改进路由机制的元学习少样本文本分类模型
2023-11-11荆沁璐胡议月
荆沁璐,冯 林,王 旭,龚 勋,胡议月
1(四川师范大学 计算机科学学院,成都 610101)
2(西南交通大学 计算机与人工智能学院,成都 611756)
1 引 言
随着深度学习的理论与技术的不断发展与进步,当前在文本分类领域[1]已经提出了很多性能优越的模型,并在日常生活、工业界等多个方面得到了广泛应用[2,3].但目前的深度模型都依赖于大量的标注数据,当数据量较少时难以高效地对数据进行分类.以电商评论情感分析为例,评论文本具有新流行用语多、缩略语多等特点,对于传统深度学习模型而言,文本分类模型可训练数据少,模型难以准确捕获语义特征,导致无法有效地进行分类.因此,如何在样本量少的情况下提升模型的预测能力成为了当前文本分类的热点问题,少样本学习(Few-Shot Learning,FSL)[4]可以利用少量样本使模型快速进行学习,从而提升预测能力.
目前,元学习(meta-learning)的理论与框架是少样本学习的重要应用场景,它希望模型具备类似人类解决问题的能力,即通过少量示范,可以学会对一类问题的解决方法.元学习不需要有太多的标注数据即可让模型快速“学会”适应新事物的能力.元学习以任务为基本单元,通过多任务的训练,使得模型能够学习到多任务的“元知识”,对于未解决过的新问题,可以利用“元知识”积累的“经验”快速适应到少样本的新任务上,没有必要重新收集大量数据进行标记并且训练新的模型.通过元学习的方法,可以较好的解决文本应用场景下缺乏已标注训练数据、包含大量参数的深度学习模型无法取得较好表现的问题,从而对标注样本少的文本进行高效分类.
当前,主流的元学习框架包括:基于度量的方法、基于优化的方法及基于迁移学习的方法.由于文本任务的特殊性,不同语境下的文本含义可能发生很大变化,因此,当前在少样本文本领域的研究多集中于基于度量的方法和基于优化的方法.基于度量的方法[5-7]首先将样本嵌入向量空间,学习样本特征表示,再采用度量模块来度量未标注样本与类原型的相似程度,从而对未标注样本进行分类.基于优化的方法[8,9]则关注于模型的参数优化策略,通过调整模型的初始化参数,使模型具有更好的泛化性,可以快速、准确的对未标注样本进行分类.然而,基于度量的方法未能解决类原型空间划分不当的问题,影响着模型的分类效果.
胶囊网络[10]可以一定程度上解决传统的卷积神经网络损失了部分特征间相对位置关系的问题,使用向量表示特征,旨在同时保存特征的位置信息和语义信息.胶囊网络提出了动态路由机制,通过计算低层胶囊与高层胶囊的相关性,动态地为低层胶囊分配权重,从而让高层胶囊较好地表示高层语义特征.Zhao等人[11]首次在文本分类中使用胶囊网络,证明了胶囊网络可以有效减少文本样本中的噪声干扰,提升分类准确性;程艳等人[12]提出文本情感分析胶囊模型,使用胶囊来表示文本情感信息,该模型可以有效提升模型泛化性和鲁棒性.
胶囊网络已经应用于文本处理领域,动态路由机制虽然可以捕获丰富的低层信息,但未能对噪声和重要特征进行有效区分,导致高层胶囊学习到的信息包含着大量噪声,表示能力差,同时,胶囊网络仅关注于同类低层胶囊与高层胶囊间的相关程度,忽视了低层胶囊在特征空间中的位置信息.而这导致胶囊网络难以解决少样本文本分类任务的几个关键问题:1)文本任务中包含噪声多,如“的”、“是”等词与文本所属类别无关,但出现频率高,对模型的分类结果有着较大影响;2)在少样本场景下每个文本类的样本点分布不均衡,易导致分类边界偏差.
为此,本文研究了胶囊网络的动态路由机制在少样本文本分类任务上的作用,基于度量学习的思想,提出一种改进路由机制的元学习少样本文本分类模型.本文提出了两种改进的路由机制来学习高质量的类原型表示,基于交互信息的路由机制(Cross Information augmented Routing,CI-Routing)建模同一类样本间的交互信息,并据此对重要特征进行加强,通过对共性信息的有效归纳和利用,减弱噪声对类向量的干扰,使类原型包含更加丰富的特征信息,泛化性更强;基于距离系数的路由机制(Distance Coefficient guided Routing,DC-Routing)重点关心样本在整体特征空间的位置关系,引入距离系数来表示样本与不同类原型的位置关系,通过微调不同样本的权重来更加合理地划分类原型边界.这两种路由机制从类内样本关系,类间样本差异两个角度出发,学习到高质量的类原型表示,最后,将两种路由机制学习到的类原型表示进行融合,并与未标注样本共同送入分类层来进行分类.实验表明,本文提出的方法可以显著提高模型预测能力.本文的主要贡献如下:
1)提出基于交互信息的路由机制,捕获同类样本间的交互信息,引导模型关注样本重要特征并进行加强,同时采用注意力机制分配权重,以学习到泛化性更好的类原型,减弱噪声带来的负面影响.
2)提出基于距离系数的路由机制,将每个样本在整个特征空间的相对位置关系量化为距离系数,指导权重的分配过程,缓解类内样本点分布不平衡导致的类原型偏移问题,提升模型分类能力.
3)将上述两种路由机制学习到的类原型向量进行融合,进一步提升类原型的表示能力.经过实验证明,本文提出的模型在HuffPost[13]、FewRel[14]、20News[15]3个数据集上具有更优的表现,验证了本文提出模型的有效性.
2 相关工作
2.1 少样本文本分类
少样本学习最初在图像领域提出,当前已经取得了较多的研究成果.随着文本分类任务中少样本场景日益增多,如网络新流行用语、缩略词、错别字等,已经有越来越多的学者针对少样本文本分类方法提出了新的模型.由于文本特征的特殊性,少样本文本分类任务上的研究多为基于度量的方法和基于优化的方法.
基于度量的方法将输入样本映射至同一特征空间中,学习同一类样本的原型表示,通过度量函数计算待分类样本与各类原型的相似度分数来进行分类.Snell等人[5]提出原型网络(Prototypical Network,ProtoNet),计算类样本的均值作为类原型,计算查询样本与类原型的欧式距离来进行分类;Sung等人[6]提出关系网络(Relation Network),使用卷积神经网络定义了一个度量函数来探索样本间的非线性关系,计算关系得分进行分类;Geng等人[7]提出归纳网络(Induction Network,InductNet),将胶囊网络用于少样本文本分类任务,利用动态路由机制来归纳学习高质量的类向量;Sun等人[16]针对少样本文本分类任务中噪声干扰而导致类原型辨别性弱的缺点,提出了层次注意力原型网络(HAPN),该模型在特征级别、单词级别、实例级别分别使用注意力机制来捕获重要信息,提升类原型的表示能力;Sui等人[17]借助外部知识库,检索与文本相关的知识,和样本共同参与模型的训练和学习过程,解决少样本文本分类任务中已标注样本少、可获取特征有限的问题.
基于优化的方法目的是让模型学习并利用“元知识”来引导模型快速学习新任务,其中典型的是Finn等人[8]提出的模型无关自适应模型(MAML),该算法首先初始化一组参数,并在其基础上并调整优化,使模型具有良好的初始化条件,从而提升模型的预测能力和泛化性;Zhang等人[9]提出了P-MAML模型,使用预训练模型Bert来表示文本特征,并和MAML算法相结合,使模型充分利用二者的优势,具有更好的泛化性和更优越的预测能力.
2.2 路由机制
在深度学习领域,路由机制往往伴随着胶囊网络出现.Hinton等人[10]在图像分类领域提出胶囊网络,使用胶囊代替传统神经网络中的神经元,通过向量来表示胶囊以保存丰富的信息.传统的神经网络通过学习参数及激活层进行计算,而在胶囊网络中,首先对输入向量进行矩阵映射得到预测向量uj|i,编码低层特征和高层特征间的空间关系,接下来使用动态路由机制来动态地为每个低层胶囊分配权重,最终加权求和得到高层胶囊.此外设计非线性压缩函数squash对高层胶囊的向量表示x进行压缩,其公式如式(1)所示:
squash(x)=φ(x)·ψ(x)
(1)
其中,φ(x)将向量x的长度压缩至[0,1]之间,ψ(x)的目的是保持其方向不变.动态路由机制相较于传统神经网络,不仅可以有效提升模型的预测能力,由于所需参数变少,胶囊网络也具有更快的运算效率.
目前,已经有一些研究学者对动态路由机制进行了研究,并提出了一些新的路由算法.Ren等人[18]结合聚类算法提出了K-means路由机制,通过调整权重更新方式使不同类别的共性特征有效链接到高层胶囊中,使路由机制更加健壮;Choi等人[19]提出注意力路由机制,使用卷积变换和注意力机制,该方法的预测能力优越,同时具有更快的收敛速度;Zhao等人[20]首次提出了无迭代的聚类路由算法,采用聚类投票的方式取代传统的独立投票,该方法具有更高的可信度,得到的高层胶囊具有更好的表示能力,由于该路由机制是无迭代的,模型的运算效率也得到了显著提升.
本文基于元学习的度量方法,结合动态路由机制可以灵活捕获样本间关系的优势,提出改进路由机制的元学习少样本文本分类模型,模型使用路由机制来学习泛化性强、辨别性高的类向量.与在文本处理任务上直接应用动态路由机制的方法相比,本文通过对动态路由机制作出两种改进,使模型可以更好地适应少样本文本分类任务的特色,具有更佳优越的表现.
3 建模与问题分析
3.1 问题定义

在元训练阶段,根据基类数据集Dbase构造N-wayK-shot元训练任务集Ttr,对于∀Tt∈Ttr,从基类Cbase中随机抽取N个类的数据,构造支持集St和查询集Qt,满足:


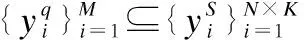
④Tt={(St,Qt)},St∩Qt=Ø
在元测试阶段,元测试任务与元训练任务构造过程基本一致,其区别在于元测试任务中假设查询集标签是不可见的,在新类数据集Dnovel上构造元测试任务集Tte,对于∀Te∈Tte,采用相同的方式构造支持集Se和查询集Qe,满足:


③Te={(Se,Qe)},Se∩Qe=Ø
其学习过程如下:


3.2 原型网络
原型网络[5]是一种经典的少样本学习模型,其示意图如图1所示.原型网络基于度量的方法,使用特征抽取网络将支持集的样本映射至特征空间中,得到样本特征表示xi,该方法认为每个类别在特征空间中都存在一个类别中心点,即类原型.原型网络以标签为依据,为每个类计算该类样本向量的均值作为该类别的原型表示pi.其计算公式如式(2)所示:

图1 原型网络Fig.1 Prototypical network
(2)
其中fξ(·)表示特征提取方法,ξ为模型参数.
当模型对查询集样本分类时,通过计算其与类原型之间的欧式距离作为分数进行分类,分数越小,表明该样本距离类原型越接近,属于该类的几率越大.通过不断训练模型,使同一类的样本更加接近,不同类的样本距离更远,更新特征抽取网络的参数.
3.3 问题分析
原型网络旨在使用均值类原型对每个类的特征信息进行归纳,但在少样本文本分类任务中,类原型易受到多方面的影响,进而导致原型空间边界产生偏差,模型预测结果不佳.
首先,文本样本中包含噪声多,文本中的关键信息对模型预测结果有着重要作用,原型网络认为样本的每个特征同等重要,导致模型易受到噪声干扰,难以捕获重要语义信息.其次,少样本任务中类内的样本点分布不均衡,对类原型的贡献程度也有所不同,原型网络则忽略了这一问题,未能关注到高相关性的样本.因此,如何减弱噪声的干扰、灵活地为各个样本分配权重成为原型网络亟待解决的问题.
胶囊网络的动态路由机制可以较好地建模样本间的关系,通过学习低层胶囊的权重,来获得包含丰富信息的高层胶囊.将动态路由机制与原型网络相结合,把样本点视作低层胶囊,类原型视作高层胶囊,根据每个样本的重要性学习高质量的类原型.由此可见,动态路由机制可以动态地为样本分配权重,将类原型的划分过程从“硬划分”转为“软划分”,使模型学习到更佳合理、灵活的分类边界.
4 改进路由机制的元学习少样本文本分类模型
4.1 基本思路与总体设计
为了提升原型网络在少样本文本分类任务上的表现,本文提出了一种改进路由机制的元学习少样本文本分类模型,通过对路由机制作出两种改进来学习高质量的类原型,合理划分原型空间.本文采用如下的思路设计整体架构,首先采用特征抽取网络及注意力机制挖掘样本的深层次特征关系,学习每个样本的向量表示,紧接着,将样本分别送入两种改进路由机制,为每个类从两个角度学习到两个类原型,最后,将两个类原型进行特征融合,计算类向量与查询样本的相似度分数,实现对查询样本的分类.
根据本文设计的基本思路,模型结构可分为以下3个部分:特征抽取层、路由层及分类层.以2-way 2-shot设定为例,模型结构如图2所示.
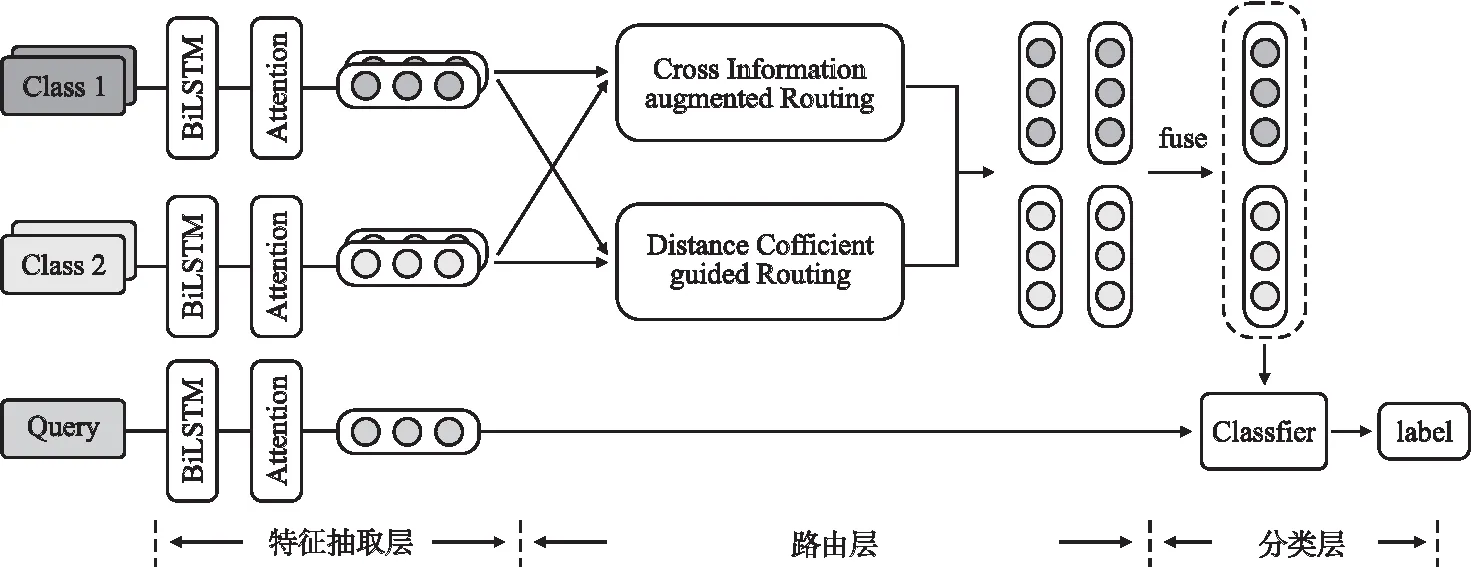
图2 模型结构图Fig.2 Overall structure diagram
4.2 本文模型
4.2.1 特征抽取层
在特征抽取层,本文使用了双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)[21]进行特征抽取,并结合自注意力机制分配权重,从而为每个样本学习包含丰富信息的样本表示.

注意力机制源于对人类视觉的研究,已在众多自然语言处理任务中得到了广泛应用.注意力机制可以有效捕获文本中单词的依赖关系,选择性的关注重要信息和忽略无关信息,通过为输入样本序列的各个单词分配不同的权重,使样本特征可以集中在重要性强的信息上.本文将H作为输入,使用注意力机制为其分配不同的权重α,其计算公式如下:
vi=tanh(W1H+b1)
(3)
(4)
其中,W1为可学习的参数矩阵,b1为偏置.
最终,根据关联程度为每个单词分配权重,从而生成包含丰富的语义信息样本表示x,计算公式如式(5)所示:
(5)
4.2.2 路由层
路由层的目的是为每个类的样本动态地分配权重,学习更具代表性的类原型,合理地划分原型空间.路由层包含两个改进路由机制,基于交互信息的路由机制(CI-Routing)关注于同类样本间关系,基于距离系数的路由机制(DC-Routing)则关注于不同类间样本的差异.这两种路由机制从两个角度出发学习类原型,实现对原型空间的“软划分”,提升类原型的表示能力.
1)基于交互信息的路由机制
为了削弱噪声对类原型的影响,本文提出了CI-Routing关注同类样本间的关系,通过捕获样本之间的交互信息,学习类级别的共性特征,并以此为依据加强与之具有高相关性的特征.此外使用注意力机制来为每个样本分配权重,使模型在计算类原型时,同时关注同类样本的交互性和独特性,从而提升类原型的泛化能力.其结构图如图3所示.
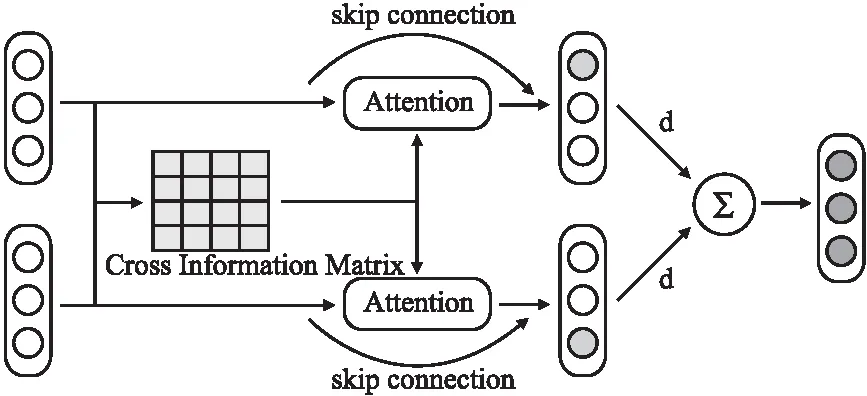
图3 CI-Routing结构图Fig.3 CI-Routing structure diagram
首先,对样本特征表示x进行矩阵映射,将样本映射到同一特征空间内,并使用压缩函数,得到低层胶囊eg,其计算公式如式(6)所示:
eg=squash(Wgx+bg)
(6)
其中,Wg为可学习的参数矩阵,bg为偏置.
针对同属于一个类的低层胶囊,根据式(7)计算样本共性特征矩阵O来表示同类样本间的交互信息.接下来,根据式(8)将低层胶囊eg与共性特征矩阵O进行矩阵乘法运算,建模低层胶囊特征与交互特征间的相关性,得到交互矩阵E,E中的每个值表示样本特征与共性特征的相关性,对矩阵E进行列式softmax操作,得到注意力得分γij,表示每个特征的重要程度,计算公式如式(9)所示:
(7)
E=eg·O
(8)
(9)
将γ与低层胶囊eg相乘后得到加权胶囊ng,可以有效识别出与类的共性信息具有高相关性的样本特征并加以关注,计算公式如式(10)所示.同时,利用残差模块,将加强后的胶囊与低层胶囊进行残差连接,得到最终胶囊mg.这样既对其重要特征进行了加强,又保持了各个样本的独特性,在加强胶囊表示能力的同时,有效避免了梯度消失等问题,计算公式如式(11)所示:
ng=eg·γ
(10)
mg=eg+tanh(W2ng+b2)
(11)
其中,W2是可学习的参数矩阵,b2为偏置.
本文为了更好的关注每个最终胶囊mg的特点,使用点积注意力机制为每个低层胶囊分配权重,注意力分数越高,表明该样本越重要.其计算公式如式(12)、式(13)所示:
bg=(Wqmg)T(Wkmg)
(12)
(13)
其中,Wq、Wk是随机初始化的参数矩阵.
最后,根据dg为每个样本分配权重,得到每个类的类原型,并使用压缩函数对其进行压缩.计算公式如下:
cg=squash(∑dg·mg)
(14)
2)基于距离系数的路由机制
Ren等人[16]提出将K-means算法引入动态路由机制,将相邻两层的动态路由机制看作是一个K-means聚类的过程,高层胶囊即为类的类中心.基于元度量的方法的核心思想即学习每个类的类中心作为类原型.由此,本文提出的DC-Routing采用K-means算法的思想,先计算初始类原型,再通过路由机制对权重进行调整,得到最终的高质量类原型.在传统方法中,仅通过计算样本与该类类原型间的相似程度来分配权重,忽略了不同类样本间的差异,但在少样本任务中样本点少且分布不均,样本在整个特征空间中的位置也值得重视.因此,DC-Routing关注于每个样本与所有类原型的相对位置关系,通过引入距离系数λ,赋予高辨别性的样本更高的权重,以实现对样本权重的微调.其示意图如图4所示.
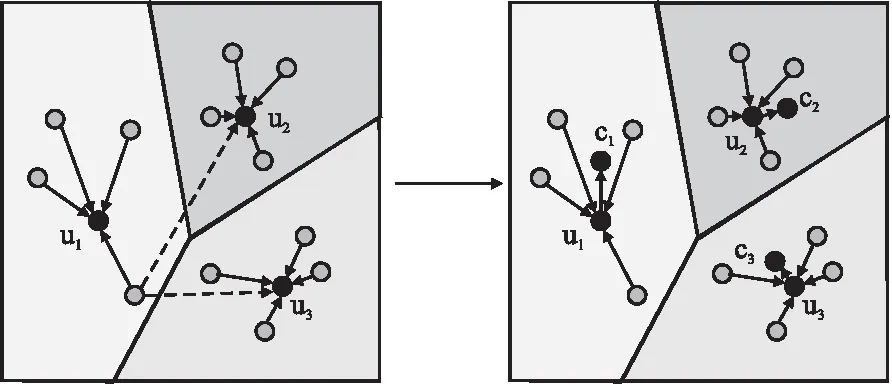
图4 DC-Routing结构图Fig.4 DC-Routing structure diagram
首先,对样本特征表示x进行矩阵映射,将其映射到同一特征空间内,得到低层胶囊er,并采用均值计算每个类的初始类原型ui,其计算公式如下:
er=squash(Wrx+br)
(15)
(16)
其中,Wr为可学习的参数矩阵,br为偏置.Si表示类别i的数据集合.
接着,计算样本与该类类原型的点积相似度作为低层胶囊的初始权重,代表样本在该类的重要程度,计算公式如公式(17)所示:
sr=er·ui
(17)
本文认为,对于那些与所属类具有高相关性、与其他类具有明显差异的样本,路由机制应当为其分配更高的权重,因此,引入距离系数λ来微调样本权重.首先,计算低层胶囊与每个类原型的欧式距离,来捕获样本与每个类原型的差距,其计算公式如下:
(18)
其中,er表示低层胶囊,ui表示类原型,n表示向量维度.
接下来,根据每个样本样本与各个类原型的欧式距离计算距离系数λ,其计算公式如式(19)所示:
(19)
其中,N表示该任务的类数量,disi代表低层胶囊er与该类类原型ui的距离,分子则表示低层胶囊与其他类类原型uj的平均距离.低层胶囊er与该类类原型距离越近,disi越小,λ越大,与其他类类原型差距越大,分子越大,λ越大.故本文使用距离系数λ来对每个低层胶囊的权重进行调整,其计算方式如式(20)、式(21)所示:
br=tanh(λ·sr)
(20)
(21)
最后,对每个低层胶囊加权求和,计算每个类的类原型,并使用squash压缩函数对其进行压缩,其计算公式如下:
cr=squash(∑dr·er)
(22)
4.2.3 分类层
在分类层,首先将CI-Routing和DC-Routing学习到的两种类向量进行特征融合,将二者学习到的信息相结合,从而提升类原型的泛化性和鲁棒性,采用的融合公式如公式(23)所示:
c=σ(τ·cg+(1-τ)·cr)
(23)
其中,σ为ReLU激活函数,τ为融合系数.
不同于使用传统的欧式距离进行度量,本文采用Socher等人[22]提出的网络(Neural Tensor Network,NTN)来对查询集样本xq进行分类.NTN采用双线性模型结构,将类原型向量ci和查询样本xq作为输入,对二者的相关性进行深层次推理,得到输出关系向量v,其计算公式如式(24)所示:
(24)
其中,Mk∈R2l×2l,l∈[1,…,h]是切片函数,σ为ReLU激活函数.
最后,将关系向量vq,i送入全连接层,计算查询样本xq与第i类原型ci的相关分数scoreq,i,分数范围在[0,…,1]之间,计算公式如式(25)所示:
scoreq,i=sigmoid(Wsvq,i+bs)
(25)
其中,Ws为可学习的参数矩阵,bs为偏置.
4.2.4 损失函数
将本文提出模型记为G(δ;·),其中δ为模型参数.本文使用交叉熵损失函数,其计算公式如下:
(26)
其中,Qi表示任务Ti对应的查询集,y′表示查询集Qi的真实类别,G(δ;Qi)表示模型对查询集Qi的预测结果.
4.3 算法描述
本文模型的训练策略如算法1.
算法1.模型训练策略
输入:训练数据集Dbase,其包含的可见类Cbase
输出:分类模型Ω
1. ForTiinTtr:
2. 随机抽取N个类别:C=Random(Cbase);
3. 创建支持集St和查询集:Qt;
4. 对St和Qt进行特征抽取,得到样本表示:
Hs,Hq=BiLSTM(St,Qt);
xs,xq=Attention(Hs,Hq)
5. 将支持集样本送入CI-Routing计算类原型:
6.将支持集样本送入DC-Routing计算类原型:
8. 对查询集样本进行分类:Y′=Classifier(ci,xq);
10. 通过损失L更新模型:δ←δ-η∇δL(δ)
11. END
12. 输出分类模型Ω
5 实 验
5.1 数据集
本文实验采用3个文本分类数据集进行实验,用来评估本文模型效果.3个数据集的分布情况如表1所示.
1)HuffPost数据集[13].HuffPost数据集为新闻标题分类数据集,其包含41个类别的新闻标题,其支持集、查询集、验证集的划分比例为20∶5∶16.
2)FewRel数据集[14].FewRel数据集为少样本关系分类数据集,其数据来源于维基百科,每种关系中包含700个实例,每个实例包括一个头实体、一个尾实体及二者之间的关系,本文将其按65∶5∶10的比例划分为支持集、查询集、验证集.
3)20News数据集[15].20News数据集是新闻文档数据集,文本长度较长,共包含有20个类.本文实验将支持集、查询集、验证集的划分比例设定为8∶5∶7.
5.2 实验环境与参数设置
本文的实验基于Linux操作系统和Tesla V100-32GPU平台,采用pytorch深度学习框架.
本文采用300维FastText词向量[23]作为词嵌入层,BiLSTM的隐藏层维度为128,注意力层维度为64,分类层网络的神经元数为100,融合系数τ设定为0.5.在训练过程中,采用了早停机制,使用Adam优化器,学习率为0.001,使用的dropout扰动系数为0.1.
本文的模型采用5-way 1-shot和5-way 5-shot两种少样本学习经典设定方式.以5-way 5-shot设定为例,每次随机抽取5个类的5个样本作为支持集,并在对应的5个类的剩余样本中采样25个样本作为查询集,即满足C=5,K=5,M=25设定.本文以模型的准确率指标为标准对模型的有效性进行定量评估.
5.3 实验结果与分析
5.3.1 与经典少样本文本分类方法的对比
为验证本文提出模型在少样本文本分类任务上的有效性,采用如下基线方法进行对比实验.
ProtoNet[5]:计算每个类的样本均值学习每个类的类原型,采用欧式距离作为度量分类器进行分类,是少样本学习的经典基线方法.
MAML[8]:训练一组初始参数,并在其基础上逐步进行梯度调整,使模型快速适应新任务,是一种经典的基于优化的方法.
InductNet[7]:针对少样本文本分类任务,使用动态路由机制归纳同类样本特征,学习泛化性更好的类原型.
P-MAML[9]:使用Bert预训练模型来充分捕获上下文信息,并结合MAML算法来解决少样本文本分类任务.
实验结果如表2 所示.

表2 与少样本文本分类方法的对比实验结果Table 2 Comparative results of different few-shot text classification models
1)定量评估
由结果看出,本文提出的模型相较于4个基线方法,在5-way 1-shot和5-way 5-shot两种设定上均有显著提升.与基于元度量的方法ProtoNet和InductNet对比,在5-way 1-shot下,本文模型在HuffPost、FewRel、20News 3个数据集上的预测准确率分别提升了3.7%/6.1%、11.2%/2.9%、2.1%/2.9%,基于5-way 5-shot设定,本文模型在3个数据集上提升了6.2%/3.8%、9.4%/9.8%、2.5%/5.9%.与基于优化的方法MAML对比,在5-way 1-shot设定下,本文提出的模型在HuffPost、FewRel、20News数据集上的预测能力分别提升了3.0%、9.5%、2.8%,在5-way 5-shot设定下,本文提出模型的预测准确率提升了2.0%、8.1%、0.8%.相比于P-MAML模型,在HuffPost数据集上,本文提出的模型在5-way 1-shot设定下的分类效果提升了6.1%,在5-way 5-shot设定下预测能力不如P-MAML模型.
2)定性分析
由表2结果及定量评估可知,相比于传统的少样本学习方法,本文模型可以针对性的解决文本处理任务中的难点,具有更好的预测能力;与基于度量的少样本文本分类方法inductNet进行比较,本文模型学习到了更佳合理、有辨别性的类原型,在1-shot和5-shot设定下均有更好的表现;与P-MAML方法相比,本文模型在1-shot设定上表现更优,表明基于优化的方法在处理样本量极少的任务时预测能力较为局限,而本文方法可以更好地学习不同类间样本的差异,从而有效处理1-shot设定下的分类任务,但在5-shot设定下,P-MAML方法可以学习到更加合适的参数,具有优秀的泛化能力,而本文模型表现较差.
由此可见,本文提出的模型基于度量学习的思想,结合两种改进路由机制来学习类原型,通过“软划分”的方式使类原型的划分过程变得更佳合理及灵活,与基线方法相比,有效提升了模型的预测准确率,使模型可以更好地解决少样本文本分类任务.
此外,本文提出的模型在FewRel和HuffPost数据集上准确率提升更为明显,分析认为,文本样本的长度会对模型的预测结果带来很大影响.由表1数据可知,20News数据集的样本平均长度为341,显著长于其他两个数据集,这要求模型有着更优的特征抽取能力,可以捕获文本中的长距离信息依赖关系.而本文模型在对长文本样本进行分类时未能很好地解决这一问题,预测能力还有待进一步提升.
5.3.2 与现有路由机制的对比
为了验证本文提出的两种改进路由机制的作用,本文在20News数据集上使用4种路由机制作为基线任务进行了对比实验.其中,3种迭代路由机制的迭代次数均按原文设置为3.
Dynamic Routing[10]:通过计算低层胶囊与高层胶囊的相似性对权重进行更新,是目前应用最为广泛的动态路由机制.
K-means Routing[18]:结合K-means算法的思路来计算每个低层胶囊的权重,同时降低使用压缩函数的次数来减弱信息的损失.
Attention Routing[19]:使用卷积变换和注意力机制进行权重分配,使高相关性的低层胶囊具有更高的权重.
Cluster Routing[20]:采用聚类算法,先对低层胶囊进行聚类,采取聚类投票的方式取代独立胶囊投票,并且该路由机制是无迭代的.
实验结果如表3所示.

表3 与路由机制的对比实验结果Table 3 Comparative results of different routing mechanisms
1)定量评估
根据表3结果可知,基于5-way 1-shot和5-way 5-shot两种设定,相比于经典动态路由机制Dynamic Routing,本文提出的CI-Routing的预测准确率提升了1.0%和4.1%,每次迭代花费时间减少了3.2s和2.6s,DC-Routing的预测准确率提升了1.7%和5.2%,每次迭代所需时间减少3.1s和3.2s,将两个改进路由机制得到的类向量进行特征融合后,模型预测准确率分别提升了2.9%和5.9%,每次迭代计算所花费时间也有所增加.本文模型与同样无迭代的路由机制Cluster Routing相比,在5-way 5-shot设定下,CI-Routing的预测准确率提升了5.6%,DC-Routing的预测准确率提升了6.7%,每次迭代时间分别减少了0.2s和0.3s,特征融合后,模型的预测能力提升了7.4%,每次迭代时间增加了2.9s,但与Dynamic Routing每完成一次迭代所需时间接近,且明显少于K-means Routing及Attention Routing.在5-way 1-shot设定下,使用Cluster Routing的模型未能收敛,可见其在少样本环境下学习能力较差.
2)定性分析
根据结果可知,4种基线路由机制在本任务上未能取得较好的表现,一是耗时时间相对较长,二是预测准确率未能随着迭代次数的增加而稳定提升.本文认为这是由以下两个主要原因导致的:一方面因为这四种路由机制均是在图像领域提出,文本特征与图像特征具有很大的不同,另一方面是由于在迭代过程中多次使用压缩函数,这会损失类原型包含的信息,导致模型预测能力产生波动.而无迭代路由机制Cluster Routing在20News数据集上表现不佳,这是因为少样本任务要求模型可以从少量样本中快速、准确的捕捉类内样本的相关性及不同类间的差异.
而本文提出的两种改进路由机制均是无迭代的,通过减少压缩函数的调用次数,可以降低信息损失带来的负面影响,使模型具有更优的预测能力,同时显著提升了模型的运算效率.相较于4种基线方法,本文提出的两种改进路由机制更好地适应了文本任务的特点,第一减弱了噪声对原型的干扰,第二利用了样本在特征空间中的位置关系来学习表示能力更强的类原型,使模型在少样本文本分类任务上具有优越的表现.
由表3结果可知,相比于Dynamic Routing,CI-Routing在1-shot任务上仅提升1%,在5-shot任务上增长幅度达到了4.1%,这是由于在1-shot任务中可学习到的样本交互特征少,模型的预测能力提升不明显,而在5-shot任务中,可以捕样本间丰富的交互信息,减弱噪声干扰来学习到更好的类原型.DC-Routing在1-shot和5-shot任务上预测能力均有所提升,可见距离系数的引入可以灵活地为每个样本点分配权重来学习类原型,提升模型的预测能力.
本文将两种路由机制学习到的类原型进行特征融合后,还可充分结合两种改进路由机制的优势,进一步提升模型预测能力,学习到更加丰富的特征,虽然每训练一次所需时间有所增长,但相比与4个基线方法,本文模型所花费时间仍旧很少,具有较强的竞争力.
5.3.3 消融实验
为了验证本文提出的两种动态路由机制在模型中的作用,本文采用同样的特征提取层和分类层设置,对路由层进行消融实验.其中,Ours-I表示不使用路由机制,取均值作为类原型,Ours-II表示删除DC-Routing,Ours-III表示删除CI-Routing,Ours表示本文提出的模型,其结果如表4所示.

表4 消融实验Table 4 Ablation study
由表4可以看出,直接计算样本均值作为类原型在3个文本数据集上表现较差,表明该方法不能充分学习文本信息特征,类原型表示能力弱.而本文采用改进路由机制学习类原型,明显提升了模型分类能力.
在5-way 1-shot和5-way 5-shot两种任务设定下,Ours-II和Ours-III两种方法的预测准确率都优于均值计算类原型的方法,这说明本文提出的两种动态路由机制均可学习到合理的类原型表示,实现对原型空间的“软划分”.由此证明两种改进路由机制从两个角度学习类原型,可以很好地捕获样本间关系,显著提升类原型的表达能力.此外将两个类向量进行特征融合,结合两种路由机制的优势,有效整合多视角下的特征信息,进一步提高模型的预测准确率.
此外,为了检验本文提出模型的收敛速度,本文对比InductNet模型,在HuffPost数据集上进行了实验,其结果如图5所示.

图5 模型收敛速度对比Fig.5 Comparison of convergence rates
由图5可知,InductNet在刚开始训练时预测准确率较低,需要多次训练才能得到较好的预测结果,而本文提出的两种路由机制在1-shot和5-shot设定下,第一次迭代时就具有更高的预测准确率,并且可以较快的收敛.在1-shot设定下,模型在第10次迭代左右达到收敛,在5-shot设定下,模型几次迭代后预测能力便接近最优.此外,将二者学习到的类向量进行特征融合后还可得到更优的分类结果.由此可见,本文提出的两种动态路由机制在提升模型预测能力的同时,还可以有效提升模型的运算效率,加快模型拟合速度.
5.3.4 融合系数实验
为了更好的融合CI-Routing和DC-Routing两种路由机制学习到的类向量,本文对融合系数τ的取值进行了实验,该实验在HuffPost数据集上基于5-way 1-shot和5-way 5-shot两种设定进行.实验结果如图6所示.
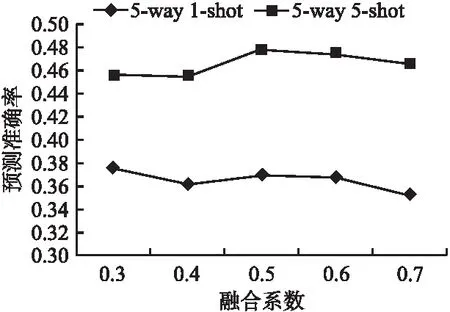
图6 不同融合系数下的分类结果Fig.6 Performance comparison on difference
从图6中可以看出,τ取值为0.5时,在两种设定下模型具有更佳优秀的预测能力,当τ的值逐渐增大,模型的预测能力反而逐渐降低.由此可见,τ的取值影响着模型的预测能力,两种改进路由机制学习到的类原型均有着重要的作用,本文将融合系数τ设定为0.5可以更好的捕获文本信息,使类原型表示能力更加优越,使模型具有更好的分类效果.
6 总 结
针对少样本文本分类任务噪声多、类内样本点分布不均的显著问题,本文提出了改进路由机制的元学习少样本文本分类模型,通过两种改进路由机制来针对性解决上述两个问题,基于交互信息的路由机制建模同类样本间的共性特征,对重要特征进行加强;基于距离系数的路由机制聚焦于样本的相对位置关系,为具辨别性的样本分配高权重.经过量化实验证明,本文提出的模型相较于传统少样本学习方法,具有更好的预测能力和收敛速度,相比于其他动态路由机制方法,本文提出的两种改进路由机制可以更高效地适应少样本文本分类任务的特点,学习到泛化性更好、表示能力更强的类原型,从而提升模型的预测结果.
基于本文结果,在未来工作中将会对胶囊网络及路由机制展开进一步的研究,结合对比学习思想,拉近同一类样本距离,提升高层胶囊即类原型的表示能力.由于本文采用英文数据集进行实验,在接下来的工作中,还将使用中文数据集进行实验,检验模型在中文数据集上的预测效果,并结合其他预训练方法,建模文本样本中的长距离信息依赖关系,使模型在面对复杂的文本时,具有抽取深层次特征,提升模型的预测能力.
