基于XGBoost 模型的三峡库区燕山乡滑坡易发性评价与区划
2023-11-11吴宏阳周超梁鑫袁鹏程余蓝冰
吴宏阳,周超,2,梁鑫,袁鹏程,余蓝冰
(1.中国地质大学(武汉)地理与信息工程学院,湖北 武汉 430078;2.三峡库区地质灾害野外监测与预警示范中心,重庆 404199;3.中国地质大学(武汉)工程学院,湖北 武汉 430074)
0 引言
滑坡作为我国主要的地质灾害类型,具有分布地区广、发生次数多、威胁严重等特点[1],对国民经济建设和自然资源可持续利用造成了不可估量的破坏。由于复杂脆弱的地质环境,三峡库区是全国滑坡发生最多、经济损失最为严重的地区之一[2]。自2003 年蓄水以来,三峡库区新滑坡的发生和老滑坡的复活明显增多[3-4]。目前,库区内共有滑坡4,664 个,其中674 个有明显变形特征[5]。因此开展定量化的滑坡灾害空间预测与精细化风险评价研究十分必要。
滑坡易发性建模的本质是研究滑坡灾害在地质、环境及人类工程活动等因素影响下发生的空间概率[6],准确、可靠的评价结果能为风险防控措施的制定提供可靠的科学依据。近几十年来,国内外学者开展了大量滑坡易发性建模研究,主要包括知识驱动模型和数据驱动模型[7-11]。随着对地观测技术的发展,高质量的区域滑坡数据获取成为可能。由于相对简单的操作和可靠的性能,数据驱动模型逐渐在滑坡易发性评价中受到欢迎,主要可以分为数理统计模型[12-14]和机器学习模型[15-16]两类。由于具有更强的非线性预测能力,机器学习模型在易发性建模中表现出更高的预测精度,常用的算法有人工神经网络[17-18]、支持向量机[19-20]、决策树(decision tree,DT)[21-22]等。
DT 是一种经典的树型结构分类算法,由于计算速度快、训练简单、便于理解和解释性好等优点被广泛运用,但在训练过程中易产生较复杂的模型,导致数据泛化能力差,出现过拟合情况,甚至微小的数据变化也会导致预测结果出现较大偏差。相比而言,基于DT 和Boosting 集成的梯度提升树模型(gradient boosting decision tree,GBDT)引入随机性,降低模型过度训练的可能性,能够较好地拟合多维复杂数据,并在相对短的时间内对海量数据得出较好的结果[23],但模型仍存在损失函数难收敛和难以处理特征缺失样本等问题。极致梯度提升模型(extreme gradient boosting,XGBoost)是在GBDT 基础上进行优化得到,通过在GBDT 损失函数中加上正则项和二阶导数来降低模型运行复杂度以及权衡模型方差,从而学习出更简单的模型,并进一步防止模型过拟合。在处理特征值有缺失的训练样本时,XGBoost 还可以自动学习并拟合出数据的分裂方向。由于XGBoost 具备预测精度高、稳定性好等特点,现已被广泛地应用到医学预测、电力估计等领域[24-27],而在滑坡易发性评价领域运用较少。
本文以三峡库区万州区燕山乡为研究区,选取坡度、工程地质岩组、堆积层厚度等九个指标因子构建易发性指标体系,应用信息量模型定量分析各指标与滑坡发育关系;分别采用XGBoost、GBDT 和DT 对研究区开展易发性评价研究,并从预测精度和稳健性方面对模型性能进行综合对比分析。
1 方法原理
1.1 决策树模型
决策树模型是一种对实例进行分类的树形结构,决策树由节点和有向边组成,其中内部节点代表一个特征或者一种属性,叶节点代表类别[28]。在模型运算过程中,首先将实例从根节点开始排列,然后将属性和特征在中间节点根据特定规则分割为两个子集,直到在叶节点得到两个分类结果(图1)。其中基尼系数构成根节点到叶子节点的分类规则序列,基尼系数值越小,代表构建分类标准越好,最终的分类结果精度越高。
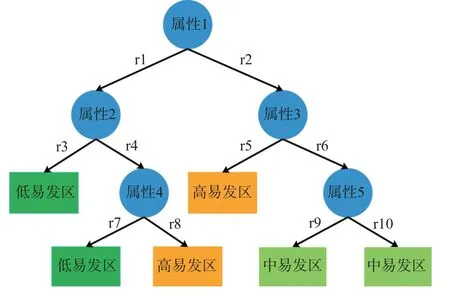
图1 决策树模型流程图Fig.1 Flowchart of decision tree model
1.2 梯度提升树模型
梯度提升树模型是一种常用的树形模型,采用Boosting 方法将多颗决策树进行关联,新决策树的生成是在上一棵树损失函数的梯度下降方向,通过不断迭代来优化模型[29](图2)。
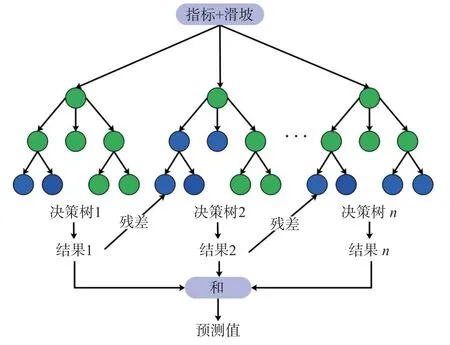
图2 梯度提升树模型流程图Fig.2 Flowchart of gradient boosting decision tree model
设训练样本为xi,初始损失函数F0为:
式中:xi——训练样本。
利用生成的决策树hj(xi)去拟合损失函数的梯度下降方向,使损失函数得到第j轮的最佳拟合值rj:
并利用损失函数对模型进行更新,得到最终预测结果计算函数为:
FM为单颗决策树预测结果,将多棵决策树预测结果求和可得到梯度提升树模型最终预测结果。
1.3 极致梯度提升模型
XGBoost 是一种基于GBDT 的模型,其模型结构与GBDT 类似,都是以决策树为基础,通过不断迭代,集成弱分类器为强分类器。随着模型迭代次数的增多,预测精度也会不断提高,计算流程如图3 所示。与GBDT 不同的是它在损失函数中加入了二阶导数hi和正则项 Ω(fk)来对每一轮的目标函数进行优化,目标函数值越小,则树结构越好[30-31]。
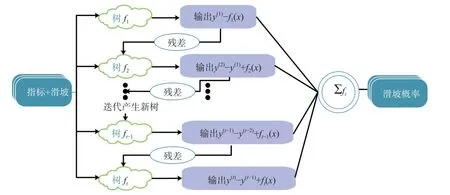
图3 极致梯度提升模型流程图Fig.3 Flowchart of extreme gradient boosting model
为了求得最小化目标函数,分别进行二阶泰勒展开、正则化项展开来合并一次项系数和二次项系数,经过多轮迭代后得到最终预测结果计算公式为:
f(x)——其中一棵回归树;
Ω(fk)——第k棵树的正则项。
2 研究区概况与数据准备
2.1 基本概况
燕山乡位于三峡库区万州区西南部长江右岸,面积约56.93 km²。燕山乡属构造剥蚀中浅切割丘陵河流地貌,地势东高西低,海拔范围在120~1 430 m。区内地形总体向西倾向长江,多形成单倾斜坡地形,长年受雨水冲刷切割形成纵向凹槽、冲沟、溪流,汇集于长江。燕山乡年平均降雨量为1 193.3 mm,日最大降雨为243 mm,最大连续降雨量为488.7 mm,夏季大雨、暴雨频繁,极易诱发滑坡灾害。区内共发育滑坡灾害33 处,其中小型滑坡6 处,中型滑坡22 处,大型滑坡5 处。研究区地理位置及滑坡分布如图4 所示。
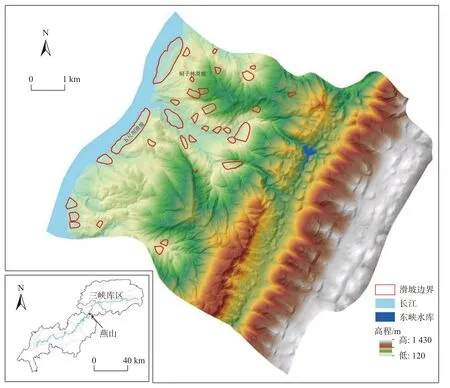
图4 研究区位置及滑坡分布Fig.4 Location of the study area and distribution of landslides
研究区位于方斗山背斜西侧,区内地层岩性复杂,主要出露地层为侏罗系新田沟组、自流井组、珍珠冲组和三叠系巴东组、嘉陵江组、大冶组,岩性为砂岩夹泥岩、泥岩、页岩和灰岩等。区内堆积层整体较薄,多分布于河谷斜坡、山顶侵蚀平台之上。河谷地带多为冲洪积亚黏土、砂土、含土卵砾石等,局部具二元结构,而山间斜坡地带主要为残积、坡积、崩积等重力堆积的含碎石土,总体上,区内堆积体结构松散,孔隙发育,为堆积层滑坡发育提供充分条件。随着社会经济的快速发展,频繁的人类工程活动(如G69 高速公路等)对周边自然环境造成了影响,特别是三峡库区周期性蓄降水,造成了许多老滑坡的复活及稳定斜坡的变形。
2.2 滑坡编录数据
基于历史滑坡编录数据、影像信息和野外实地调查建立研究区滑坡灾害编录数据库。根据野外实际调研结果,研究区滑坡主要诱发因素有大气降雨、人类工程活动、水库蓄水等。其中沙榜咀滑坡在暴雨和连续强降雨下发生变形,大量雨水汇集,一方面加强了地下水入渗,使滑体本身的重量变大,另一方面当雨水入渗到滑动面,也减弱了滑带土的抗剪强度,增加了滑体的下滑力。桐子林滑坡滑体物质为大量后期人工生活及建筑堆积物和崩积含碎块石粉质黏土;五尺坝滑坡为区内典型的受库水位影响的库岸滑坡,其中前缘以滑塌变形为主,受到库水位浸泡和侧向冲刷是诱发滑坡前缘变形的主要原因。研究区滑坡从发育平面形态特征来看,共发育舌形滑坡16 个,箕形滑坡7 个,扇形滑坡5 个,横长形滑坡3 个,不规则长条形滑坡2 个。从发育剖面形态特征来看,直线形所占比例最大,其比例为91%,圆弧形较少分布,其比例为9%。整体来看,研究区滑坡在东西方向数量分布存在明显差异,且东西方向上堆积层厚度、坡度、工程地质岩组等指标存在明显差异,根据主要诱发因可分为受水库波动影响较大的缓倾角堆积层滑坡和受降雨影响较大的陡倾角堆积层滑坡(图5)。

图5 典型滑坡全貌图Fig.5 Overview of typical landslide
2.3 易发性评价指标体系
影响滑坡发育的指标因子主要包括有地形地貌、地质条件和人类工程活动等[32]。在前人对万州区进行滑坡易发性评价基础上[33-35],考虑研究区地质背景、滑坡形成条件及其发育特征,并根据野外实际调研中,研究区东西方向地理条件差异鲜明情况,选取土地利用、斜坡结构、岩组、坡度、距长江距离、堆积层厚度、植被归一化指数、斜坡形态、汇水面积九个指标因子构建研究区易发性评价指标体系。为了判别指标之间相关性密切程度,利用ArcGIS 中波段集统计工具检验各指标因子之间的相关性,结果显示各指标因子之间相关性皆小于0.4,表明指标因子之间呈弱相关性或不相关(图6),可用作研究区滑坡易发性评价建模,各因子指标分级情况如图7 所示。
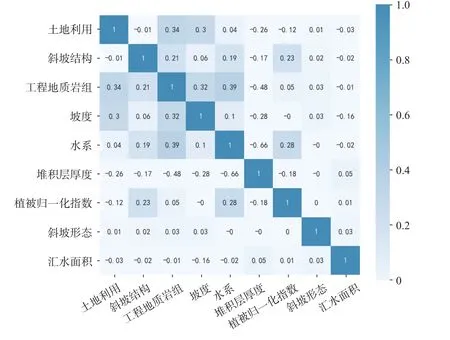
图6 指标相关性Fig.6 The correlation plot of Indicator factors

图7 研究区易发性评价指标图Fig.7 Indicator plot for landslide susceptibility assessment in the study area
3 滑坡易发性建模
3.1 模型建立
将指标因子作为模型输入数据,滑坡预测相对概率作为模型输出进行易发性建模。随机选择70%的滑坡和相同数量的非滑坡数据作为训练数据,剩余30%滑坡数据则作为验证数据[36]。
为了保证模型在对比时达到一个较优的状态,需要对各个模型进行调参。最大叶子节点数是决策树模型主要影响参数,通过试算法确定叶节点个数。如图8(a)所示,DT 模型的预测精度随着最大叶子节点数的增大呈现出上升趋势,当叶子节点数目达到160 时,预测精度达到峰值,呈稳定状态,因此设置决策树模型最大叶子节点数目为160。
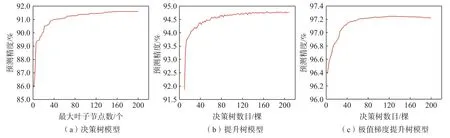
图8 参数与预测精度关系曲线Fig.8 Relationship curve between parameters and prediction accuracy
GBDT 和XGBoost 为集成树模型,主要通过创建新决策树,由多颗决策树的预测值得到最终结果,而影响集成树模型精度的主要参数为决策树数量。一般来说,模型决策树数量较小时,容易欠拟合,而决策树数量过多,计算量快速增加,且决策树数量增加到一定时,模型逐渐趋于稳定,预测精度不会随决策树数量增加出现大幅度变动[37]。同样采用试算法来确定适合模型的决策树数量,GBDT 和XGBoost 模型中决策树数量和预测精度的关系曲线分布如图8(b)和图8(c)所示。可以看出GBDT 和XGBoost 在决策树数量分别大于145 和大于75 预测精度无明显提升,且趋于稳定,因此设置GBDT和XGBoost 决策树数量分别为145 和75,此时最大决策树深度为7,能够最多生成的叶子结点数为49。此外,设置XGBoost 学习率、L1 和L2 正则项权重分别为0.1、0 和1。
将评价指标输入到训练好的DT、GBDT 和XGBoost模型中,计算研究区滑坡易发性相对概率值,并分为四个易发性等级区间,分别为低(77%)、中(7%)、高(7%)和极高(9%)。结果如图9 所示。
3.2 结果对比与分析
3.2.1 滑坡空间发育规律分析
信息量模型是一种二变量统计方法,统计结果能够很好地表征影响因素对滑坡空间发育的影响作用与程度。信息量值为正,说明指标对滑坡发育有促进作用;信息量值为负,则说明有抑制作用,且绝对值越大表明作用越强,各评价指标的信息量计算结果如表1 所示。影响区内滑坡发育的主要指标有距长江距离(0~400 m)、堆积层厚度(>2.4 m)和工程地质岩组(砂岩夹泥岩和砂岩),信息量值分别为2.96、2.54 和1.58。受三峡水库蓄降水的影响,研究区长江沿岸滑坡面积约占总滑坡面积的53%,并且长江支流附近水系发育,受各类水流的长期侵蚀和冲刷,斜坡整体稳定性低;研究区第四系堆积层厚度大于2.4 m 的区域主要在冲沟和长江沿岸,此类斜坡土体结构松散,吸水能力较强且持水能力差,在降雨诱发下快速形成暂时的饱水带,易失稳滑动;区内泥岩风化程度高,结构破碎,在降雨等不利条件下极易失稳滑动。
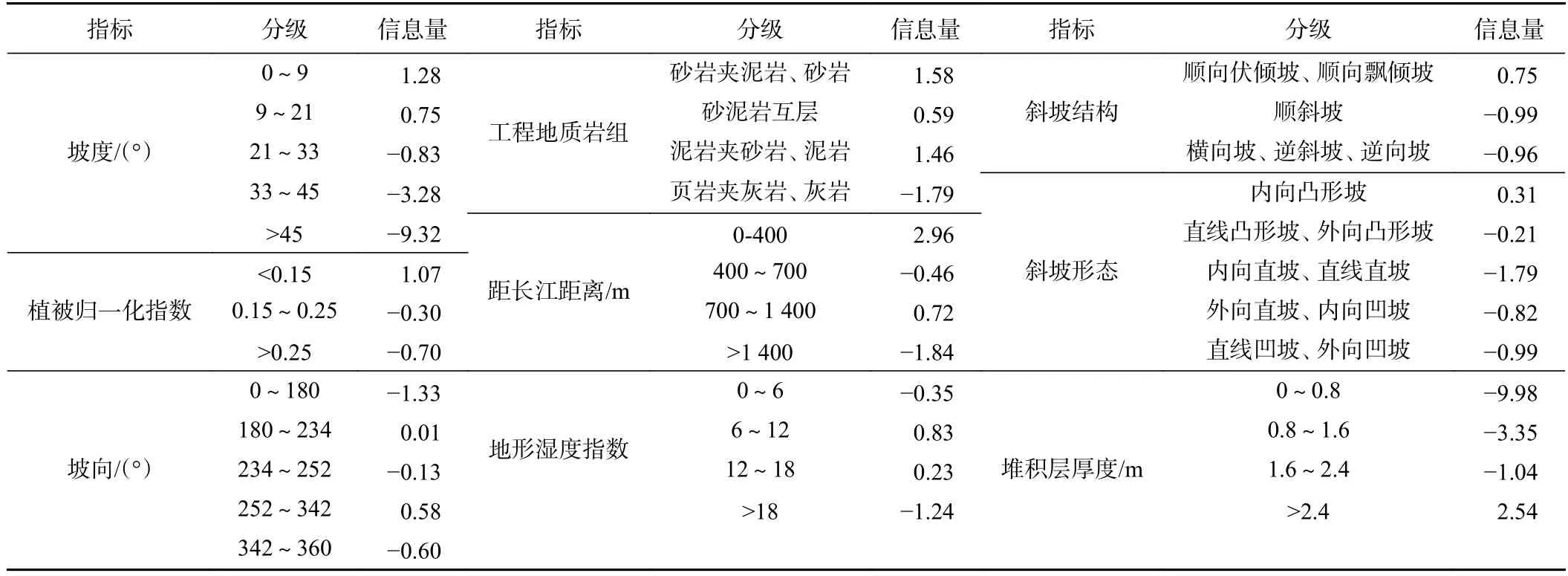
表1 各因素状态信息量表Table 1 The weighted information values of each factor state
3.2.2 模型性能分析
滑坡比率为该易发性等级滑坡栅格点数量占总滑坡栅格点数量之比与分级栅格数占研究区栅格数之比的比值。统计各模型滑坡比率,各模型滑坡比率皆是从低易发性到极高易发性依次增大,且在极高易发区滑坡比率最高。XGBoost 极高易发性等级的滑坡比率分别10.19,高于为DT 和GBDT 的8.07、8.59。准确率为分类正确的滑坡样本个数占总滑坡样本个数的比例[38],通过计算得到各模型准确率分别为92.63%、93.13%和94.32%,表明XGBoost 预测结果准确性最高,优于DT 和GBDT(图10)。绘制全区受试者工作特征曲线(receiver operating characteristic curve,ROC)[39](图11),可以看出XGBoost 全区预测精度为0.973,优于DT 和GBDT。

图10 各易发区灾害点比例Fig.10 Proportion of disaster points in different susceptibility zones
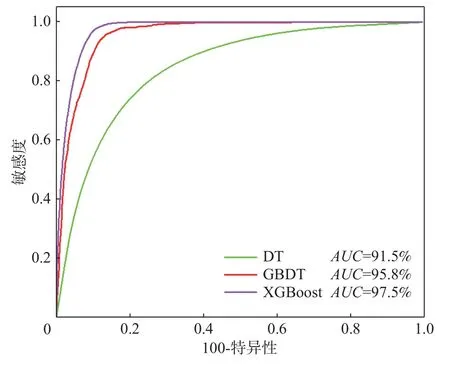
图11 模型 ROC 曲线图Fig.11 ROC curves of the different models
为进一步探究模型预测的稳健性,随机生成100 组试验数据进行滑坡易发性预测,得到预测精度和抽样次数关系曲线、标准差和变异系数如图12 和表2 所示。
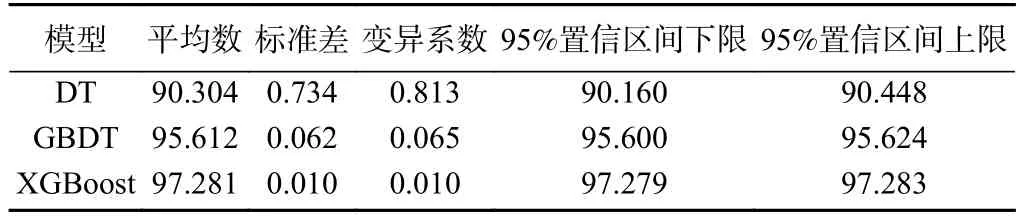
表2 标准差和变异系数Table 2 Standard deviation and coefficient of variation
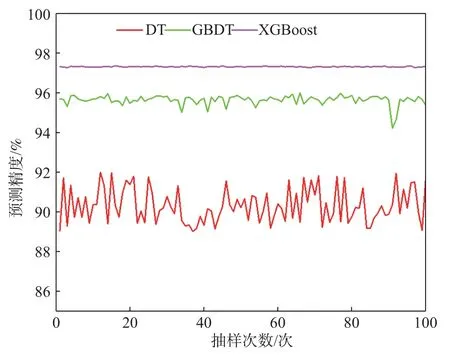
图12 抽样次数与预测精度关系曲线Fig.12 The correlation curve between sampling times and prediction accuracy
在多组抽样数据下,XGBoost 拥有最好的预测精度,且预测精度上下起伏不大,稳定性较好,预测精度平均值为97.28%,优于GBDT(95.61%)和DT(90.30%),其标准差为0.010,小于GBDT(0.062)和DT(0.734),变异系数为0.010,小于GBDT(0.065)和DT(0.813)。
4 结论
以燕山乡为例,选取坡度、工程地质岩组、堆积层厚度等九个影响因子构建易发性评价指标体系,应用信息量模型分析滑坡发育与指标之间的关系。研究结果发现:距长江距离(0~400 m)、工程地质岩组(砂岩夹泥岩、砂岩和泥岩夹砂岩、泥岩)和堆积层厚度(>2.4 m)是研究区滑坡空间发育的主要控制因素;燕山乡东部出露抗风化能力较强的灰岩且基本无第四系堆积物,不具备发育滑坡的条件,研究区西部长期受到库水位压力变化,斜坡失稳概率极大。因此研究区东部与西部地区之间滑坡易发性评价结果有明显的差异,与野外实际勘察情况一致。
通过对100 组训练/验证数据集开展易发性评价探究模型预测准确性、稳定性。结果表明XGBoost 模型的标准差和变异系数均为0.01,优于GBDT 和DT,说明该模型在多次重复中具有较好的稳健性。对评价结果进行验证得到准确率和预测精度分别为94.3%和97.3%,优于GBDT 和DT。DT 是一个训练简单、可理解性好的模型,但模型易过拟合且预测精度不高,通过模型集成的方法可以解决DT 易过拟合的不足;将DT 和Boosting 集成的GBDT 能够较好地拟合多维复杂数据并降低模型过拟合可能。为解决损失函数难收敛问题,在GBDT 基础上添加正则项和二阶导数的XGBoost 拥有模型稳定性和预测准确性。XGBoost 是一种优秀的滑坡易发性预测模型,具有较高的预测精度,并能为后续滑坡风险评价和分析提供技术支撑。
