基于绕城高速收费数据的车辆特征识别及应用
2023-11-09赵国祥李芷倩高晋红
李 男,赵国祥,李芷倩,张 敏,高晋红
(1.河北高速集团工程咨询有限公司,河北 石家庄 050000;2.河北高速公路集团有限公司承德分公司,河北 承德 067000;3.长江航道规划设计研究院,湖北 武汉 430040;4.长安大学运输工程学院,陕西 西安 710064)
0 引言
绕城高速是指环绕城市修建且被纳入国家或地方高速公路网的高速公路,主要解决城市通勤车辆的疏导问题。对于旅游城市,旅游旺季期间的出行量较大,绕城高速也分担部分的交通疏解压力,导致利用绕城高速进行出行行为的复杂性增加。因此,精确识别车辆通勤及其他出行特征对于提高绕城高速的通行效率尤为重要。
随着交通信息采集系统的建设完善,高速公路收费流水数据为城市拥堵及其内在规律的分析提供了条件。李树彬等[1]利用高速公路进出口收费站数据,采用仿真手段将动态OD 进行网络加载,从而产生实时的高速公路全路网无缝覆盖的网络状态估计。郭瑞军等[2]通过高速收费流水数据统计分析高速交通流量的时变规律、行程速度分布,分析高速公路的交通流特性。胡继启[3]通过分析高速公路交通拥堵和行程延误时间之间的关联性,提出了基于行程延误的高速公路交通拥堵判别与定位算法。杨庆芳等[4]探讨了利用高速公路收费数据作为数据依据进行道路状态评价的可行性。魏广奇等[5]借助K-means++聚类方法识别高速公路日常通勤的车辆,进一步分析通勤车辆的出行时空分布特征。
综上,目前对于收费数据的应用主要集中于研究路网运行状态评价指标,研究车辆出行特征较少。同时,城市道路网的规划都是从满足居民日常通勤出行需要的角度出发,而旅游城市中的旅游客流必然对城市日常交通产生一定影响。旅游出行的行为特征区别于通勤出行,因此有必要运用收费数据对通勤及其他出行行为进行识别、分类研究。
本文以绕城高速收费流水数据为基础,提取有明显通勤及其他特征的车辆,分析其出行时空分布特征,为优化绕城高速收费站管理及缓解城市交通系统问题提供方法支撑和相应的辅助决策信息。
1 数据及预处理
1.1 基础数据
基于我国京津冀地区某旅游城市绕城高速公路收费交易流水数据,重点关注载客车辆的出行情况,主要分析客车的收费数据,数据字段见表1。

表1 高速公路收费流水数据格式
1.2 数据预处理
通常情况下,缺失值所占比例很小,且样本数据量大,故采用删除法移除所有含有缺失数据的行。将含有异常值的数据用平均值进行修正。与此同时,从绕城高速收费站点的数据中分离出工作日的一型客车数据,以供车辆出行特征识别。
为有利于分析车辆出行空间分布,进行地图匹配。借助网络上的电子地图数据获取底图,在此基础上,使用ArcGIS 绘制电子地图,其中包括空间地物的地理位置信息和路段、节点的拓扑关系信息。
2 出行特征识别
2.1 出行特征界定
基于高速公路的通勤车辆属于城市通勤交通的一种,具有与通勤交通类似的出行行为特征,主要包括以下几种类型:①出行的时间与地点相对稳定;②工作日早晚高峰基本都有出行;③工作日平峰间基本没有出行[5];④出行存在往返性[4]。旅游交通的特征与通勤交通部分相同,包括每天首次出行的地点通常固定,且连续一段时间内均有出行。不同之处在于旅游交通在平峰也可能有出行,时间相对不固定,地点通常集中在旅游景点周边。
2.2 出行特征提取
聚类分析算法不依赖预先定义类或者带类标记的训练实力,将相似的对象归到同一类[6],最经典的聚类算法有K-means和模糊C均值算法等;随机森林算法是一种有监督的集成学习分类技术,对于高维数据,随机森林的综合性能指标明显优于其他单分类器[7]。由于数据量较大,特征较多,随机森林具有良好的泛化性、准确性,适合用来对聚类分析后的结果进行精度验证。
2.2.1 K-means聚类算法
最佳聚类中心数的确定通常采用“手肘法”,手肘法的核心指标是误差平方和(SSE)。SSE是所有样本的聚类误差,代表了聚类效果的好坏。
基于K-means 算法的不足,提出了改进,主要有以下方面:①对于初始k 值的确定,先设置选定月份的总出行天数、工作日天数及该月每天的出行车辆数作为约束条件,再运用“手肘法”计算聚类误差,可以预先观察相对合理的聚类数;②关于初始聚类中心的选取,采用了基于密度的初始聚类中心选择方法,其基本思想是针对每一个特征值,计算以该特征值为圆心,以α(设置为该特征值平均数)为半径的圆中包含其他特征值的个数,并以此作为该特征值的密度,然后根据密度排序,选取密度最大的前k 个特征值作为初始聚类中心;③在聚类的过程中,加入外部约束条件进行调整,得出满足选定月份总天数、工作日天数和早晚高峰时间段的个数等约束条件的最优结果。
2.2.2 聚类变量
提出基于高速公路的出行识别的特征变量:
①X1,在车辆每天的首次出行中,以最常选择的起始收费站进行出行的天数。
②X2,在工作日车辆全天有出行的天数总和。
③X3,在工作日平峰时段(09:00—16:00、18:00—次日07:00)有出行的天数总和。
④X4,在该月份中车辆出行的连续天数总和。
⑤X5,在工作日早高峰时段(07:00—09:00)或晚高峰时段(16:00—18:00)有出行的天数总和。
2.3 识别结果验证
采用R 软件中的randomForest 包建立随机森林模型[8],首先指定节点中用于二叉树的变量个数,即mtry参数,对mtry 的选择是逐一尝试,直到找到比较理想的值;再指定随机森林所包含的决策树数目,即ntree 参数,对ntree 的选择则通过图形判断模型内误差稳定时的值。由于随机森林算法在构建每棵树时,随机且有放回地抽取训练集中的数据,没有参与的数据则是该棵树的袋外样本数据。该特点允许使用袋外数据误差评估算法的有效性。
在计算随机森林中变量的重要性时,通过随机打乱变量并观察模型的性能变化,可以评估变量的重要性。模型的准确率或GINI 系数显著下降,表示变量的重要性越高。
3 实证分析与讨论
为验证绕城高速公路车辆出行特征分析方法的可行性,以京津冀地区某城市作为实例进行分析。该城市绕城高速的东西向路段全线双向四车道,设计速度120 km/h,南北向路段全线双向六车道,设计速度100 km/h,最高限速均为100 km/h。其中共有9 个收费站,从1 到9编号,布局如图1所示。
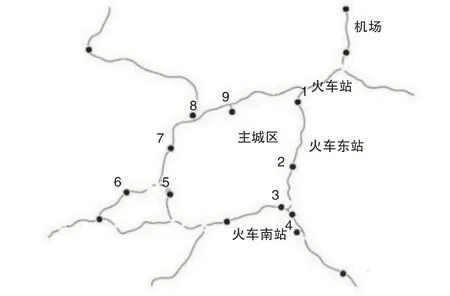
图1 绕城高速布局示意图
3.1 出行特征识别
3.1.1 识别结果分析
2021 年7 月份的工作日22 天,非工作日9 天,在该城市境内出现的客车约27 万辆,产生了约58 万条流水数据。对每一辆车Xi生成相应的特征向量Fi=[X1,X2,X3,X4,X5],根据“手肘法”确定最佳聚类中心数k为3。
采用K-means 算法对车辆的特征矩阵进行聚类分析,聚类中心与结果分布见表2。因聚类分析对噪声点敏感,可从结果中看出第1 类数据分布较为离散,即为数据集中的噪声点,舍弃该类数据。提取第2、3类车辆的矩阵特征值,分别绘制概率密度函数图,如图2和图3所示。

图2 第2类车辆的概率密度函数图
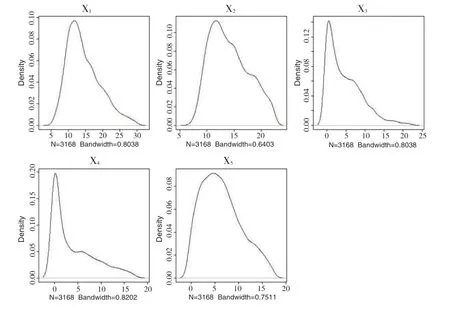
图3 第3类车辆的概率密度函数图

表2 K-means聚类中心与结果
由图2 可以看出,在第2 类车辆中,所有车辆的X1主要集中在2天~7天;X2则相对较大,集中在3天~8天;X3比前两者小,分布在0~5 天;X4更小,基本聚集在0~2天;X5分布与X3接近,集中在0~5 天,均小于8 天。上述特征说明,第2类车辆在一段时间内出行的时间与地点相对稳定,连续出行天数较短。此外,工作日与非工作日、早晚高峰与平峰的出行天数基本都接近,具有明显的旅游特征,占绕城高速出行车辆比例的8.11%左右。
由图3 可得,在第3 类车辆中,所有车辆的X1均大于5 天,且主要集中在10 天~20 天;X2相对较大,集中在11 天~21 天;X3比前两者小,分布在1 天~12 天;X4聚集范围更小,基本聚集在0~5 天;与X4相比,X5分布则较大,集中在5 天~15 天,但均小于20 天。上述特征说明,第3类车辆出行地点趋于长期稳定,工作日早晚高峰基本都有出行,且平峰出行较少,具有明显的通勤特征,占绕城高速出行车辆比例的1.17%左右。
3.1.2 结果验证
文中的mtry=2,ntree=400,此时袋外数据误差为0.09%,模型拟合较好。在本文中,通过模型准确率和GINI 系数的数值判断影响最为重要的是工作日的出行天数,最不显著的是连续出行天数。
结果表明运用聚类算法分类的误差较小,其中类别1 的误差为0.02%,类别2 的误差为0.55%,类别3 的误差为2.68%。数据表明,工作日出行天数的多少最能区分通勤与非通勤交通。
3.2 车辆出行特征分析
3.2.1 通勤车辆出行空间分布
①早高峰车辆入口与出口情况。
早高峰时段(07:00—09:00)通勤车辆进出绕城高速公路的空间分布如图4所示。从空间分布来看,早高峰通勤车辆进入量较大的收费站主要有3 号和2 号收费站,离开量较大的收费站主要集中在3 号和4 号收费站。可以看出,早高峰时的通勤车辆集中在该城市东侧的主城区,但也有部分通勤车辆从主城区流向另一城区,基本是从居住区域往核心办公区行驶,通过绕城高速进行接驳,再进入城市道路。
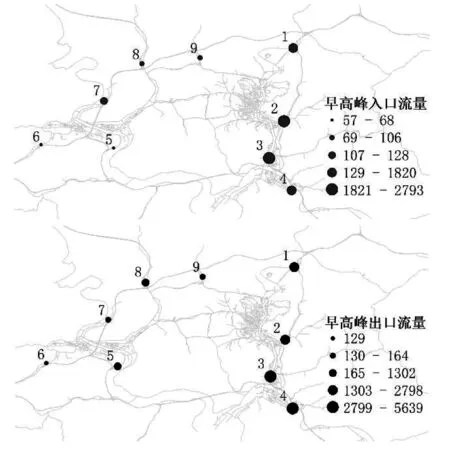
图4 早高峰车辆入口与出口的空间分布
②晚高峰车辆入口与出口情况。
晚高峰时段(16:00—18:00)通勤车辆进出绕城高速公路的空间分布如图5所示。由图可知,晚高峰通勤车辆进入量较大的收费站主要有1 号和4 号收费站,离开量较大的收费站主要集中在3号收费站。总体上,晚高峰通勤车辆流向趋势与早高峰相反,主要是从办公区往居住区扩散。说明主要居住区位于2 号和3 号收费站周边,核心办公区位于1 号和4 号收费站周边,具有明显的职住空间分离的特征。
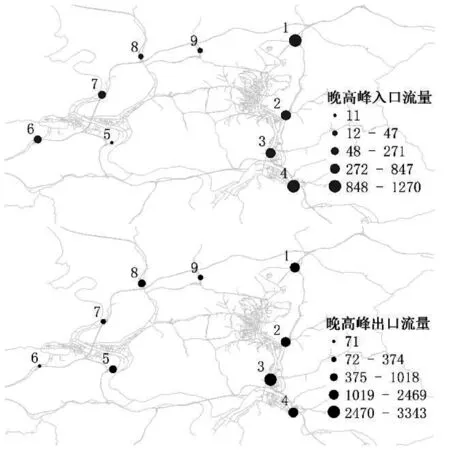
图5 晚高峰车辆入口与出口的空间分布
③平均到达里程。
统计通勤车辆由各个收费站进入后的平均到达里程,如图6所示。

图6 绕城高速公路收费站平均到达里程分布
其中,4 号和5 号收费站的平均到达里程最大,在20 km~23 km之间,3号收费站的平均到达里程接近20 km,1 号、9 号和7 号收费站的平均到达里程较小,为15 km~17 km,2号和8号收费站的平均到达里程最小。综上,绕城高速大部分收费站的平均到达里程集中分布在10 km~20 km之间。
3.2.2 旅游车辆出行空间分布
统计旅游车辆驶离高速公路的收费站空间分布情况,如图7所示。从各收费站所处地理位置来看,由于3号和4号收费站与火车站相近,2号收费站位于主城区,且毗邻火车站,而1 号收费站也临近火车站,又是该城市往来机场的必经之路,因此呈现明显的旅游交通流集中分布的趋势。
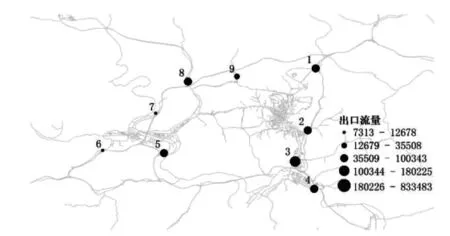
图7 旅游车辆出口的空间分布
3.2.3 车辆出行时间分布
①通勤车辆出行时段占比情况。
统计工作日每小时通勤车辆进入高速公路收费站的比例,如图8所示。可以得知通勤车辆出行的早晚高峰占比较高,且出行量在图中呈现双高峰趋势,表明该类车辆具有明显的通勤出行特征。此外,相比晚高峰时段(16:00—18:00),车辆在早高峰时段(07:00—09:00)内的出行峰值更高,说明通勤车辆更愿意在早高峰使用高速公路通勤出行,可能原因是早高峰的时间成本高,使得车辆偏向于使用高速公路达到快速出行的目的。
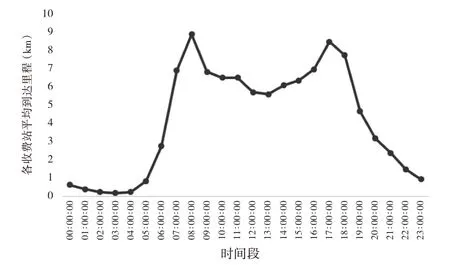
图8 通勤车辆每小时出行量占比分布图
②旅游车辆出行时段占比情况。
统计7 月的每小时旅游车辆进入高速公路收费站的比例,如图9所示。可以看出旅游车辆的出行量在图中呈现双高峰趋势,在11:00 附近达到第一个峰值,其后有短暂的下降,在18:00左右达到了第二个峰值。此外,从6:00 开始,出行量呈正比例稳步增长,且在两个峰值之间总体保持较高的值。数据表明,旅游出行的时间段基本分布在全天的黄金游玩时间,且双高峰的聚集时间在就餐时间附近,符合旅游出行的目的。
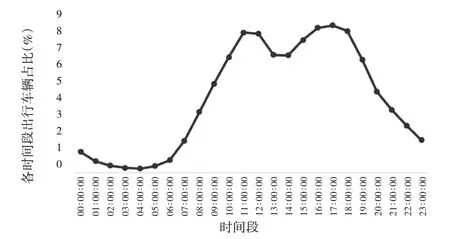
图9 旅游车辆每小时出行量占比分布图
3.3 应用与讨论
为验证本文所提出的车辆特征识别方法的适用性,将分析得到的时空分布特征应用于交通走廊判别方面。交通走廊通常被定义为市域范围内以主干道为载体,集合多种运输方式,具有共同流向的,贯穿城市不同组团的交通通道[9]。交通走廊按照研究地域广度可划分为3 个研究层次,即国家或国际交通走廊、区域交通走廊以及城市交通走廊[10]。本文从城市交通走廊的层次研究,按照功能细分为通勤走廊和旅游走廊,均采用客运量指标、空间集聚度指标、时间集聚度指标进行判定,见表3。

表3 交通走廊分类评价指标
结合车辆出行特征分布,满足上述3个评价指标可有效判别城市客运交通走廊。挖掘城市绕城高速上通勤与旅游的快速出行廊道分布,有利于分析大运量客运交通的线路走向,对引导城市交通发展有及其重要的意义。
4 结语
①利用改进K-means 聚类方法识别使用绕城高速公路进行通勤与非通勤出行的车辆,进行分类提取,再利用随机森林算法对分类结果的准确性进行验证。从通勤出行的角度,挖掘城市通勤快速出行的时空分布;从旅游出行的角度,分析绕城高速公路疏解旅游车流的运行情况。车辆出行特征可运用于判定城市绕城高速公路上的客运交通走廊,对提升城市交通系统效率具有重要的影响。
②以京津冀地区某城市为例进行实证分析。通勤车辆的空间分布明显区分就业地和居住地,与土地利用性质基本一致;通勤出行的到达里程较小,主要为短途出行;通勤交通的早晚高峰交通流占比大。旅游交通在空间分布上聚集于火车站、高铁站以及机场等客运场站附近,高峰时间处于就餐时间附近。
③在分析城市通勤与非通勤交通的特征时,侧重于考虑时空分布特征,在后续研究中,需进一步完善各个类别车辆在绕城高速上的运行状态与收费情况的构建与分析,对优化城市交通系统结构有重要作用。
