面向异构数据的风电大数据质量治理方法
2023-11-09马辉张二辉刘一丁徐兴朝田嵘
马辉, 张二辉, 刘一丁, 徐兴朝, 田嵘
(1.北京金风慧能技术有限公司,北京 100176; 2.河北新天科创新能源技术有限公司,河北,张家口 075000;3.江苏金风软件技术有限公司,江苏,无锡 214000)
0 引言
近年来以“大数据”“云计算”“物联网”为代表的信息科学技术在风电行业得到广泛的应用,提高了电力企业生产、运营工作的自动化、信息化水平,大量数据积累以及缺少有效数据管理方法将带来一系列数据管理及应用问题,低质量的风电大数据将对决策产生误导,严重时产生有害结果[1-2]。
针对风电大数据质量存在差异的问题,文献[3]对智能电网的大数据特征进行分析,建立数据质量的评估管理体系,调度中心积累电网运行、生产管理和市场运行方面的大量数据。由于这些数据存在分散性和异构性,很难直接挖掘到数据背后隐藏的信息。文献[4]提出标准化的数据质量管理规范,加强对数据质量的管控和评估,提高了电力企业决策分析的合理性和实用性。但由于数据质量的复杂性,形成广泛应用的评估指标较为困难。
1 大数据环境下的风电数据质量评估系统设计
本文构建一套风电数据质量评估系统,风电数据质量评估系统由数据源、大数据处理模块、数据结果集、数据评估和具体应用模块组成,能够实现风电大数据的自动化、智能化评估[5]。对风电大数据质量评估之前,先对数据集进行可信分析,根据时间和上下文的动态变化进行信任度的动态更新。可信度的计算先计算直接数据源的可信度,再计算具有邻接关系的间接数据源的可信度。通过对异构数据信息处理,以实现多种形式数据的风电数据质量评估和计算,增强了数据兼容能力。本文的风电数据质量评估系统功能架构示意图如图1所示。

图1 风电数据质量评估系统结构
本文系统应用RDS关系型数据库服务,提供数据监控、异地容灾和故障恢复的功能,RDS的内核基于MySQL和PostgreSQL,并能够兼容Oracle,通过线程池技术提高了数据库的并发处理能力,并增强了查询缓存机制,面对大量数据库连接时能够保持较高的性能。系统根据得到数据可信度,将可信度低的数据移除,提高了数据质量。然后对系统底层各异构数据源进行整合,并提出基于贝叶斯网络的数据质量优化方法[6]。利用朴素贝叶斯结构对划分得到的子空间建立关联模型,将数据质量不达标的数据字段的状态发送给关联模型库,利用关联模型库对参数进行诊断。
本文系统基于KEYValue的一种REDIS的缓存服务,有效解决了系统数据读写速度较慢的问题,提高了系统的数据查询能力。REDIS提供更加多样的数据结构和便捷的数据持久化方法,支持字符串、链表、有序集合等数据存储类型,通过SDS、LRU和TTL等数据处理方法加快了缓存系统的速度。通过对数据的分析结果,对风电数据进行计算,分析数据的有效性得到数据质量评价结果[7]。具体应用模块对系统的功能进行管理,并将数据质量评价结果进行界面展示。通过接口编程,为其他文件类型提供统一的抽象实现,使功能模块具有更好的可扩展性。
2 关键技术分析
2.1 基于可信分析的风电大数据质量评估模型
应用数据前需要对风电数据的质量进行评估,判断给定质量不同的多维度数据中的数据是否有用,数据反映出的可靠性表示数据本身的质量。基于可信分析的风电大数据质量评估模型的硬件结构如图2所示。
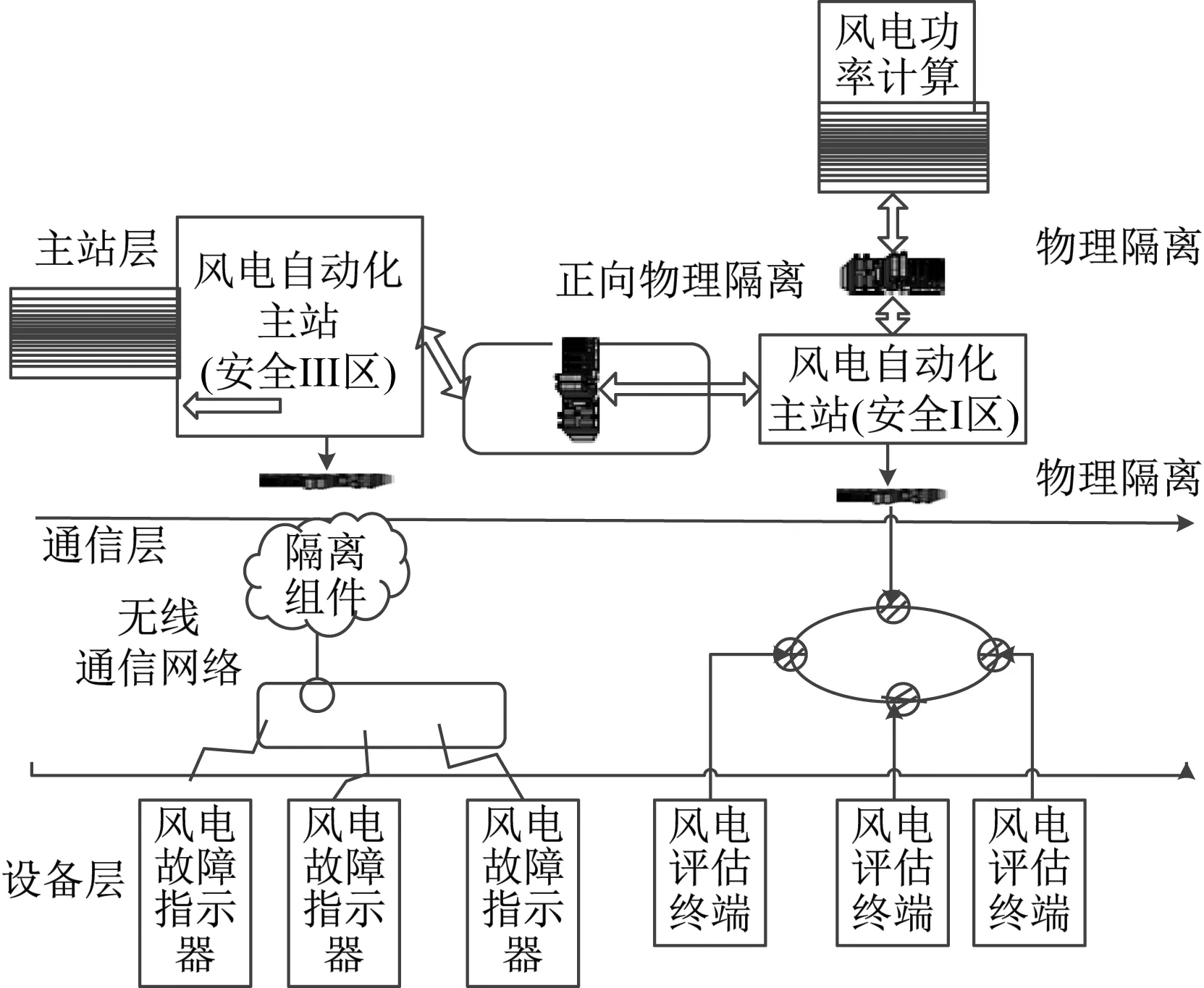
图2 硬件结构示意图
硬件结构中包括了风电故障指示器、无线通信网络、隔离组件和风电自动化主站等,通过主站层获取硬件数据评估特征。在评估数据信息时,为提高数据质量评估模型的可靠性,通过可信分析判断数据来源是否可靠,并利用层次分析法对评估结果进行综合[8-9]。
在进行大数据治理时,数据质量评估模型的评估步骤如下。
步骤一:导入需要进行数据质量评估的数据。
步骤二:筛选数据。选择对数据质量影响较大的数据进行评估。
步骤三:可信分析。从数据源间、数据源、数据本身分析数据库中数据来源是否可信,并移除不可信数据。直接可信度可表示为
DTDn(xi,xj,C,t)=

(1)
其中,xi、xj表示可信度模型中数据,C表示数据上下文交互,t表示时间,δ表示可信度系数,ΔC=φ表示没有上下文交互,n表示数据集合中的实体,λ(t)表示外界影响数据信息的因子。间接可信度表示与目标数据有邻接关系,可信度为
ITDn(xi,xj,C,t)=

(2)
当t=0时,邻接数据的可信度均匀分配,若邻接数据与目标数据有上下文交互,间接可信度进行更新。
步骤四:设置评估规则。确实数据质量5个维度有限性、一致性、及时性、完备性和完整性的占比,通过设置好的规则对数据质量进行评估。
步骤五:得到数据质量分数。运行每个维度的每条规则得到规则得分,根据得分、权重、维度占比得出每个维度的分值,将5个维度的分值相加。
步骤六:维度综合。采用层次分析法对数据质量评估维度进行权重分析,按照权重相加得出数据质量的综合评估结果。
步骤七:质量优化。根据数据质量评价结果,针对影响数据质量较大的维度,观测数据上下游找出影响较大的流程进行改进。
本文风电大数据质量评估模型的评估流程如图3所示。

图3 大数据质量评估模型的评估流程
在上述模型中,考虑到数据集交互的动态性,在数据质量评估模型中引入时效性因子λ对应时效性,惩罚性因子δ对应数据集交互的动态变化性。若两个数据源进行交互,则乘以惩罚系数,惩罚系数与交互的正负有关;没有进行交互则数据源的信任度随时间衰减。信任度可表示为

(3)
其中,T(A,B)表示数据源A与数据源B之间的可信度,DirT(A,B,Inter(A,B))表示数据源在上下文交互情况下的信任值,Accept(A,B)表示数据源之间的相似度,λ(t)表示时间衰减函数,α1、β1表示惩罚系数,ΔI表示数据源A与数据源B之间的交互情况。如果数据源交互为正,数据的可信度增加;如果交互为负,则可信度下降。相邻数据源对数据源A的综合可信度可表示为
(4)
其中,T(data)表示数据data的可信度,Sum(A)表示数据源的总体数据量,sourcen表示n维向量,α2表示数据可信度影响程度的参数,β2为数据库影响n维向量的参数。
数据data的可信度需考虑到直接数据源和间接数据源,数据的可信度可表示为
T(data)=1-∏data∈X(1-T(X,data))
(5)
其中,data∈X表示数据与数据源X有关。直接可信度就是数据源X的可信度。
2.2 面向异构数据的数据质量优化方案
面对不断增长的风电数据,本研究提出一种优化策略提高SQL相应速度,然后通过贝叶斯网络训练关联模型库,训练好后对风电数据质量评估系统的数据源进行分析,自动定位错误的数据字段。基于贝叶斯网络的风电数据质量优化的主要流程如图4所示。

图4 基于贝叶斯网络的风电数据质量优化流程
风电大数据中存在的异构数据来自不同的数据源,不同的数据源之间存在一定的关联性,包含数据样本的特异性信息,存在数据缺失、数据噪声和数据分布不均衡的问题。本研究基于贝叶斯网络对风电异构数据进行数据质量优化,解决异构数据中的缺失问题,建立数据之间的关系模型,进行数据聚类并定位异构数据中的问题字段,对问题数据进行数据质量优化,处理原始数据中存在的噪声信息和冗余信息,优化目标为使输出的风电数据满足系统优化要求,输出包含完整的细节特征和全局特征,不同的风电数据源包含同一样本的特异性信息,且其中的数据完整不存在缺失值和冗余信息。
本文将风电数据状态空间划分成多个状态子空间,使子空间中的数据字段具有较强的关联性。对状态空间进行子空间划分的过程如下:
统计风电样本数据sample={space1,space2,…,spacep}表示风电数据在不同的时间窗口下的状态空间的集合,得到P(θi,η)、P(θi,η,θj)、P(η)。计算数据随机变量直接的条件互信息熵,并找出最大值和最小值,可表示为
(6)
其中,H(x)为信息熵,p(x)为自信息量。采用中心聚类算法对数据字段field={θ1,θ2,…,θm}进行划分,使子空间中的数据字段之间具有较强的关联性,定义两个参数之间的距离为
(7)
其中,Zmax表示条件互信息熵的最大值,Zmin表示条件互信息熵的最小值。进行聚类时随机选择k个数据字段作为中心点,每轮迭代过程中比较其他点和中心点的距离,与距离最小的中心点归为一类,迭代超过一定次数或目标函数收敛时停止迭代。
划分后的子空间为Sub_spacei={η,sub_fieldi},其中sub_fieldi表示在中心聚类算法中被分到同一类的数据字段。
对划分好的子空间分别建立基于贝叶斯网络的关联模型,从而定位影响业务数据质量的问题字段。计算每个Sub_spacei中数据字段的Score(θj)值,选出Score(θj)最大的p个变量作为问题字段输出,修改问题字段提高风电数据的数据质量。
3 应用测试
为验证本研究风电数据质量评估系统的性能,分别使用文献[3]系统、文献[4]系统和本研究系统进行实验,对比3种系统对数据的质量评估效果。实验环境如表2所示。
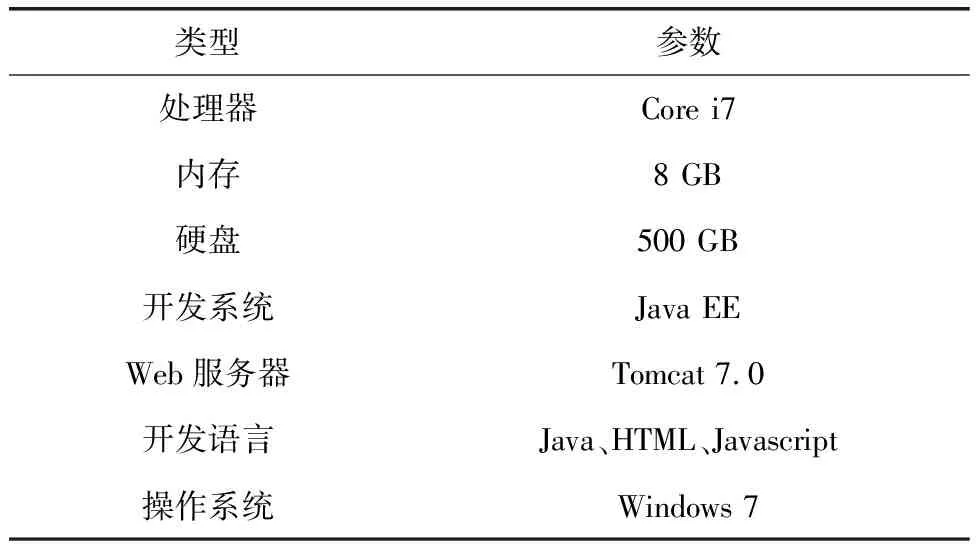
表2 实验环境
本研究实验数据通过查询风电历史数据和模拟产生,实验中模拟的数据量超过10万条,实验数据如表3所示。

表3 实验数据
试验架构示意图如图5所示。

图5 风电大数据试验架构示意图
由于实验数据中可能存在大量确实数据和噪声值,为避免对实验结果造成影响,对样本进行实验之前对数据进行预估并消除实验数据中的噪声。对缺失的实验数据进行补全和修正,与真实值更加接近。实验过程对实验数据进行5个维度的评估,完成评估后采用层次分析法将维度进行综合,得到实验数据各维度的权重分布如图6所示。
本文系统对实验数据进行质量评估参考有关数据源之间的可信度模型,选出实验数据属性列与数据源属性列相关程度低的数据,去除可信度低的数据。使用3种系统对实验数据进行数据质量评价,得到数据质量的各维度评价结果如图7所示。

图7 数据质量评价结果
对比3种系统得到的实验数据质量评价结果可知,本文系统得到各评价维度的评价结果更高,去除低可信度数据后,提高了数据质量各维度的评价结果,评价维度中的规范性和及时性高达100%,准确性为99%,数据整体质量高达95%以上。
为验证系统的数据评估效率,测试系统评估模型的执行效率,设定实验数据集大小为0~100 MB,每组实验数据集中的数据量为0~10 000,文献[3]系统和文献[4]系统作为对比实验,使用3种系统的进行数据质量评估并记录评估时间,系统的平均运行时间如图8所示,具体数据如表4所示。

表4 系统运行时间

图8 运行时间
数据量在60 M以下时,进行数据质量评价系统运行时间不超过15 s,数据量增加到100 M时,系统运行时间低至20.08 s。数据量达到100 M时文献[3]系统的运行时间达到63.45 s,文献[4]系统的运行时间高达56.47 s,评估模型的评估效率较低。
测试本文系统处理风电大数据的效率,进行数据分类实验,为减少原始数据噪声对分类结果的影响,去除原始数据集中包含的噪声信息,得到风电实验大数据集如表5所示。

表5 风电实验大数据集
为确保本研究算法的有效性,排除其他因素的干扰,将表5中的实验数据集随机划分为5个子集,选择其中1个子集作为测试集进行测试,其他的4个子集作为训练集。实验设计设定为60 min,进行5次数据分类实验,文献[3]系统和文献[4]系统作为对比实验,得到对测试集数据的分类结果如图9所示。

图9 数据分类结果
根据5次实验结果可知,本研究系统对风电大数据集的平均分类准确率为97.74%,系统处理大数据任务能够取得较好的分类效果,数据质量的优化有助于提高数据集的分类准确率,其中第4次实验时得到的分类准确率最高为99.1%。
文献[3]系统的分类准确率最高为93.8%,文献[4]系统的分类准确率最高为95.7%,第2次实验的分类准确率最低为91.8%。文献[3]系统和文献[4]系统在面对大量风电数据集时处理效果不稳定,数据分类精度出现一定的波动,分类准确率不超过96%,存在错误分类的情况。
4 总结
本文基于风电大数据特征,建立风电数据质量评估系统,结合海量风电信息数据,对评估模型进行分析和检验,从风电运行、市场运营和生产管理各个环节描述了影响数据质量的因素,并建立层次结构,提出基于可信度的数据质量评估模型,在原有数据质量评估维度的基础上进行可信分析,去除不可信数据对5个维度进行评价,进行综合得到数据质量评估结果。
本文仍存在一些不足之处还需进一步改进,在对风电大数据的研究过程中也会出现新的评估维度,评估模型也需不断更新和完善评估维度。
