浅埋连拱隧道施工场景风险行为视觉关系检测仿真
2023-11-13马培广邓稀肥
马培广 邓稀肥
(中铁广州投资发展有限公司1) 广州 510335) (中铁四局集团有限公司2) 合肥 230023)
0 引 言
连拱隧道是我国近几年高速公路建设的一种新型的跨度较大的隧道,浅埋连拱隧道具有线性流畅、无需很大占地面积和空间利用最大化等优势[1].由于该隧道埋深较浅,且开挖和支护交错,浅埋地段的围岩稳定性较差,如果施工过程中发生人员行为不规范[2],易导致安全隐患.因此,该隧道在施工过程中,均会采用监控的方式掌握施工现场的安全情况.由于隧道施工的环境因素,会影响视频采集图像的清晰度和图像质量,导致无法及时对风险行为进行预警.
针对施工场景风险行为检测,Mao等[3]对黄土连拱隧道的漏水敏感区进行了检测,通过设置不同数量的环形和纵向裂纹,分析围岩渗流场的变化,确定漏水敏感区域.Li等[4]通过三维有限差分模拟研究了三重隧道的成拱机理,及时实施管棚和帷幕灌浆,确保后续开挖中的开挖安全,监测和分析了三个截面的力学响应.吴贤国等[5]基于物元理论和证据理论,研究了盾构隧道施工对邻近建筑物的风险评价.龙丹冰等[6]基于知识图谱改进相关施工行为安全风险检测方法,但是光纤交时的检测精度仍需进一步提升.
文中研究浅埋连拱隧道施工场景风险行为视觉关系检测仿真方法,以浅埋连拱隧道施工场景的特性分析为基础,针对监控视频画面色彩对比度不足、画面清晰度较低等问题实行修复后,采用YOLOv3检测算法,完成施工场景风险行为检测,算法独特性在于仅仅实际标注的特征图目标框的位置信息以及目标框中物体的类别信息即可计算出网络的预测输出与实际标框之间的误差,同时,其多尺度特性也使得视觉关系参数不受施工场景风险行为定位初始点坐标的约束,为视觉定位提供新方法.
1 施工场景风险行为检测
1.1 基于YOLOv3风险行为检测方法
基于YOLOv3风险行为检测方法,包含风险行为数据集的构建和标注、监控视频图像修复、风险行为检测以及检测结果优化.方法架构见图1.
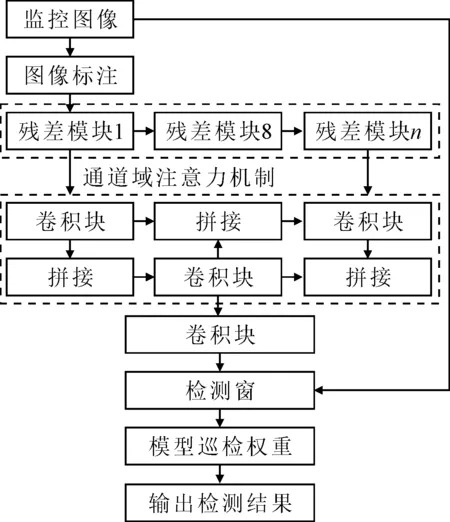
图1 基于YOLOv3的风险行为检测框架
在风险行为数据集构建和标注过程中,采用VOC格式完成监控视频图像的标注,标注后,生成xml格式的视频图像标注文件,对该文件进行图像修复.
1.2 施工场景监控视频图像修复
为保证检测的实时性和精准性,对完成标注的监控视频图像实行修复处理,以此提升图像的分辨率[7],文中基于对抗网络完成监控视频图像修复.该网络由生成器和判别器组成,两者均采用非线性映射函数,网络模型结果见图2.

图2 基于对抗网络模型结构
模型在训练过程中,以反向传播算法完成,该网络模型的目标表函数公式为
Ex~pz(z)lgD(1-G(z))]
(1)
式中:V(D,G)为交叉熵函数,对应二分类;D和G分别为判别器和生成器;z为噪声向量;x为监控视频图像的采样值;pdata(x)为该图像的真实值;pz(z)为噪声的真实值;E为期望结果.
如果G为给定,求解最优D,其目标函数公式为
ObjD(θD,θG)=-Ex~pdata(x)[lgD(x)-
Ex~pz(z)lgD(1-G(z))]
(2)
式中:D的训练数据是由两部分组成,分别为G生成的图像数据pg(x)和pdata(x);在G为给定的前提下,对该公式实行最小化处理后[8],即可获取D的最优解.因此,在连续空间内该公式可转换成:
pg(x)lgD(1-G(z))]dx
(3)
如果pg(x)和pdata(x)分别采用m、n表示,y∈[0,1],对式(3)实行简化后得出:
ObjD(θD,θG)=-mlg (y)-nlg (1-y)
(4)
(5)
网络模型在训练过程中,对D和G分别进行训练,对于前者需训练其最大化数据占据真实数据的概率,对于后者则生成最小化lgD(1-G(z))值.依据不断迭代完成D和G的优化和固定,以此保证D具有最大的判别概率.将其固定后[9],进行G的优化,此时保证D具有最小的判别概率.在pdata(x)=pg(x)的情况下,可获取全局最优解.
网络模型的D和G都有自身对应损失函数,因此,为了获取视觉质量更佳、清晰度更高的监控视频图像,采用多维损失函数描述G的损失函数LG,其公式为
LG=Ladv+αLper+βLtex
(6)
式中:α和β为权重参数;Ladv、Lper、Ltex均为不同的多维损失函数,依次分别对应对抗、感知,以及纹理.三者的计算公式分别为
Ladv=D(x)(Ex~pG-Ex~pdata)+
λEx~penalty[(‖xD(x)‖-1)2]
(7)
(8)
(9)
式中:λ为变量;x为数值差;Wij和Hij分别为图像的宽和高;φij为特征图谱,对应第j层卷积层;IHR和ILR为特征图的高维语义信息,前者对应生成特征图,后者对应真实特征图.Ltex可完成监控视频图像纹理信息的局部配准,引入该函数后,可在图像修复生成过程中,避免发生伪影现象[10],保证更好的图像纹理信息,提升浅埋连拱隧道施工场景视频监控图像清晰度和质量.
1.3 风险行为检测
1.3.1施工场景风险行为检测模型
YOLOv3检测模型是由较多的残差模块构成,其主要结构包含特征提取、特征融合以及目标检测三个部分,特征提取是由模型中的卷积层完成,各个卷积层的核心为卷积核[11-12],并且结合残差模块保证特征提取的精准性.完成特征提取后进行特征融合,该融合主要依据上采样方式完成,保证图像深层和浅层特征的有效融合,为风险行为检测提供可靠特征依据[13],最后依据融合后的特征完成风险行为检测.
YOLOv3检测模型的损失函数包含坐标、类别以及置信度,依次分别用l1、l2、l3表示,三者的计算公式为
(10)
(11)
l3=(cξ-cζ)2
(12)
式中:N为训练的图像样本数量;r为四个属性值r∈(x,y,ω,h);(x,y)为初始点坐标;特征图的宽和高分别用w和h表示;λo为二值变量,依据该变量判断检测单元格内是否存在目标,如果存在该变量结果为1,反之为0;k为行为类别,其取值范围(0,K-1),其中K为行为类别总数量;ctruth和cpredict分别为行为的类别的实际结果和检测结果;cξ和cζ分别为置信度的实际结果和检测结果.
总损失函数为
l=l1+l2+l3
(13)
1.3.2施工风险行为检测模型优化求解
YOLOv3检测模型在进行浅埋连拱隧道施工场景风险行为检测时,需先完成图像的特征提取.为了提升模型的特征提取效果,在模型的残差层和特征层之间,引入通道域注意力机制,以此使模型能够自动完成特征图对应的各个通道权重的学习,强化特征图,显著降低背景信息的干扰[14],为风险行为检测提供更丰富的特征信息,提升施工场景风险行为检测的精准性,其步骤如下:
步骤1设U表示获取的特征图,其大小为s×w×h,通道域注意力机制引入后,采用压缩方式对U实行处理;同时,通过全局池化对卷积层的输出结果进行处理[15],以此可获取新的特征图Zs,其大小为s×1×1.则压缩后通道s的特征计算公式为
(14)
式中:ψsq为压缩操作;Us为二维矩阵,且为第s个通道;(i,j)为像素特征,对应第i行第j列.
步骤2采用非线性变换对压缩获取的s通道的特征图Z实行处理,该变换通过连续的两个全连接神经网络完成;以此可得出卷积核σ,其大小s×1×1.压缩公式为
c=ψsq(Z,σ′)
(15)
式中:σ′为其中一个卷积核,其可用于完成权值的学习;ψsq为乘法操作.
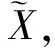
(16)
式中:ψsc为us和σs的乘积操作.
2 算例分析
获取某浅埋隧道工程施工时的视频监控图像作为测试图像,该图像的大小为512 px×521 px,图像数量共有2 000张.通过Vensim PLE软件完成风险行为检测的仿真测试,获取的图像数据通过MySQL存储,利用OpenCV和Tensorflow两种图像处理库编写图像算法.网络模型参数设置:检测网络的训练轮次为50,学习率为0.001,每经过两次迭代则完成一次权重更新.
为衡量本文方法的检测性能,采用二值变量λo作为衡量指标,随机抽取10张图像进行测试,其中包含4张无人图像,6张有人施工图像,获取10张图像的λo结果,见表1.

表1 二值变量测试结果
由表1可知:采用本文方法对随机抽取的10张图像进行检测后,10张图像的λo结果与实际图像的一致,其中图像2、4、5、6为无施工人员图像,因此λo值为0;其余6张图像的λo值均为1,表示检测的图像中存在人员施工.因此,本文方法检测性能良好,能够精准判断施工场景内是否存在检测目标.
为更进一步衡量本文方法对于施工场景风险行为的检测性能,采用图像的前景和背景的误检率作为评价指标,其中前景指的是图像中的施工人员,除此之外均称为背景,其计算公式分别为
(17)
(18)
式中:Ap和Ab为面积,前者对应检测框区域,后者人体最小外接矩形;S为Ap和Ab相交面积.文中两个指标的期望结果低于7%.
随机抽取一张图像,依据上述两个公式获取本文方法在不同大小的检测窗口下,两个指标的计算结果,见图3.

图3 两个指标的计算结果
由图3可知:在不同的检测窗口大小下,采用本文方法对进行风险行为检测后,φff和φbf两个指标结果最高值分别为4.5%和5.5%左右,最小值分别为1.7%和1.5%.因此,本文方法的检测性能良好,可有效区别图像中的前景和背景,以此保证精准的检测效果.
获取采用本文方法对全部的测试图像实行检测,并获取风险行为结果,见图4.
由图4可知:本文方法应用后,能够完成施工场景内各种风险行为的检测,并且可显示当前施工场景内存在的施工人员数量、风险行为人员数量;同时发送风险行为预警提醒.除此之外,还可查看历史不安全行为记录以及发生区域,见表2.
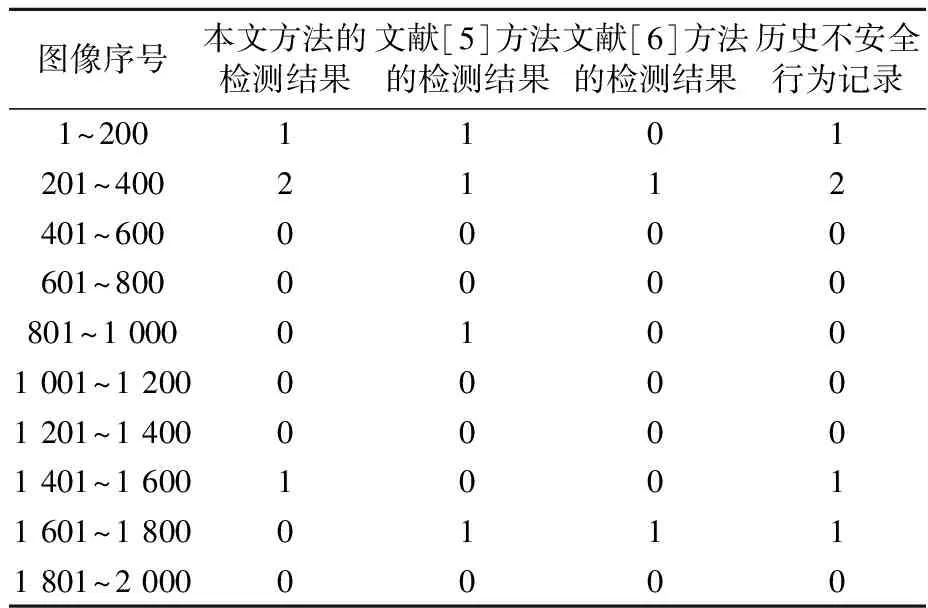
表2 不安全行为漏检率测试结果 单位:次
由表2可知:与其他方法相对比,本文方法只有在1 601~2 000的情况下,漏检一个,表明应用性良好,能够实时、可靠检测施工场景内的风险行为.
3 结 论
1) 基于对抗网络模型结构,对完成标注的监控视频图像实行修复处理,保证图像的曝光现象和阴暗现象有效改善,提升图像质量和清晰度,可靠完成图像中的目标检测.
2) 在连续空间内,采用多维损失函数,去除伪影现象,进行监控视频图像纹理信息的局部配准,保证检测目标前景、后景与实际图像的一致,可动态显示当前施工场景内存在的施工人员数量、风险行为人员数量.
3) 引入通道域注意力机制,构建施工场景风险行为YOLOv3检测模型,自动完成特征图对应的各个通道权重的学习,强化特征图,获取不同风险行为结果,降低漏检现象的同时发送风险行为预警提醒.
