融合依存句法和图注意力网络的事件检测模型
2023-11-10郑志蕴裴晓波张行进王军锋
郑志蕴,裴晓波,李 钝,张行进,王军锋
(郑州大学 计算机与人工智能学院,郑州 450001)
1 引 言
事件检测(Event Detection,ED)[1]作为信息抽取的子任务,旨在从非结构化的文本中自动抽取用户感兴趣的事件信息并以结构化的形式展示.由此产生的语义理解已应用于广泛应用在信息搜索[2]、金融分析[3]、自动摘要[4]等领域.
事件检测任务是从自然语言文本识别事件的触发词(Event Trigger),并将它们分类为特定的类型.事件的触发词是唤起相应事件的关键词[5],一般为动词或名词.如例句S1:“They killed a lot of our people in Chamchamal but I feel bad for them too.”中,事件检测的任务即为识别触发词为“killed”并对应事件类型“Life:Die”.
现有研究表明使用图神经网络模型(Graph Neural Network,GNN)[6]进行事件检测能有效提高总体性能,具体方法为根据依存句法解析将依存句法树转换为图,句子中的每个单词都作为一个节点,有向边体现的是从当前词到其依赖词的语法依存关系.依存句法解析的目标是分析句子的语法结构并描述各词语之间的依存关系,例句S1的依存句法解析如图1所示.利用图特性,可以规范化文本中许多的词汇和语法变化[7],使得图信息更容易被建模,有助于有效地捕捉每个候选触发词与其它相关实体之间的相互关系.
图注意力网络模型(Graph Attention Network,GAT)是具有注意力机制的GNN,能够更好地学习到图的全局特征之间的依赖关系,在GNN家族中有不可或缺的优势.GAT利用掩蔽的自注意力层聚合邻居节点,实现对不同邻居的权值自适应匹配,从而提高模型的准确率.
然而现有的GAT模型,存在以下问题:①忽略单词之间的依存标签信息,而依存标签可以作为一个单词是否是触发词的重要指标,能有效提高事件检测准确率.例如S1中,从依存边“nsubj”(名词主语)和“dobj”(直接宾语)可以看出“They”和“people”分别是“killed”的主语和宾语,边“nmod”(名词修饰语)指出“Chamchamal”是“killed”事件的地点,这些依存关系对识别出触发词“killed”提供了有效帮助.②在使用循环神经网络模型捕获句子中每个单词的上下文信息时,现有模型都选择长短期记忆网络模型(Long Short-Term Memory,LSTM),计算量大、结构复杂导致模型内存空间占用多.
为了解决上述问题,本文提出依存边信息嵌入的图注意力网络模型(Graph Attention Network with Dependency Edge Information Embedding,EIEGAT)用于事件检测.①为了充分挖掘隐藏在依存边中的信息,在图注意力网络模型的基础上,设计依存边信息嵌入模块,将依存边的标签信息嵌入到图的邻接矩阵中,使邻接矩阵等价于加入了依存边标签信息的图结构.使得模型在构造图时不仅考虑了节点表示,且考虑了依赖边的表示,提高事件检测准确率.②使用结构和计算更简单的循环神经网络变种模型——门控循环单元结构(Gated Recurrent Unit,GRU),自适应累计上下文信息流,在获得比LSTM相当甚至更佳性能的同时,达到简化网络结构,节省内存空间的目标.
本文贡献概述如下:
1.提出EIEGAT事件检测模型.在图注意力网络模型中嵌入依存边信息,即同时利用了句法结构、注意力权重信息及依存边标签信息来实现事件检测任务.
2.在ACE2005语料集上的实验表明本模型优于基线模型,有效提高了事件检测的总体性能.
本文其余部分的结构如下:第2章介绍随着发展进程的用于事件检测任务的相关算法,第3章介绍本文提出的基于依存句法和图注意力网络的事件检测模型,第4章介绍数据集和评价指标,及针对本文模型与相关研究设计的各种实验,第5章对整篇论文所做的工作进行总结.
2 相关工作
事件检测的方法随着发展进程,主要分为基于模式匹配、基于机器学习和基于深度学习3类.
早期的事件检测主要是基于模式匹配的方法,核心是事件检测模板的构建,再将待识别的句子与对应模板进行匹配.该方法能较好地应用于特定领域,但可移植性和灵活性较差.当跨域使用时,需要重新花费大量的时间和人力构建模型.
利用机器学习提取事件,本质上就是将事件检测作为一个分类问题来处理.其主要任务是选择合适的特征并构造合适的分类器,分类器通常基于统计模型构建,例如最大熵模型、条件随机场模型[8]等.与模式匹配方法相比,机器学习方法可以跨域使用,具有较高的可移植性和灵活性.但该方法需要大规模标注训练语料库,语料库的建设不仅需要大量人力和时间,同时存在着数据稀疏和数据不平衡.这两种情况导致训练语料库不够或类别单一,都将严重影响事件检测的效果.
深度学习是机器学习领域研究的新方向,它可以学习更抽象的数学特征,使数据具有更好的特征表达,从而高质量地实现事件检测任务.目前,深度学习神经网络已成为事件检测的主流研究方法.
如何设计高效的神经网络模型是深度学习方法的主要挑战之一.现有的神经网络事件检测模型主要包括基于序列和基于GNN两种方法:
基于序列的方法:将事件检测问题作为序列标记任务来处理,包括卷积神经网络模型(Convolutional Neural Network,CNN)和循环神经网络模型(Recurrent Neural Network,RNN).Chen等分别采用动态多池化卷积[9]及使用FreeBase大型知识库进行远程动态多池化卷积[10],提取词汇级和句子级特征的动态多池层来评估句子的各个部分.CNN结构以单词嵌入的拼接作为输入,对连续单词进行卷积操作,捕捉当前单词与相邻单词的上下文关系.因此,不能很好地捕捉到遥远单词之间的一些潜在的依存关系,从而利用整个句子的信息来提取触发词.
RNN结构具有时间连续特性[11],可以通过在句子中按照单词的顺序(向前或向后)输入单词,直接或间接利用任意两个单词之间的潜在依赖关系.Nguyen等[12]使用双向RNN和人工设计的特征联合提取事件触发词和事件元素.
自然语言的内部实际是极为复杂的树形结构,也即图结构.基于序列的方法无法利用句子丰富的语法结构,因此存在捕获句子长期依赖关系时效率低下、忽略句法结构等问题从而影响事件检测性能.
基于GNN的方法:在图结构上运行神经网络.传统的神经元操作,如在CNN和RNN中广泛使用的卷积核和递归核,可以应用于图结构中,从而学习图中所嵌入的各种深度特征用于特定的任务.因此,使用GNN模型利用依存句法结构迅速成为事件检测领域的研究热点.
现有GNN方法用于事件检测的方法基本都是在图上进行卷积操作,即在图上运行图卷积神经网络模型(Graph Convolutional network,GCN).Nguyen等[13]、Liu等[14]和Cui等[15]根据句法连通性将依存句法树转换为图,对GCN进行不同的改进以更好地建模图信息,在ACE语料集[16]上效果良好.但GCN模型结合邻近节点特征的方式依赖特定图结构,限制训练所得模型在其他图结构上的泛化能力.
GAT[17]利用自注意力机制[18]通过直接计算图中任意两个节点之间的关系,能够获取图结构的全局特征,拥有全图访问的优点;GAT使当前节点只与相邻节点有关而无需得到整张图的信息,拥有泛化性高的优点.Yan等[19]使用GNN对句法依存树建模,并加入注意力机制聚合句中多阶的句法信息.但现有GAT往往忽视丰富的依存边标签信息,而依存边标签信息能为识别事件提供十分实用的帮助.
3 依存边信息嵌入的图注意力网络模型
针对依存边标签信息对模型的重要性及GRU的优势,本文提出基于依存句法和图注意力网络的事件检测模型,将依存边信息嵌入到图注意力网络上.模型总体结构如图2所示,包含5个模块:1)嵌入层,将输入的句子编码成向量序列;2)Bi-GRU层,捕获每个单词的上下文信息;3)依存边信息嵌入模块,将依存边的标签信息嵌入至图的邻接矩阵中;4)图注意力网络层,对依存边信息嵌入后的依存句法图进行图注意力卷积;5)触发词分类层,预测事件触发词标签作为分类结果.

图2 模型结构图Fig.2 Structure of the proposed method
3.1 嵌入层
使用神经网络模型处理数据之前,数据需要经过嵌入层进行向量化处理.将输入嵌入层含有n个单词的句子表示为S={w1,w2,…,wn},wi为句子中第i个单词.首先将句子S经过下列4个嵌入转换为特征向量:
wi的词嵌入向量wordi:用以捕捉单词wi隐藏的句法和语义属性.词嵌入通常是在大型未标注语料库上进行预训练.
wi的词性标注嵌入向量posi:用以捕捉单词wi的词性属性.词性标注嵌入通过查找随机初始化的词性标注嵌入表生成.
wi的位置嵌入向量psi:如果wc是当前单词,通过查找随机初始化的位置嵌入表,将wi到wc的相对距离i-c编码为一个实值向量.
wi的实体类型标签嵌入向量eti:使用BIO标注模式[20]对句子中的实体进行标注(BIO即:B是实体开头的字段,I是指实体除了开头的字段,O是指非实体的部分),并通过查找实体类型嵌入表将实体类型标签转换为实值向量.
嵌入层将句子中每个单词wi转换成实值向量xi=(wordi,posi,psi,eti),向量中包含了语义信息、词性信息、位置信息和实体信息等.将上述4个嵌入向量进行连接后,实现将输入句子S转换成一个向量序列X={x1,x2,…,xn},并作为下一层Bi-GRU层的输入.
3.2 Bi-GRU层
使用GNN捕获依存句法树中节点之间的依赖关系时,GNN的层数限制了捕获局部图信息的能力.因此需要采用自适应累积上下文的机制——RNN,利用本地顺序上下文有助于在不增加GNN层数的情况下扩展信息流.
但是传统RNN模型在训练时存在梯度消失或梯度爆炸问题,故需要使用传统RNN模型的变体,即LSTM[21]或GRU[22].GRU既能达到LSTM有效捕捉长序列之间的语义关联、缓解梯度消失或爆炸现象的功能,且具有比LSTM更简单的结构和计算.考虑到GRU不能编码句子从后到前的信息,因此本文最终使用双向门控循环单元(Bi-GRU)沿着节点的两个方向捕获信息,获得单词的上下文信息,减少来自图神经网络模型的限制并提高整个图上的长期信息传播.
Bi-GRU层将嵌入层输出的向量序列X编码为H={h1,h2,…,hn},公式如式(1)所示.
(1)
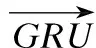
3.3 依存边信息嵌入模块
每个依存句法树都可以转换为一个n×n的邻接矩阵A表示单词节点间的连通性.构造A时仅使用单向依赖边体现句法结构,能更好地将注意力集中在触发词处.则A中数值设置为如果节点hi和节点hj之间存在语法依存边,则Aij=1;否则,Aij=0.此时邻接矩阵A为二进制矩阵,但这种二进制邻接矩阵忽略了单词之间丰富的语法依赖标签.
为了充分挖掘隐藏在依赖边中的线索,设计了依存边信息嵌入模块(Dependency Edge Information Embedding Module,DEIEM).该模块的作用是将节点之间的语法依存标签关系注入到邻接矩阵A中,形成依存边矩阵E.E不再是二进制矩阵而等价于加入了依存边标签信息的图结构.如果节点hi到节点hj之间边的标签信息为r,则对应E中表示为eij=r.对应的邻接矩阵变化如图3所示.
图3的输入为依存句法解析后的例句S2:“He was born on November 4th”,左侧为网络模型的层次结构,右侧为S2经过DEIEM的处理从邻接矩阵(A)到依存边矩阵(E)的变化.
DEIEM具体操作为将Bi-GRU层输出的节点hi和节点hj,与两节点的依赖边dep进行连接,使节点表示中表达的潜在关系信息能够被有效挖掘并注入到依存边矩阵E中.计算如式(2)所示.
eij=DEIEM(hi,hj,dep)=Wu[hi⊕hj⊕dep]
(2)
其中,⊕表示连接操作,Wu是一个可学习的变换矩阵.DEIEM通过连接节点信息,动态地优化依赖边的表示,更新句子中的的邻接矩阵,使边的表示更具信息量.
3.4 图注意力网络层
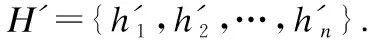
attij=a(Whi,Whj,eij)
(3)
注意力机制a(·)是计算两个节点注意力系数的函数,得到的结果表示节点vj的特征对节点vi的重要性.为了简化计算,将这种注意力系数的计算限制在一阶邻居内.此函数具体计算如式(4)所示.
(4)
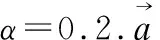
(5)
将计算所得的注意力系数αij存入矩阵中,称为注意力矩阵T,为邻接矩阵的最终形式.例句S2经过图注意力网络层邻接矩阵的变化如图4所示.

图4 图注意力网络对邻接矩阵的影响Fig.4 Effect of Graph Attention Network on adjacency matrix
(6)
其中,σ为ELU激活函数[24].
3.5 触发词分类层
(7)
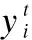
Oi=Wth′+bt
(8)
其中,Wt为将单词表示h′映射到每个事件类型的特征得分,bt是偏差.在softmax操作之后,选择概率最大的事件触发词标签作为分类结果.
3.6 损失函数
由于数据中“O”标签的数量远大于事件标签的数量,本文使用偏差损失函数[25]来增强事件标签在训练中的影响,偏差损失函数的表示如式(9)所示.
(9)
其中,Ns为句子数,Ni,w是句子si的单词数,I(O)是区分标签为“O”或事件类型的切换函数.单词的标签不为事件类型时,表示为“O”,此时I(O)=1;否则0.λ是大于1的权重参数,λ值越大,表示事件类型标签对模型的影响越大.
4 实 验
4.1 数据集和评价指标
本文的评测语料为ACE2005中英文数据集(https://catalog.ldc.upenn.edu/LDC2006T06),是目前使用最为广泛的事件检测数据集.该数据集共标注8个事件类型、33个事件子类型,如表1所示,这些子类型与NONE类一起,作为该数据集的34分类问题的预定义标签集.

表1 ACE 事件类型及子类型Table 1 ACE event type and subtype
为了确保与之前在该数据集上的工作进行兼容比较,在ACE2005英文数据集上,沿用文献[25,26]的数据分割方式.将数据集分割为用于测试集的40篇新闻文章(881句子),用于验证集的30个其他文档(1087句子),以及用于训练集的529个剩余文档(21090句子).
在ACE2005中文数据集上,沿用文献[27]的语料分割方式,从633篇标注文档中随机抽取534篇作为实验的训练集、33篇作为验证集、66篇作为测试集.
采用精确率(Precision,P)、召回率(Recall,R)和综合评价指标(F1-Measure,F1)作为评价标准.P反映了模型预测为正例的样本中识别正确的比例,R反映了所有正例样本中识别正确的比例,F1是对两者的综合度量.这3个指标根据以下两条标准进行计算:1)触发词识别:当模型预测出的触发词与语料库中一致则为正确;2)触发词分类:当模型预测出的触发词类型与语料库中一致则为正确.P、R和F1的计算公式如式(10)、(11)所示.
(10)
(11)
其中,TP(True Positive)为与真实样本相同的真正例;FP(False Positive)、FN(False Negative)分别是与真实样本不同的假正例和假反例.
4.2 实验设置
借助Stanford coreNLP工具包(http://stanfordnlp.github.io/ CoreNLP/)对数据进行预处理,对ACE2005数据集进行分句、分词、词性标注、词元化、依赖解析等处理.对ACE2005中文数据集的分词工作基于词语而不是字符,这能够使分词后的数据与数据集中的标注相互匹配.本文词嵌入向量[28]使用Skip-gram算法[29]在纽约时报语料库上预训练获得.
实验相关超参数的设置如表2所示.

表2 模型的超参数设置Table 2 Hyperparameters of our model
4.3 总体性能
将本文模型在ACE2005英文数据集上与下列两类基线模型进行对比:
1)基于序列的模型:
• DMCNN模型[9]由Chen等人提出,采用动态多池化卷积模型来保存多事件的信息;
• JRNN模型[12]由Nguyen等人提出,使用双向RNN和人工设计的特征联合提取触发词和事件元素;
• DMCNN-DS模型[10]由Chen等人提出,使用FreeBase大型知识库通过远程监督来标记无监督语料库中的潜在事件.
2)基于GNN的模型:
• GCN-ED模型[13]由Nguyen和Grishman提出,使用基于GCN的参数池机制进行事件检测;
• JMEE模型[14]由Liu等人利用自注意力和高速网络(Highway Network)增强GCN,提高GCN的事件检测性能;
• EEGCN模型[15]由Cui等人提出的一种新的边缘增强图卷积网络体系结构同时利用了句法结构和类型依赖标签信息来实现事件检测;
• MOGANED模型[19]由Yan等人利用基于依赖树的具有聚合注意力的图卷积网络显式建模和聚合句子中的多阶句法表示.
本模型与上述模型在ACE2005英文数据集上的实验结果如表3所示.
根据表3可以得出以下结论:
1)使用基于GNN的模型在数据集上的分类结果明显高于基于序列的模型,这表明了在句子上运行图算法的有效性.
2)在同样借助了图特性的前提下,本文模型在触发词识别和触发词分类上要优于文献[13-15,19],这是因为文献[13-15]仅仅使用基础GCN模型,使得模型分配给句子中不同邻居单词的权重是完全相同的,忽略了触发词等关键节点的重要性,本文模型可以给句子结构不同单词节点指定不同权重,使触发词分类的F1值平均提升3.7%.
3)本文基于文献[19]的优点则是在GAT的基础上加入了DEIEM,使得本文模型在构造图时额外考虑了依赖边标签信息的表示,提高了模型的性能,其中触发词分类的F1值提升2.8%.
将本文模型在ACE2005中文数据集上与下列模型进行对比:
• 文献[9]的DMCNN模型应用在中文时,模型包括对中文数据集上基于字的CDMCNN模型和基于词的WDMCNN模型;
• NPN模型[27]是由Lin等人提出的结合字和词嵌入表示的方法,先进性特征信息抽取再做信息融合,以学习触发词内部结构组成,解决触发词不匹配的问题;
• TLNN模型[30]是由Ding等人针对触发词不匹配问题,提出触发词感知的Lattice LSTM网络;同时针对一词多义问题,利用外部知识库HowNet补充词级别语义信息;
• MTL CRF模型[31]是贺等人提出的使用分类训练的策略为每类事件分别训练一个基于CRF的事件联合抽取模型,解决事件元素多标签的问题.
本文模型与上述模型在ACE2005中文数据集上的实验结果如表4所示.
根据表4可以得出以下结论:
1)EIEGAT模型在ACE2005中文数据集的实验结果依旧能够高于基线模型,这表明EIEGAT模型的创新点对中文同样适用.
2)对中文数据集做分字操作的CDMCNN模型的触发词识别与分类结果明显低于分词操作的WDMCNN模型,这证明在对中文进行预处理阶段时,针对中文语言的特殊性,分词操作是必不可少的步骤.
4.4 邻接矩阵中边信息选取对模型的影响
以往GNN模型中构造邻接矩阵时通常使用依赖边+逆向边+自环边[14,15],逆向边为依赖边的反向边,即令Aji=Aij;自环即邻接矩阵中对角线位置,即令Aii=1.而本文初始邻接矩阵的构建仅使用单向依赖边还原句法结构,本节设计对比实验验证选取不同边信息构建邻接矩阵对最终结果的影响.实验结果如表5所示.
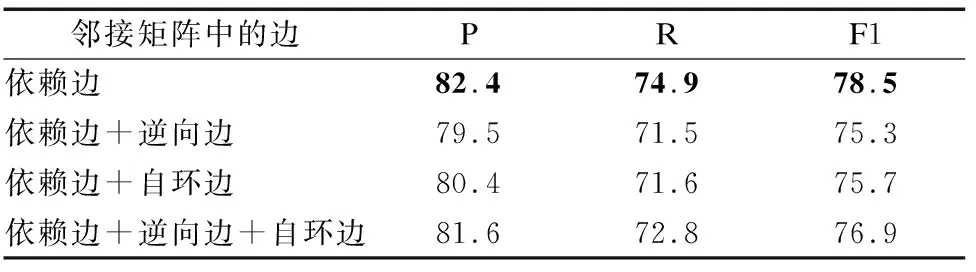
表5 邻接矩阵中的边信息选取实验结果Table 5 Experimental results of edge information selection in adjacency matrix %
由表5可得,邻接矩阵中仅使用单向依赖边的最终事件检测F1值结果最优,为了探究其原因,本文将由邻接矩阵经过EIEGAT操作后的注意力矩阵T可视化,以句子S2为例,图5为邻接矩阵中加入不同的边得到的注意力矩阵T的热力图.
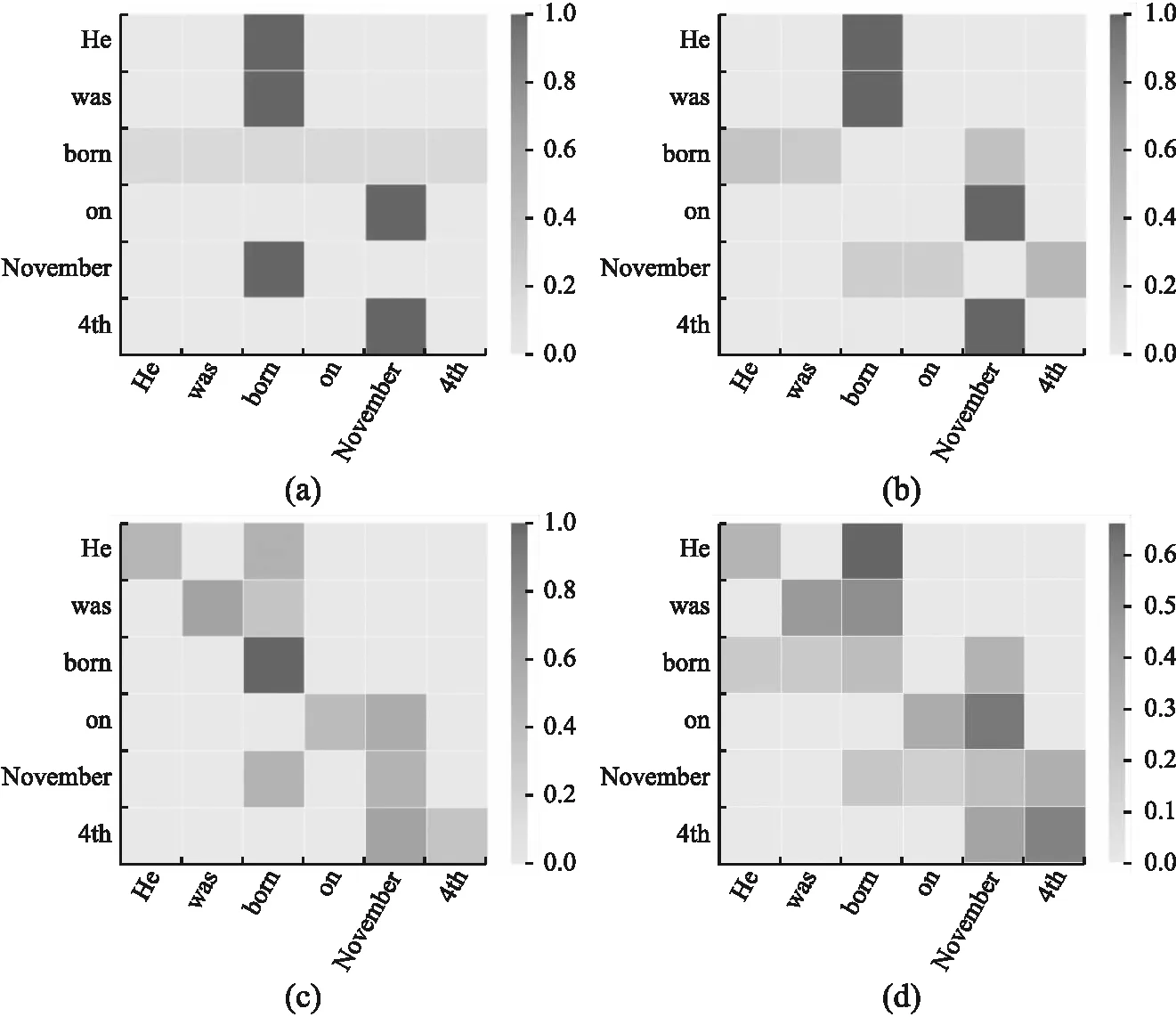
图5 注意力矩阵热力图Fig.5 Attention matrix heat map
图5(a)为邻接矩阵中仅加入有向依赖边经过EIEGAT模型后的注意力矩阵,可以看到注意力矩阵与初始句法依存图十分对应,注意力聚焦在触发词“born”处;图5(b)的初始邻接矩阵中为依赖边+逆向边,事件触发词“born”回馈了依赖它的单词节点;图5(c)的初始邻接矩阵中为依赖边+自环边,注意力更集中于注意力矩阵的对角线;图5(d)的初始邻接矩阵中为依赖边+逆向边+自环边,此时注意力矩阵中含有较多信息.
由此可得,邻接矩阵仅体现依存句法图中的依赖边时,最终模型会拟合句法图结构,给予事件触发词更高的注意力系数,随着加入更多的信息,触发词的高注意力分值会被逐渐稀释,反而降低最终结果.
4.5 消融分析
本节将评估不同的模型体系结构,以实验RNN变种模型的选择、GAT与GCN差别以及添加DEIEM与否对总体性能的影响.事件分类任务的消融实验结果如表6所示.
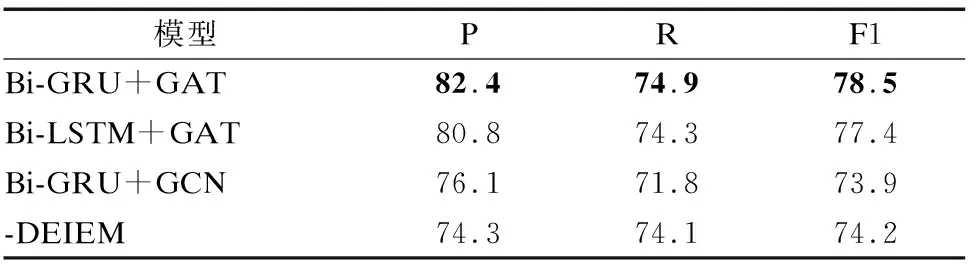
表6 模型的事件分类消融实验结果Table 6 Experimental results of event classification ablation of the model %
从表6可以看出,当RNN变种模型的选择为Bi-GRU、图神经网络选择为GAT以及添加DEIEM,事件检测模型的性能最好.由表6可得出以下结论.
1)当RNN变种模型选择Bi-LSTM时,模型的F1性能下降1.1%,且实验发现于内存占用也比Bi-GRU多约2000MB,由此表明在捕获单词上下文信息方面,使用GRU模型能利用比LSTM更为简单的结构和计算获取更佳的性能.
2)为了验证GAT模型对事件检测整体性能的影响,将GAT模型换成基础GCN模型,F1值下降4.6%,实验表明GAT模型分配句子中不同单词以不同的权重这一功能,能有效提升事件检测性能.
去除DEIEM后,模型的F1值下降4.3%,这足以表明聚合依赖边的信息,对于获得更全面的图信息、提升对于触发词的检测与分类是切实可行的改进.
5 结 语
本文提出依存边信息嵌入的图注意力网络模型用于事件检测,将依存句法树转化为图,利用图特性规范化文本中的词汇和语法变化.为了充分利用隐藏在依赖边中的信息,在图注意力网络的基础上设计依存边信息嵌入模块,将依存边的标签信息嵌入到图的邻接矩阵中,使模型在构造图时同时考虑了节点和依赖边的表示,提高模型事件检测的准确率.在获取上下文信息的RNN变种模型中,选择门控循环单元,简化计算、节省内存空间.在ACE2005中英文语料集上进行事件识别与事件分类的实验表明本模型具有效性和优越性.
