基于交叉区域SMOTE算法的非平衡数据分类
2023-11-13吴立胜皮珣珣
吴立胜 皮珣珣
(江西科技学院信息工程学院,江西 南昌 330098)
1 引言
不平衡数据分类问题指的是在二分类任务中,某一类样本的数量远远小于另一类样本,导致数据分布不平衡[1]。这种情况在现实生活中的许多场景中都普遍存在,例如信用卡欺诈检测、信息检索和过滤、市场行为分析等。传统分类算法通常假设待分类的两类样本数量大致相等,因此在处理不平衡数据时容易受到多数类样本的影响,导致分类边界偏移和分类错误的问题。
为了解决不平衡数据分类问题,学者们提出了许多解决方案,主要从数据集和算法两个方面入手。在数据集方面,处理不平衡数据的方法通常涉及两个方面:过采样增加负类样本或者下采样减少正类样本,以实现数据样本的平衡,并提高分类准确率。其中,过采样增加负类样本的方法之一是SMOTE(Synthetic Minority Over-sampling Technique)[2],它通过从负类样本中选取K近邻样本,并生成新的合成负类样本,从而增加负类样本的数量。
但是,SMOTE算法对负类样本合成未考虑负类样本点分布。Han等人针对生成负类样本点分布不平衡提出了Borderline-SMOTE方法[3],其在最近邻正类样本点构成n维球体内进行随机插值,扩大生成负类样本点的区域,将数据集中到分类边界。宋艳等人针对数据不平衡提出E-SMOTE算法[4],SMOTE算法在进行插值时,不仅考虑了邻域样本点,还考虑了附近邻域样本点的分布特征。它通过控制近邻样本点的分布特征,来生成合成的负类样本点,以实现对负类样本点分布区域的调控。
Francisco等使用了二值化分解正类样本并结合SMOTE算法来生成负类样本,以平衡数据集[5]。Matwin等通过边界、冗余和去重等方法减少正类样本的数量。Mani等采用KNN算法删除正类样本点,并提出了NearMiss-1、NearMiss-2、NearMiss-3和“最远距离”四种方法,根据负类样本点的距离选择正类样本点[6]。在算法层面,Patel等采用混合加权的KNN方法对不平衡数据进行分类,通过动态设置权值,给予负类样本较大的权值,以减小分类边界对正类样本的影响[7]。袁兴梅等提出了一种新型的集成分类算法AdaStASVM,首先利用聚类算法获取样本的结构信息,然后通过Ada-Boost动态调整样本权重,以减少数据不平衡带来的影响[8]。
综上所述,现在对不平衡数据研究关注重点是对负类样本合成过程、分类算法权重等方面。本文通过限制负类样本的合成区域提出CRSMOTE算法。CRNSMOTE算法确定负类样本点合成最佳阈值区间。将CRSMOTE与SVM相结合进行大量仿真实验,实验结果表明该算法提升了在不平衡数据集上的G-mean,F-value以及Precision值。
2 相关理论
2.1 经典支持向量机在不平衡数据分类的不足
支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法[9],被广泛应用于二分类和多分类问题。然而,在处理不平衡数据分类时,经典的支持向量机算法存在一些不足之处。
在经典的支持向量机算法中,目标是找到一个决策边界,将正类样本和负类样本尽可能地分开。然而,在不平衡数据集中,正类样本的数量明显多于负类样本,这导致支持向量机更倾向于将决策边界偏向多数类别。这种偏向会导致分类器对少数类别的识别能力下降,容易将少数类别误分类为多数类别,影响了分类的准确性。
此外,支持向量机的学习过程中,对每个样本的处理是均等的,没有对不平衡数据集进行针对性的处理。这意味着在模型训练中,每个样本对分类器的影响相同,无论其属于多数类还是少数类。对于少数类样本而言,可能受到多数类样本的干扰,导致分类器难以捕捉到少数类样本的特征和模式。
因此,针对不平衡数据分类问题,仅使用经典的支持向量机算法可能无法达到理想的分类效果。为了改进不平衡数据分类的性能,需要采用一些特殊的方法或算法来处理不平衡数据集,以提高对少数类别的识别能力和分类准确性。
图1中表明分类边界向负样本方向移动,产生上述情况是由于优化函数中对正类样本和负类样本采用相同惩罚系数,造成负类样本分类存在较大的误差。负类样本其惩罚系数应远远小于正类样本的惩罚系数。因此,要提高SVM在不平衡数据分类中的准确性,需要解决SVM偏向负类样本的问题[7]。
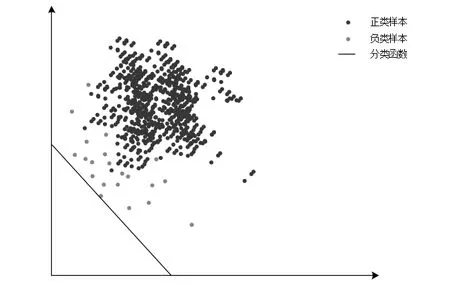
图1 SVM分类的结果
2.2 SMOTE算法
SMOTE算法是采用人工合成增加负类样本点降低数据不平衡性。SMOTE算法根据欧几里德距离计算一个样本X={x1,x2…,xn}和样本Y={y1,y2…,yn}之间距离。那么样本X和样本Y之间的欧几里德距离D:
根据欧几里德距离,将样本空间中最近的样本点分为一组。然后,将距离较近的样本点划分为负类样本。接着,在每组样本中,使用SMOTE算法构造新的负类样本。
其中i=1,2,…,m,X表示负类样本点,Yi为X的第i个近邻样本,rand(0,1)表示0到1一个随机数。Xnew表示新合成的样本。
3 基于不平衡算法的改进
SMOTE算法在进行负类样本合成时候,无法解决负类样本点分布不均衡的问题[10],同时计算过于复杂。本文针对SMOTE算法负类样本分布不均匀提出了CRSMOTE算法。CRSMOTE算法重点关注样本点产生的区域和合成数量,避免样本数据分布的边缘化。
CRSMOTE算法:
输入:训练集I,原始样本点正类样本集合为S1={x1,x2…xn}、负类样本集合为S2={y1,y2…ym}。
(1)从负类样本集中随机选择一个样本点yi,i,j∈(1,m),以参数φ为半径,其计算公式为:
其中,D(yi,yj)表示采用欧式距离来计算负类样本点yi和yj之间的距离。
(2)将负类样本点yi与剩下任意一个负类样本点yj采用公式3得到数值Mi。
(3)以负类样本点yi为圆心,以Mi为半径的圆Oi,计算其中包含样本点数目Ni,其中负类样本数目Ai,其负类样本密度计算公式MinPtsi:
(4)负类样本点yj与剩下任意一个负类样本点ya,a∈(1,m),采用公式3得到数值Mj。
(5)以负类样本点yj为圆心,以Mj为半径的圆Oj采用公式计算其密度MinPtsj。
(6)计算圆Oi和Oj之间交叉空间负类样本点比重I,其计算公式如下:
其中,MinPtsi∩j表示圆Oi和Oj之间相交部分负类样本点密度。
(7)若I小于相应阈值区间,则在yi和yj之间进行负类样本点合成数目为N',使得I最终处于最佳阈值区间。若I值大于1,则忽略交叉区间不对负类样本点yi和yj进行合成。
(8)如果合成负类样本点数目不足,则继续转步骤4。当步骤4中负类样本点全部随机完成,但是合成负类样本点还未达到和正类样本点数量1:1,则再转步骤1选择不重复负类样本点:继续步骤2~7,直到生成负类样本点和正类样本点数量达到1:1。
如何获得高效的阈值区间,从而进行负类样本点合成是本实验需要解决问题的关键。本文采用在非平衡数据中分类的一般性的评价标准:F-value和G-mean计算的值进行评估。采用I来确定合成的负类样本点分布。在表1和表2分别随机选择3个数据集进行实验,划分区间为[0.0,0.2),[0.2,0.4),[0.4,0.6),[0.6,0.8),[0.8,1.0]这5个区间,分别将下面数据集中包含负类样本点按照CRSMOT算法合成对其进行测试。经过测试,图1和图2表明,不同数据集在I处于[0.2,0.4)之间F-value和G-mean值更为高效。说明交叉区域内负类样本合成具有一定的普适性,除了改变负类样本点分布区域之外,还可以提高分类器的分类效率。

表1 不同区间下的G-mean值

表2 不同区间下的F-value值
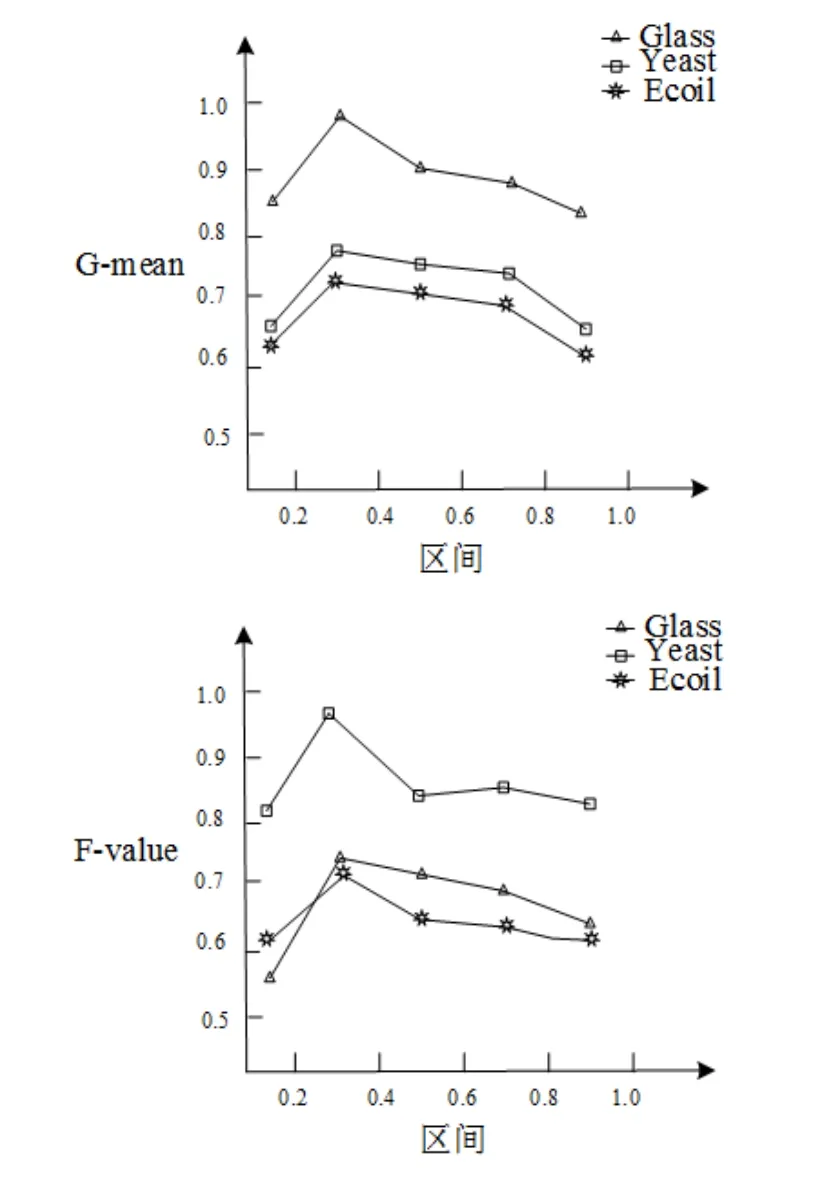
图2 不同区间下G-mean值和F-value
4 实验与结果分析
4.1 不平衡数据评价指标
对二分类问题采用混淆矩阵来对其进行评价。混淆矩阵将样本分为四种组合:真正类(True Positive):样本的真正类别属于正类,模型预测的结果也是正类。假负类(False Negative):样本的真正类别属于正类,模型预测的结果属于负类。假正类(True Negative):样本的真正类别属于负类,但是模型将其预测成为正类。真负类(True Negative):样本的真正类别是负类,模型预测成为负类。分类混淆矩阵如表3所示[11]。
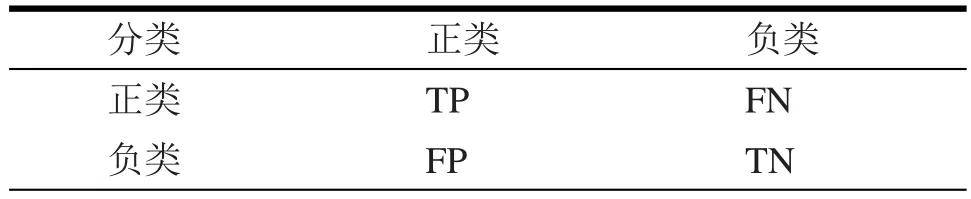
表3 混淆矩阵
分类器进行分类以准确率(Precision)和召回率(Recall)为最基础两个指标[12]。准确率:测试数据中,分类器正确分类的样本数量占总样本的比重。召回率:样本数据中,表示样本数据集中存在多少正例样本被正确预测。其计算公式为[13]:
F-value是对准确率和召回率进行平均,本次实验中β调和因子设置为1。F-value定义如下:
在对于非平衡数据的处理中,对于分类器中两类样本性能一般采用G-mean值评价。G-mean其定义如下:
4.2 实验过程和结果
本文为了测试CRSMOTE算法对非平衡数据的处理,文中采用了8个UCI数据集进行分析和实验。非平衡比是指正类样本和负类样本的数量比。表4同时给出负类样本、正类样本以及非平衡比。
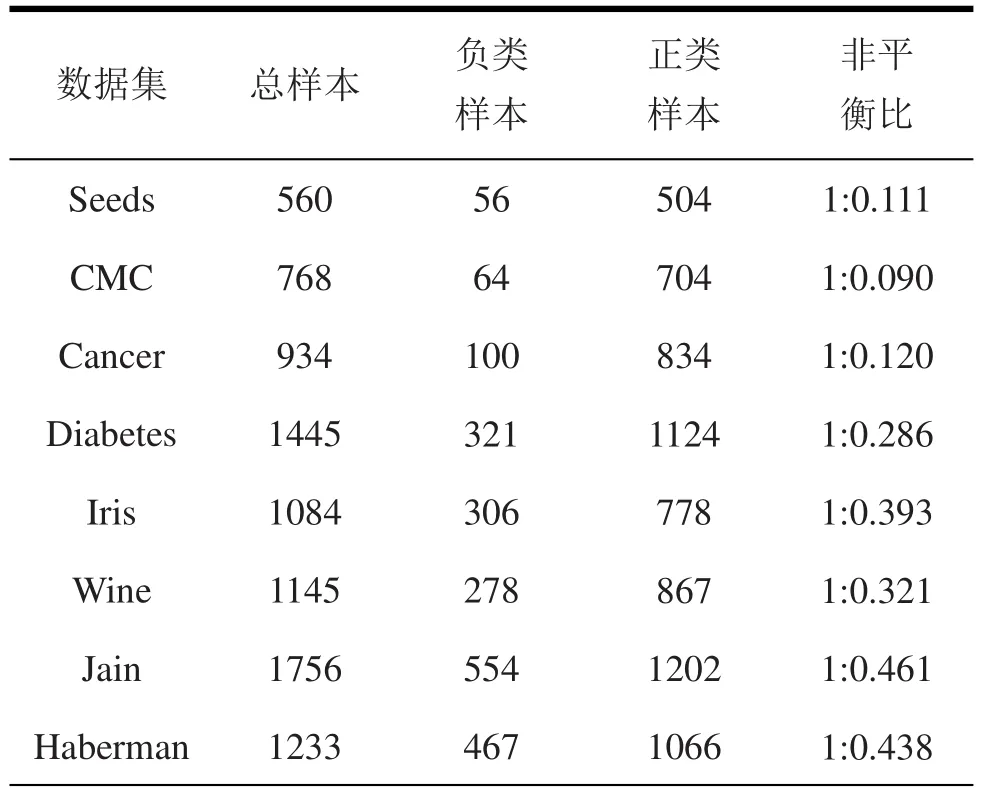
表4 实验中UCI数据集
每次实验采取随机方法将样本数据中80%划分为训练集,剩余20%划分为测试集。本文对测试数据取10次数据的均值,同时采用F-value、G-mean、Precision评价指标进行评价。实验中将CRSMOTE算法与SMOTE算法、TSMOTE算法[14]和单纯SVM算法进行对比,以显示该算法的优势。从图3~5中分别采用了4种策略算法在8个数据集来表示其趋势。从图可以看出采用CRSMOTE算法进行过采样,使得负类样本的性能得到提升。
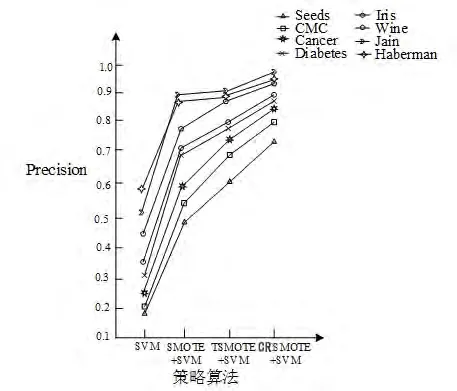
图3 不同策略算法Precision值变化图
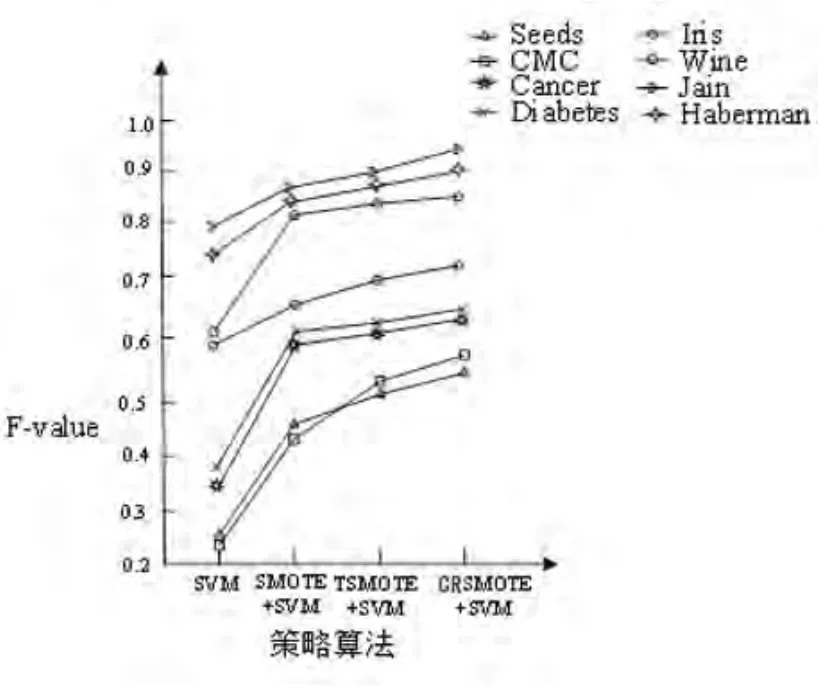
图4 不同策略算法F-value值变化图

图5 不同策略算法G-mean值变化图
实验表明在图3~5和表5~7采用四种算法分别是:SVM、SMOTE、TSMOTE、CRSMOTE仿真得出F-value、G-mean、Precision指标进行比较。结果表明数据集中采用CRSMOTE算法在SMOTE基础上进行改进使其指标均得到提升。本文提出的算法在处理不平衡样本中,生成负类样本点分布更加均匀,最终使得分类准确性得到提升。

表5 数据集中Precision值
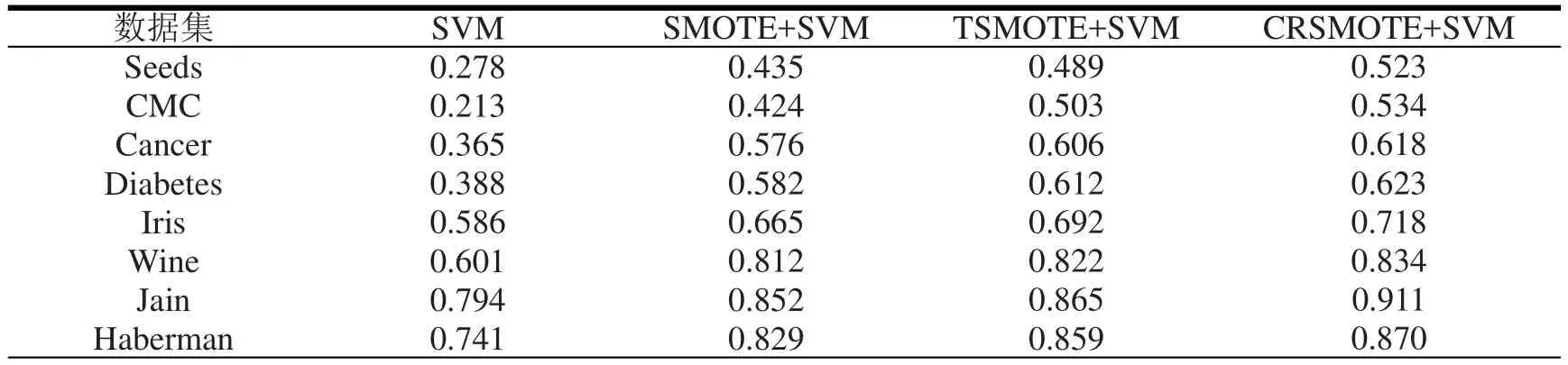
表6 数据集中F-value值

表7 数据集中G-mean值
5 结语
本文针对SMOTE算法进行改进提出CRSMOTE算法。改进算法考虑到数据生成区域和数量分布,使得对样本点生成准确率得到提升,有效改善SMOTE算法样本点分布不均匀的问题。实验结果表明,CRSMOTE与SMOTE和TSMOTE相对比得到了比较高的F-value、G-mean和Precision值,提高了对于不平衡数据分类的准确性。本文算法改进还存在合成负类样本点计算量过大、未考虑异常点剔除等缺陷,未来将对模型做进一步优化。
