复杂交通环境下基于多任务学习的道路感知方法
2023-11-13黄崇栋刘云涛朱永东
赵 旋,黄崇栋,刘云涛,朱永东
(之江实验室,浙江 杭州 311121)
0 引言
随着自动驾驶行业的发展,全景驾驶感知系统相关算法的研究显得尤为重要,特别是在复杂交通环境下的高准确度实时道路感知一直是业界的痛点之一。通过摄像头提取到的图像数据信息,基于视觉的感知算法能有效提取到自动驾驶车辆所需要的道路信息,包括车道位置、道路是否可行驶等,而在复杂交通环境下,道路环境的信息会受到比较大的影响,如何在复杂交通环境下提高可行驶区域识别和车道线检测的性能和效率是规划车辆行驶路线的关键技术。
目前大多数对于车道线检测、可行驶区域识别的研究是独立进行的,例如ENet[1]和PSPNet[2]实现的可行驶区域识别算法,SCNN[3]和Lanenet[4]用于检测车道。对于自动驾驶领域来说,需要同时具备高精度和高实时性,然而在实际场景中计算资源往往是边际的、有限的,因此如何在保证高性能的同时高效地实现自动驾驶感知算法的应用具有非常大的挑战。
车道线和可行驶区域都属于道路信息,具有非常多相同或相关的特征信息,例如车道线必须存在于可行驶区域中,且可行驶区域的边缘很有可能存在车道线。因此,一个能够捕获这些关联信息的组织良好且统一的网络结构有望比单独的网络取得更好的效果,可以有效解决复杂交通环境下道路特征信息的损坏、缺失等问题。此外,统一的方法也将有利于计算效率,使其更容易部署在自动驾驶汽车的车载系统上。
在多任务联合网络研究领域,Mask R-CNN[5]被提出用于联合检测对象和分割实例,每个任务都达到了最先进的性能,但不能检测可行驶区域和车道线。MultiNet[6]通过一个架构进行联合分类、检测和语义分割,在多个任务中表现良好,但不支持车道线检测任务。
为了在保证高性能和高效率的同时,实现自动驾驶中车道线检测和可行驶区域识别,提出了一种复杂交通环境下基于多任务学习的道路感知网络(Multi-task Learning-based Road Perception Network in Complex Traffic Environment,MLRPNet)。MLRPNet主要提出了以下三方面的改进:对车道线和可行驶区域的道路特征信息进行共享,有效提高道路感知的准确率;采用Transformer的Encoder模块以提取特征图上对应车道线anchor的全局信息,提高了网络对车道线预测的拟合水平;结合空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)在语义分割领域的优势,将其用于可行驶区域识别中,可提高道路区域特征的提取,提高复杂交通环境下可行驶区域识别的精度和鲁棒性。
1 相关工作
经典的基于深度学习的车道线检测和可行驶区域识别算法大多数是独立算法,实际道路情况中,车道线和可行驶区域具有非常多相同或相关的特征信息,例如在图1中,可行驶区域的边缘一般为车道线,即一般情况下,车道线会包裹可行驶区域,如何利用二者之间的特征信息和道路关系实现复杂交通环境下的道路感知,并在保证准确率的情况下提高实时性是本文的研究重点。首先对这2个方向的算法做一些简单介绍,然后再介绍一些常见的多任务学习网络。

(a)模型输入图像

(b)车道线检测输出图像

(c)可行驶区域识别输出图像
1.1 车道线检测
在车道检测中,基于深度学习的研究有很多创新。Lanenet[4]构建了双分支网络,对图像进行语义分割和像素嵌入,进一步对双分支特征进行聚类,实现车道实例分割。PolyLaneNet[7]是一种用于端到端车道线检测估计的卷积神经网络(Convolutional Neural Network CNN),能够直接输出代表图像中每个车道标记的多项式。SCNN[3]提出了一种在特征图中的片连片卷积,使消息能够在像素之间跨行、跨列传递,但这种卷积非常耗时。文献[8]提出了一种新颖的基于锚点的注意力机制,该机制聚集了全局信息。
1.2 可行驶区域识别
在可行驶区域识别领域,一类是基于图像和激光点云数据融合的算法,此类方法能有效融合雷达和图像的数据特征,具有较高的识别准确率。SNE-RoadSeg[9]对深度图的法向量和图像融合,能有效获取空间结构信息。PLARD[10]对点云梯度图和RGB图像信息进行融合,实现了性能最优的方案。另一类是基于纯图像的算法,由于深度学习的快速发展,许多基于CNN的方法在语义分割领域取得了巨大的成功,它们可以应用于可行驶区域识别任务,提供像素级的结果。FCN[11]第一个将全卷积网络应用到语义分割领域,但其性能受到了低分辨率输出的限制。PSPNet[2]提出了金字塔池化模块,用于提取不同尺度的特征,提高性能。在提升算法效率方面,ENet[1]通过减小特征映射的大小实现推理的实时性。
1.3 多任务网络
多任务学习的目标是通过多个任务之间的共享信息来学习更好的表征,特别是基于CNN的多任务学习方法也可以实现网络结构的卷积共享。Mask R-CNN[5]是在Faster R-CNN[12]的基础上进行了扩展,增加了预测目标掩码的分支,将实例分割和目标检测任务有效地结合在一起,这2个任务可以相互促进性能。LSNet[13]将目标检测、实例分割和姿态估计总结为位置敏感视觉识别,并使用统一的解决方案来处理这些任务。MultiNet[6]通过一个共享的编码器和3个独立的解码器,同时完成场景分类、目标检测和驾驶区域分割3个场景感知任务。DLT-Net[14]继承了编码器-解码器结构,并在子任务解码器之间贡献构建上下文张量,以在任务之间共享指定信息。
2 基于多任务学习的道路感知网络
自动驾驶中的道路感知任务包括车道线检测与可行驶区域识别,在DLT-NET[14]中提到可行驶区域与车道线之间具备部分共同的特征信息。利用多任务学习能将2种感知任务结合,通过共享一部分特征信息来提升2种任务的感知准确率,尤其针对复杂交通环境下存在的道路信息干扰、遮挡,光照过亮、过暗或不均,大雾大雨等视线受损的情况,能够通过特征信息共享的方式得到一定的优化。多任务学习的道路感知避免采用2类模型分别解决感知问题,提高了感知任务的效率。
2.1 特征提取
复杂交通环境下基于多任务学习的道路感知算法的网络结构如图2所示,采用硬约束的多任务学习方法,车道线检测与可行驶区域识别共用一个特征提取的ResNet34主干网络,主干网络由4个残差块与首尾的池化处理构成。通过共享特征提取的底层参数,联合多个相关任务,一方面可以降低模型的过拟合风险,另一方面通过特征信息的互补可以有效提高复杂交通环境下特征缺失、受损时的特征提取能力。独立的检测输出层所应对的车道线检测与可行驶区域识别任务处理的场景数据具备图像的空间特征信息一致性,可行使区域同样是车道线的所在区域,且存在边界的对应关系。共享主干网络能提高模型对特征的学习能力。
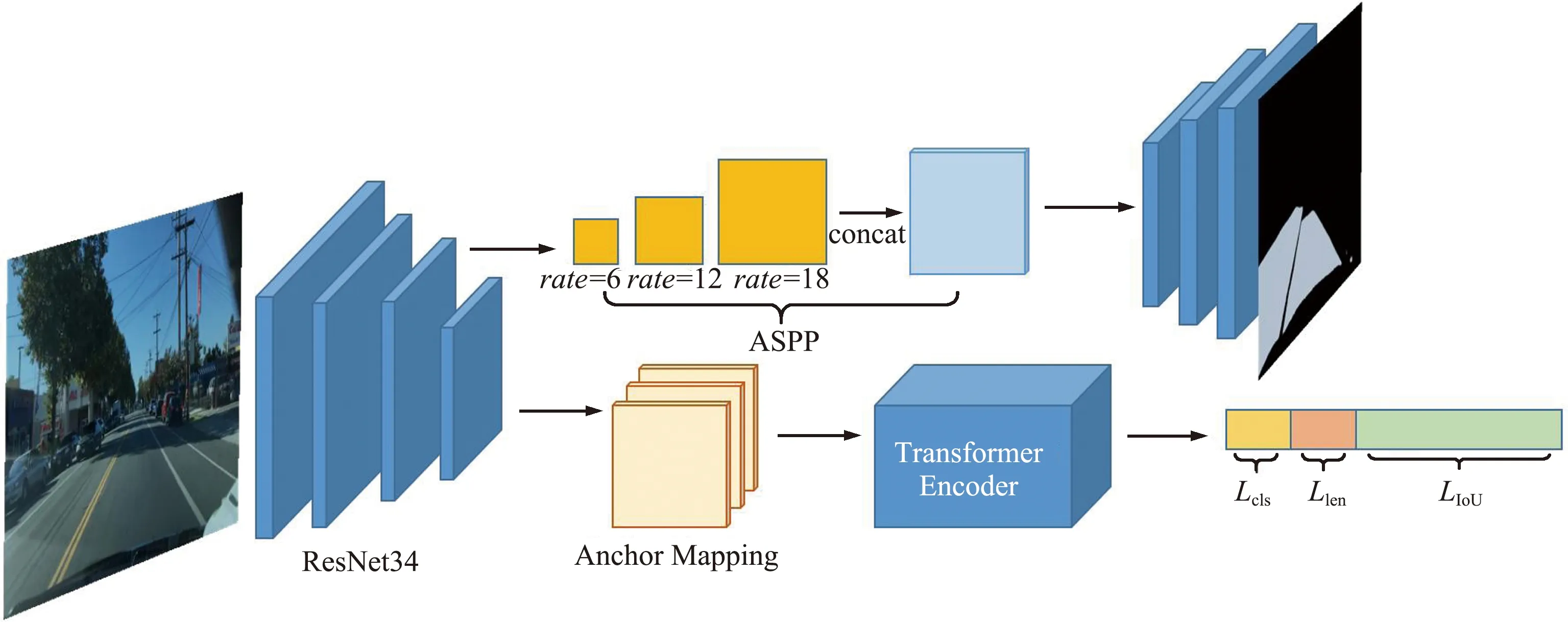
图2 基于多任务学习的道路感知算法网络结构Fig.2 Architecture of MLRPNet
2.2 车道线检测
经过主干网络ResNet34提取到特征信息后,模型输出层分为2路,各自对应一类感知任务。车道线检测模块采用基于行锚点(Line-Anchor,LA)的检测方法,车道线的锚点设计沿用Line-CNN[15]的设计方式,利用对数据的先验知识,仿照车道线的射线形态,分别从图像的底边与左右两边上均匀取数个点,对每条边规划一组方向角,左边界取(0°,90°),右边界取(90°,180°),底边取(0°,180°),3条边上每个点沿各自的方向角分别构造射线,即得到车道线的车道线锚点组。通过一个锚点映射(Anchor Mapping,AM)模块可以得到锚线在特征图上的映射,对每个起始点(xorg,yorg)以及发散角θ,其在特征图上的特征点(xi,yi)表示可由式(1)确定:
(1)
基于车道线锚点的检测方法能加速学习过程,避免预测结果产生较大波动,使模型专注于提高对车道线预测的拟合水平。
复杂交通环境场景通常存在大量的车辆、行人及非机动车,会对车道线产生遮挡覆盖等。此外,道路线标志会随着时间推移而发生缺损,或是由于夜晚、柏油路反光以及恶劣天气等外界因素而模糊,导致通过图像对复杂场景的道路线进行检测更具挑战性。为了解决遮挡、覆盖及光照条件等复杂场景下难以检测的问题,基于多任务学习的道路感知算法采用Transformer[16]的编码器模块以提取特征图上对应车道线锚点的全局信息。本文采用的Transformer的编码器模块核心是一个带有4个输出层的多头注意力层,用以计算上一层输出的车道线特征之间的关联信息。将Transformer的输出分别做回归与分类计算,分类层区分特征是否为车道,其输出记为cp;回归层计算预测车道线相对于车道线锚点的水平偏移以及预测线的长度,其输出记为xp和lp。

(2)
式中:N为点集内的总点数,w为近点车道的偏移范围,b为远点车道的固定偏移范围。
网络的总损失由车道类别损失、长度计算损失以及IoU损失共同组成,即:
Llane=λLcls(cp,cg)+Llen(lp,lg)+μLIoU(xp,xg),
(3)
式中:λ和μ为损失的平衡系数。
2.3 可行驶区域识别
复杂交通环境下会存在道路特征信息磨损、缺失的情况,导致可行驶区域识别过程中出现目标丢失、目标识别错误等问题。针对此类问题,基于多任务学习的道路感知方法采用基于空洞卷积计算的ASPP的可行驶区域识别网络进行区域分割。分割任务对分辨率有较高要求,通常会对特征图进行上采样以满足分割需求,但上采样过程计算量较大。为了解决分辨率需求与计算效率的问题,DeepLabV2[18]提出了一种使用空洞卷积计算的ASPP模块对特征图进行处理,可以在不下采样的情况下增加网络的感受野,从而增加网络获得多尺度感受野的能力。采用ASPP模块能够在扩大感受野的同时,通过堆叠不同权重间隔的空洞卷积结果,得到具备全局信息且维持较高分辨率的特征。
可行使区域分割模型引入ASPP模块对特征图进行处理,一方面可以提高计算效率,另一方面通过提取到的全局特征信息提高复杂交通环境下可行驶区域特征提取的精度和鲁棒性。网络的输入同样为特征提取网络的输出,得到的特征图再输入到ASPP模块,分别由6、12、18的空洞系数rate进行卷积,得到3种不同感受野下的空洞卷积特征,堆叠后输出到分割模型的解码器中,示例如图3所示。
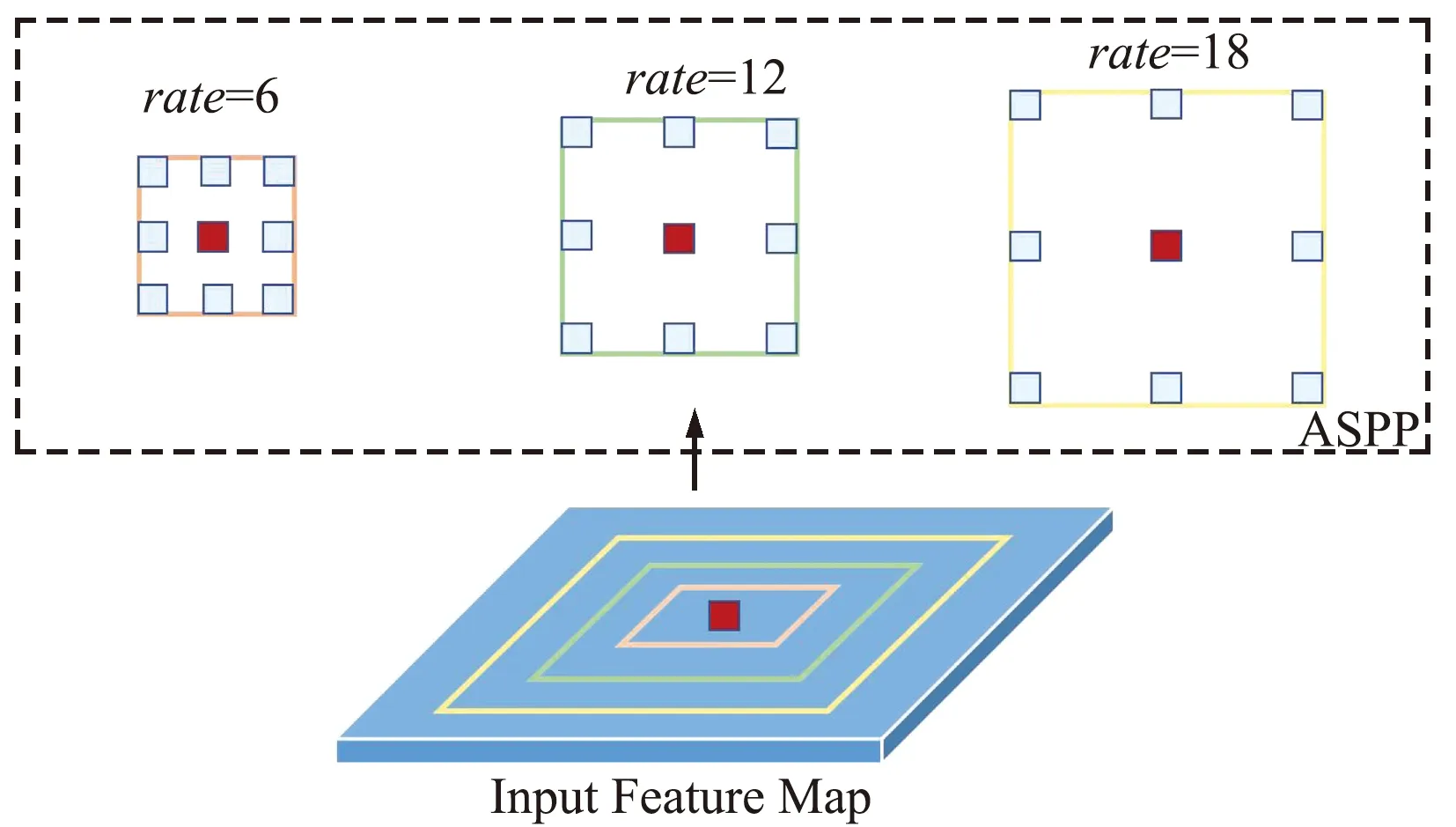
图3 ASPP模块示意Fig.3 Schematic of ASPP module
经过ASPP模块处理后的特征再通过解码器做上采样,得到维度为(w,h,2)的分割结果Segpred,其中(w,h)是输入图像的原始宽高,Segpred表示原尺寸图上每个像素点是可行驶区域或背景的概率。损失函数计算输出图上像素与目标之间的分类误差,采用交叉熵损失,即:
Ldrive=Lce(Segpred,Segtarget),
(4)
式中:Segtarget表示可通行域分割的目标结果图。
3 实验结果与分析
3.1 数据集和网络训练环境配置
BDD100K[19]是自动驾驶领域一个包含道路目标、车道线和可行驶区域的公开数据集,也是目前计算机视觉领域规模最大、最多样化的开源视频数据集。数据集由100 000个视频组成,每个视频大约40 s,720P,30帧/秒,涵盖了不同的天气状况,包含晴天、阴天和雨天以及在白天和黑夜的不同时间。数据集进行了图像标记、道路对象边界框、可驾驶区域、车道标记线和全帧实例分割。表1给出了BDD100K数据集和当前主流交通领域数据集的对比。
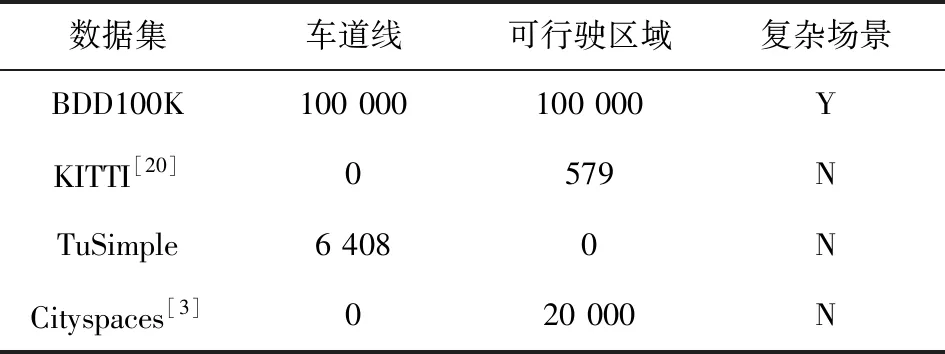
表1 交通领域不同数据集比较Tab.1 Comparison between different datasets
从表1可以看出,BDD100K不但具有数量庞大的数据,同时包含车道线数据和可行驶区域数据而且还具有更多的复杂场景,包括不同城市、不同天气和一天的不同时间段等。实验将在该数据集上对本文算法和对比算法进行测试对比。
网络的输入数据维度为1 280×720×3,经主干网络提取后得到32倍降采样下的512维特征图。Transform Encoder设置检测头为4,激活函数采用ReLU。实验共设置40个epoch,Batch Size设为8。实验使用 Pytorch 库在 Python 上实现,并在GPU环境为NVIDIA GTX TITAN Xp的服务器上进行训练测试。
3.2 测试结果
3.2.1 车道线检测
在BDD100K数据集上对包含可行驶区域识别模块在内的多任务道路感知模型进行了测试,测试结果如表2所示,其中Accuracy=Npred/Ngt,Npred表示预测正确的车道线点数,Ngt表示Ground-truth车道线点数。由表2可以看出,联合可行驶区域的多任务学习显著提高了模型的车道线检测准确率,准确率较ENet[1]等提高了30%,稍低于YOLOP[21],但检测速度更快,在提高检测准确率的同时保证了检测效率。

表2 BDD100K车道线检测结果对比Tab.2 Comparison of lane detection results on BDD100K
测试数据集上的车道线检测结果可视化如图4所示,测试数据的可视化结果分为白天光照充足路段以及夜间光照不足路段。由可视化测试结果图可以看出,本文的车道线检测方法能够在城市道路内对不同光照条件下场景的车道线准确检测。

(a)白天路段
3.2.2 可行驶区域识别
在训练测试中将BDD100K数据集中的“area/drivable”和“area/alternative”两类都归为“drivable area”。本文模型只需要区分图像中的可行驶区域和背景。可行驶区域识别的可视化结果如图5所示。与车道线检测划分相同,可视化结果测试数据同样分为白天光照充足路段以及夜间光照不足路段。

(a)常规场景
与经典算法的对比测试结果如表3所示。可行驶区域识别使用平均交并比(mIoU)来评估模型的分割性能,mIoU表示所有类别交集和并集之比的平均值。
由表3可以看出,MLRPNet的mIoU比MultiNet、ERFNet、DLT-Net和PSPNet分别高出19.7%、 22.6%、19.2%和1.7%,比YOLOP略低,但推理速度比YOLOP略高,在保证性能的同时提高了效率。

表3 可行驶区域识别结果对比Tab.3 Comparison of drivable area segmentation results
4 结束语
本文分析了在复杂交通环境下道路感知领域内的车道线检测与可行驶区域识别任务的共同点,针对感知任务独立训练推理效率低、无法利用共同场景信息的问题,利用2类任务之间存在的关联,设计了基于多任务学习的道路感知算法。由于车道线与可行驶区域在图像上的重叠,2类任务具备同样的感兴趣区域,通过共享一个特征提取的主干网络参数使模型快速学习有效特征。同时针对可行驶区域在复杂交通环境下特征提取困难的问题,采用ASPP模块提高特征缺失、特征受损时的特征提取能力,另外车道线检测分支则采用线型锚点做特征映射,通过基于Transformer编码器模块提取全局信息。在BDD100K数据集上进行的车道线检测与可行驶区域识别任务的测试实验表明,2类任务共同学习能够显著提高准确率,同时达到了较高的推理速度,提升了任务处理效率。
