融合双谱特征的雷达辐射源个体识别方法
2023-11-14段可欣闫文君王艺卉李春雷
段可欣,闫文君,刘 凯,王艺卉,3,李春雷
(1.海军航空大学,山东 烟台 264001;2.91422部队,山东 莱阳 265200;3.31401部队,山东 烟台 264001;4.92038部队,山东 青岛 266109)
0 引言
随着现代军事装备技术的发展,大量新体制辐射源的出现使战场电磁环境变得日益复杂。新型技术体制的雷达不断装备战场,电子对抗环境日趋复杂与密集。信号参数不断变化对雷达辐射源信号分选识别提出了更高的要求。辐射源个体识别(Specific Emitter Identification,SEI)对于雷达对抗信息处理和雷达对抗侦察系统都具有重要意义,其不仅能使雷达对抗、侦察、干扰等效能得到充分发挥,更重要的是,它还能由辐射源的性能、工作状态等辐射源个体信息,分析得到关于辐射源载体的属性、工作状态和威胁等级等初始判断信息。
在雷达辐射源识别领域,基于传统特征的个体识别方法对于目前复杂的电磁环境适用性较差,尤其当待识别信号数量少、提取累积特征困难时,识别能力有限。因此,不断有专家学者提出新的特征提取方法。高阶谱分析在分析信号特征时具有独特的优势,与时间无关的特殊性使高阶谱分析能够提取信号的非高斯性特征和非线性特征。除此之外,还具有相位保持性和尺度不变性等优良特性。信号双谱分析[1-2]作为高阶谱应用中最广泛的1 种方法,在信号处理中备受关注。
孟祥豪等提出用双谱的对角线积分作为特征,对复合调制LPI 雷达信号进行识别的方法,降低了计算量,但对信噪比有一定要求[3];张彦龙等融合了双谱理论、奇异值分解和信息熵理论对不同调制类型的雷达辐射源信号用模糊C均值算法进行聚类分析,但为降低计算量,仅对第一象限区域进行取样分析,整体特征获取不够全面[4];王世强等提出利用Bhattacharyya距离结合SVM对信号双谱进行分析处理的分类识别办法,对双谱特征加以优化,算法结果较稳定,但是该方法提取辐射源个体信息不够充足[5];曹儒等先向量化信号双谱的幅度,再利用层次极限学习机以图像处理的办法学习4 类有意调制类型的特征,进而达到识别目的[6];为降低双谱计算量,陈培博等提出取第一象限的双谱幅度特征和相位特征,再使用对抗网络对所提取的特征进行识别[7-8];丁力达等采用卷积神经网络对二维压缩后的双谱特征进行学习,但图像特征维数过高,聚集性不够强[9]。综上所述,在辐射源个体识别中,对所提取的双谱特征挖掘不够全面充分,导致辐射源识别效果受限。
本文通过对辐射源信号的双谱进行分析,根据香农信息熵的概念定义双谱奇异值全局熵和双谱对角线的幅度分散熵。首先,将双谱矩阵进行奇异值分解,依据奇异值的分布规律提取双谱的奇异值全局熵;然后,以双谱对角线的幅值分散程度定义幅值分散熵;最后,联合双谱对角线及对角积分一起组成特征向量。该方法的特色之处在于在信号分析中融入了熵理论,它可以充分挖掘接收到的辐射源信号双谱特征在分布上的特征,丰富了辐射源识别指纹特征,提高识别率。
1 算法模型
1.1 双谱特征提取
双谱分析可对信号幅度和相位的保持性显现出信号的非线性特性。双谱的概念如下所述[10]。
假定高阶累积量ckx(τ1,τ2,…,τk-1)是绝对可和的,即:
则k 阶谱定义为k 阶累积量的k-1 阶散Fourier变换,即:
那么,双谱即三阶谱可定义为:
可以求出接收机接收到的离散含相噪信号为:
式(4)中:w( n )是高斯噪声信号;s( n )是发射机输出的含有非高斯噪声的信号,且w( n )和s( n )相互独立。对x( n )求三阶累积量,则有:
式(5)中,E()· 表示求期望。将式(5)展开,然后合并得到:
所以,只要信号和噪声的均值为0,就有:
若w(n)是高斯有色噪声,则c3ω(τ1,τ2)可以忽略不计。可见信号的双谱可以消除高斯有色噪声对信号的影响,其双谱由c3s(τ1,τ2)确定,即:
由上述分析可知,双谱分析可滤除高斯噪声的影响,从而最大化保留辐射源信号个体特征。本文仿真了来自3幅射源信号的双谱,如图1所示。
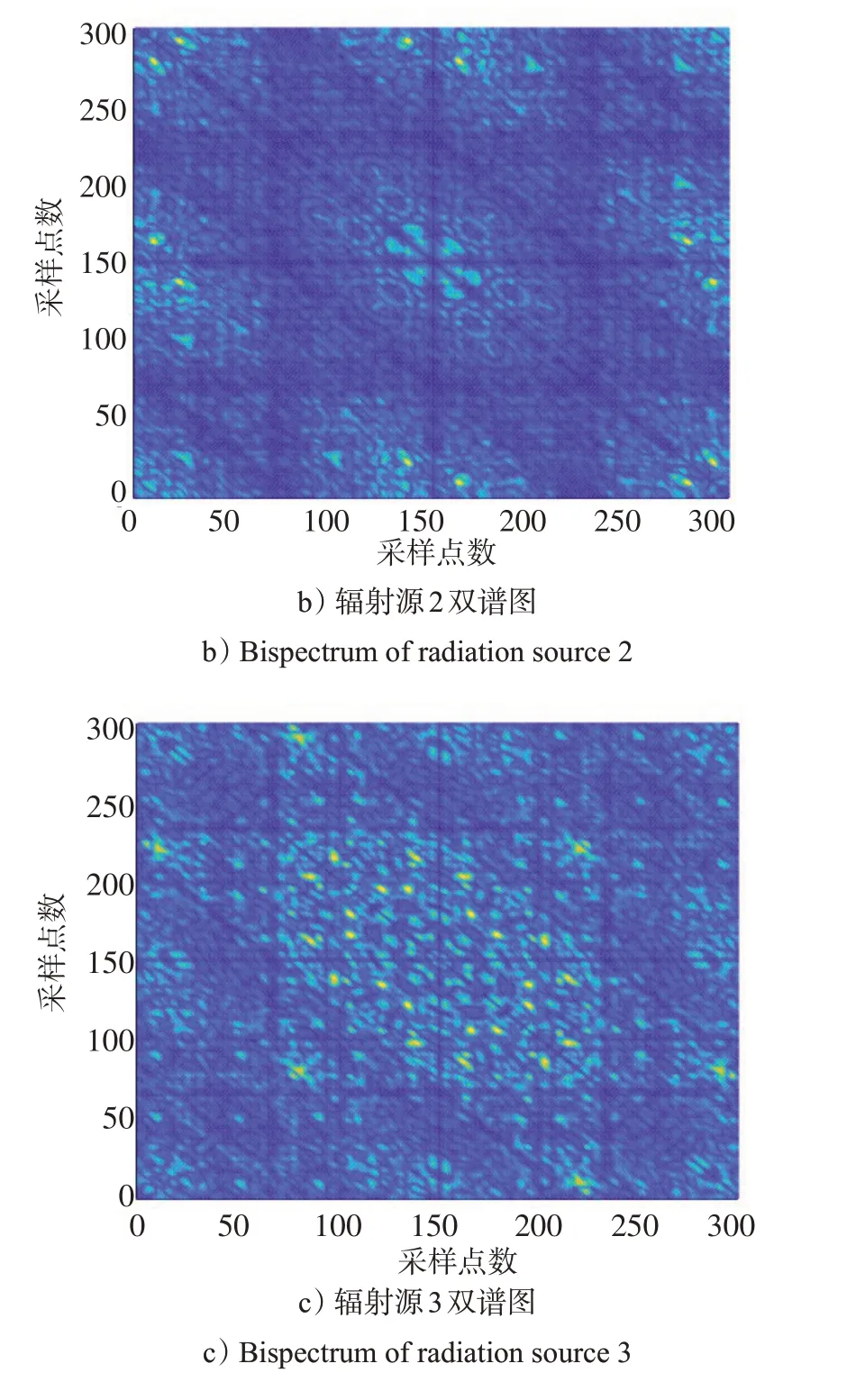
图1 不同辐射源双谱图Fig.1 Bispectrum of different radiation sources
由图1 可以看出,不同辐射源信号双谱的幅值和分布存在不同。
1.2 对角积分双谱
辐射源个体识别的实时性对辐射源个体特征计算量有一定的要求。如果将信号的双谱全部纳入个体识别中,计算量较大。因此,引入降维的方法,通过对双谱进行积分,可以将二维双谱转变成一维特征函数,但积分双谱仍有以下缺点:
1)积分双谱是沿双谱某一路径上的积分,但双谱具有对称性,存在一些点位上的信息重复和冗余,这些双谱点对于提取雷达辐射源个体特征的贡献不大;
2)由于所接收的原始雷达辐射源信号中有可能存在交叉项,经过高阶谱多次相关函数计算和双谱积分后,交叉项将更加严重。
为了克服上述缺点,考虑双谱具有对称性和周期性的特点,选择合适的积分路径既能最大化保留双谱特征,也能有效避免交叉项恶化。在比较现有积分双谱特征的基础上,本文使用对角积分双谱[11]。选用双谱次对角线,避免插值的同时,包含了丰富的雷达辐射源信号幅度和相位信息,双谱对角线积分表达式如下:
对3 个辐射源双谱分别取对角切片,如图2 所示。可以看出,不同辐射源的双谱对角线在幅值和分布规律上有明显不同。
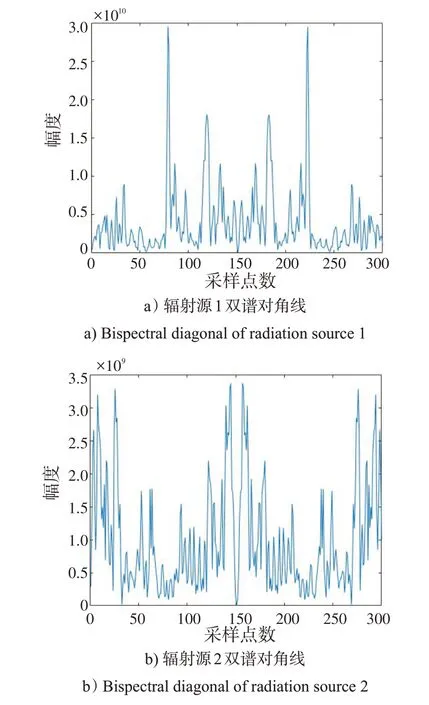
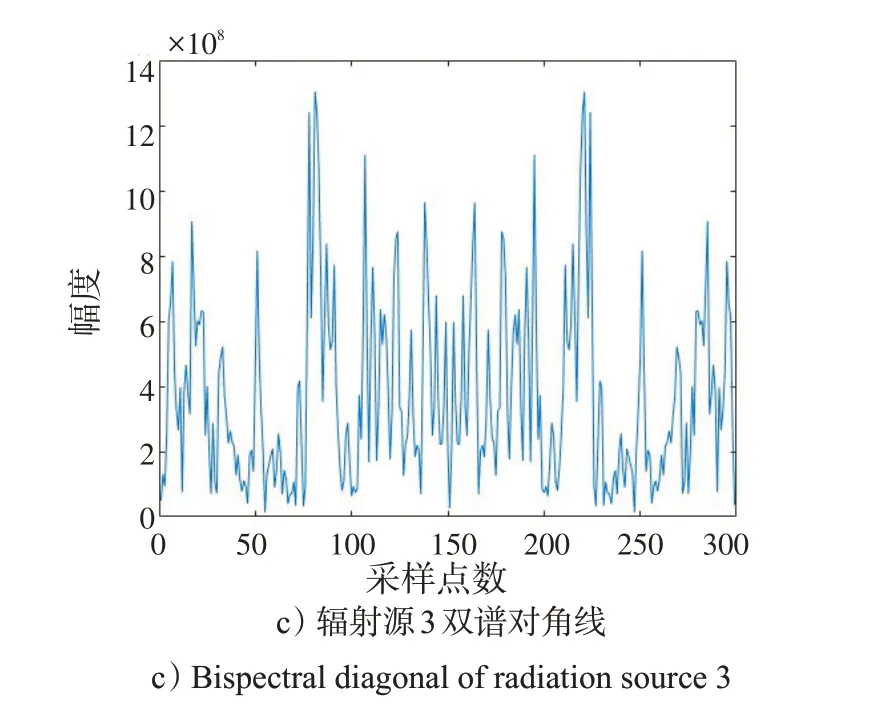
图2 不同辐射源双谱对角线切片Fig.2 Diagonal slices of bispectrum from different radiation sources
1.3 双谱奇异值全局熵
熵最初提出是为了表示热力学中热状态的不平衡程度。香农为描述信息量的大小,提出“信息熵”的概念。熵的值对照信息系统的有序程度:值越大,信息系统的信息量越小,信息系统越无序;反之,值越小,系统内信息量越大,信息系统越有序。信息熵定义为[12]:设Pi表示集合中事件i()i=1,2,…,n 出现的概率,则各事件概率矢量的集合为P=(P1,P2,…,Pn),且满足0 ≤Pi≤1 和=1 。 由此,信息熵H(P1,P2,…,Pn)的值为:
由于雷达信号是有用信号叠加了随机噪声,不同的雷达携带了一定程度的指纹特征,信号双谱的能量集中情况和分布复杂程度也因各信号时频分布存在不同而不同[13]。因此,为刻画雷达辐射源信号的双谱能量在全局的分布情况,引入双谱奇异值全局熵的概念,对双谱运用奇异值分解[14],提取双谱矩阵的全局主要信息得到奇异值向量()σ1,σ2,…,σk。奇异值可以理解为“主特征值”,且有从大到小的排列顺序。奇异值包含了矩阵的重要特征信息,且奇异值的大小还代表了该奇异值对原始矩阵的重要程度,有权重的含义在里面。1个矩阵可以表示成k 个秩为1,值为奇异值的小矩阵的“和”。k 的值决定了保留奇异值向量的个数,既能保留大部分特征,又能减少计算量。由此引入奇异值的全局熵[15]概念;每个奇异值在整个奇异值向量中占的比重为Qi=,则奇异值的全局熵Eσ为:
双谱奇异值全局熵包含被分析信号双谱矩阵的代数特性和分布特征。
1.4 双谱对角线的幅度分散熵
由图2 可看出,双谱对角线具有非常标准的对称性,但每个辐射源双谱对角线上的峰值和谷值的位置、大小各不相同。就本文而言,由于实验中使用的是同厂家、同型号的发射机,采用的是相同的调制方式,同一台接收机,在同样的实验条件下采集的数据,在对收集的数据进行双谱分析取得的对角线特征中的不同,就是要提取的辐射源指纹特征。
根据对角线幅值分布情况,先对整条对角线均分成n 段,对每段取幅值均值ai,双谱对角线可用1个幅值向量()a1,a2,…,an来表示,各幅值均值占幅值积分的比例记为Ai=,则双谱对角线的幅度分散熵为:
2 网络模型
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是深度学习[17-18]中1 个非常重要的神经网络结构[15],多用于图像,音、视频等信息的处理。由于具有强大的前向反馈功能,CNN能够自动学习并提取数据中的特征,进而利用所获取的特征信息进行识别。CNN 主要包括卷积层、池化层、全连接层。卷积层目的是提取输入数据的特征,并在迭代过程中提取越来越复杂的特征;池化层是对卷积层提取到的特征进行亚采样处理,以减少网络中参数个数,避免过拟合,提高神经网络识别的鲁棒性;全连接层是把CNN学到的特征映射到样本空间,完成最终的识别任务。
2.2 卷积神经网络结构
CNN利用卷积核作为“特征过滤器”,使用不同的卷积核以提取不同的特征。卷积层数和卷积核的个数决定提取特征的数量和复杂度,这也正是网络设计需要平衡的网络结构的宽度和深度。更进一步,在同一个CNN结构中,迭代次数和训练的批样本数量都会影响神经网络的识别率。这些参数都需要不断调整寻优实验获取,以期用最少的计算量得到最佳结果。本文中,设计的CNN模型使用2层网络层用于一维特征向量的数据分析,CNN模型如图3所示。

图3 CNN网络结构图Fig.3 Network structure diagram of CNN
卷积核大小设为3×1。卷积层1(Conv1)由32个长度为3 的一维卷积核构成,卷积运算后做最大池化;卷积层2(Conv2)由64 个长度为3 的一维卷积核作卷积运算,并做最大池化。全连接1(Dense1)有1 024 个结点,全连接2(Dense2,softmax 输出)有3 个结点,输出的3个节点代表3个不同的辐射源。
3 仿真实验
3.1 仿真条件
本文实验平台为Windows 10,双谱算法平台为MATLAB R2018b。深度学习模型架构为Tensor-Flow,其中环境为Python3.7。本文采用基于GNU Radio 和USRP 的SDR 平台模拟辐射源,用ADS-B 数据流盘软件和USRP的组合模拟信号收集器。实验过程中,搭建由装有GNU Radio 软件的计算机和3 台USRP-B210组成的SDR平台作为信号发射装置,由装有ADS-B 数据流盘软件的计算机和1 台USRP-B210 作为信号接收装置,信号采集过程如图4所示。

图4 辐射源信号采集系统实物图Fig.4 Physical diagram of radiation source signal acquisition system
在GNU Radio的GUI界面中,将发射信号的参数设置如下:信号的调制方式为16QAM,载波频率为1.09 GHz,带宽为2 MHz,发射增益为50,USRP 采样率为2 MHz,通道选择TX/RX 2 ∶0。在ADS-B数据流盘软件操作界面配置B210 设备信息,工作频率设为20 MHz,采样频率2 MHz,通道选择RX 2 ∶0,接收增益为60。在发射机流图与接收机装置均连接好之后,进行真实环境下的数据收集,实验场景如图4所示。
运行GNU Radio 的GRC 流图,ADS-B 数据流盘软件的DATA文件开始存储接收到的.usrp文件,即原始数据集。相同环境下,用同一接收机接收一段噪声信号,计算这段信号幅度的平均值M 和标准差S。由于这段信号仅包含噪声信号,令平均值M 作为噪声强度,即信号强度。假设信号和噪声的功率比为K ,方差为标准差的平方,即M=,根据信噪比定义可知,SNR=20 lg 10()2,计算得出该环境下信噪比估计值为22.87 dB(取到小数点后2位)。接下来的实验均在此信噪比条件下进行。
用同一套接收装置分别接收发射端使用3台不同USRP-B210发射的信号,保证3台USRP-B210设备调成一样的参数,接收来自3 台不同发射机的.usrp 数据。将收集到的.usrp数据先转换成.mat数据,然后对.mat 数据进行双谱分析,得到3 个辐射源的双谱对角线如图5所示。
有效运用“四种形态”。紧扣“六大纪律”等规定,坚持正确执纪导向,把握运用好“四种形态”。计提醒谈话56人,党纪轻处分3人,力求挺纪于前、防早防小、治病救人。
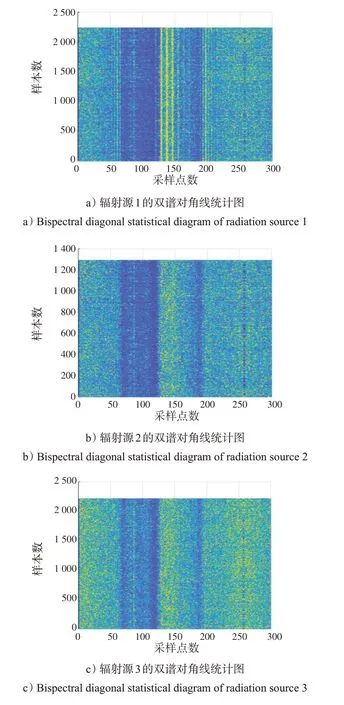
图5 不同辐射源的双谱对角线统计图Fig.5 Bispectral diagonal statistics of different radiation sources
在双谱分析的基础上,求信号双谱奇异值全局熵,对角线积分和对角线幅度分散熵。双谱对角线取值个数设为300,由此得到长度为303 的特征向量,3个辐射源分别收集2 235、1 291、2 212条样本,共得到5 738条长度为303的数据组成的数据集,训练集和测试集的划分比为3 ∶1,将它们送入神经网络进行训练和测试。
3.2 网络参数配置
为降低网络结构的复杂度,提高模型的泛化能力,本文使用由2个卷积层构成的CNN。采用3×1 的卷积核对辐射源信号进行特征采集,2 个卷积层中卷积核的数目依次为32、64。为保留信号有效特征,池化层采用3×1 的池化核。最后,使用全连接层进行特征组合及特征分类。为了避免模型产生过拟合,本文在CNN 的全连接层后加入dropout 正则项,在训练过程中随机使一些神经元失活,进而滤除部分噪声点。
由于不同参数对网络性能影响较大,本文在对网络进行训练时,采取可变参数策略对网络性能进行优化。所选取的参数主要有迭代次数(epoch),批样本数量(batchsize),衡量网络性能的指标选取为识别率和训练时的损失函数。
对于神经网络而言,在模型训练的过程中,1次训练所选取的样本数称为批样本数量,它的大小影响模型的优化程度和速度,适当批样本数量使得梯度下降方向更加准确。运行模型对全部数据完成1次前向传播和反向传播的完整过程叫做1 个单次迭代训练,合适的迭代次数能保证在不会过拟合的条件下得到比较优秀的训练效果。
图6、7分别为不同的迭代次数与批样本数量对网络性能影响的对比情况。从图6 可以看出,神经网络迭代后期,损失函数变化很小。
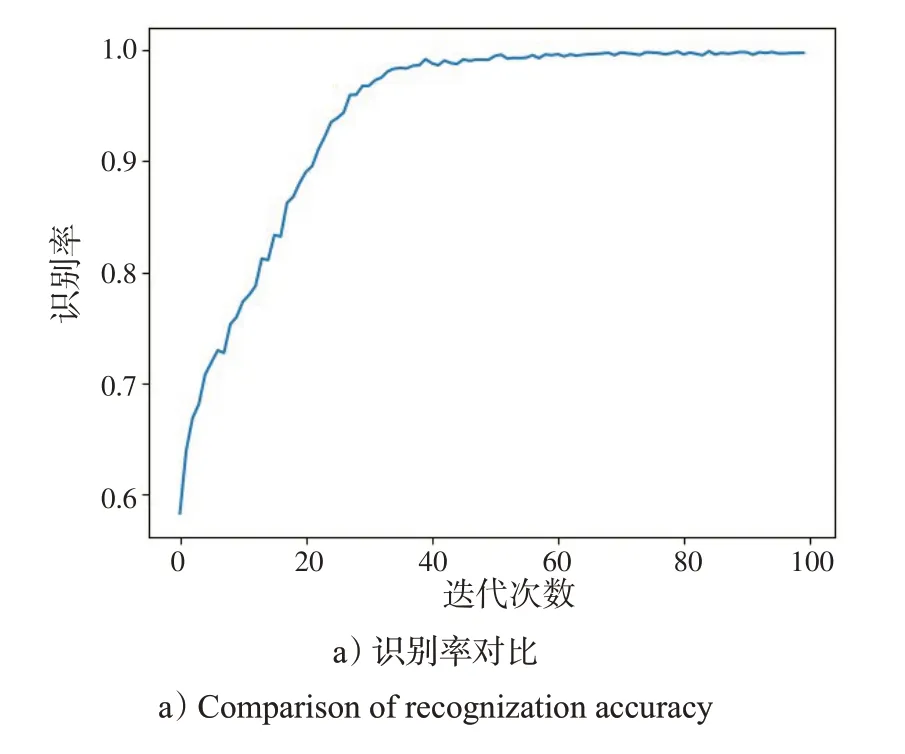

图6 不同迭代次数的识别率和损失函数Fig.6 Recognization accuracy and loss function of different iterations
为防止过拟合,在接下来的实验中,迭代次数设置为1 个较大的数字100,同时使用回调函数callback中的EarlyStopping。在训练过程中,每训练一段时间,观察一下模型在数据上的表现,并在数据表现没有明显提升时自动终止迭代,输出准确率和损失函数的值,如图7所示。
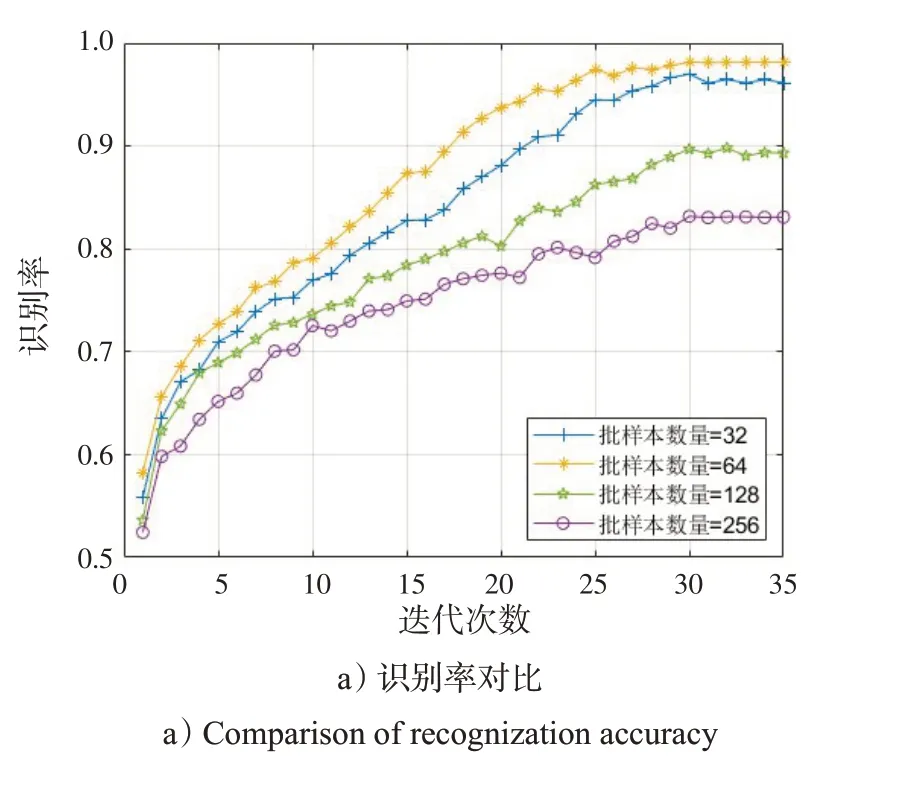
图7 不同批样本数量的识别率和损失值Fig.7 Recognization accuracy and loss values of different batch sample sizes
由图7 a)可以看出,随着批样本数量从32增加到64时,识别率随迭代次数增大而升高。当迭代次数大于25时,识别率达到了95%以上。但当批样本数量增加到128 和256 时,准确率逐渐下降。这是因为过大的批样本数量会使模型梯度下降加快,过早进入收敛状态,训练完数据集所需的次数减少,使训练时间增加,参数修正较慢,导致准确率下降。同时,由图7 b)可以看出,批样本数量为64 时,损失值也是最低。因此,对本文的模型来说,最佳的批样本数量应选64。
3.3 算法识别性能分析
为客观比较本文算法的性能,选用单独使用双谱对角线作为识别特征和使用SVM作为分类器进行识别和对比。得到如图8所示混淆矩阵。图8 a)表示使用本文方法测试的结果;图8 b)表示单独使用双谱对角线作为特征测试的结果;图8 c)表示使用SVM测试的结果。
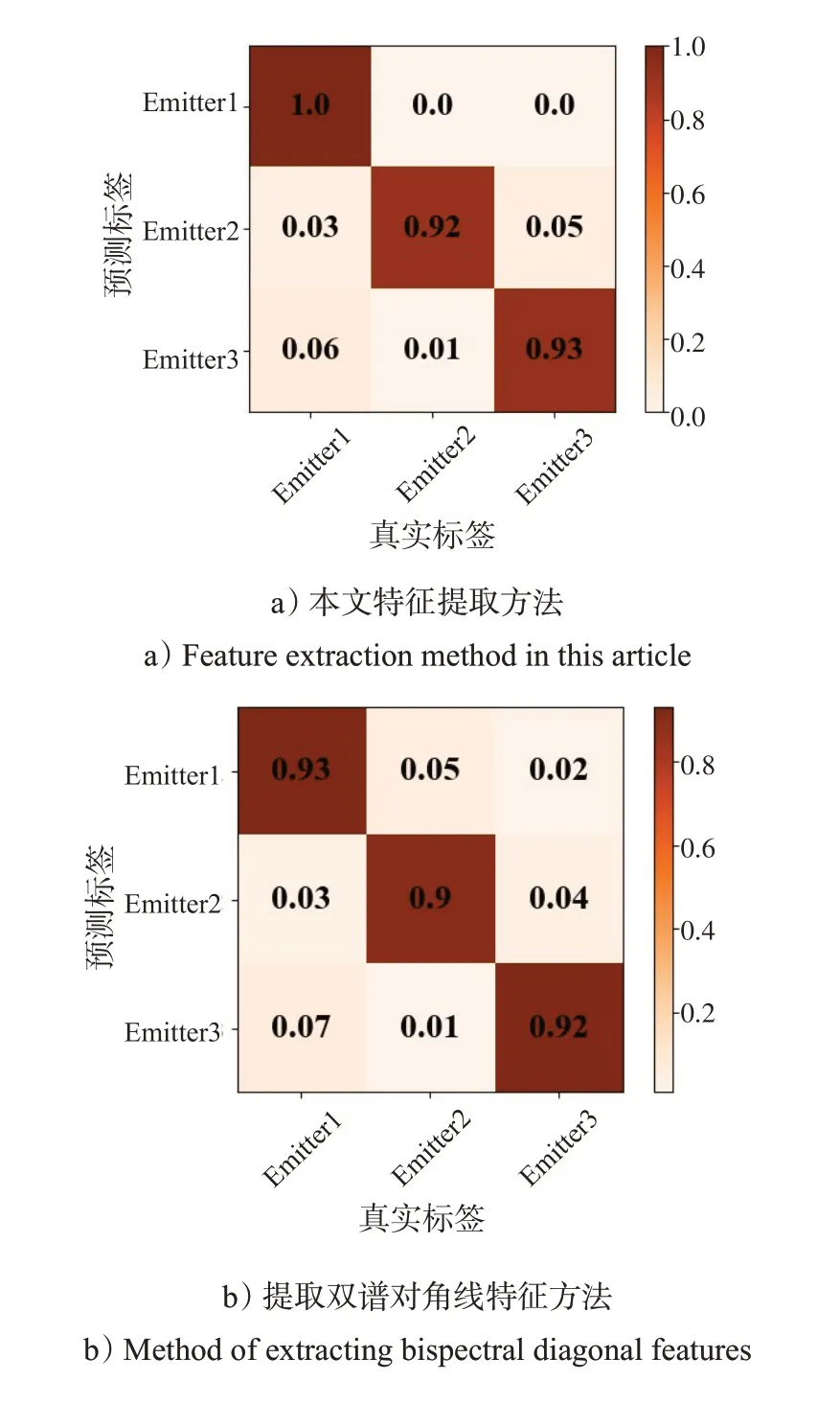

图8 本文方法与其他识别方法的对比结果Fig.8 Comparison results of this method with other recognition methods
由图8 可知,本文方法比单独使用双谱对角线所提取的特征信息有一定增强,神经网络的特征提取能力也优于SVM,准确率更高。
3.4 算法复杂度分析
对3 种方案的算法复杂度进行比较,将空间复杂度和时间复杂度作为算法复杂度的衡量指标。空间复杂度指网络中卷积核的系数,时间复杂度从迭代耗时和平均识别时间方面进行考虑。3类模型使用样本数量均为5 738,训练测试比为3 ∶1。
SVM方法的识别率相比另外2种方法较低,且算法原理中不涉及算法复杂度中包括的2种时间统计内容。表1给出了本文方法与双谱对角线法的算法复杂度比较。其中,M 为判别网络的卷积核系数,迭代时间为模型训练迭代30次的时间,平均识别时间为模型在测试集上的预测时间。由表1 可知,本文方法和双谱对角线法在空间复杂度相同的条件下,迭代耗时相差不大但平均识别时间要短19%,说明使用本文方法提取的特征对于神经网络的训练更有效,对测试集的识别效果也更好。

表1 算法复杂度分析Tab.1 Algorithm complexity analysis
3.5 网络鲁棒性分析
对训练集和验证集在网络中的识别率分析,得到结果如图9所示。Train1、Validation1分别表示本文方法的训练集和验证集;Train2、Validation2 分别表示双谱对角线方法的训练集和验证集。由图9 可知,本文方法相比双谱对角线方法识别率更高,且随着迭代次数增多,本文方法条件下训练集和验证集的正确率数值差距也逐渐减小,相比双谱对角线方法识别效果也更稳定。
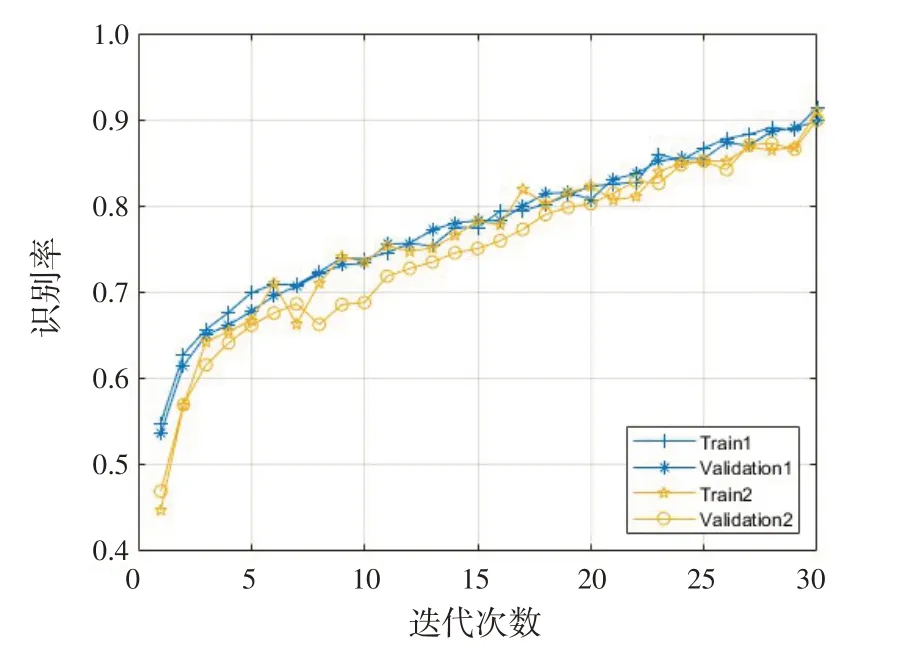
图9 不同训练集和验证集的识别率对比Fig.9 Comparison of recognition accuracy between different training sets and validation sets
综上所述,利用信号的双谱及其在双谱基础上提取的二次特征组成的特征组合,在神经网络的加成下对同类型雷达辐射源的识别有较高的准确率且实时性较好。
4 结束语
本文在信号双谱分析的基础上取对角线作为识别特征,并通过对角线上的双谱信息求双谱对角线幅度分散熵和对双谱矩阵取奇异值全局熵,进一步扩充了辐射源个体的识别特征。这样既减少了计算量,又通过二次特征进一步丰富了双谱特征信息量,提高了辐射源个体识别率。因此,利用双谱包含的丰富辐射源个体特征信息配合熵理论对于不确定度的刻画、对于辐射源个体的识别都有一定的工程意义。
