基于改进DeepLabV3+深度学习模型的冬小麦种植面积提取研究
2023-11-13路秋叶刘法军丁志国宫锟霖
路秋叶,刘法军,2*,丁志国,郭 鹏,2,宫锟霖,2
(1.山东农业大学 信息科学与工程学院,山东 泰安 271018;2.山东省地质矿产勘查开发局第五地质大队,山东 泰安 271018)
0 引言
冬小麦是我国北方地区的主要粮食作物之一,对国家经济发展起着举足轻重的作用[1]。及时了解冬小麦种植面积对开展冬小麦长势监测和估产、区域粮食安全评估、制定农业政策等工作具有重要的社会意义[2]。当前,卫星遥感技术已经成为获取大范围冬小麦种植信息的最主要方法,国内外众多学者开展了冬小麦种植面积提取研究[3-4]。其中,最常见的监测冬小麦种植面积的方法有:① 以归一化植被指数(Normalized Difference Vegetation Index,NDVI)等植被指数的时间序列变化为依据,设定适当的阈值,提取出冬小麦的空间分布信息[5-6]。②采用机器学习的方法,对遥感图像中的各类地物进行分类,并提取出冬小麦的种植面积[7-9]。然而现有的机器学习方法依赖于专业知识人为创建特征,对影像特征或组合方式的选取均会影响算法的精度,且没有有效地利用影像中的特征信息。基于深度学习的卷积运算,以其特有的内部层次结构、强大的自主性与容错性能够从原始数据中自动提取特征,并对其进行逐像元的语义分割,广泛应用于作物信息提取,但存在模型复杂以及训练时间较长的问题。
谷歌团队自2015年起提出了一系列DeepLab模型,其中分割效果最优的是DeepLabV3+模型[10],但该模型在解码器(Decoder)部分对于特征图的多尺度连接不够充分,存在漏分、错分以及边界粘合现象,最终的语义分割图的分割精细度有待提高[11]。此外,因遥感影像中冬小麦内部差异较小,Xception主干网络并不能很好地发挥深层网络结构的优势,导致过度拟合的风险增大;同时,过深的网络还需要更多的硬件支持,导致训练时间过长。
因此,本文旨在解决深度学习语义分割中存在的分割效果差、提取精度低、模型复杂以及训练时间长等问题,基于高分辨率遥感影像,利用DeepLabV3+模型,引入MobileNetV2主干网络、注意力机制、损失函数、组归一化(Group Normalization,GN)和条带池化(Stripe Pooling),提出一种改进的DeepLabV3+模型,并应用于山东省泰安市岱岳区夏张镇和徂徕镇的冬小麦种植面积提取,取得了较为满意的结果。
1 研究区概况与数据预处理
1.1 研究区域概况
山东省泰安市岱岳区位于泰山以南,属于温带季风气候,四季分明,寒暑适宜,光温同步,雨热同季,气温年平均值13.3 ℃,年平均降水量685.6 mm,年际变幅较大。受地貌影响,东部降水多于西部,山区降水多于平原,具有春旱、夏涝、晚秋又旱的水情特点。夏张镇位于岱岳区西部,地势北高南低,在良好的土壤墒情和适宜的气候下,冬小麦种植基本实现全覆盖,主要集中在东南部的平原地区,且大面积连片种植,小部分集中在西部;徂徕镇位于岱岳区东南部,地势东南高西北低,耕地主要集中在北部和西部,冬小麦分布分散且占比小。
1.2 数据及预处理
高分二号卫星是我国自主研制的首颗空间分辨率优于1 m的民用光学遥感卫星,搭载2台高分辨率1 m全色、4 m多光谱相机。影像采集时间为2020年4月28日和2020年5月3日。利用ENVI软件对原始影像进行辐射定标、大气校正和正射校正等预处理,并裁剪成512 pixel×51 pixel的小样本,然后使用Labelme工具包绘制冬小麦标签。本文采用旋转90°、旋转180°、旋转270°、水平翻转和竖直翻转共5种方式对原图和标签图进行数据增强,以提高模型精度,防止过拟合现象[12],如图1所示。经过筛选去除问题影像,最终生成6 564对样本数据,并依照6∶2∶2的比例生成训练集、验证集、测试集,从而完成数据集的构建。


图1 数据增强Fig.1 Data enhancement
1.3 研究区采样点分布
通过对夏张镇和徂徕镇的实地调研,根据研究区的地形、土地利用、冬小麦分布等布设采样点,共布设夏张镇冬小麦采样点115个,徂徕镇冬小麦采样点104个,采样点位置分别如图2(a)和图2(b)中的绿色三角符号所示。获取的实际采样点不仅可以为样本数据集的制作提供数据支撑,还可以用于岱岳区夏张镇和徂徕镇冬小麦种植面积提取结果的精度验证。

(a)夏张镇采样点示意

(b)徂徕镇采样点示意
2 模型与方法
2.1 DeepLabV3+模型
DeepLabV3+是一种基于编码器(Encoder)与Decoder相结合的语义分割模型[13]。Encoder采用主干网络Xception和空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)提取的深层特征[14]通过上采样(Upsample)进入解码器,并将其与原始浅层特征图融合,再利用上采样还原特征图,最终得到冬小麦分割结果[15-16]。原始的DeepLabV3+网络结构如图3所示。
2.2 改进DeepLabV3+模型
针对DeepLabV3+模型对图像分割的拟合速度慢、目标边缘分割精度不高的问题,对DeepLabV3+模型做以下五方面的改进。改进的DeepLabV3+语义分割网络整体结构如图4所示。

图4 DeepLabV3+改进后的网络结构Fig.4 Improved network structure of DeepLabV3+
2.2.1 替换主干网络
本文采用轻量化改进的MobileNetV2网络模型[17],在利用深度可分离卷积的基础上,通过引入倒置残差模块和线性瓶颈层的方法,极大地降低模型参数量,从而加快网络的收敛速度。
2.2.2 CBAM
卷积块的注意力模块(Convolutional Block Attention Module,CBAM)结合通道注意力模块和空间注意力模块,将其按顺序串联处理[18],如图5所示。该模块通过对各通道及各像素点的处理,对输入图像的特征进行自适应优化,使模型获得最优的处理效果,且能够节约参数和计算力[19]。

图5 CBAMFig.5 CBAM
2.2.3 组归一化
批归一化(Bath Normalization,BN)是指一种在批次维度上进行归一化的操作,并受批次大小(batchsize)的影响。BN错误率随batchsize的减小而增大,若batchsize过小则计算均值和方差会不准确,若太大则显存可能不够用。而组归一化(Group Normalization,GN)算出的是每个组的均值和方差,避免了batchsize对模型的影响,基本保持不变。
2.2.4 Focal Loss+Dice Loss组合
损失函数是评价分类器性能的函数。原始模型使用交叉熵损失函数(Cross Entropy loss,CE)计算损失时未对不同类别进行限制。相似系数损失函数(Dice Loss)是一种基于区域的损失,从全局出发计算损失,而焦点损失函数(Focal Loss)是基于分布的损失,是交叉熵损失的一种变体,二者结合可通过降低简单示例的权重来解决类别不平衡难易样本的不平衡问题[20]。
2.2.5 条带池化
条带池化采用水平垂直的条带状池化的方法,有效处理目标为长条状时的情形,并可获得孤立区域间的远距离关系,进而获得上下文信息[21]。ASPP与条带池化并联能够更好地捕捉多尺度信息,适应不同大小的目标。同时,条带池化和ASPP都具有参数共享的特性,它们可以共享相同的参数减少训练数据量,降低过拟合风险,并增强模型的鲁棒性和稳定性。
2.3 实验环境设置
实验过程中使用Pytorch1.8.0、CUDA11.1、Python3.8、Windows 10;硬件实验环境采用GPU显卡为NVIDIA GeForce RTX 3090-24 GB。batchsize设置为16,初始学习率设置为7×10-3[22],训练轮数为100。
2.4 评价指标
本文利用平均交并比(Mean Intersection over Union,MIoU)、准确率(Accuracy)和平均像素精度(Mean Pixel Accuracy,MPA)作为识别结果评价指标[23]。其中MIoU为计算真实值和预测值2个集合的交集和并集之比;Accuracy为预测类别正确的像素数占总像素数的比例;MPA为计算每个类内被正确分类的像素数之后求所有类的平均值。
式中:TP为预测为冬小麦的像素数,FN为将冬小麦预测为背景的像素数,FP为将背景预测为冬小麦目标的像素数,TN为预测为背景的像素数。
3 结果与分析
3.1 改进前后结果对比
为解决由于网络过深而导致的过拟合现象,本文选择MobileNetV2作为主干网络,由于其具有轻量化的网络结构,可以对训练时间、预测时间及参数数量等方面进行优化。不同的主干时间和参数量情况如表1所示,替换主干网络之后的单张训练时间降低到2.8 s,预测时间缩短到29 ms,参数量减少到22.4 MB,从数据上完成轻量化网络的任务[24]。损失值是反映预测值和真实值之间的差距,改进前后损失函数曲线如图6所示。

表1 不同主干网络训练时间与参数量的结果对比Tab.1 Comparison of the results of training time and number of parameters for different backbone networks

(a)DeepLabV3+模型Loss图

(b)改进DeepLabV3+模型Loss图
由图6(a)可以看出,随着训练次数的增多,前40次训练时,以Xception为主干网络的DeepLabV3+模型的训练集Loss值(train loss)不断降低,但测试集Loss值(val loss)反升,表明网络虽在训练集上能够取得较好的效果,但难以将其扩展到训练集以外的其他数据上,因而造成严重的过拟合现象;当进行第60次迭代训练时,DeepLabV3+模型逐渐收敛,最后的训练集最小Loss值为0.164,测试集最小Loss值为0.126。由图6(b)可以看出,以MobileNetV2为主干网络的改进DeepLabV3+模型在训练前期Loss值出现振荡,但总体上变化幅度较小,且训练集和测试集的Loss值均呈现出下降趋势;模型在60次迭代后逐渐收敛,损失函数值最终均收敛为0.060,与原始模型主干网络相比,分别降低了0.104、0.066,说明轻量化主干能够有效减少过拟合现象,改进模型具有较好的损失函数收敛性,这将有利于提高冬小麦图像分割精度。
3.2 深度学习方法提取结果与有效性验证
本文选取夏张镇和徂徕镇进行冬小麦种植面积提取,从定性和定量2个方面对改进后的DeepLabV3+模型提取冬小麦结果进行分析,以验证改进模型在提取冬小麦方面的优越性。使用DeepLabV3+网络模型对原样本图进行训练,结果如图7所示。图7(a)~图7(c)为夏张镇影像及其提取结果图,图7(d)~图7(f)为徂徕镇影像及其提取结果图,绿色椭圆为原始DeepLabV3+模型错分和漏分明显的部分。可以明显看出,不论冬小麦的种植区是密集或者分散,改进后的模型均可识别出冬小麦,虽然仍存在少量的错分和漏分问题,但2个地区改进后的模型提取结果相对于原始网络模型边界线表现相对平滑、棱角分明,对于识别线性地物的效果良好,提高了规则和不规则地块的提取效果。

(a)原始夏张镇图

(b)夏张镇原始模型图

(c)夏张镇模型改进图

(d)原始徂徕镇图

(e)徂徕镇原始模型图

(f)徂徕镇模型改进图
为验证本文改进模型的有效性,引入MIoU、Accuracy、MPA进行有效性验证,精度结果如表2所示。可以看出,改进后的DeepLabV3+模型相较于原DeepLabV3+模型分别提高了5.22%、2.43%和2.77%,表明改进后的DeepLabV3+模型比原始的DeepLabV3+模型有明显的精度提升效果。

表2 模型改进前后的精度结果对比Tab.2 Comparison of accuracy results before and after model improvement
为进一步评价改进模型的提取精度,利用ArcGIS10.2软件对改进前后夏张镇和徂徕镇的冬小麦提取结果进行叠加分析。结合研究区的采样点(图2(a)和图2(b)),对比改进DeepLabV3+模型提取的夏张镇冬小麦提取结果,其中108处分类正确,错误分类点7个,分类精度为93.91%,较原始的Deep-LabV3+模型的精度提高2.61%;改进DeepLabV3+模型在徂徕镇的结果,96处验证点正确分类,8个出现误分,分类精度为92.31%,较原始的DeepLabV3+模型的精度提高2.89%,结果有力证明了改进算法,使得DeepLabV3+模型模型在冬小麦提取时具有更高的提取精度。
3.3 改进DeepLabV+消融实验结果
为了进一步验证本文提出的方法是否有效及改进部分是否对模型的整体性能起到积极作用,将本文提出的改进方法在原始DeepLabV3+模型基础上进行消融实验,并制定多种评估方案,记录每一种方案及其对应结果,如表3所示。其中方案1为原始DeepLabV3+模型,方案2~7均在方案1基础上做出改进。

表3 消融实验结果评估Tab.3 Assessment of ablation experiment results
对比方案1和方案2的精度结果可以发现,基于原始的DeepLabV3+模型,在引入改进的MobileNetV2作为主干网络后MIoU提高了3.56%;方案2和方案3相比,引入Focal Loss+Dice Loss组合后,并没有损失过多的精度,MIoU仅减少0.05%;方案3和方案4相比,添加CBAM后,MIoU提高了0.36%,结果表明,虽然注意力机制对精度有一定的改善,但是其提高幅度并不大,是由于原始的DeepLabV3+模型因过深网络而造成过拟合现象;方案4和方案5相比,引入GN替代BN后,MIoU提高了0.16%;方案4和方案6相比,添加条带池化,MIoU提高了0.33%;方案5和方案7相比,GN结合条带池化后,MIoU明显提高了1.19%。将5种改进方案结合后精度显著提高,即改进的DeepLabV3+模型的MIoU提高了5.22%,进一步验证了本文方法的可行性。
3.4 夏张镇冬小麦分布信息提取
本文利用改进后的模型,基于高分二号遥感数据提取夏张镇,以获得冬小麦的空间分布信息,结果如图8所示。对比图8(a)和图8(b)可以看出,改进前后模型都可以较好地提取冬小麦种植范围,但改进后的模型显著地减少了错分部分,如图8(a)中红色椭圆圈出的部分,主要以湖泊和与冬小麦特征相似的其他植物为主。

(a)原始模型的夏张镇冬小麦提取结果

(b)改进模型的夏张镇冬小麦提取结果
对夏张镇冬小麦种植面积统计与分析结果如表4所示。可以看出,改进的DeepLabV3+模型提取的夏张镇冬小麦种植面积与官方统计面积相差仅0.32万亩,相对误差仅为-7.11%,提高了1.56%。分析提取误差出现的原因:一是由于背景地物种类较多,而发生错误的样本点多为零星分布的冬小麦,极易产生误差;二是训练集对样本点的标注也有一定影响,大量的人工工作必然会带来不确定性,导致人为干预下的标注不够精确,从而对分类效果造成一定影响。
3.5 徂徕镇冬小麦分布信息提取
利用改进前后的模型对徂徕镇冬小麦分布信息提取,如图9所示。对比图9(a)与图9(b)可以看出,改进后模型提取效果明显优于原始模型提取效果。通过将实际影像中冬小麦的种植范围与改进模型提取出的种植范围对比,发现仍有小部分误差。分析造成提取误差的主要原因为徂徕镇的冬小麦分布分散,导致改进的DeepLabV3+模型有效利用的上下文特征较少,以及人工标注对于分类结果造成不可避免的影响。
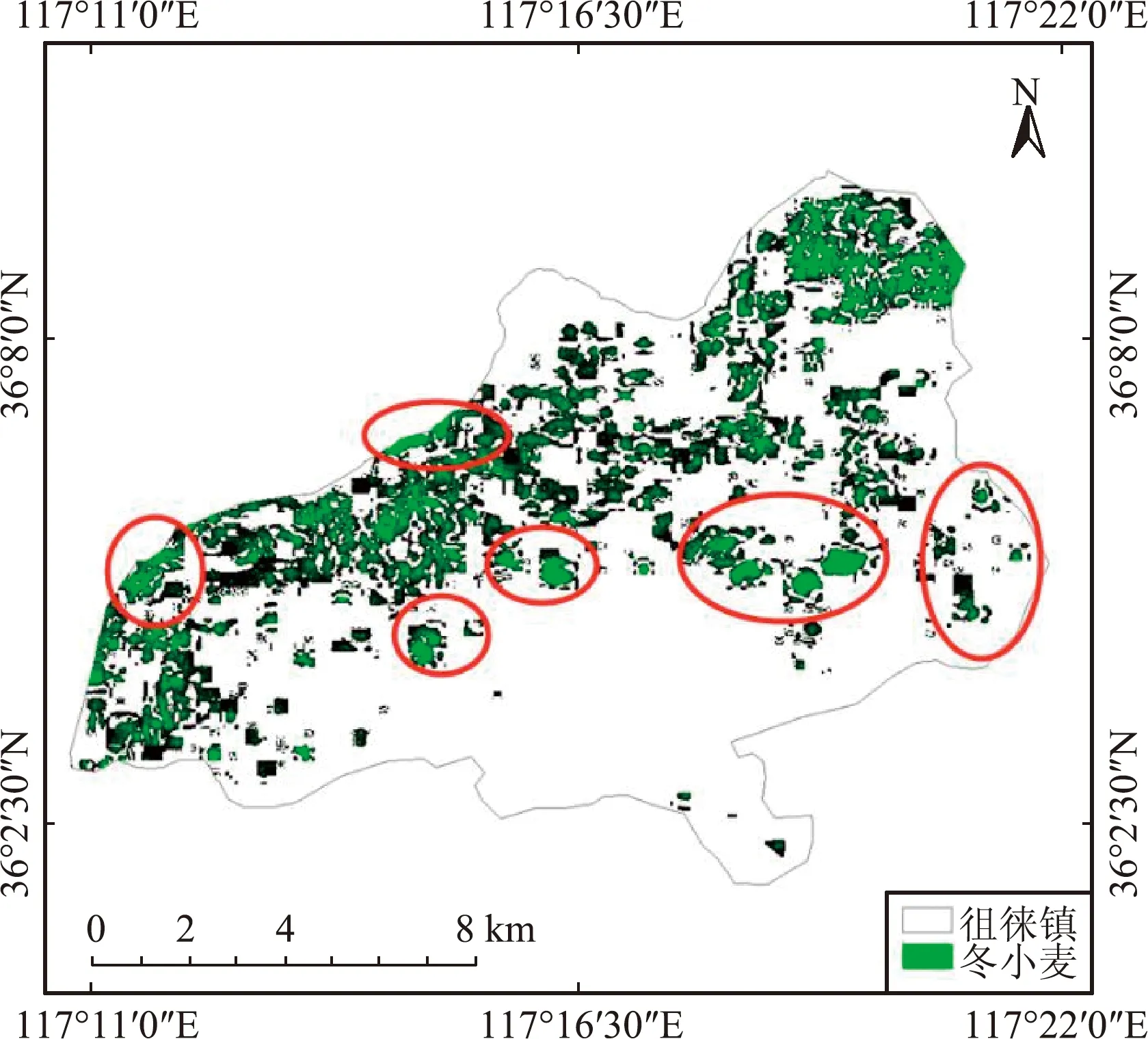
(a)原始模型的徂徕镇冬小麦提取结果

(b)改进模型的徂徕镇冬小麦提取结果
4 结束语
针对基于深度学习的语义分割模型DeeplabV3+中存在的分割效果差、提取精度低、模型复杂以及训练时间长等问题,本文提出了一种适用于遥感冬小麦种植面积提取的改进模型。在DeepLabV3+模型的基础上,替换Xception主干网络为MobileNetV2主干网络,极大地降低了模型的参数量,减轻模型训练对硬件条件的依赖,从而加快网络的收敛速度;条带池化有效改善深层特征复杂冬小麦分割效果和边界细节分割不精确;CBAM加强冬小麦的分割精度与边缘完整度;Focal Loss+Dice Loss组合更准确地衡量预测结果与实际结果之间的差别及处理类别不平衡和难样本的问题;GN结合条带池化后,MIoU明显提高了1.19%,有效地提高了模型的精度。同时,改进模型的MIoU、MPA和Accuracy分别达到93.66%、97.04%和98.17%,相较于原DeepLabV3+模型分别提高了5.22%、2.43%和2.77%。利用本文改进方法对夏张镇和徂徕镇冬小麦种植面积进行提取,错分、漏分现象明显少于原始模型,边缘划分的效果得到了进一步改善,将提取的夏张镇冬小麦面积与官方提供数据相比较,相对误差仅为-7.11%,精度较原始模型提高了1.56%。结合外业采样点计算提取精度,精度分别达到93.91%、92.31%,证明了改进模型对冬小麦提取结果的有效性。
