基于CNN和LSTM 混合模型的红外人体行为识别
2023-11-09童安炀王文剑
高 程,唐 超,童安炀,王文剑
(1.合肥学院人工智能与大数据学院,合肥 230601;2.山西大学计算机与信息技术学院 太原 030006)
人体行为识别(Human Action Recognition,HAR)是指通过现代计算机相关技术来识别人的行为动作的一个过程。它是计算机视觉领域中一个活跃的研究课题,在虚拟现实[1]、自动监视[2]、人机交互[3]和智能视频监控[4]等许多领域都展现出巨大潜力。然而,行为识别提取特征受光照影响严重,缺少对时域信息的整合,使得准确高效地识别人体行为仍旧是一个难题。
近年来大多数的人体行为识别研究是在可见光环境下进行的,对于夜间环境下的研究相对较少。由于传统光学相机在晚上无法正常工作,而许多影响到人身和财产安全的行为动作又常常出现在夜晚或较暗的地方。相比较而言,红外成像具有很强的鲁棒性,基本上可以排除烟尘、雨雪这些恶劣天气的干扰;具有细节保留性,能够保留较为完善的图像边缘轮廓和细节特征[5];具备较好的光照不变性,能极大地降低光照影响。因此,后续针对夜间环境下的红外人体行为识别研究具有发展意义。
本文针对红外人体行为数据集较少的现象,设计相关的人体行为动作,用专业的红外摄像机采集了足量的数据集进行实验研究。提出的混合网络模型C-L,该混合模型是基于CNN 和LSTM 两种深度学习网络,分别提取空间信息和时间信息,再按照一定的置信比进行融合的。最后通过实验对比得出更加精确的分类结果。
1 相关工作
目前,针对夜间环境下的人体行为识别方法主要分为两类:基于可穿戴传感器和基于红外视频图像。
基于可穿戴传感器的方法能够通过获取使用者的位置和运动姿态等关键特征,并利用模式识别对人体行为动作情况进行识别分类。[6]kumar 等人[7]提出一个包含加速度计和陀螺仪的可穿戴传感器,通过支持向量机(Support Vector Machine,SVM)算法对人体行为检测,得到比较高的准确率为93%。Giuffrida等人[8]提出了一种基于可穿戴传感器和机器学习的跌倒检测系统,通过提取信号的特征输入到SVM 分类器进行区分人类的行为活动。Kerdjidj 等人[9]提出一个可穿戴的Shimmer 设备,采用压缩感知的方法对人体跌倒和活动进行识别。Sun等人[10]提出了基于空时特征融合的深度学习模型,在公开的可穿戴传感器数据集DaLiAc 上进行人体行为识别的方法,总体识别率为97.6%。然而,佩戴在身上的传感器存在着很大的局限性,因为它影响了人自然自主的活动轨迹和动作。此外,这些传感器检测的主要是个人层面的活动,因此很难检测其他涉及人和物或人和人交互的复杂活动,这可以通过基于视频图像的行为识别来克服。
红外人体行为识别方法主要分为两大类:基于手工提取特征的方法和基于深度学习的方法。基于手工提取特征的方法,Shao 等人[11]提出了一种基于稠密轨迹融合特征的红外人体行为识别方法,对IADB红外行为数据库展开研究,准确率达到96.7%。Xie等人[12]提出了一种基于多尺度局部二进制模式(Local Binary Pattern,LBP)共生直方图的红外人脸识别方法,最终实验表明识别率可以达到91.2%。Su等人[13]针对FLIR 红外目标识别中复杂背景干扰等问题,提出了一种基于轮廓片段匹配和图搜索的目标识别方法,具有较好的适应性和泛化能力。Wu等人[14]提出一种基于多特征融合的红外图像目标识别算法,有效地提高了红外图像在复杂多变环境下的识别准确率。
基于深度学习的方法,Gao等人[15]提出一种双流卷积神经网络,并构建了一个红外行为识别数据集InfAR 来验证实验,平均识别率为76.66%。Liu 等人[16]提出一种基于全局时间表示的三流卷积神经网络,在红外数据集InfAR和NTU RGB+D 上取得79.25%和66.29%的平均识别率。Akula等人[17]提出带两个卷积层的监督CNN 架构来识别6 种行为动作,识别精度是87.44%;Boissiere 等人[18]提出一种结合骨架和红外数据数据的模块化网络,在NTU RGB+D 数据集上实现了比较好的性能。Jiang 等人[19]提出了一种改进的空时双流网络,采用基于决策级特征融合机制来反映行人的动作类别,有较高的工程应用价值。
2 本文方法
本文提出的红外人体行为识别混合网络模型,其总体框架如图1所示,主要步骤为:(1)对输入的红处视频图像进行预处理操作,包括灰度化、归一化和划分序列;(2)将预处理后的图像输入到卷积神经网络和长短时记忆网络中,分别训练得到动作的空间信息特征和时间信息特征;(3)将上一步得到两种不同的特征分别输入到分类器中进行决策级的得分融合,输出分类结果。
2.1 数据预处理
为了规范图像数据的格式以及提高图像数据的表征能力,本文做了一些数据预处理的工作,具体如下:
第一步,通过灰度变换将红外图像转为灰度图像,设输入红外图像为I(x,y),灰度化为Gray(⋅),得到的灰度图像为G(x,y),即
因为灰度图像每个像素只需要较少的空间存放灰度值,所以能够提高运算速度,节约时间成本。
第二步,为了增加图像处理的效果,需要对图像进行规格化。设输入图像为G(x,y),调整尺寸为Re(⋅),调整后得到的图像为R1(x,y),即
将输入图像尺寸规格化为120×120输入到网络中。
第三步,数据归一化是利用特征的最大最小值,将特征的值缩放到[Min,Max]区间,计算公式如下
其中:R1(x,y)是Step2 中尺寸规格化后得到的图像;R1min 是R1中取的最小值;R1max 是R1中取的最大值;R(x,y)是是数据归一化后的图像。另外Max取1,Min取0,即原本的数据映射到了[0,1]这个区间,由此可以加快梯度下降求解最优解的速度。
2.2 CNN网络
本文在空间域上设计了一个卷积神经网络,是一个由很多不同功能的网络层交替出现组成的层级结构网络,包括输入层(1 层)、卷积层(2 层)、池化层(2 层)、全连接层(2 层)、输出层(1层)等,卷积神经网络模型,如图2所示。该网络处理图像数据具体操作如下。
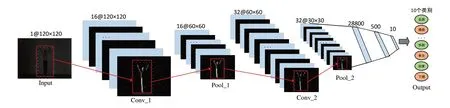
图2 卷积神经网络模型
1)卷积层由多个卷积单元组成,输入图像经过预处理以120×120的尺寸输入,可以提取人体行为不同的局部区域特征。由图2所示,Conv_1和Conv_2分别是两次卷积后的人体行为特征图,为了保留边缘信息,卷积得到的特征图经过padding尺寸大小保持不变。卷积层的计算公式如下。
其中:为第l层中第(i,j)点的输入值;Yli,j为第l层中第(i,j)点的输出值;mh为第l层中局部感受野[20]的高度值;nw为第l层中局部感受野的宽度值;为第k层中卷积核(i,j)点值;bl为第l层的偏移量。
2)本文的激活函数选择ReLU 函数,可以对网络进行稀疏化处理,加快训练速度及防止梯度消失[21]。数学表达式如下。
其中:当输入x<0时,ReLU函数的输出为0;当输入x≥0时,ReLU函数的输出为x。
3)本模型中池化层选取的池化方法是最大池化,它可以对特征进行降维,提高算法的运行速度和性能。由图2 所示,Pool_1 和Pool_2 分别是两次池化后的人体行为特征图,尺寸均为之前输入特征图的一半。计算公式如下
其 中:Xm,n表示当前的输入值;Yi,j表示池化后的输出值,m∈(i×H,(i+1)×H-1),n∈(i×W,(i+1) ×W-1);H和W分别为池化窗口的高度和宽度。
4)本文全连接层设置了两层,如图2所示,第一层长度是28 800,作用是将卷积层提取的特征进行线性组合,第二层长度是500,实现了对输入的数据进行高度的非线性变换的目的。
5)输出层采用softmax函数计算各个类别的概率值,函数的具体形式如下。
其中:yi为softmax的输出概率值;xi为softmax的输入值;n为softmax的输入值个数。
2.3 LSTM 网络
本文构建一个双层LSTM 网络用于时序特征的挖掘,如图3所示,输入的红外图像经过预处理划分为t个序列,这里的t取值为120。将划分的图片序列经过LSTM 单元后,对应会输出h11,h12...h1t,然后输入到下一个LSTM单元,输出h21,h22...h2t,最终所有时序信息都输入到softmax进行分类。
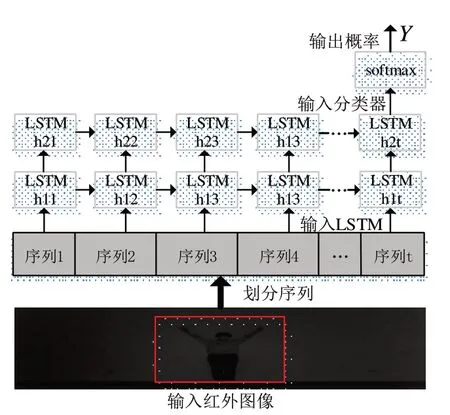
图3 双层LSTM 网络分类模型
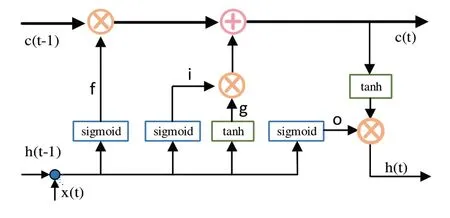
图4 LSTM 结构单元图4 LSTM 结构单元
LSTM结构单元中三个门的步骤具体如下:
1)遗忘门f:表示从h(t-1)传进来的输入信息有多少可以通过。公式如下
其中:f是遗忘门的激活;Wf为输入层到f的权重向量;bf是遗忘门的偏移量。
2)输入门i:表示当前输入x(t)新计算出来的状态有多少可以通过。公式如下
其中,i是输入门的激活,Wi为输入层到i的权重向量,bi是输入门的偏移量。
3)输出门o:决定哪些信息可以被当成当前状态的输出。公式如下:
其中:o是输出门的激活;Wo为输入层到o的权重向量;bo是输出门的偏移量。
2.4 时空特征融合
基于CNN 和LSTM 融合的C-L 网络模型经过预训练分别提取出空间、时间特征向量,但是单一的特征向量包含的特征维度不够,表征能力和模型泛化能力不足。而融合不同的隐含特征是提高模型识别性能的重要方法,卷积神经网络包含大量的空间特征信息描述,长短时记忆网络可提取大量时间特征信息描述,融合两者特征优点可以使训练识别分类的精确度有所提升。目前主流的特征融合方法有三种:像素级融合、特征级融合、决策级融合。[22,23]
本文通过实验对比,选取决策级融合中的得分融合方法,取代传统的最大值融合方法,加强模型的容错性和实时性,提高模型的泛化能力。本文采用的融合策略如下式所示
其中:F是融合后的得分:C是CNN 网络分类的概率分布:L是LSTM 网络分类的概率分布,α+β=1,α≥0,β≥0。
本文通过实验做了各种不同比例的加权融合进行对比,得到了最好的识别结果,如表1 所示。接着再通过argmax()函数找到一组概率中最大值出现的位置,即得到特征信息最终被分到的类别。

表1 在不同数据集下,采用不同融合比例时的识别率/%
3 实验分析
3.1 实验环境
本文具体的实验环境参数如下:CPU 为Intel Core i9-11900F@2.50 GHz 8 cores;GPU 为Nvidia Ge-Force 3060 11G;操作系统为Ubuntu 20.04;编程语言为Python3.7;采用深度学习框架pytorch,建立网络模型进行训练和测试,其中两个网络模型的batch_size 均选取64,CNN 网络模型学习率为0.001,LSTM网络模型学习率为0.01。
3.2 数据集
人体行为数据集的更新和发展为计算机视觉领域的崛起奠定了很重要的基础。但是与可见光领域公开的人体行为识别的数据集不同,红外的人体行为识别公开的数据集少之又少。为验证本文研究方法的有效性与可行性,我们用于实验的数据集包括公开的红外图像数据集,公开红外视频数据集(Infrared Action Dataset,IAD)以及自建红外人体行为数据集。
公开红外图像数据集,包括受试者在单一场景下执行的一系列的简单动作。该红外数据集于网上下载所得。是一组背景简单、视图单一的数据集,共1680 张图像帧。数据集中5 个不同受试者的6 种人体行为:坐下(a)、跑步(b)、站立(c)、转身(d),走路(e)、躺倒(f)。其示例如图5所示。
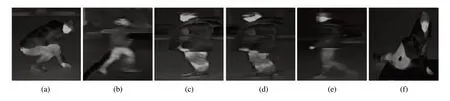
图5 红外图像数据集
公开红外视频数据集IAD,动作类型包括12个类别,每个动作类别有30个视频剪辑,所有动作都由25名不同的志愿者执行,视频由手持红外摄像机IR300A拍摄,每个剪辑平均持续4秒,帧速率为每秒25 帧,分辨率为293×256。12 个动作类别分别是Fight,Handclapping,Handshake,Hug,Jog,Jump,Punch,Puch,Skip,Walk,Wave1,Wave2。其中每个视频包含一个人或几个人执行一个或多个动作。其示例如图6所示。

图6 红外动作数据集
自建红外人体行为数据集HFUU Infrared HAR,数据集是用固定的红外热成像摄像机以25fps 的帧速率记录的单一背景的数据集,共200 个视频序列。其中红外摄像机的参数有:录像分辨率:4K 2880×2160(24FPS),数码变焦:16X,焦距:f=7.36mm,光圈:F3.2 等。数据集中提供了同种场景下20个不同受试者的10种人体行为:走路(a).Walking、慢跑(b).Jogging、快跑(c).Running、双手挥(d).Wavings、拳击(e).Boxing、拍掌(f).Clapping、单手挥(g).Waving、跳跃(h).Jumping、下蹲(i).Crouching、弯腰(j).Bending。其示例如图7所示。

图7 HFUU红外人体行为数据集
4 实验结果及分析
本文的实验是在一个公开的红外图像数据集,IAD 和自建的红外视频数据集上进行的,然后通过对比实验,验证了本文方法的有效性。其中,公开的红外图像数据集有6 个行为动作,分为训练集和测试集,训练集共1200 张图像,测试集共480 张图像,IAD 红外数据集共有12 个类别,600 个动作视频,而自建的红外视频数据集有10 个类别,200 个动作视频,进行分解后得到74385 张视频帧。由于样本的数量有限制,在训练过程中采用十折交叉验证的方法对数据集进行划分学习研究,保证模型对数据的充分学习。
识别准确率如表2所示,它对模型整体的泛化能力有更直观的表达,计算公式如下

表2 不同算法在不同数据集的准确率%
其中:TP表示分类正确的样本数;Total表示分类的样本总数。
由表2可知,本文的C-L模型在公开数据集,IAD红外数据集和自建数据集上的分类效果比单一的CNN 模型和LSTM 模型有明显的提升。在公开数据集上C-L 模型比CNN 模型高1.6%的准确率;在IAD红外数据集上C-L 模型比CNN 模型高1.47%的准确率,并且比原作者提出的传统方法要高7.62%的准确率,明显地提升了识别效果;在自建数据集上C-L 模型比CNN 模型高1.95%的准确率,比LSTM 模型高4.76%的准确率。另外由于公开的红外数据集数据量较小,且是不连续的图像,所以运用针对时序较为有效的LSTM 模型效果不是很好,只有61.95%的准确率,但这个问题在IAD 红外数据集和自建的红外数据集上就不复存在,自建数据集是拍摄的红外视频,处理后对连续的视频帧进行训练测试,最后得到了比较好的识别结果。
另外,还可以从多方面的模型评价指标来表达实验的完整性,包含精确率(Precision,P)、召回率(Recall,R)、F值(F-Measure)三个常用来表示模型精度和泛化能力的重要评价指标。其中,精确率P表示的是预测为正的样本中有多少是真正的正样本。计算公式如下
其中:TP是真正例(True Positive,TP);FP是假正例(False Positive,FP)。
召回率R表示的是样本中的正例有多少被预测正确。计算公式如下
其中,FN是假反例(False Negative,FN)。
还有一个常见的方法是F-Measure,指的是通过计算F值来评价一个指标。以下是其中一个具体计算公式
其中:P代表Precision;R代表Recall;F1 综合了Precision与Recall的产出的结果。
从表3可以看出,C-L混合模型的三项评价指标的结果都比单个CNN和LSTM网络要明显高,足以证明了混合模型有效提高了模型的精度和识别能力。其中,公开红外数据集的LSTM 模型精度低也是因为该数据集是由不连续的帧组成,没有形成时间上的一个序列,破坏了LSTM 的时序依赖性,从而结果不是很理想;但自建的红外视频数据集和IAD 红外数据集是连续的视频帧,LSTM 模型识别结果正常。

表3 两种红外人体行为数据集的PRF值
如图8,9所示,分别为基于公开红外图像数据集和自建红外视频数据集的行为识别混淆矩阵,图中每一列代表预测类别每一行代表该活动的真实归属类别,每个动作的准确度也是直观的以小于1 的概率值输出。由图8、9 可知,CNN 和LSTM 结合后,数据集中几乎每个类别的准确率都比单个模型得到了提升。其中,在公开红外数据集的sitting、lying-down 动作上实现100%的准确率,在自建的红外数据集的boxing 实现了100%的准确率,在wavings、claping、bending 动作上也都取得了高达99%的准确率,足以证明了混合模型C-L在提高图像特征和模型训练上更有优势,对实现动作分类更加有效。

图8 公开红外数据集的混淆矩阵

图9 自建红外数据集的混淆矩阵
5 总结
为了提高和加强人体行为识别在红外即夜间环境下的识别率,本文提出了一种基于CNN 和LSTM的混合模型C-L 的红外人体识别方法。通过将卷积神经网络提取的空间信息和长短时记忆网络提取的时间信息进行融合,采用各自的置信度占比,通过实验结果,得出最合适的权重比例,从而选出最佳的融合结果。在公开的以及自建的红外人体行为三个数据集上的实验结果表明,对比单纯使用CNN 和LSTM神经网络,混合模型C-L不仅在识别率上优势明显,抗干扰能力和不依赖个体能力也较强,从而证明了本文方法的有效性,是一个很好的方案。
