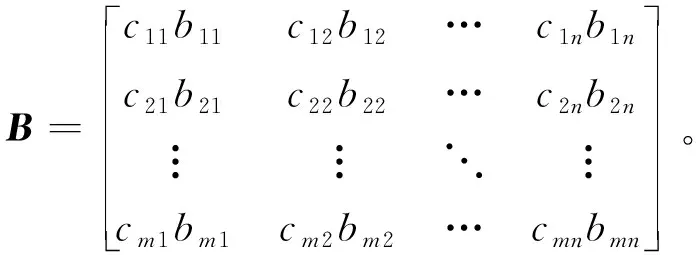
X为原始交通流数据构成的数据矩阵;M为X的掩模矩阵,维度与X相同;mi为M中第i个元素的值,当X中第i个元素为观测数据时,mi为1,当X中第i个元素为缺失数据时,mi为0。TGAIN的目标是填充数据矩阵X中的缺失值。引入矩阵乘积运算法则Hadamard积[19],其符号为○。如果矩阵C∈m×n,矩阵Β∈m×n,则2个矩阵的Hadamard积定义为:
(1)
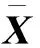
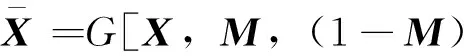
(2)
式中1为维度与M相同、元素均为1的矩阵。补全结果为:
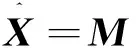
(3)
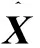
(4)
(5)
因为生成器G的实际输出包含所有数据的矩阵,所以在G的训练过程中,不仅要使数据缺失点插补的值成功“骗过”判别器,还要保证观测数据尽可能不变,为此定义下列2个损失函数:
(6)
(7)
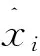
(8)
式中α为超参数。图1描述了交通生成对抗插补网络的结构和补全数据的产生过程。
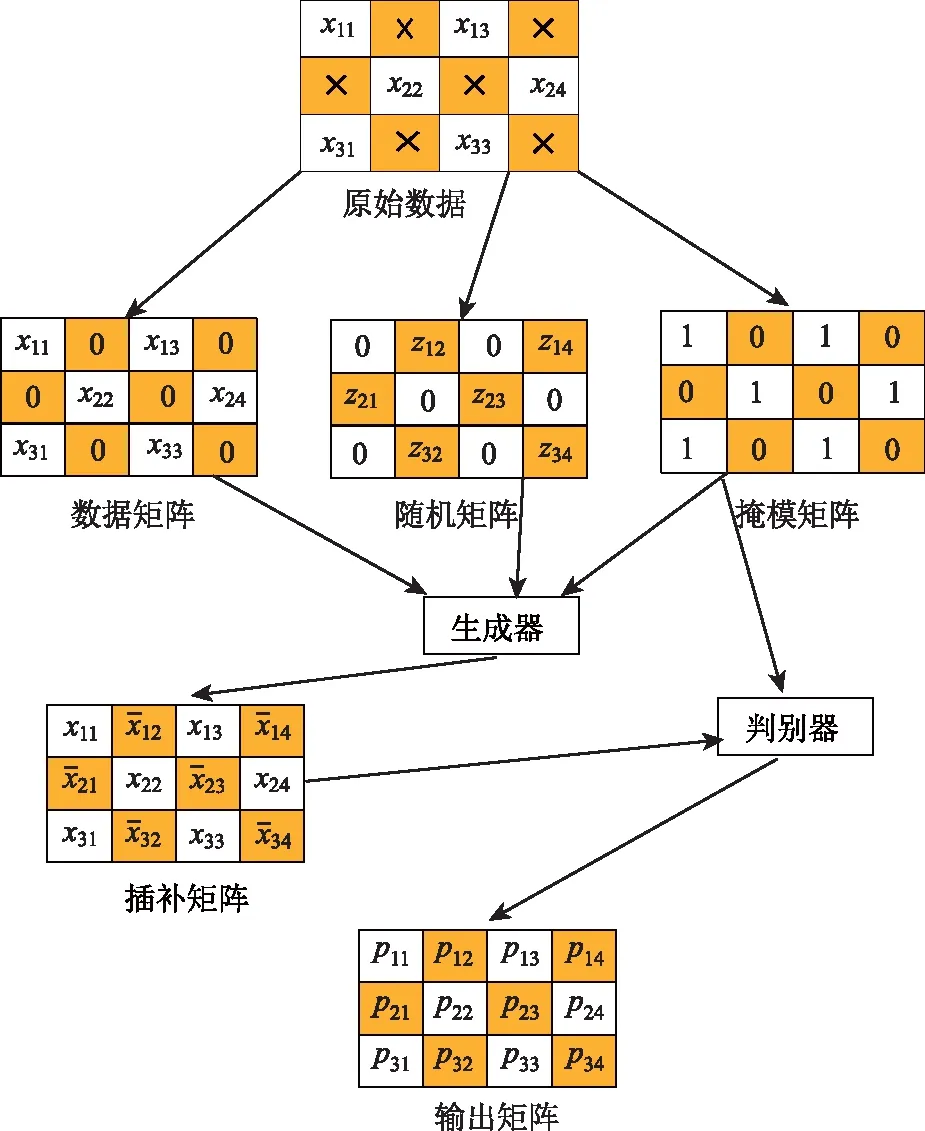
图1 交通生成对抗插补网络结构Fig.1 Traffic generative adversarial imputation network structure
2.2 时空预测模型
2.2.1 经验模态分解
交通流数据属于非线性非平稳时间序列,具有一定的非平稳性、周期性和随机性。由于车、路和人等多种外部因素的耦合影响,原始交通数据往往还包含一些噪声,有时表现出较大的波动,进而导致了预测性能的下降。为降低噪声对预测模型性能的影响,将经验模态分解(Empirical Mode Decomposition,EMD)用于交通流数据处理,将复杂的交通流时间序列转化为多个具有较强规律性的分量,再将各分量分别进行重构作为后续预测模型的输入,最后合并各分量预测结果。
EMD方法是由Huang等[20]提出的一种针对非线性、非平稳数据的分解方法。与小波分解和傅里叶分解等基于先验的分解方法不同,EMD是一种完全由数据驱动的分解方法,突破了傅里叶变换的局限性,克服了小波分解需要主观选择小波基的缺陷。作为一种自适应的分析方法,EMD具有良好的时频分辨率,能够将有噪声、非平稳的交通流时间序列分解为单一、平稳的分量。在噪声抑制方面,EMD可以将噪声和有效信号分离为不同的本征模式函数(Intrinsic Mode Function,IMF)和残差,IMF分量反映了原始交通流时间序列的不同时间尺度的震荡特性,残差反映了原始数据的长期趋势。每个IMF的特征应符合2个条件:
(1)完整的时间序列中,序列的所有极大值点的个数和极小值点的个数之和与序列过零点的数目必须相等或最多相差一个。
(2)在时间序列的任何时刻,局部最大值的上包络线和局部最小值的下包络线均值为零。分解后的IMF与原始交通数据序列相比具有更强的规律性,去除了一定噪声影响。EMD可以处理分析非线性、非平稳数据,这对于探索交通流预测模型的隐藏时间序列关系起了至关重要的作用,该方法有助于揭示复杂非线性时间序列的特征。
定义交通流时间序列x(t)≈(x1,x2,…,xT),T为时间序列的长度,xt为当前路段t时刻观测到的交通流参数。IMF分量和残差由以下步骤确定:
(1)判定交通流时间序列x(t)的所有局部极大值和极小值点;
(2)应用三次样条插值分别拟合所有局部极大、极小点形成x(t)的上包络线u(t)和下包络线v(t);
(3)计算上下包络线的均值m(t);
(4)计算原始交通流时间序列x(t)与包络线平均值m(t)的差h(t):
(5)判断h(t)是否满足IMF的条件,若h(t)满足条件,则h(t)为原交通流时间序列的本征模函数分量,定义C(t)=h(t),令r(t)=x(t)-h(t),x(t)=r(t);若不满足,则令x(t)=h(t);
(6)重复步骤(1)-(5)直到r(t)变为单调函数或IMF分量数目达到最大数量条件,EMD分解终止。
通过步骤(1)~(6),x(t)被分解为n个IMF分量和1个残差项,EMD对交通流时间序列的分解结果可以表示为:
(9)
式中Ci(t)为第i个IMF分量。
本研究中设置IMF分量的最大数目为6,交通流时间序列经过EMD多次筛选处理后,可以得到一系列从高频到低频排列的IMF分量和残余项。其中高频IMF分量的随机性较强,通常会代表交通流中的噪声干扰和交通流自身的一些随机特性。低频IMF规律性较强,代表交通流自身具有的时间规律特性。残余项则是一个趋势项,各IMF分量和该趋势叠加可以得到原始的交通流时间序列。对各分量及残余项分别进行预测,将预测结果叠加得到交通流预测结果。
2.2.2 图卷积网络
在深度学习获取数据空间特征方面,一直由卷积神经网络(Convolutional Neural Network,CNN)统治,其在计算机视觉领域也取得了十分优异的效果。但是,CNN处理的数据都是欧式结构的数据,对于交通路网拓扑这种非欧式结构的数据,拓扑图中每个顶点的相邻顶点数目都可能不同,因传统的离散卷积在非欧式结构数据上无法保持平移不变性,故而无法用同样尺寸的卷积核来进行卷积运算。为了在非欧式结构(拓扑图)上有效提取空间特征来进行深度学习,近年来,图卷积网络(Graph Convolutional Network,GCN)[21]成为了人工智能领域研究的热点。本研究使用GCN对交通路网拓扑结构进行学习捕获交通流空间相关性。GCN的作用和CNN一样,是一个特征提取器,只是GCN的对象是图数据。假设在交通路网拓扑图中,有n个节点,每个节点都有T维的交通流时间序列,设这些节点的特征组成矩阵X∈n×T,各个节点之间的拓扑关系形成邻接矩阵A∈n×n,将X和A作为图卷积模型的输入。GCN为多层神经网络,层与层之间的传播方式为:
(10)
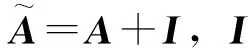
(11)

2.2.3 门控循环单元
循环神经网络(Recurrent Neural Network,RNN)是用于处理序列数据的一种神经网络。RNN在许多深度学习任务中表现出卓越的性能,如机器翻译、语音识别和推荐系统等。交通流数据作为时间序列数据,RNN在交通流数据预测上同样表现亮眼。RNN因为可以将先前的信息用于当前的任务,所以非常适合处理交通流时间序列,捕获交通流数据的时间相关性。但是,RNN训练时极易产生梯度消失或梯度爆炸的问题,因此产生了门控循环单元(Gated Recurrent Unit,GRU)[22]等循环神经网络的变种。本研究采用GRU捕获交通流数据的时间相关性,其结构如图2所示。

图2 门控循环单元结构Fig.2 Gated recurrent unit structure
在两层GCN基础上叠加一层GRU以捕获时间特性[12]。图2中,ht-1为t-1时刻的隐藏状态;Xt为t时刻的交通信息;rt为重置门,用于控制先前时刻状态信息的度量;ut为上传门,用于控制上传到下一状态的信息度量;ct为t时刻储存的信息;ht为t时刻的输出隐藏状态。GRU通过获取t-1时刻的隐藏状态与当时的交通状态信息得到t时刻的交通信息。各变量定义如下:
ut=σ{Wuf[(A,Xt),ht-1]+bu},
(12)
rt=σ{Wrf[(A,Xt),ht-1]+br},
(13)
ct=tanh{Wcf[(A,Xt),rt×ht-1]+bc},
(14)
ht=ut×ht-1+(1-ut)×ct。
(15)
综上所述,本研究建立的EMD-GCN-GRU模型可以处理复杂的带有噪声和时空特性的路网交通流数据,将交通流数据经EMD处理后得到6个IMF分量和一个残差分量,将同级分量重构为后续模型输入,再使用GCN学习路网的空间拓扑,捕获道路之间的空间相关性,使用GRU捕获交通流的时间相关性,最后将各个分量的预测结果叠加,得到最终预测结果,实现交通流预测任务。模型的损失函数设计为:
(16)
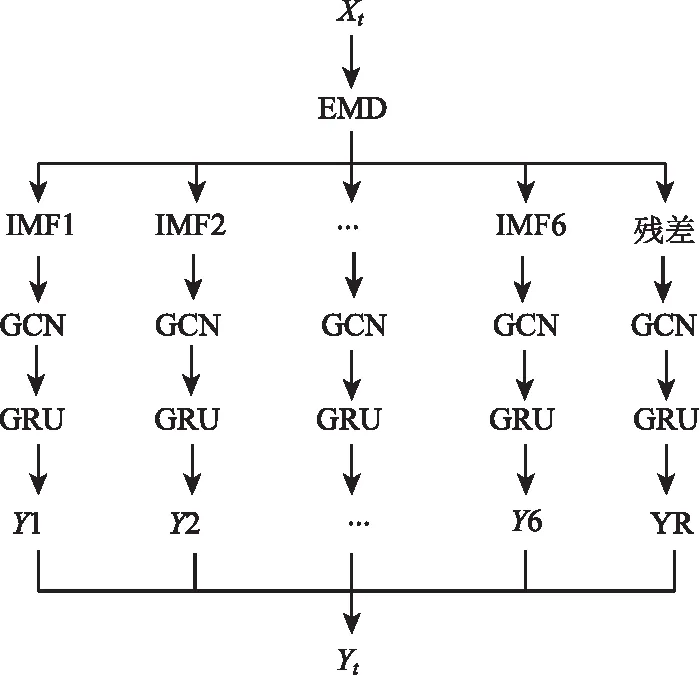
图3 EMD-GCN-GRU模型结构Fig.3 EMD-GCN-GRU model structure
2.3 模型精度评价指标
本研究主要从预测精度、准确性等方面衡量模型的性能,从数值上对比不同预测模型的优劣,选取了5个性能指标进行衡量,分别为:
(1)平均绝对误差(Mean Absolute Error,MAE)。
(2)均方根误差(Root-mean Square Error,RMSE)。
(3)准确度(Accuracy):衡量预测数据准确性,即
(17)
(4)数据的拟合程度,即:
(18)
(5)解释方差得分,即:
(19)
3 试验结果与分析
3.1 补全模型
选取深圳市罗湖区464 256条平均车速数据为研究对象,设置2种缺失模式和6种缺失比率,使用TGAIN与矩阵分解(Matrix Factorization,MF)模型[23-25]进行补全验证。随机缺失补全精度对比如表1所示,可以观察到TGAIN的MAE和RMSE均明显低于MF模型,其中在缺失率为30%时,TGAIN补全精度优势最为显著,相对于MF模型,TGAIN的MAE降低了约40.64%,RMSE降低了约30.04%,补全准确性更高。
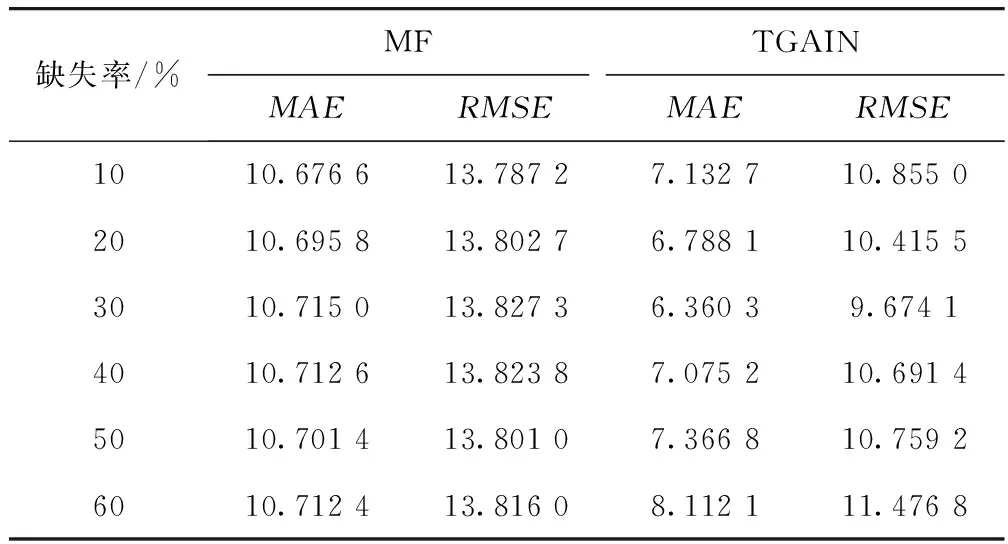
表1 随机缺失补全精度Tab.1 Random missing completion accuracy
非随机缺失补全精度对比如表2所示,可以观察到,在缺失率为10%,20%和30%时TGAIN的MAE和RMSE均明显低于MF模型,补全准确率更高。在缺失率为40%时TGAIN的MAE和RMSE均低于MF模型,但相差不大。在缺失率为50%和60%时TGAIN的MAE和RMSE均高于MF模型,补全性能变差。TGAIN模型受非随机缺失率影响较大,在非随机缺失数据增多至总数据量一半以上的情形下,无法准确地学习真实数据的分布,导致补全误差增加。
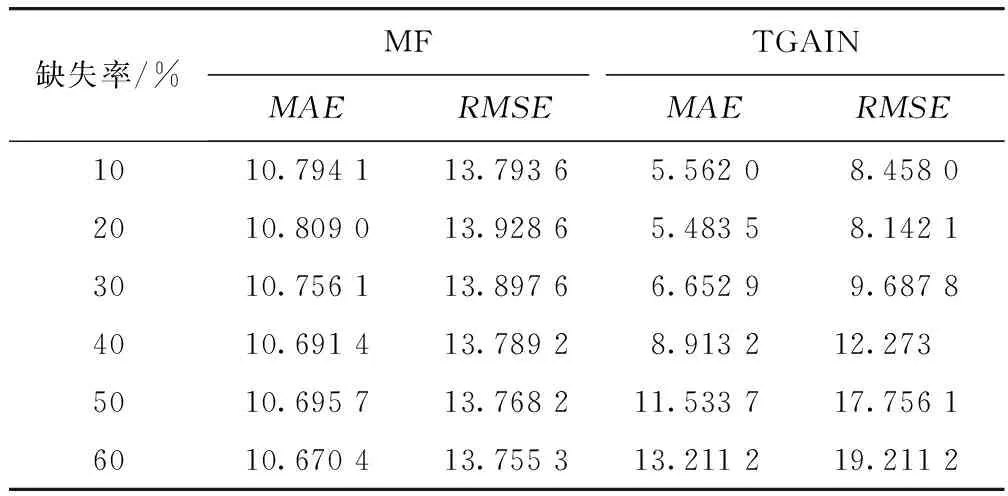
表2 非随机缺失补全精度Tab.2 Nonrandom missing completion accuracy
3.2 时空预测模型
通常在训练次数足够的情况下,隐藏单元数目Num对模型预测精度影响最大,故首先对EMD-GCN-GRU方法选用不同隐藏单元数目进行预测精度对比,选出最优隐藏单元数目。各含有不同隐藏单元数目的模型预测精度如表3所示,第1行表示隐藏单元的数量,第1列表示不同精度评价指标。可以看出在隐藏单元数目为100时模型的拟合程度最高,所以选用隐藏单元数目为100进行后续研究。随着隐藏单元数目增加,模型预测精度先提高后降低,这是因为当隐藏单元数目过度增加时模型过拟合。
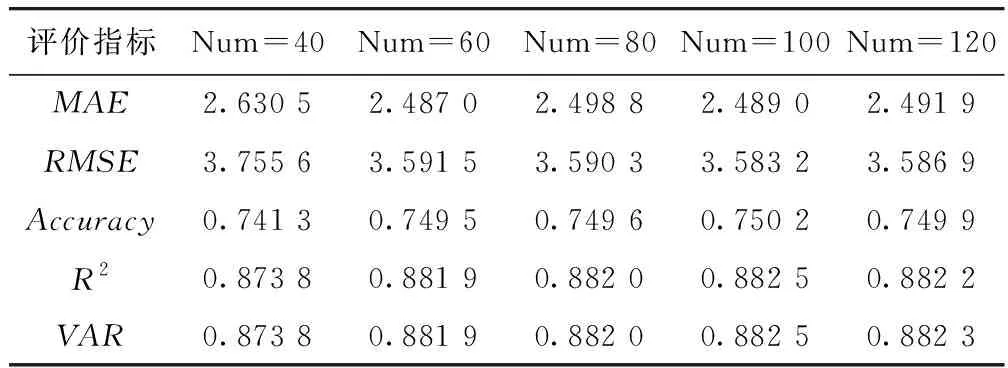
表3 不同隐藏单元数目模型预测精度比较Tab.3 Comparison of prediction accuracy of models with different number of hidden units
选用数据集前80%作为训练集,其余20%作为测试集。选用过去1 d的速度数据(96个时间步)预测下一时间段即15 min的平均速度,使用Adam优化器优化预测模型(见表4)。
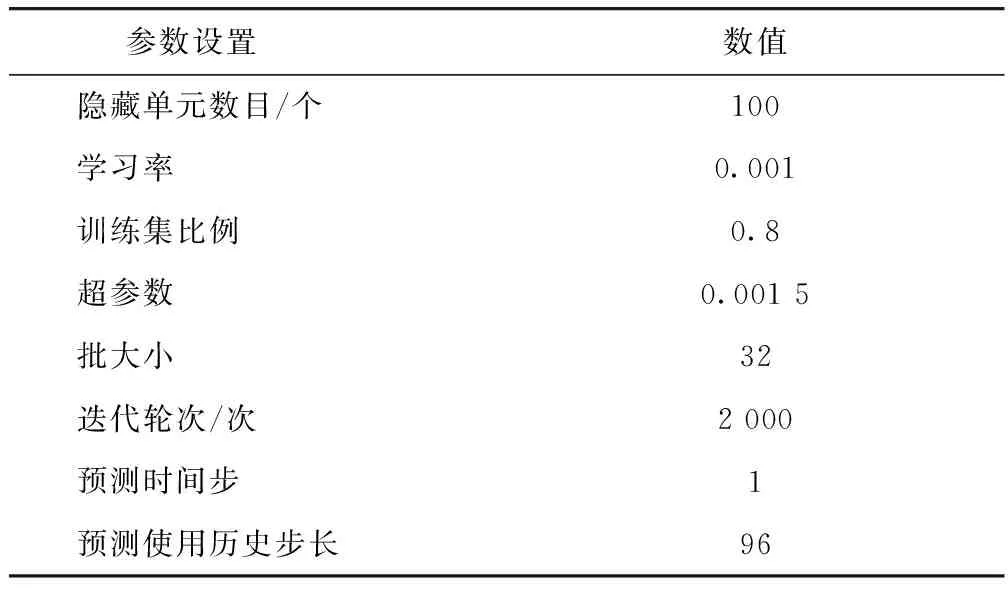
表4 预测模型参数Tab.4 Prediction model parameters
为便于作图表示,预测算法的验证均以第一条道路为例给出结果。经EMD处理后,原始道路车速数据作为EMD的输入信号被分解为6个IMF分量和一个残差分量,其分别描述了不同时间尺度的车速变化特征,如图4所示。
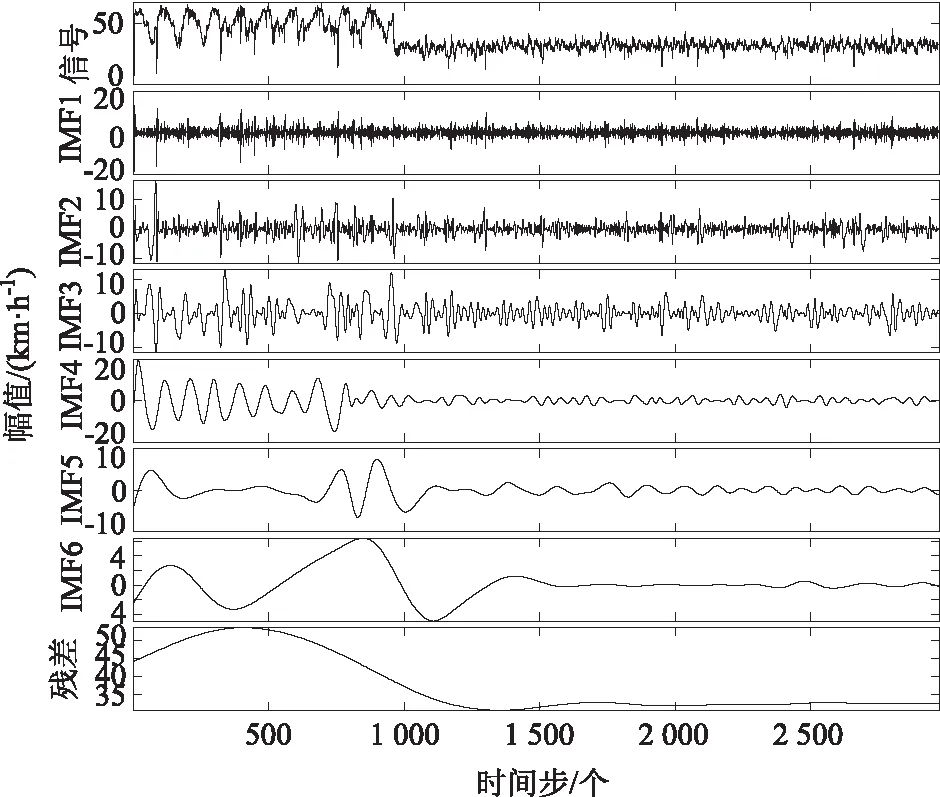
图4 经验模态分解结果Fig.4 Empirical mode decomposition result
IMF1分量预测结果如图5所示,可以看出模型对IMF1分量的预测效果较好。交通流时间序列经EMD处理后,得到了一系列规律性较强的分量,将同级分量重构为模型输入分别进行后续预测模型的训练,由于时间演化趋势不再互相耦合,各分量均具有更好的可预测性。
模型的预测结果如图6所示,在预测全程,模型的预测值变化趋势贴合真实交通速度分布,基本接近车速真值,说明模型的有效性。由图7前96步的预测结果可知,模型在第20步左右未能准确预测到速度变化极值,对其他时刻的速度变化趋势、极值均能较为准确地进行预测,总体预测效果良好。在少量极值点预测性能较差,主要原因是在使用GCN时定义了傅里叶域中的平滑滤波器,通过不断移动过滤器捕捉空间特征。这个过程导致总体预测结果的波动较小,使峰值更为平滑[12]。
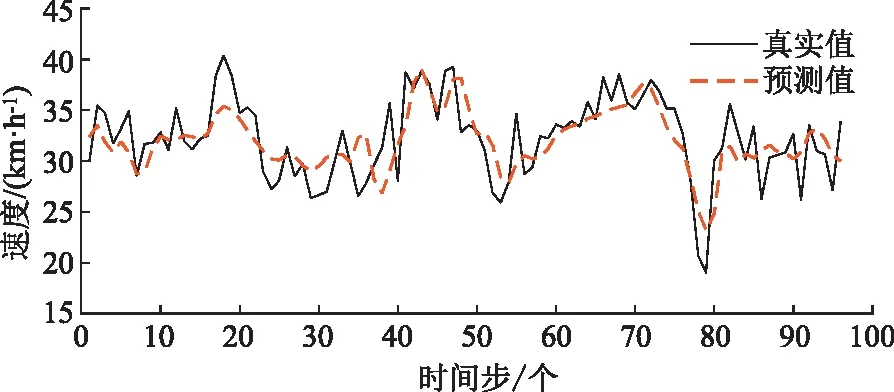
图7 前96步预测结果Fig.7 Prediction result of the first 96 steps
选取如下模型与本研究EMD-GCN-GRU模型进行预测精度对比:
(1)历史平均模型(HA):使用历史交通流数据的平均值作为预测值;
(2)支持向量回归(SVR):利用历史数据对模型进行训练,得到输入和输出之间的关系,然后通过训练后的模型预测未来的交通流。在该模型中使用的核函数是线性核;
(3)自回归积分滑动平均模型(ARIMA):将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列并进行预测;
(4)循环神经网络(RNN):用于处理序列数据的神经网络;
(5)长短时记忆网络(LSTM):一种时间递归神经网络[22];
(6)门控循环单元(GRU);
(7)GCN-GRU组合预测模型:将图卷积网络与门控循环单元结合组成的预测模型[12]。
统计每个模型预测结果的MAE和RMSE(见表5),可以看出与其他7种预测算法相比,EMD-GCN-GRU的MAE和RMSE均为最小,优于其他模型,相较于MAE较低的SVR,LSTM和GRU,MAE分别下降7.34%,1.02%和1.47%,相较于RMSE较低的LSTM,GRU和GCN-GRU,RMSE分别下降10.43%,10.72%和8.94%,说明EMD-GCN-GRU模型具有更好的交通流预测准确性。
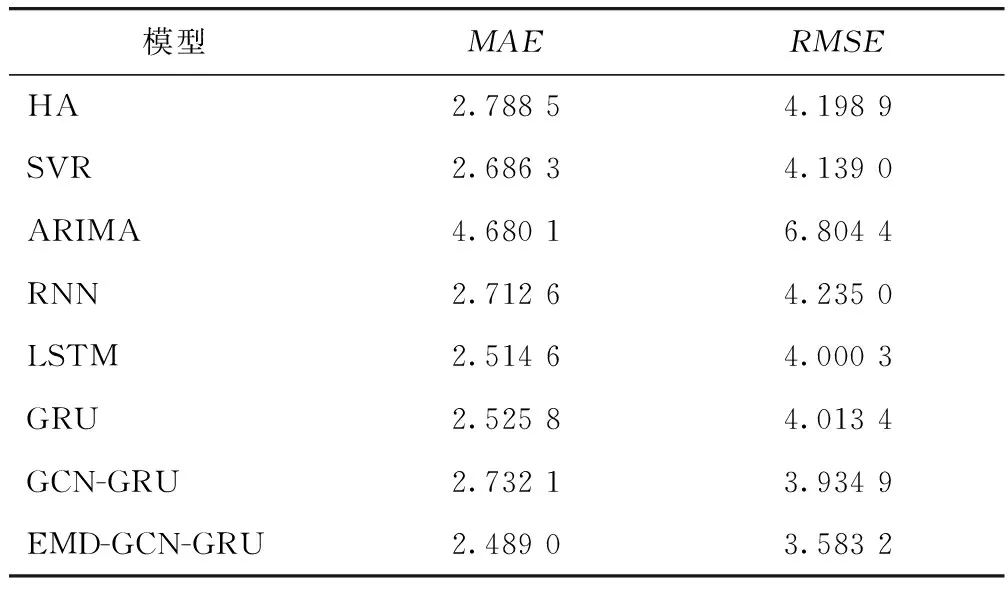
表5 各模型预测精度Tab.5 Prediction accuracy of each model
为研究使用不同历史时长数据进行预测对预测模型性能的影响,设置预测所用历史数据时长分别为1,2,3,24 h,统计各模型的预测精度指标如表6所示。可以看出预测模型的MAE和RMSE在24 h时最低,说明预测模型在此数据集上使用历史1 d的数据进行交通流预测更加科学准确。
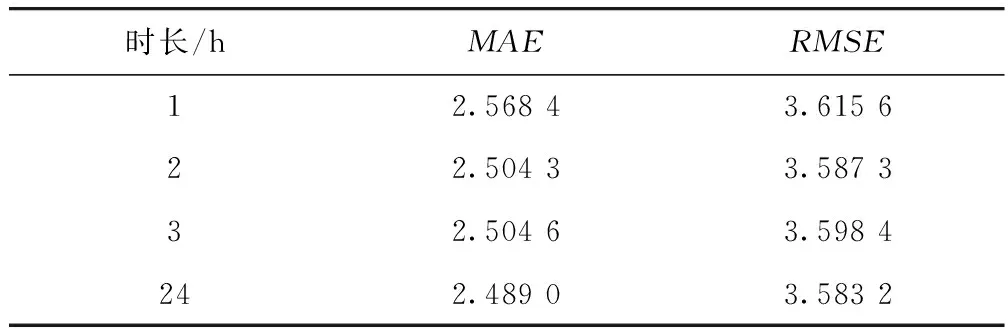
表6 使用不同历史时长数据的预测精度Tab.6 Prediction accuracy with different historical duration data
3.3 组合预测模型
组合预测模型是对含缺失交通流数据集中的缺失值使用TGAIN进行填充后,再使用EMG-GCN-GRU模型进行城市道路网络交通流预测。在试验中,选择20,40,60,80,100这5种隐藏单元数目构建预测模型进行精度对比,各评价指标如表7所示。可以看出在隐藏单元数目为60时的预测模型精度最好,所以选用隐藏单元数目为60进行后续研究。

表7 不同隐藏单元数目的组合模型预测精度Tab.7 Prediction accuracy of combination model with different number of hidden units
选用数据集前80%作为训练集,余20%作为测试集。选用过去1 d的速度数据(96个时间段)预测下一时间段的平均速度,使用Adam优化器优化预测模型。模型的主要参数:隐藏单元数目为60,批大小为128,其余参数同表4。表8给出在缺失率为20%时,针对2种缺失模式,分别使用缺失数据和经TGAIN补全后的数据进行预测的预测结果,可以看出在2种缺失模式下,使用补全数据进行预测的模型精度显著优于使用原始缺失数据的预测精度,使用补全数据进行预测能够更好地捕获车速的变化规律,说明了组合预测模型的优越性,同时也再次证明了TGAIN补全方法的有效性。
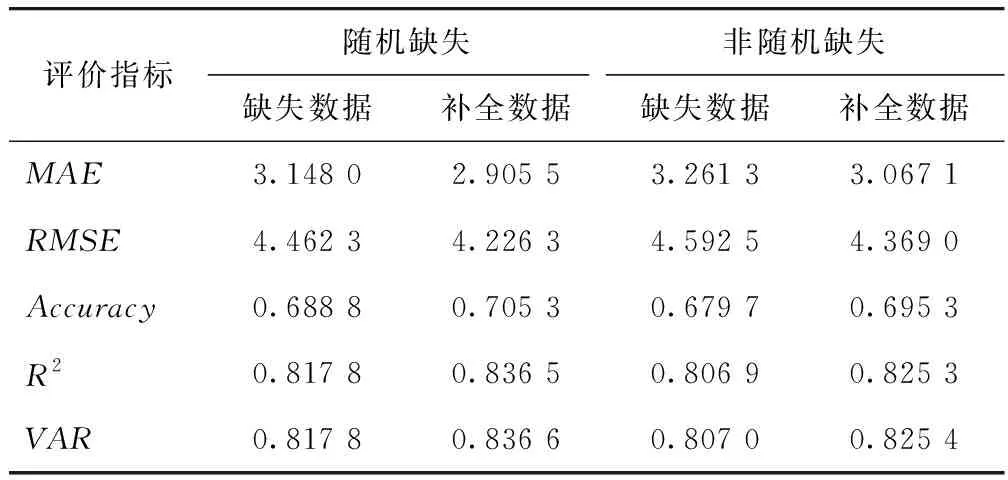
表8 使用缺失数据和补全数据的预测精度Tab.8 Prediction accuracy with missing data and complete data
为研究使用不同历史时长数据对组合预测模型性能的影响,设置预测所用历史数据时长分别为1,2,3,和24 h,各模型的预测精度统计见表9,可以看出组合模型的MAE和RMSE在24 h时最低,说明组合模型在此数据集上使用历史1 d的数据进行交通流预测更加科学准确。
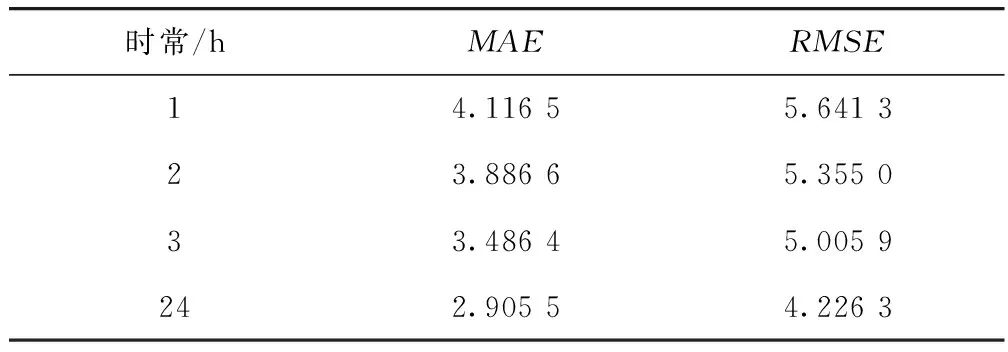
表9 使用不同历史时长数据的预测精度Tab.9 Prediction accuracy with different historical duration data
4 结论
本研究基于生成对抗网络,提出用于城市道路网络交通流数据补全的交通生成对抗插补网络TGAIN。采用深圳市罗湖区出租车平均车速数据集对TGAIN与具有较高补全准确性的矩阵分解模型进行了对比。结果表明TGAIN模型在数据集随机缺失模式下补全准确性较高,补全性能受随机缺失率影响较小,在数据集非随机缺失模式下补全准确性受缺失率影响较大,在非随机缺失率低于50%时补全性能较好。
针对具有已知空间联系的路网交通流数据,在可获取路网空间邻接拓扑的基础上,建立对交通流数据进行分解重构并捕获时空相关性的EMD-GCN-GRU预测模型。结果表明,相比其他7种预测算法,EMD-GCN-GRU预测模型具有较高的预测准确性。对含缺失值的城市道路网络交通流预测问题设计组合预测模型,将TGAIN与EMD-GCN-GRU模型相结合进行预测,仿真结果表明使用组合模型预测精度显著提高。
