基于空间级解耦和上下文增强的行人搜索方法
2023-11-10庞彦伟王佳蓓
庞彦伟,王佳蓓
基于空间级解耦和上下文增强的行人搜索方法
庞彦伟1, 2,王佳蓓1, 2
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 天津市类脑智能技术重点实验室,天津 300072)
行人搜索是一个同时处理行人检测与行人重识别的联合任务.然而,行人检测与行人重识别之间存在任务冲突:行人检测旨在区分人与背景区域,关注行人的共性;行人重识别旨在辨别不同人,关注行人的特性. 针对此任务冲突,与以往堆叠多个卷积层的深度级解耦方式不同,基于空间分离的思想,提出了一种简单高效的空间级解耦策略.该策略为两个任务设计不同的可形变卷积,自适应地在不同位置上分别提取行人检测特征与行人重识别特征,实现了行人共性与特性的分离. 进一步,为了利用丰富的上下文信息帮助更好地辨别不同的行人,提出了一种上下文增强特征提取模块.该模块使用全局感知的多头注意力网络生成信息互补的多级特征,然后利用所设计的基于自注意力机制的多级特征融合模块,融合得到上下文增强特征.在该上下文增强特征的基础上,应用上述空间级解耦策略对其不同空间位置进行采样,解耦行人检测和行人重识别两个任务. 实验结果表明,所提方法在CUHK-SYSU测试集上mAP和top-1准确率分别达到了94.2%和94.6%,在PRW测试集上mAP和top-1准确率分别达到了52.6%和87.6%,能够有效地提升行人搜索任务性能.
行人搜索;行人检测;行人重识别;形变卷积;上下文增强
行人搜索[1-2]旨在从一组多种场景图像中寻找与定位特定目标行人,它可以看作是行人检测与行人重识别的联合任务.相比于在剪裁后的行人图像中辨别行人的行人重识别任务[3],在全景图像中对行人进行搜索与辨别的行人搜索任务更加贴近真实应用场景,同时也具有挑战性.一方面,它需要面对这两个子任务各自普遍存在的挑战,如遮挡[4]和尺度变 化[5];另一方面,行人搜索需要应对行人检测与行人重识别两个子任务之间的冲突[6].
在过去的几年里,借助于深度卷积网络,行人搜索研究工作取得了巨大的成就.当前行人搜索方法大致可以分为两类:两步行人搜索方法和单步行人搜索方法.两步行人搜索方法使用两个独立的网络分别处理行人检测与行人重识别任务,即首先在全景图像中检测行人,然后使用裁剪后的行人图像完成行人重识别任务.例如,Wang等[7]利用了检测和重识别任务的相关性,提出了一个查询目标图像身份信息引导检测器和一个适应检测结果的重识别模型.与之相对应,单步行人搜索方法则在单个网络中同时进行行人检测与重识别任务.Xiao等[1]通过引入在线实例匹配损失监督行人重识别的学习,提出了第1个单步端到端行人搜索方法.之后很多单步行人搜索方法[8-9]都是基于这个框架.例如,Chen等[10]提出将行人特征表达向量在极坐标系中分解为径向模长和角度,分别用于检测分类和重识别预测.Han等[11]提出了一种解耦检测与重识别优化网络,使用区域候选框网络预测行人检测结果,使用真值框的感兴趣区域特征预测行人重识别.与两步行人搜索方法相比,单步行人搜索方法在运行速度与内存消耗上均具有比较明显的优势.
本文聚焦于解决行人搜索任务中行人检测与行人重识别的任务冲突问题.行人检测目的是定位图像中的人,区分人和背景的过程会最小化不同人之间的特征差异;而重识别任务目的是判断不同行人图像是否属于同一人,辨别不同的行人过程会最大化不同行人特征差异.为了解决该任务冲突问题,现有的单步行人搜索方法在不同的深度层级上分别预测检测与重识别,在检测与重识别预测网络之间保持一定的深度距离,隐式地转换特征.与之不同的是,本文在空间中分离特征选择,提出空间级解耦策略.其出发点在于检测任务的空间特征选择集中在最小化不同人特征差异的位置上,而重识别任务的空间特征选择集中在最大化不同人特征差异的位置上.所提出的空间级解耦策略是通过分离变形模块(separate deformation module,SDM)实现的.SDM使用同一输入特征,利用两个并行可形变卷积分支分别提取特征进行检测预测和重识别预测,通过使用不同的空间特征来缓解任务冲突.
此外,具有丰富上下文信息的特征对于行人搜索任务至关重要.例如,在一些具有挑战性的场景中,上下文信息可以通过利用周围环境或附近行人来帮助识别目标行人[12-13].为此,本文提出上下文增强特征提取模块(context-enhanced feature extraction module,CFEM),该模块包括多级特征生成(multi-level feature generation,MFG)和多级特征融合(multi-level feature fusion,MFF),采用基于全局感知的多头注意力网络来生成具有丰富上下文互补信息的多级特征,代替原有基于局部感知的卷积神经网络,在多级特征的基础上,进一步引入基于自注意力机制的上下文多级特征融合模块,挖掘更多的上下文信息,在两个公开数据集上进行丰富的实验,证明了本方法的有效性.
1 本文方法
基于空间级解耦和上下文增强的行人搜索方法的网络结构如图1所示,主要包括上下文增强特征提取模块和分离变形模块两个部分.
给定一幅包含待搜索行人的输入图像,先经过上下文增强特征提取模块(CFEM)提取两个任务通用的融合特征,其中多级特征生成(MFG)能够提供上下文信息丰富的特征金字塔,多级特征融合(MFF)将不同分辨率的特征有效地融合成为上下文增强特征.然后,分离变形模块(SDM)对这一上下文增强特征的不同空间位置进行采样,通过一种高效的并行多任务设计,解耦行人检测和重识别两个子任务,最终有效完成行人搜索任务.
1.1 分离变形模块
行人搜索的两个子任务之间存在着本质上的任务冲突:行人检测任务将所有人视为同一类(前景),为了区分人和背景会最小化不同人之间的特征差异,使得不同人的特征尽可能地靠近;而行人重识别任务将不同人视为不同的类别,为了辨别不同的人会最大化不同人特征差异,使得不同人的特征尽可能地远离,如图2所示,其中不同颜色的特征表示不同类别的特征.理想的单步行人搜索方法应该能够处理该任务冲突,而不需要过于复杂的过程.

图1 所提方法网络结构

图2 行人检测与行人重识别任务冲突说明
为了解决检测和重识别之间的任务冲突问题,当前大多数行人搜索方法倾向于使用来自不同深度层的不同特征来进行这两个子任务的预测.具体地,两步行人搜索方法采用两个独立的网络分别处理行人检测与行人重识别任务,以此来显式分离检测与重识别的特征.单步行人搜索方法是在检测预测与重识别预测之间堆叠几个卷积或正则化层等,以不同深度级的方式生成不同特征,从而隐式地解耦检测和重识别任务,典型的单步行人搜索方法预测网络对比如图3所示.图3(a)中的OIM[1]和图3(b)中的NAE[10]在检测预测和重识别预测之间存在多个全连接或归一化层.图3(c)中AlignPS[14]遵循重识别任务优先的原则,在检测预测之前叠加4个卷积层.总之,这些已有的行人搜索预测网络在检测和重识别预测层之间保持一定的深度距离.这种方法一定程度上忽略了两个子任务之间的相关性,并且带来了大量不必要的计算开销,所以本文认为这种深度级的解耦并不是一个有效的解决冲突的方式.为解决已有方法的局限,本文提出空间级解耦策略,在空间级上选择不同位置的特征,在空间中分离特征选择.行人检测特征更集中在能够最大化行人共性特征的位置,以便将人与背景区域分开.相反地,重识别预测特征更集中在能够最大化不同人的特征差异的位置,以便区分不同的人.空间级解耦策略是通过一个分离变形模块(SDM)来实现的,该模块有效地学习空间中两个子任务关注的不同位置特征,如图3(d)所示.通过一定程度的空间分离,便可以有效缓解行人重识别与行人检测之间的任务冲突,同时避免了已有方案存在的计算开销大的问题.

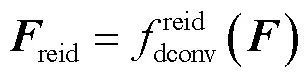

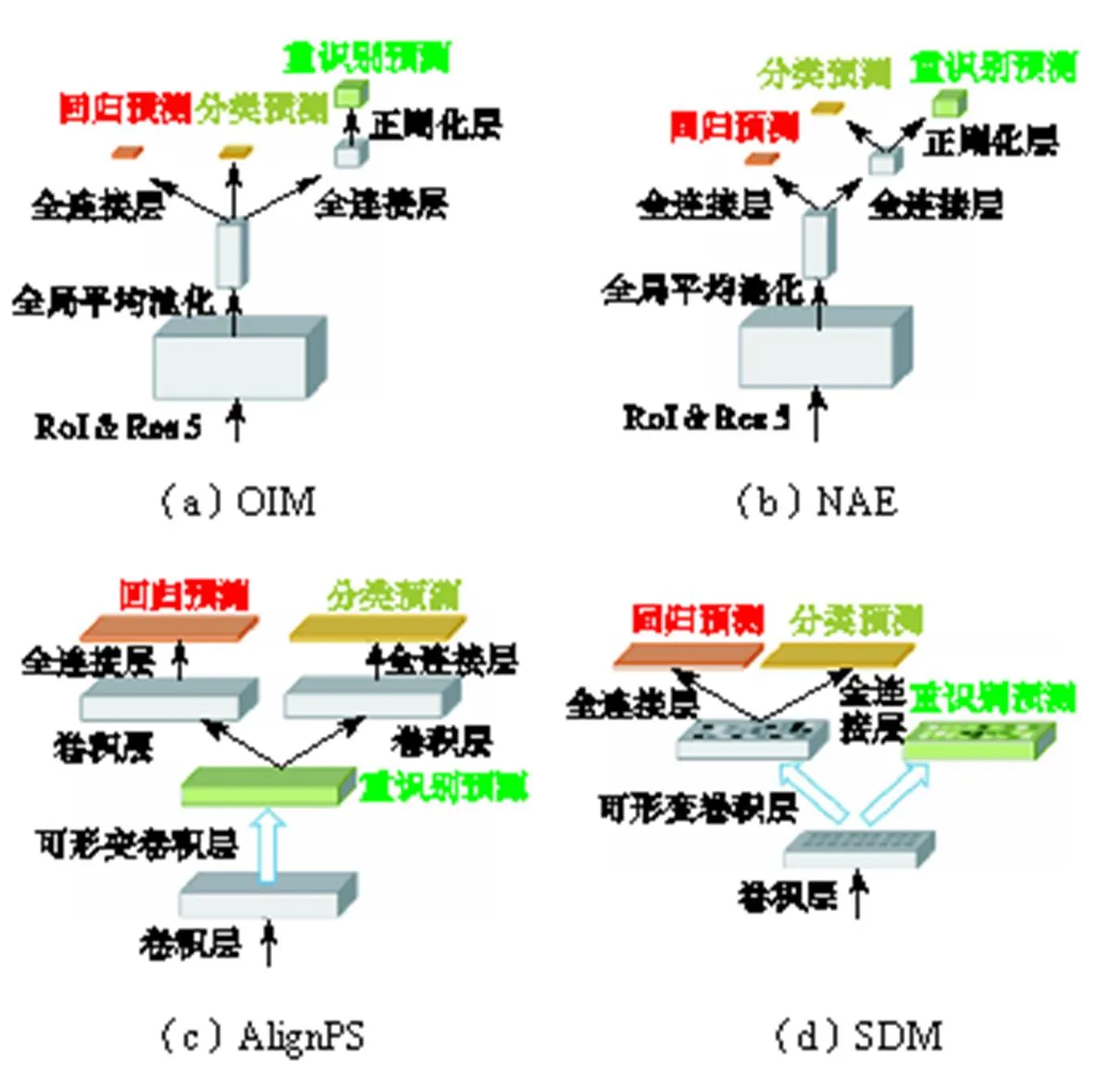
图3 不同单步行人搜索方法预测网络对比
1.2 上下文增强特征提取模块
上下文信息在行人搜索中起着重要的作用,一些研究利用上下文信息来提高行人搜索的准确性.例如,Yan等[12]建立了一个图学习框架并使用具有相邻行人信息的上下文特征来更新计算不同行人之间的相似性.Munjal等[13]提出了一种查询图像引导的行人搜索网络,利用查询图像与待搜索的图库图像的全局上下文信息.本文提出了一个简单而有效的上下文增强特征提取模块(CFEM),它可以生成拥有丰富上下文信息、更鲁棒的特征.CFEM分为两个连续的部分:多级特征生成(MFG)和多级特征融合(MFF).
1.2.1 多级特征生成

1.2.2 多级特征融合





为了充分增强各级特征中的上下文信息,提出了上下文多级加和策略,如图4(c)所示.首先在多级输入特征图上分别使用注意力层,利用其对非相邻特征间关系的建模能力,来捕捉特征中的远距离信息.其中注意层保留了原有设计的跳连接方式.之后,多级注意力层后的输出特征的和作为最终输出特征,实现了具有丰富上下文信息的多特征融合,计算表达式为


图4 不同多级特征融合网络结构对比
2 实验结果与分析
2.1 实验数据集与评价指标
为了验证所提出方法的有效性,本文在两个公开行人搜索数据集CUHK-SYSU[1]和PRW[2]进行行人搜索实验.
CUHK-SYSU是一个大规模的行人搜索数据集,有街拍和电影场景两种数据来源.它一共包含18184张图像、8432个标注身份和96143个标注行人边界框.对于每个需要查询的目标行人,对应的搜索图库大小包含了从50~4000不等的6种配置.如果没有特殊说明,默认使用搜索图库大小为100张图的配置来进行实验.

使用mAP(mean average precision)和top-1准确率两个标准行人搜索任务评价指标.与行人重识别任务评价不同,只有当预测边界框与真值的交并比(intersection over union,IoU)大于0.5,该预测框才会被作为候选框计算行人搜索匹配度,计算mAP和top-1准确率.对于mAP,首先基于每个目标行人的精度-召回曲线下的面积计算平均精度(AP),再对所有目标行人的AP计算平均来作为mAP.top-1准确率是指在整个搜索图库中,具有最高得分的预测候选框与给定目标行人匹配的平均值.
除了以上两个用于行人搜索任务的评价指标外,本文还使用AP50评价指标来度量行人检测任务的性能.
2.2 实验细节
本文基于开源库mmdetection[22]实现了所提出的单步无锚框行人搜索方法.使用在ImageNet-1K[23]上预训练过的骨干网络,包括ResNet-50、Swin Transformer和PVTv2.最后采用的PVTv2模型使用AdamW优化器在单个NVIDIA GeForce RTX 3090 GPU上训练.具体相关实验参数设置如表1所示.
表1 实验参数设置

Tab.1 Parameter setting of the experiment
2.3 所提模块有效性验证
本文在PRW数据集上进行消融实验来验证所提出的不同模块的效果,包括上下文增强特征提取模块和分离变形模块,其中上下文增强特征提取模块包含两部分:多级特征生成和多级特征融合,如表2所示.

表2 在PRW测试集上所提模块消融实验结果

Tab.2 Ablation experiment results of the proposed mod-ules on the PRW test set
表3为分离变形模块行人搜索预测网络在不同设置下的对比实验结果,即使用不同的检测预测特征采样卷积和重识别预测特征采样卷积.首先使用单个相同的可形变卷积同时进行检测与重识别预测在mAP和top-1准确率上分别达到了44.8%和84.4%.表3中其他实验结果均为使用两个或多个不同的卷积分别处理检测与重识别预测.仅使用单个可形变卷积分别用于检测预测特征采样和重识别预测特征采样,在mAP上分别达到了43.0%和48.9%.与这些方法相比,通过使用两个并行的可形变卷积自适应地对检测和重识别预测特征进行采样,分离变形模块实现了最好的性能,mAP和top-1准确率分别是52.6%和87.6%,这证明了分离变形模块可以通过对检测和重识别在不同感兴趣位置上提取特征,有效地解决两者之间的任务冲突.此外,按照AlignPS[14]在检测预测之前堆叠4个标准卷积,在增加了网络参数量的同时,观察发现可以提高检测性能,然而并没有改善搜索mAP性能,对top-1准确率的提高很小,这表明在检测和重识别预测层之间堆叠更多的卷积层并不重要.这也反映了先前方法所采用的深度级解耦策略增加计算开支的同时并没有带来行人搜索性能上的明显收益,反而会引入一定负作用.一个重要的原因是在单步行人搜索方法中由于存在任务冲突,单一任务性能的提升可能会导致另一任务性能的下降,最终的搜索性能下降.
表3 在PRW测试集上分离变形模块对比实验结果

Tab.3 Comparison of experiment results of separate deformation module on the PRW test set

表4展示了不同骨干网络的对比实验结果.对于行人检测任务性能AP50,卷积神经网络和多头注意力网络作为骨干网络的性能相近.对于行人搜索任务性能,ResNet-50和ResNet-101的mAP分别为44.6%和45.0%,而Swin-T、PVTv2-B1、Swin-S和PVTv2-B2的mAP分别为48.2%、48.3%、49.5%和52.6%,作为骨干网络,多头注意力网络优于卷积神经网络,上下文信息对于帮助辨别目标行人十分重要,进而基于全局注意力机制的多头注意力网络相比于局部感知的卷积神经网络更能够捕获上下文信息,可以利用丰富的上下文信息来提升行人搜索性能.在骨干网络采用不同多头注意力网络中,PVTv2-B2的性能最好.与PVTv2-B2相比,Swin-T和Swin-S可能无法通过局部注意模块充分利用全局上下文信息,所以最终采用PVTv2-B2作为模型骨干网络.

图5 在PRW测试集上可形变卷积采样点可视化
表4 在PRW测试集上不同骨干网络对比实验结果

Tab.4 Comparison of experiment results of different backbone networks on the PRW test set

表5 在PRW测试集上单级特征与多级融合特征对比实验结果

Tab.5 Comparison of experiment results of single-level features and multi-level fused features on the PRW test set
为了证明提出的分离变形模块的有效性,在AlignPS上进行实验,骨干网络均使用ResNet-50,用空间级解耦的SDM替换AlignPS中的原始深度级解耦的预测网络模型.表6展示了模型准确率、推理时间、时间复杂度和空间复杂度的结果.其中时间复杂度采用浮点运算(floating-point operations,FLOPs)次数指标衡量,空间复杂度采用访存量指标衡量.与原始的AlignPS预测网络相比,通过将SDM集成到AlignPS中,它以更低的计算复杂度、更快的推理速度获得了更好的性能,证明了所提出的空间级解耦策略的有效性.
表6 在PRW测试集上AlignPS与SDM效率对比实验结果

Tab.6 Comparison of experiment results of the efficiency of AlignPS and SDM on the PRW test set
2.4 与其他方法的比较
本文将所提出的方法与一些先进的行人搜索方法进行行人搜索任务性能比较,包括单步行人搜索方法和两步行人搜索方法,如表7所示.
表7 在CUHK-SYSU和PRW测试集上与其他先进方法对比

Tab.7 Comparison with other state-of-the-art methods on the CUHK-SYSU and PRW test sets
在CUHK-SYSU数据集上,使用100个搜索图库将本文方法与其他先进方法进行了比较.本文方法达到了94.2%的mAP和94.6%的top-1准确率,优于目前多数的单步和两步行人搜索方法.例如,两步法TCTS和单步法DMRNet分别有93.9%和93.2%的mAP,本文方法分别高出其0.3%和1.0%.另外,还将本文方法与其他的单步和两步行人搜索方法在50~4000的不同图库规模下进行了比较,如图6所示.行人搜索任务是在图库候选图像中按照给定的包含目标行人的查询图像进行搜索,定位与识别目标行人,图库规模表示图库中候选图像数量.随着图库规模的增加,行人搜索的挑战难度越来越大.本文方法在不同的图库规模下稳定地优于其他方法,尤其是图库规模较大的时候.
PRW数据集由于搜索图库规模更大,拍摄视角变换更多,性能指标更低,更具有挑战性.本文方法分别实现了52.6%的mAP和87.6%的top-1准确率,超过了当前所有其他先进方法.本文方法在mAP上比最好的两步行人搜索方法TCTS提高了5.8%,比最好的单步行人搜索方法DMRNet在mAP和top-1准确率上分别提高了5.7%和4.3%.

图6 在CUHK-SYSU测试集上改变图库规模与其他方法对比
除了以上定量的比较外,部分行人搜索结果的可视化如图7与图8所示.图7显示了本文方法在PRW测试集上的一些搜索定性结果,图7(a)为包含目标行人的查询图像,图7(b)~(d)为本文方法在图库中进行识别匹配得到的属于目标行人在不同场景图像中的3个搜索结果示例.本文方法成功地检测和识别了不同摄像机视角下的搜索图库中的目标行人,其中行人具有姿势、大小和背景等差异.图8进一步展示了一些本文方法和AlignPS方法在PRW测试集上最佳匹配的搜索结果对比.相比之下,本文所提出的模型成功地在不同场景下找到了目标行人,原因之一在于本文方法能够利用丰富上下文信息来帮助识别目标行人.比如第3行,目标行人旁边有1名儿童;最后1行,有5个人在目标行人附近谈话.

图7 在PRW测试集上本文方法定性结果

图8 在PRW测试集上与AlignPS定性结果(最佳搜索结果)比较
3 结 语
本文提出了一种新的单步无锚框行人搜索方法,该方法采用了空间级解耦策略,有效地缓解了行人检测和行人重识别之间的任务冲突.该策略基于检测与重识别任务的特征集中在不同空间位置的观察,简化任务冲突的解决方法为空间级的特征选择而不是深度级的特征选择.具体地,空间级解耦策略由一个分离变形模块(SDM)实现.此外,提出一个上下文增强特征提取模块(CFEM),利用丰富的上下文信息更好地辨别行人.该方法在CUHK-SYSU和PRW两个行人搜索数据集上取得了良好的性能,提升了行人搜索任务性能.
在未来,本文提出的空间级解耦策略可以扩展到单步两阶段检测器行人搜索方法中,提供一种可能的方式:从不同的空间采样位置提取感兴趣区域特征分别用于检测和重识别,例如使用可形变感兴趣区域操作.此外,行人搜索任务是在搜索图库图像中识别目标行人,可广泛用于智慧城市的构建.
[1]Xiao T,Li S,Wang B C,et al. Joint detection and identification feature learning for person search [C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:3376-3385.
[2]Zheng L,Zhang H H,Sun S Y,et al. Person re-identification in the wild[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:3346-3355.
[3]He S T,Luo H,Wang P C,et al. TransReID:Transformer-based object re-identification[C]// Proceed-ings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal,Canada,2021:14933-15002.
[4]梁 煜,李佳豪,张 为,等. 嵌入中心点预测模块的Yolov3遮挡人员检测网络[J]. 天津大学学报(自然科学与工程技术版),2021,54(5):517-525.
Liang Yu,Li Jiahao,Zhang Wei,et al. Embedded center prediction module of Yolov3 occlusion human detection network[J]. Journal of Tianjin University (Science and Technology),2021,54(5):517-525(in Chinese).
[5]庞彦伟,余 珂,孙汉卿,等. 基于逐级信息恢复网络的实时目标检测算法[J]. 天津大学学报(自然科学与工程技术版),2022,55(5):471-479.
Pang Yanwei,Yu Ke,Sun Hanqing,et al. Hierarchical information recovery network for real-time object detection[J]. Journal of Tianjin University(Science and Technology),2022,55(5):471-479(in Chinese).
[6]Chen D,Zhang S S,Ouyang W L,et al. Person search via a mask-guided two-stream CNN model[C]// Proceedings of 2018 European Conference on Computer Vision. Munich,Germany,2018:764-781.
[7]Wang C,Ma B P,Chang H,et al. TCTS:A task-consistent two-stage framework for person search [C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:11949-11958.
[8]Dong W K,Zhang Z X,Song C F,et al. Bi-directional interaction network for person search[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:2836-2845.
[9]Xiao J M,Xie Y C,Tillo T,et al. IAN:The individual aggregation network for person search[J]. Pattern Recognition,2019,87:332-340.
[10]Chen D,Zhang S S,Yang J,et al. Norm-aware embedding for efficient person search[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:12612-12621.
[11]Han C C,Zheng Z D,Gao C X,et al. Decoupled and memory-reinforced networks:Towards effective feature learning for one-step person search[C]// Proceedings of 2021 AAAI Conference on Artificial Intelligence. Hong Kong,China,2021:1505-1512.
[12]Yan Y C,Zhang Q,Ni B B,et al. Learning context graph for person search[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision and Pattern Recongnition. Long Beach,USA,2019:2158-2167.
[13]Munjal B,Amin S,Tombari F,et al. Query-guided end-to-end person search[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision and Pattern Recongnition. Long Beach,USA,2019:811-820.
[14]Yan Y C,Li J P,Qin J,et al. Anchor-free person search[C]//Proceedings of 2021 IEEE/CVF Computer Vision and Pattern Recognition. Hong Kong,China,2021:7686-7695.
[15]Lin T Y,Goyal P,Girshick R,et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(2):318-327.
[16]Tian Z,Shen C H,Chen H,et al. FCOS:Fully convolutional one-stage object detection[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul,Korea,2019:9626-9635.
[17]Chen D,Zhang S S,Ouyang W L,et al. Hierarchical online instance matching for person search[C]// Proceedings of 2020 AAAI Conference on Artificial Intelligence. New York,USA,2020:10518-10525.
[18]He K M,Zhang X Y,Ren S Q,et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:770-778.
[19]Dosovitskiy A,Beyer L,Kolesnikov A,et al. An image is worth 16×16 words[C]//Proceedings of 2021 International Conference on Learning Representations. Vienna,Austria,2021:1-19.
[20]Liu Z,Lin Y T,Cao Y,et al. Swin Transformer:Hierarchical vision transformer using shifted windows [C]//Proceedings of 2021 IEEE/CVF Interna-tional Conference on Computer Vision. Montreal,Canada,2021:9992-10002.
[21]Wang W H,Xie E Z,Li X,et al. Pyramid vision transformer:A versatile backbone for dense prediction without convolutions[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal,Canada,2021:568-578.
[22]Chen K,Wang J Q,Pang J M,et al. MMDetection:Open MMLab detection toolbox and benchmark [EB/OL]. http://arxiv.org/abs/1906.07155,2019-04-25.
[23]Deng J,Dong W,Socher R,et al. Imagenet:A large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Florida,USA,2009:248-255.
[24]Lan X,Zhu X T,Gong S G. Person search by multi-scale matching[C]//Proceedings of 2018 European Conference on Computer Vision. Munich,Germany,2018:553-569.
[25]Han C C,Ye J C,Zhong Y S,et al. Re-ID driven localization refinement for person search[C]//Proceed-ings of 2019 IEEE/CVF International Conference on Computer Vision. Long Beach,USA,2019:9813-9822.
[26]Dong W K,Zhang Z X,Song C F,et al. Instance guided proposal network for person search[C]//Proceed-ings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:2582-2591.
[27]Liu H,Feng J S,Jie Z Q,et al. Neural person search machines[C]//Proceedings of 2017 IEEE/CVF Interna-tional Conference on Computer Vision. Venice,Italy,2017:493-501.
[28]Chang X J,Huang P-Y,Shen Y-D,et al. RCAA:Relational context-aware agents for person search[C]// Proceedings of 2018 European Conference on Computer Vision. Munich,Germany,2018:86-102.
[29]Kim H,Joung S,Kim I,et al. Prototype-guided saliency feature learning for person search [C]// Proceedings of 2021 IEEE/CVF Computer Vision and Pattern Recognition. Boston,USA,2021:4863-4872.
[30]Zhao C R,Chen Z C,Dou S G,et al. Context-aware feature learning for noise robust person search[J]. IEEE Transactions on Circuits and Systems for Video Technology,2022,32(10):7047-7060.
[31]Lee S,Oh Y,Baek D,et al. OIMNet++:Prototypical normalization and localization-aware learning for person search[C]//Proceedings of 2022 IEEE/CVF European Conference on Computer Vision. Tel Aviv,Israel,2022:621-637.
Person Search with Spatial-Level Decoupling and Contextual Enhancement
Pang Yanwei1, 2,Wang Jiabei1, 2
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China;2. Tianjin Key Laboratory of Brain-Inspired Intelligence Technology,Tianjin University,Tianjin 300072,China)
Person search is a joint task that simultaneously performs pedestrian detection and person re-identification;however,these two sub-tasks are not similar. Pedestrian detection aims to differentiate persons from background regions by focusing on the commonness of pedestrians,while person re-identification aims to distinguish different persons by emphasizing the uniqueness of each pedestrian. To address this task contradiction,a simple and efficient spatial-level decoupling strategy was proposed,as opposed to the existing depth-level decoupling methods of stacking multiple convolutional layers. Two different deformable convolutions were endorsed to adaptively extract features at different positions for the two sub-tasks,allowing the separation of pedestrian commonness and uniqueness. Furthermore,a context-enhanced feature extraction module was also presented to exploit rich contextual information for better person identification. A multi-head attention network capable of capturing long-range dependencies was used to generate multi-level features with complementary information. Moreover,a multi-level feature fusion module based on a self-attention mechanism was proposed to obtain the context-enhanced features. The above spatial-level decoupling strategy was applied to the context-enhanced feature for sampling features at different spatial positions,thereby decoupling the pedestrian detection task and person re-identification task. Experimental results show that the mean average precision(mAP)and top-1 accuracy of the proposed method are 94.2% and 94.6% on the CUHK-SYSU test set,respectively. For the PRW test set,the mAP and top-1 accuracy are 52.6% and 87.6%,respectively. Those results indicate that the proposed method can significantly improve person search.
person search;pedestrian detection;person re-identification;deformable convolution;contextual enhancement
Tianjin Science and Technology Program(No. 19ZXZNGX00050).
10.11784/tdxbz202209005
TP391.4
A
0493-2137(2023)12-1307-10
2022-09-05;
2022-12-01.
庞彦伟(1976— ),男,博士,教授.Email:m_bigm@tju.edu.cn
庞彦伟,pyw@tju.edu.cn.
天津市科技计划资助项目(19ZXZNGX00050).
(责任编辑:孙立华)
