基于动态异构集成的多标签数据流分类算法
2023-11-03武红鑫
丁 剑,武红鑫,韩 萌
(北方民族大学 计算机科学与工程学院,宁夏 银川 750021)
0 引 言
随着大数据技术的快速发展,生活中产生了大量的数据,为了从这些数据中获得人们所需要的信息,开展了许多与数据挖掘有关的研究[1]。这些数据呈现出连续、大容量、高速和动态变化的特点,称为数据流[2]。由于它们是海量的,同时包含多个标签数据,尤其是标签会随着数据分布的动态变化而出现,这就会导致发生概念漂移问题。因此,现有的数据流分类算法在准确性方面有很大的挑战。
许多研究者验证利用多种学习算法构成的集成比同构集成具有更高生成多样化分类器的潜力[3]。在单标签分类算法中,文献[3]利用异构集成来进行不平衡学习。文献[4]提出一种基于基分类器多样性的动态加权异构自适应集成分类器,该算法在集成中利用不同类型的基分类器和使用Q统计量来度量集成分类器之间的多样性。在处理概念随时间变化的动态数据流时,动态自适应集成可以提供一种合适的方法,可以保留长期存在的历史概念并覆盖新出现的概念[4]。同时在以往的研究中,异构集成分类器中的基分类器数量是根据分类算法的数量来确定,即它使用H个不同算法生成H个基分类器并将其构成集成模型进行预测,例如文献[5]中的异构分类模型。除此之外,文献[6]采用多种文本特征提取的主流情感进行分类集成方法。文献[7]提出一种基于GSO优化权值的异构集成学习入侵检测算法。自适应调整基分类器的数量可以更符合数据流特性,获得更高的分类结果。
针对以上问题,本文提出一种基于动态异构集成的多标签数据流分类算法(multi-label data stream classification algorithm based on dynamic heterogeneous ensemble,DHEML),主要贡献如下:
(1)提出动态生成候选分类器组E的方法,使E中的候选基分类器始终可以很好处理新实例,为构建异构集成分类器HE做准备。
(2)提出自适应选择策略来动态集成HE,提高集成分类器的泛化性。
(3)在大量数据集上进行实验,DHEML在4个评估指标中均获得最好结果。
1 提出的DHEML算法
1.1 候选分类器组的动态生成策略
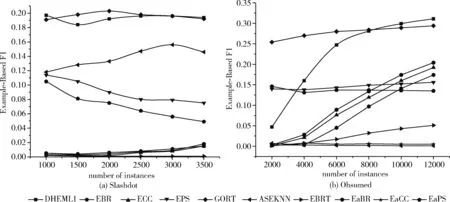
DHEML使用H个分类算法对固定大小的数据块Dt训练生成候选分类器组E={E1,…,Eh,…,EH}, 其中Eh={Ch1,…,Chm,…,ChM}。E的生成过程中,共有两种情况。为了限制E中候选基分类器的数目,设置上限值为K。第一种情况是当数据块个数T (1) (2) 取w的偏导数,并将梯度设置为零,得如式(3)所示 (3) 将式(3)化简为式(4) (4) 为了更好适应新传入的实例,DHEML会使用式(4)计算E中每个候选基分类器的权重,选出具有最小权重的候选基分类器并进行替换,实现Ei的组内动态更新。 为了增加最终集成分类器中的泛化性,提出新的异构集成分类器的自适应选择策略(adaptive selection strategies for heterogeneous ensemble classifiers,HEAS),它将整合1.1节动态生成的E1,E2,…,EH中分类性能最佳的候选基分类器来构成HE。在1.1节中,权重是以组为单位进行计算的,不同组之间候选基分类器的性能不能进行比较。为此,使用另一种方式计算候选基分类器的全局权重。 (5) MSEr=∑yp(y)(1-p(y))2 (6) 将MSEm和MSEr结合,可以给出基分类器的准确度信息和当前类分布的情况。同时为了避免被零除法的问题,添加一个非常小的正值θ。 HEAS是选择最佳的候选基分类器并将其进行整合构成HE的策略,使用式(7)计算组内候选基分类器Chm的全局权重,并记为wg (7) HEAS的具体过程在算法1中进行描述。第(1)~(5)行是为每组E中的候选基分类器计算wg的过程。第(7)行是选出wg最大的候选基分类器。它选择的过程是按照组内基分类器的顺序进行。首先,它将选出所有E中第一个候选基分类器 {C11,C21,…,CH1} 中具有最大wg的候选基分类器Cbest,并将其加入到HE中;之后,会选出E中的第二个候选基分类器 {C12,C22,…,CH2} 中具有最大的wg的候选基分类器Cbest,再将其加入到HE中。以此类推,直到HE中基分类器的数目与E中候选基分类器的数目相等。 算法1:HEAS算法 输入:E:候选分类器组;C:E中的候选基分类器,M:当前E中候选基分类器的数目,H:分类算法的数目。 输出:HE:高层异构集成分类器。 (1)For (h=0;h (2) For (m=0;m (4) End for (5)End for (6)For (m=0;m (8)HE←将Cbest添加入HE中 (9)End for (10)输出HE 图1描述了DHEML算法的实现过程。它分为3个模块,分别为E的动态生成、候选基分类器的动态更新和HE的自适应生成。首先是对章节1.1中的E生成过程进行描述。由H种分类算法训练数据块Dt生成H个候选基分类器C1t,C2t,…,CHt。 将同种算法生成的基分类器 {C11,C12,… },{C21,C22,…},…,{CH1,CH2,… } 分别构成E1,E2,…,EH。 其次是E的动态更新过程,为了使其具有最佳的分类性能,需要进行组内候选基分类器的动态更新。图1以EH1为例进行介绍候选基分类器动态更新。当当前组内候选基分类器数量t大于K时,使用最新数据块Dt+1生成候选基分类器CHt+1去替换旧的、过时的候选基分类器。使用1.1节中的式(4)计算E中每个候选基分类器的权重w,选择权重最小的基分类器CH2进行替换。最后是使用章节1.2的HEAS动态生成HE。为了增加集成分类器的泛化性,算法将每个E中最优的候选基分类器加入到HE中。DHEML使用章节1.2节中的式(7)计算每个E中候选基分类器的wg。 按图中的列进行比较,如C11,C21,…,CH1, 通过判断选出wg最大的候选基分类器并将其加入到HE中。 图1 DHEML算法实现过程 图1生成的HE是一种极端的情况,即采用HEAS方法对不同算法生成的候选基分类器都有一个选中,但现实中并非如此,它会根据wg选择出最合适、性能最好的候选基分类器将其加入到HE中,可能某个算法构成的候选基分类器都没有被选中,或者都被选中。该算法不再是根据构建候选基分类器方法的类型来决定HE中基分类器的数量。 DHEML的训练与预测具体细节如算法2所示。第(2)~(7)行描述了该算法的预测阶段,其中第(3)行使用章节1.2节的HEAS算法构建HE。第(5)~(21)行描述了训练阶段。其中第(6)~(8)行使用H种分类算法训练Dt数据块生成H种候选基分类器。第(10)~(16)行是为E中候选基分类器的动态更新过程,即当前组内候选基分类器的数量大于上限数量K时,需要使用1.1节的式(4)计算权重,将权重值最小的候选基分类器与最新生成的候选基分类器进行替换。第(17)~(20)行为候选基分类器的添加和增量更新过程。 算法2:DHEML训练与预测算法 输入:D:数据流,Dt:数据块,C:候选基分类器,E:候选分类器组,K:E中基分类器的上限数量,H:分类算法的数目,HE:异构集成分类器。 (1)WhileD≠null //当数据流中的实例不为空时 (2)xi←当前的数据实例 (3)HE←使用HEAS构建HE//使用1.2节的算法1 (5)IfDtis full //当数据块中的实例达到固定数目时 (6) For (h=0;h (7)Chin←分类算法h使用Dt构建候选基分类器 (8) End for (9)t++; //统计Eh组内候选基分类器的数量 (10) Ift>K//当Eh中候选基分类器的数量大于上限数目时 (11) For (h=0;h (12) 使用式(4)计算Eh中每个候选基分类器的权重w (13)Chout←选择Eh中权重最小的候选基分类器 (14)Eh←Eh-Chout//将Chout从Eh中移除 (15) End for (16) End if (17) For (h=0;h (18)Eh←Eh∪Chin (19)Eh←使用Di训练Eh中的候选基分类器 //对除Chin之外的其余基分类器进行增量学习 (20) End for (21) End if (22)End While 本实验软件环境是大规模在线分析开源平台(massive online analysis,MOA)[12],并结合MEKA[13]中的多标签方法。实验预测采用了交错式训练与测试(interleaved-test-then-train,ITTT)的评估方法[9]。 本章将提出3个DHEML算法与10种分类算法(EBR[13]、ECC[13]、EPS[14]、GORT[9]、EBRT[15]、EaBR、EaCC、EaPS[16]、ASEKNN[17]、MLSL[18])进行对比,其中,DHEML1采用PS和CC的分类算法构建HE,DHEML2采用BR和CC的分类算法构建HE,DHEML3采用BR和CC的分类算法构建HE。 实验从研究领域、实例数(n)、特征数(m)、标签数(L)、标签基数(LC(D))和标签密度(LD(D))对数据集进行介绍,见表1。其中,标签基数和标签密度如式(8)、式(9)所示 表1 数据集 (8) (9) 在多标签分类中,单一的使用某些评估指标作为评估指标是不合适的。针对多标签分类设计了许多评估指标。本文使用准确度、实例的F1值、微观F1和宏观F1来进行评估。 (1)固定与动态调整基分类器对比实验 传统的异构集成分类器是由不同分类算法训练的基分类器构成,基分类器的数量由采用的不同分类算法的数量决定。为了验证动态调整基分类器的数量可以提高分类性能的说法,本节将固定基分类器数量的HEML与动态调整基分类器数量的DHEML进行实验。在HEML中,每次选择E中wg值最大的候选基分类器加入到HE中。为了保证小数据集也可以生成多样性的基分类器,块的大小设置为500。实验结果如图2所示,在大多数的情况下,DHEML算法比HEML算法具有更好的性能。DHEML2在Philosophy数据集上对比结果尤为明显。由此得出自适应调整异构集成分类器中基分类器的数量可以提高分类的性能。 图2 异构集成分类对比 (2)与同构/异构集成的对比实验 将DHEML1、DHEML2、DHEML3与EBR、ECC、EPS、GORT、ASEKNN、EBRT、EaBR、EaCC、EaPS算法在6个数据集上进行对比的结果见表2,详细的实验结果包括每个算法的准确度、实例的F1值、微观F1和宏观F1。最好的结果使用加粗表示。实验中设置基分类器的数量均为10。 从表2中可以看出,DHEML1、DHEML2、DHEML3在4个评估指标准确度、实例的F1值、微观F1和宏观 F1上均获得较好的结果,其中DHEML1算法获得了最好排名。与EBR、ECC、EPS相比,在数据集Medical的准确度中,DHEML1比EBR高9.3%,比ECC高9.7%,比EPS高8.1%。在数据集Ohsumed的准确度中,DHEML3比EBR高12.5%,比ECC高13.6%,比EPS高18.1%。 与增加窗口机制的EaBR、EaCC、EaPS算法相比,使用DHEML的算法也可以获得不错的实验结果。而在数据集Ohsumed上的准确度中,对比算法EaCC却不是很乐观。DHEML1、DHEML2、DHEML3 比EaCC有明显的提升。其中,DHEML1算法比EaCC的Accuracy值高达22.1%,DHEML2的算法比EaCC的Accuracy值高达19%,DHEML3的算法比EaCC的Accuracy值高达31.2%。总体来说,DHEML的算法比使用同构集成的算法结果性能更好。因为该算法使用HEAS来选择可以获得更好性能的基分类器构成HE。由此得出,采用异构集成的分类算法提高集成分类器的多样性,从而有效提高分类结果。 在时间效率方面,小型数据集时所有DHEML拥有较小的时间效率,但面对较大数据集时,随着实例的增加和特征关系的复杂性,几何加权方法会消耗大量的时间,所有DHEML的运行时间增加,比同构集成算法花费更多时间。EPS的运行时间较短,这是因为它可以修剪不经常出现的标签集来关注标签最重要的关系,从而节省时间。 (3)数据流分析 当实例不断增加,数据流算法的分类能力也会随之改变。本节研究随着实例的增加和实例分布变化引起概念漂移现象时,DHEML算法是否具有较好的自适应调节能力。当数据集较小时,如果分类算法选择的数据块太大,则不能很好应对突变漂移,同时基分类器的数量也会减小,导致集成分类器的泛化性降低,使分类结果降低。当数据集较大时,如果分类算法选择的数据块较小,则运行时间增多。针对以上两种情况,本节选择块大小为500进行实验,并给出了10种算法分别在数据集Slashdot和Ohsumed上基于实例的F1的评估结果。结果如图3所示。 图3 基于窗口的模型评估 图3可以看出,随着实例的增加,集成分类器的分类性能也在不断的变化。EPS、EaPS在两个数据集中都位于图片的中间位置,在图3(a)中还呈现下降的趋势,这是因为它的剪枝策略可能修剪掉了有用的信息使分类器不能充分的学习。DHEML1的最终结果都处于较好的位置。在图3(b)中,DHEML1算法在训练基分类器时需要较多的实例才可以获得更好的结果。由此可知,DHEML在数据流环境中可以较好应对概念漂移同时具有较高的评估值。 为了实现自适应调整基分类器的数量从而得到更符合数据特性的HE,本文提出了DHEML算法。为了可以处理新传入的数据,使用几何加权计算候选基分类器的权重,根据权重进行更新替换;根据HEAS动态选择适当的候选基分类器来构建HE。通过实验得知,自适应调整基分类器的数量可以提高分类结果,同时与其它集成分类器的算法相比,DHEML算法可以在准确度、实例的F1值、微观F1和宏观 F1上获得较好的结果,综合排名最好。但随着数据集实例的增加,该算法的时间效率开始增加。在未来的工作中,本课题组将关注算法时间效率,在保证评估指标稳定的情况下,使E的候选基分类器生成和更新阶段可以并行运行,提高算法的时间效率。

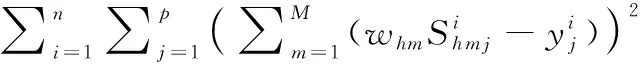

1.2 异构集成分类器的自适应选择策略
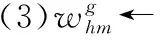
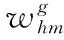
1.3 DHEML的实现过程


2 实验结果与分析
2.1 实验设置

2.2 实验分析

3 结束语
